







目录
pandas批量删除优化
批量删除方法1:
遍历drop删除,1万条,耗时24秒
self.df_label = pd.read_csv(self.label_file)
self.rename_columns = {'size': 'size_0/size_1'}
self.df_label.rename(columns=self.rename_columns, inplace=True)
def_count=0
start =time.time()
for index_a in self.df_label.index:
try:
image_path=self.initial_path + self.df_label.loc[index_a].values[0]
except Exception as e:
print(e)
if not os.path.exists(image_path):
related_path = image_path.replace(self.initial_path, "")
# print('del',image_path)
def_count+=1
self.df_label.drop(self.df_label[self.df_label.img_path == related_path].index, inplace=True)
print("time1",time.time()-start)
start = time.time()方案2:用concat重新建表,1万条左右,耗时24秒
self.df_label = pd.read_csv(self.label_file)
self.rename_columns = {'size': 'size_0/size_1'}
self.df_label.rename(columns=self.rename_columns, inplace=True)
def_count=0
start = time.time()
data2=[]
for index_a, data in self.df_label.iterrows():
image_path=self.initial_path + data.values[0]
if os.path.exists(image_path):
data2.append(pd.Series(data.values, index=self.df_label.columns))
def_count += 1
gdp4=pd.concat(data2,axis=1)
print("time2",time.time()-start)pandas读取遍历数据
df_label= pd.read_csv(from_dir)
ssh = get_ssh()
imgs=[]
out_to = to_dir + '/imgs/'
os.makedirs(out_to, exist_ok=True)
for row_index, data in df_label.iterrows():
path=data['img_path']
imgs.append('/xxx/' + os.path.basename(path))
pandas 统计元素出现次数
import pandas as pd
if __name__ == '__main__':
data1 = {'auser': ['zszxz', 'craler', 'zszxz'], 'aprice': [100, 200, 300],
'ahobby': ['reading', 'running', 'hiking']}
data_len = len(data1['auser'])
index = [i for i in range(data_len)]
frame1 = pd.DataFrame(data1, index)
# frame1['aprice'] = [1, 2, 3] # 列赋值
aaa= frame1['auser'].value_counts() #统计元素次数
"/".join(aaa.index.tolist()) # 不同元素名单
df1 = frame1.drop(['ahobby'], axis=1) # 删除列拼接合并表append
以下内容转自不错的博客:
pandas用法-全网最详细教程_一夜了的博客-CSDN博客_pandas
result = df1.append(df2)
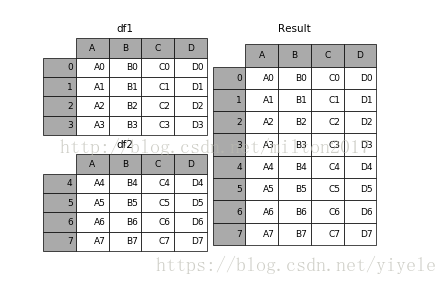
上面会警告,推荐用cancat来拼接,不能自动去重:
import pandas as pd
x=['上海','北京','深圳','广州','重庆']
y=['上海','北京','深圳','广州','天津']
z=['天津','苏州','成都','武汉','杭州']
datas=[]
gdp1=pd.Series([32679,30320,24691,23000,20363],index=x)
gdp2=pd.Series([30133,28000,22286,21500,18595],index=y)
gdp3=pd.Series([18809,18597,15342,14847,13500],index=z)
datas.append(gdp1)
datas.append(gdp2)
datas.append(gdp3)
gdp4=pd.concat(datas, axis=1)
#gdp4 = pd.concat(data2, axis=1)
print('del count',self.df_label.shape[0]-def_count)
self.df_label = gdp4.T
self.df_label.to_csv(self.label_file, index=False)result = left.join(right, on='key')pandas修改列名,直接设置新表头即可
import pandas as pd
def getValue(s):
if 'a' in s:
return s.replace('bb','111')
else:
return s
if __name__ == '__main__':
csv_file=r"D:\data\quality\aaa.csv"
df=pd.read_csv(csv_file)
new_columns=["aaaa",'bbb','ccc'] #会把数据也一起改,不能用
df.columns =new_columns
df.to_csv(csv_file, index=False)
# print(df)
pandas列赋值,删除列
if __name__ == '__main__':
data1 = {'auser': ['zszxz', 'craler', 'rose'], 'aprice': [100, 200, 300], 'ahobby': ['reading', 'running', 'hiking']}
data_len=len(data1['auser'])
index = [i for i in range(data_len)]
frame1 = pd.DataFrame(data1, index)
frame1['aprice'] =[1,2,3] # 列赋值
df1 = frame1.drop(['ahobby'], axis=1) # 删除列
df1.to_csv("temp.csv",index=False)pandas修改列
label_file=r'D:\data\cls\laduni\la_train\la_0_6_t\label.csv'
shutil.copy(label_file,label_file.replace("label.csv","label_1112.csv"))
df_label = pd.read_csv(label_file)
values=[]
for data in df_label.itertuples():
if data[2]==2:
values.append(6)
elif data[2]==6:
values.append(2)
else:
values.append(data[2])
df_label[df_label.columns[1]] = values # 列赋值
df_label.to_csv(label_file, index=False)pandas合并列
# -*- coding: utf-8 -*-
import pandas as pd
def col_rename():
csv_file=r"D:\data\quality\aaa.csv"
df=pd.read_csv(csv_file)
new_columns=["aaaa",'bbb','ccc'] #会把数据也一起改,不能用
# df02 = df.reindex(columns=new_columns) # 调整索引,不仅仅调整行,也可以调整列
# 注意这里reindex的妙用,可以自动关联数据,调整数据
df.rename(columns={'box': 'small/big'}, inplace=True)
df.to_csv(csv_file, index=False)
if __name__ == '__main__':
data1 = {'auser': ['zszxz', 'craler', 'rose'], 'aprice': [100, 200, 300], 'ahobby': ['reading', 'running', 'hiking']}
data_len=len(data1['auser'])
index = [i for i in range(data_len)]
frame1 = pd.DataFrame(data1, index)
data2 = {'bperson': ['zszxz', 'craler', 'rose'], 'bnumber': [100, 200, 300],
'bactivity': ['swing', 'riding', 'climbing']}
frame2 = pd.DataFrame(data2, index)
join = frame1.join(frame2)
print(join)读取设置索引index
比如读取数据时想把第一列设为index,那么只需要简单的
pd.read_csv("new_wordvecter.csv",index_col=[0])
修改列数据类型
使用astype如下: df[[column]] = df[[column]].astype(type)
pandas不支持遍历修改,可以单元格修改:
遍历修改报错:
frame1 = pd.read_csv("temp.csv")
for i in range(3):
frame1.iloc[i]["aprice"]=i
# for row in frame1.itertuples():
frame1.to_csv("temp.csv",index=False)
pandas 报警告:A value is trying to be set on a copy of a slice from a DataFrame
我的解决方法:用list存储新的列数据,然后整列赋值。
解决方法二
换一种方式对 pandas 单元格进行修改
dfc = pd.DataFrame({'a':[1,2,3,4,5,6],'b':[2,3,4,5,6,7]})
dfc2 = dfc[['a','b']]
# 这个命令不会警告
dfc2.loc[3, 'b'] = 'english'
注意: loc 有一个很类似的api,即iloc ,但我在使用 dfc2.iloc[0][0] =111 修改单元格数据时弹出警
原文链接:https://blog.csdn.net/qq_38463737/article/details/124126393
pandas按行筛选
import pandas as pd
data1 = {'auser': ['zszxz', 'craler', 'rose'], 'aprice': [100, 200, 300], 'ahobby': ['reading', 'running', 'hiking']}
data_len =len(data1['auser'])
index = [i for i in range(data_len)]
frame1 = pd.DataFrame(data1, index)
data1=frame1.iloc[:2]
print(data1)pandas批量插入数据
方法1:for循环 loc的方式批量生成数据很慢,10万数据200秒左右。
row_data.append(0)
row_data.append(
";".join([str(xyxy[0]), str(xyxy[1]), str(xyxy[2] - xyxy[0]), str(xyxy[3] - xyxy[1])]))
row_data.append(1)
row_data.append(opt.cam_id)
df_label.loc[len(df_label) + 1] = row_data方法2:
把每列数据单独保存,最后按列赋值,效率非常快,10万数据4秒左右。
也可以参考第一条批量删除数据。
import os.path
import shutil
import time
import pandas as pd
if __name__ == '__main__':
list_path=r'D:\data\quality\28w\train_3'
g = os.walk(list_path)
label_files = ['%s/%s' % (i[0], j) for i in g for j in i[-1] if j=='label.csv']
for csv_file in label_files:
csv_to_file=csv_file.replace("label.csv","label_cam.csv")
data1=[]
data2=[]
data3=[]
data4=[]
data5=[]
data6=[]
df_label=pd.read_csv(csv_file)
df_2 = pd.DataFrame(df_label.columns)
start=time.time()
# try:
columns = {'none/incomplete': 'none/ban/small/big','is_train':'val/train','size':'size_0/size_1'}
df_label.rename(columns=columns, inplace=True)
col_names = df_label.columns.tolist()
new_col = "cam_id"
df_label.insert(loc=df_label.columns.size, column=new_col, value=-1) if new_col not in col_names else 1
col_names = df_label.columns.tolist()
start=time.time()
col_1=[]
for row_index,data in df_label.iterrows():
img_path = data[col_names[0]]
cam_id=int(img_path.split("_")[-3])
col_1.append(cam_id)
data1.append(data[col_names[0]])
data2.append(data[col_names[1]])
data3.append(data[col_names[2]])
data4.append(data[col_names[3]])
data5.append(data[col_names[4]])
# data6.append(data[col_names[5]])
df_label[col_names[0]] = data1
df_label[col_names[1]] = data2
df_label[col_names[2]] = data3
df_label[col_names[3]] = data4
df_label[col_names[4]] = data5
df_label[col_names[5]] = col_1
print('sace data len', df_label.shape[0],'time',time.time()-start)
df_label.to_csv(csv_to_file, index=False)
# except Exception as e:
# print(csv_file,e)pandas模糊匹配筛选数据
模糊匹配可能效率较低,数据量大了会比较耗时。
我们在使用pandas读取Excel后一般都需要对数据进行筛选,如果是数字格式的话比较简单,如果遇到列全部都是文字的话,如果按照我们的需求进行筛选呢?如筛选有指定文字的数据集,筛选包含某几个字的数据集,甚至运用正则表达式,去使用更高级的筛选策略呢,欢迎阅读如何使用pandas对包含文字的列数据进行筛选。
样例数据:

固定值过滤(必须全匹配)
print(data[data['籍贯'] == '北京'])
模糊过滤
文字匹配
print(data[data['籍贯'].str.contains('河北')])
注意data['籍贯'].str.contains('河北')返回的数据类型是Series,内容为是否包含河北的bool值
正则匹配
Str.contians也支持传入正则表达式进行匹配,这就给数据筛选提供了多的可能
print(data[data['籍贯'].str.contains('.*?泰州')])
匹配以泰州结尾的籍贯
原文链接:https://blog.csdn.net/qq_42006613/article/details/109531495
pandas数据去重
下来介绍到就是用于数据去重的drop_duplicate方法
这个方法是对DataFrame格式的数据,去除特定列下面的重复行。返回DataFrame格式的数据。
这个方法里面有三个可填参数:
DataFrame.drop_duplicates(subset=None, keep=‘first’, inplace=False)
subset : column label or sequence of labels, optional 用来指定特定的列,默认所有列
keep : {‘first’, ‘last’, False}, default ‘first’ 删除重复项并保留第一次出现的项
inplace : boolean, default False 是直接在原来数据上修改还是保留一个副本
例如:
1、整行去重。
DataFrame.drop_duplicates()
2、按照其中某一列去重,示例代码
self.df_label=self.df_label.drop_duplicates(subset='img_path')
3、只要是重复的数据,我都删除(例如有三个数字:1,2,1;执行之后变成:2;重复的都删除了)
DataFrame.drop_duplicates(keep=False)
下面给上第3中情况的代码
import pandas as pd
csv=pd.read_csv('E:/aaa/03.csv',low_memory=False,error_bad_lines=False)#读取csv中的数据
df = pd.DataFrame(csv)
print(df.shape)#打印行数
f=df.drop_duplicates(keep=False)#去重
print(f.shape)#打印去重后的行数
f.to_csv('E:/aaa/distionct_03.csv',index=None)#写到一个新的文件














 3405
3405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











