







文章目录
整体规划:
- 虚拟机基础概念
- class文件结构
- 内存加载过程
- 运行时内存结构
- JVM常用指令
- GC与调优(重点)
Part 1
JVM基础
java从编码到执行:
xxx.java -> javac命令 -> xxx.class -> java命令执行class文件 -> class文件和用到的相关类库被对应的ClassLoader加载进内存 -> 字节码解释器解释class文件/JIT即时编译器编译class文件 -> 执行引擎执行
其中ClassLoader到执行引擎的这部分叫做JVM(Java虚拟机)
JVM可以叫做是一个跨语言的平台,很多语言都能在JVM上跑。eg:java,scala,kotlin,groovy…
并且linux,unix,windows,mac,android都有自己实现的JVM
之所以这么多语言都可以在JVM上跑,就是因为他们在执行前都被预先编译成了class文件,JVM只看class文件 屏蔽了语言之间的差异。
ps:JVM只是一种规范,有很多不同的实现。
JVM的几种实现:
- HotSpot(oracle官方的实现)
- JRockit(曾经号称世界上最快的JVM,后来被oracle收购 和hotspot合并)
- J9-IBM
- VM-Microsoft
- TaobaoVM-hotspot(淘宝深度定制版JVM,阿里天猫都用这款)
- LiquidVM(直接针对硬件的JVM)
- azul zing(速度非常快,最新垃圾回收的业界标杆)
JVM < JRE(JVM + core lib) 可以运行class文件 < JDK(JRE+development kit) 可以写java程序 可以编译class文件 可以运行class文件
Class文件格式
class文件到底是个什么东西?
轻松看懂Java字节码
先来写一个最简单的类,这个类是空的:
package day01.example;
/**
* @author zhaoyu
* #Description T01_ByteCode01
* #Date: 2023-02-20 21:02
*/
public class T01_ByteCode01 {
}
然后用javac命令得到其字节码文件后,执行命令hexdump -C /Users/zhaoyu/Desktop/BigData/2022.05.05/JVM调优/src/main/java/day01/example/T01_ByteCode01.class
得到其未反编译前的原始十六进制字节码:
00000000 ca fe ba be 00 00 00 3d 00 0d 0a 00 02 00 03 07 |.......=........|
00000010 00 04 0c 00 05 00 06 01 00 10 6a 61 76 61 2f 6c |..........java/l|
00000020 61 6e 67 2f 4f 62 6a 65 63 74 01 00 06 3c 69 6e |ang/Object...<in|
00000030 69 74 3e 01 00 03 28 29 56 07 00 08 01 00 1c 64 |it>...()V......d|
00000040 61 79 30 31 2f 65 78 61 6d 70 6c 65 2f 54 30 31 |ay01/example/T01|
00000050 5f 42 79 74 65 43 6f 64 65 30 31 01 00 04 43 6f |_ByteCode01...Co|
00000060 64 65 01 00 0f 4c 69 6e 65 4e 75 6d 62 65 72 54 |de...LineNumberT|
00000070 61 62 6c 65 01 00 0a 53 6f 75 72 63 65 46 69 6c |able...SourceFil|
00000080 65 01 00 13 54 30 31 5f 42 79 74 65 43 6f 64 65 |e...T01_ByteCode|
00000090 30 31 2e 6a 61 76 61 00 21 00 07 00 02 00 00 00 |01.java.!.......|
000000a0 00 00 01 00 01 00 05 00 06 00 01 00 09 00 00 00 |................|
000000b0 1d 00 01 00 01 00 00 00 05 2a b7 00 01 b1 00 00 |.........*......|
000000c0 00 01 00 0a 00 00 00 06 00 01 00 00 00 08 00 01 |................|
000000d0 00 0b 00 00 00 02 00 0c |........|
000000d8
Class文件解读
接下来我们对上面的十六进制字节码进行解读:
前4个字节CA FE BA BE 叫做magic number(魔数),代表这是一个class文件
之后两个字节,这里是00 00 叫做minor version 代表小的版本号;再之后两个字节,eg:00 3d叫做大的版本号。00 3d对应的十进制数字是61(0011 1101),对应的jdk版本是jdk17
| java主要版本号 | jdk版本 |
|---|---|
| 46 | jdk1.2 |
| 47 | jdk1.3 |
| 48 | jdk1.4 |
| 49 | jdk5 |
| 50 | jdk5 |
| 51 | jdk6 |
| 52 | jdk8 |
| 53 | jdk9 |
| 54 | jdk10 |
| 55 | jdk11 |
| 56 | jdk12 |
| 57 | jdk13 |
| 58 | jdk14 |
| 59 | jdk15 |
| 60 | jdk16 |
| 61 | jdk17 |
再之后两个字节 eg:00 0d 代表常量池中存在了多少个常量,既然这里用两个字节来表示 那么说明常量池最多能存2^16-1个常量(65536-1=65535)
再之后两个字节0a 00 代表class的类型,叫做access_flags 例如:
- ACC_PUBLIC 0x0001:是否为public
- ACC_FINAL 0x0010:是否为final
- ACC_INTERFACE 0x0200:是否为接口
- ACC_ABSTRACT 0x0400:是否为接口或抽象类
- ACC_ANNOTATION 0x2000:是否为注解
- ACC_ENUM 0x4000:是否为枚举类
当一个类兼具了上面几个flag的特征时,把这几个flag按位与得到一个2字节的access_flag
之后还记录了一些General Information 例如:Interfaces count(实现的接口数量),Fields count(类属性的数量),Methods count(类方法数量),Attributes count(附加属性数量)
General Information之后就是最重要的部分:Constant Pool
Constant Pool之后是Interfaces,Fields,Methods,Attributes。在Methods中还记录了方法的具体实现Code
方法的具体实现在字节码文件中全是16进制表示 JVM再根据其去自己的指令表中查找对应的汇编指令 eg:根据jvm规范,0x00 00代表nop,0x01 01代表aconst_null… 这些是java的汇编语言
总结:
整个Class文件结构由这几部分组成:
- General Information
- Constant Pool
- Interfaces
- Fields
- Methods
- Attributes
Part 2
Part 1复习
class文件的前4个字节是固定的CAFE BABE,声明这是一个字节码文件;
之后两个字节:minor version 代表jdk的小版本号,再之后两个字节:major version 代表jdk大的版本号(ps:jdk1.8的十进制major version是52)
之后就是常量池constant pool,前两个字节记录常量池的长度,后面存储常量池的内容
constant pool之后就是access flags,描述类的种类(接口/枚举类/普通类/抽象类…)
之后是super class 记录父类信息
之后是interface count 这个类实现的接口数量
之后是interfaces 存放具体实现的接口信息
之后是fields count 记录这个类中的属性数量
之后是fields 具体的属性信息
之后是methods_count 记录这个类中具体的方法数量
之后是method_info 记录具体的方法信息
最后是attribute_count 存放额外信息的数量
最后是attribute 存放具体的额外信息,其中最重要的是code属性 包含了Java虚拟机指令、异常表和其他与方法代码有关的信息。
Field和Attribute的区别:

类加载过程
类加载器
class需要经过什么样的步骤才能被加载进内存呢?
class -> loading -> linking(verification -> preparation -> resolution) -> initializing -> GC
- verification:校验装入的class文件是否符合标准 eg:前4个字节是否为CAFE BABE
- preparation:为class文件中的静态变量赋默认值() eg:static int i = 8; 静态变量i在preparation在这一步被赋默认值=0;
请注意,preparation阶段是针对静态变量的。实例变量(非静态变量)将在对象实例化时,也就是在类的构 造函数调用过程中,进行初始化。实例变量的默认初始化是在对象分配内存时由 Java 虚拟机自动完成的,而具体的初始值设定则是在构造函数中根据程序员的代码设定的。
所以,总结来说,在类加载的 preparation 阶段,是为所有静态变量赋默认值,而不是为所有变量赋初始值。具体的初始值设定发生在类的初始化阶段(initialization),此时会执行静态变量的赋值语句和静态代码块。 - resolution:将class文件中的引用转换为内存地址
- initializing:给静态变量赋初始值 eg:static int i = 8;静态变量i在这一步被赋值为8
类加载器:
JVM中的所有class文件都是被对应的类加载器ClassLoader加载进内存的。
class对象:class文件被load进内存后,内存后会有两块内容:1.存放class文件 2.生成一个class类的对象,指向内存中的class文件。这里提一下,所谓的反射就是将类文件加载进内存,然后用其class对象来创建其对象的过程。而正常的创建对象流程是加载类->链接类->类的初始化->对象的实例化。当我们创建一个对象时,是会涉及到类对象的创建的,因为Java中的每个类都是java.lang.Class类的一个实例,一个类对象对应其在JVM中加载的那个类文件。如果这个类还没有被加载,那么在我创建对象之前,JVM会先加载类文件到内存中,然后创建类对象,最后创建我通过new关键字请求的实例对象。

ps:class类的对象存在metaSpace里(metaSpace就是指方法区/元空间,方法区在jdk1.8之间叫Permanent Generation 永久代,在jdk1.8之后叫metaSpace)
我们可以通过这个class对象执行其对应类中的方法,访问类的属性、方法、或者通过该类的构造器创建对象等。这就是反射。
类加载器的层次问题:
不同的类加载器在不同的层次上加载不同的类:
- 第一层:Bootstrap(C++实现的类加载器),负责加载jdk中最核心的jar包 eg:rt.jar charset.jar等核心类。如果getClassLoader()的返回值是null,说明使用的是这个最顶层的类加载器
- 第二层:Extension,负责加载扩展jar包 eg:ext包
- 第三层:Application,负责加载classpath下的字节码文件,即我们自己写的类
- 第四层:Custom ClassLoader
获得类加载器案例:
package day02.example;
/**
* @author zhaoyu
* #Description T01_ClassLoaderLevel
* #Date: 2023-02-24 13:24
*/
public class T01_ClassLoaderLevel {
public static void main(String[] args) {
System.out.println(String.class.getClassLoader()); //null
//BootStrap ClassLoader是C++实现的 java里并没有一个类和它对应 所以返回空
System.out.println(sun.awt.HKSCS.class.getClassLoader()); //null
//BootStrap ClassLoader
System.out.println(sun.net.spi.nameservice.dns.DNSNameService.class.getClassLoader()); //sun.misc.Launcher$ExtClassLoader@6d6f6e28
//ext包下的DNSNameService:ExtClassLoader
System.out.println(T01_ClassLoaderLevel.class.getClassLoader()); //sun.misc.Launcher$AppClassLoader@18b4aac2
//自定义类的类加载器:AppClassLoader
System.out.println(sun.net.spi.nameservice.dns.DNSNameService.class.getClassLoader().getClass().getClassLoader()); //class sun.misc.Launcher$ExtClassLoader
//ExtClassLoader这个类加载器的ClassLoader也是Bootstrap ClassLoader
System.out.println(T01_ClassLoaderLevel.class.getClassLoader().getClass().getClassLoader()); //null
//ApplicationClassLoader这个类加载器的类加载器也是Bootstrap ClassLoader
}
}
类加载器的双亲委派机制:
不同层次之间的ClassLoader,虽然叫父加载器,但是类加载器之间并没有继承关系
eg:AppClassLoader的层次低于ExtClassLoader,但是他们都继承自URLClassLoader->SecureClassLoader->ClassLoader
ps:关于rt.jar
- rt.jar代表runtime,包含所有核心Java运行环境的已编译的class文件
- 必须在类路径中包含rt.jar,否则我们无权访问核心类。比如 java.lang.String,java.lang.Thread,java.util.ArrayList或java.io.InputStream等都是rt.jar下的类。
- 可以使用IDE打开并查看rt.jar中的内容,它不仅包含所有Java API,还包含com包中指定的内部类
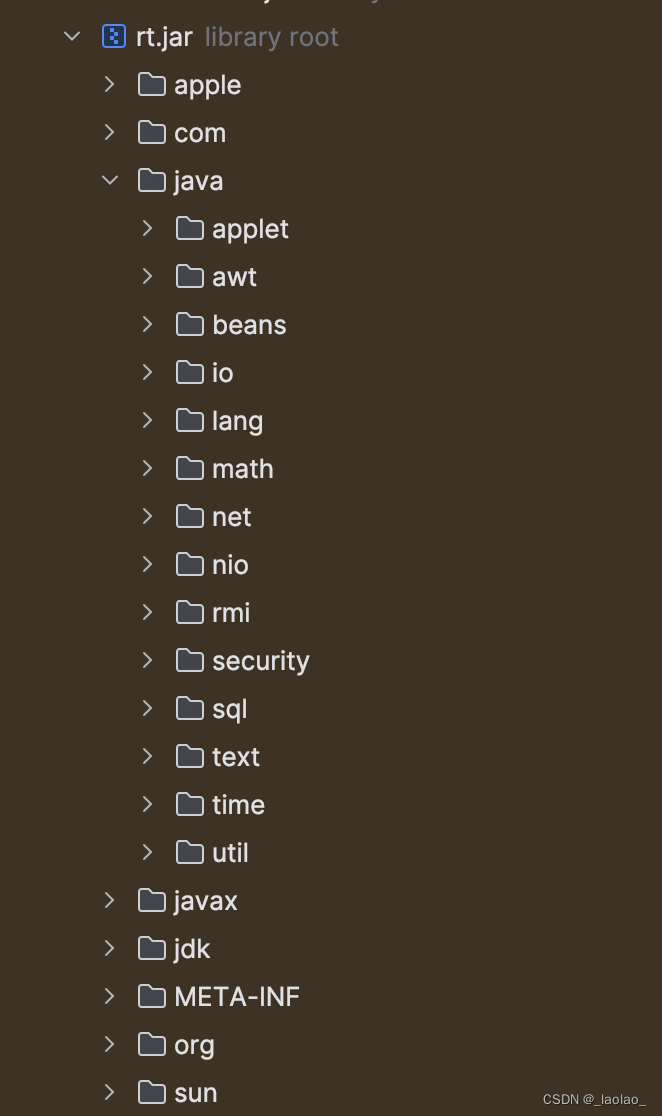
双亲委派:
在Launcher.java中,AppClassLoader和ExtClassLoader都作为其内部类存在。Launcher中声明了这三种类加载器能加载的类的范围:
BootStrapClassLoader:
private static String bootClassPath = System.getProperty("sun.boot.class.path");
AppClassLoader:
final String var1 = System.getProperty("java.class.path");
ExtClassLoader:
String var0 = System.getProperty("java.ext.dirs");
并且在Launcher的构造方法中调用了内部类中AppClassLoader的loadClass方法:
Launcher构造方法:注意 AppClassLoader ExtClassLoader的父子(parent构造参数)关系就是在这里指定的 至于ExtClassLoader和BootStrapClassLoader的父子关系
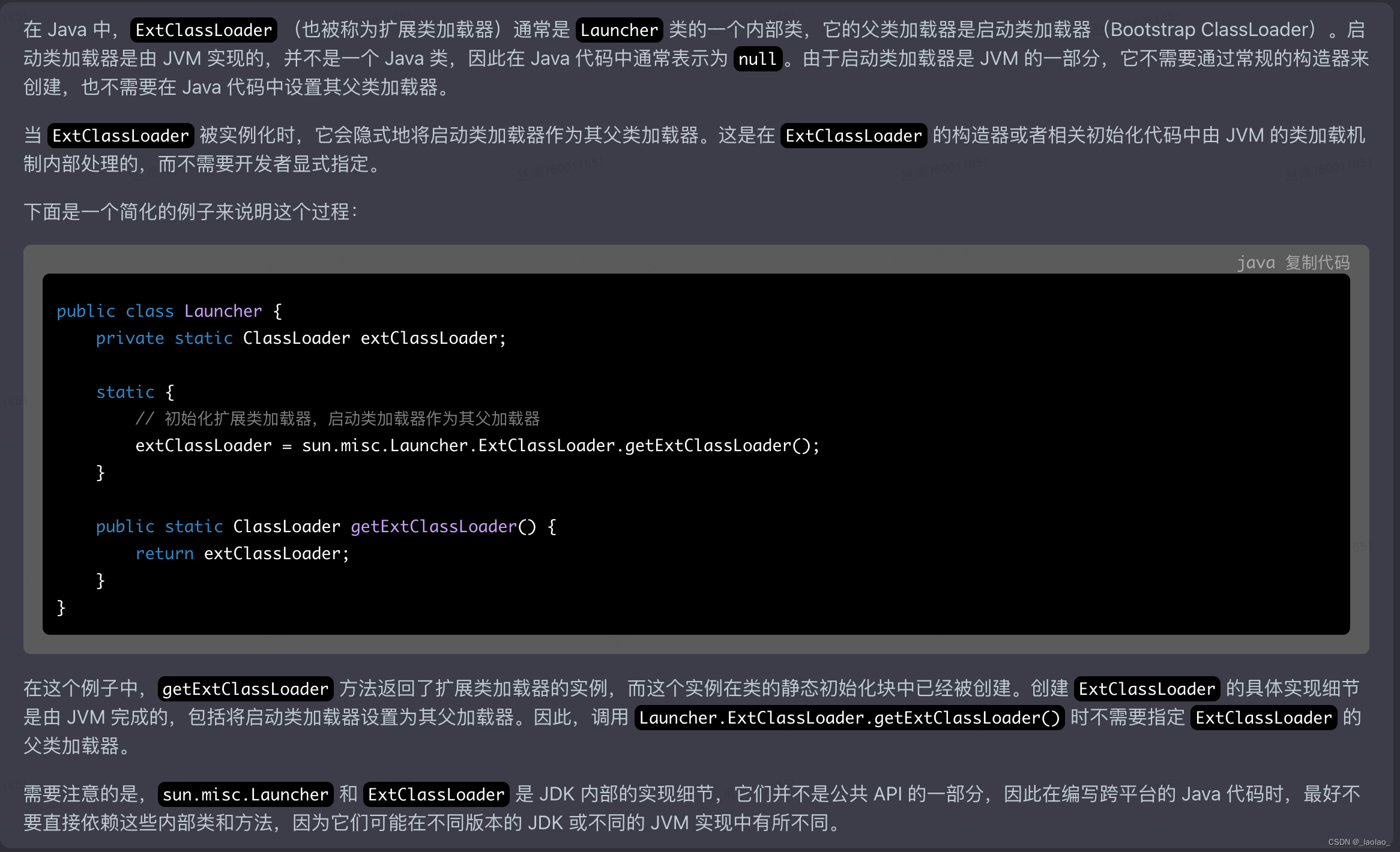
public Launcher() {
ExtClassLoader var1;
try {
//创建Launcher.ExtClassLoader对象,由于BootStrapClassLoader不是java实现的,所以这里不能写getExtClassLoader(bootStrapClassLoader),实际上这里是隐式指定了ExtClassLoader的父加载器是BootStrapClassLoader
var1 = Launcher.ExtClassLoader.getExtClassLoader();
} catch (IOException var10) {
throw new InternalError("Could not create extension class loader", var10);
}
try {
this.loader = Launcher.AppClassLoader.getAppClassLoader(var1);
} catch (IOException var9) {
throw new InternalError("Could not create application class loader", var9);
}
Thread.currentThread().setContextClassLoader(this.loader);
String var2 = System.getProperty("java.security.manager");
if (var2 != null) {
SecurityManager var3 = null;
if (!"".equals(var2) && !"default".equals(var2)) {
try {
//调用AppClassLoader的loadClass方法
var3 = (SecurityManager)this.loader.loadClass(var2).newInstance();
} catch (IllegalAccessException var5) {
} catch (InstantiationException var6) {
} catch (ClassNotFoundException var7) {
} catch (ClassCastException var8) {
}
} else {
var3 = new SecurityManager();
}
if (var3 == null) {
throw new InternalError("Could not create SecurityManager: " + var2);
}
System.setSecurityManager(var3);
}
}
AppClassLoader中调用了ClassLoader的loadClass方法:super.loadClass
public Class<?> loadClass(String var1, boolean var2) throws ClassNotFoundException {
int var3 = var1.lastIndexOf(46);
if (var3 != -1) {
SecurityManager var4 = System.getSecurityManager();
if (var4 != null) {
var4.checkPackageAccess(var1.substring(0, var3));
}
}
if (this.ucp.knownToNotExist(var1)) {
Class var5 = this.findLoadedClass(var1);
if (var5 != null) {
if (var2) {
this.resolveClass(var5);
}
return var5;
} else {
throw new ClassNotFoundException(var1);
}
} else {
return super.loadClass(var1, var2);
}
}
类加载过程:ClassLoader#loadclass 这里是递归调用loadClass方法加载类的
protected Class<?> loadClass(String name, boolean resolve)
throws ClassNotFoundException
{
synchronized (getClassLoadingLock(name)) {
// First, check if the class has already been loaded
Class<?> c = findLoadedClass(name);
if (c == null) {
long t0 = System.nanoTime();
try {
if (parent != null) {
c = parent.loadClass(name, false);
} else {
c = findBootstrapClassOrNull(name);
}
} catch (ClassNotFoundException e) {
// ClassNotFoundException thrown if class not found
// from the non-null parent class loader
}
if (c == null) {
// If still not found, then invoke findClass in order
// to find the class.
long t1 = System.nanoTime();
c = findClass(name);
// this is the defining class loader; record the stats
sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0);
sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1);
sun.misc.PerfCounter.getFindClasses().increment();
}
}
if (resolve) {
resolveClass(c);
}
return c;
}
}
其中AppClassLoader的findClass方法(这里是多态):这个方法调用了父类URLClassLoader的findClass方法
protected Class findClass(String var1) throws ClassNotFoundException {
int var2 = var1.indexOf(";");
String var3 = "";
if (var2 != -1) {
var3 = var1.substring(var2, var1.length());
var1 = var1.substring(0, var2);
}
try {
return super.findClass(var1);
} catch (ClassNotFoundException var8) {
if (!this.codebaseLookup) {
throw new ClassNotFoundException(var1);
} else {
String var4 = ParseUtil.encodePath(var1.replace('.', '/'), false);
final String var5 = var4 + ".class" + var3;
try {
byte[] var6 = (byte[])((byte[])AccessController.doPrivileged(new PrivilegedExceptionAction() {
public Object run() throws IOException {
try {
URL var1 = new URL(AppletClassLoader.this.base, var5);
return AppletClassLoader.this.base.getProtocol().equals(var1.getProtocol()) && AppletClassLoader.this.base.getHost().equals(var1.getHost()) && AppletClassLoader.this.base.getPort() == var1.getPort() ? AppletClassLoader.getBytes(var1) : null;
} catch (Exception var2) {
return null;
}
}
}, this.acc));
if (var6 != null) {
return this.defineClass(var1, var6, 0, var6.length, this.codesource);
} else {
throw new ClassNotFoundException(var1);
}
} catch (PrivilegedActionException var7) {
throw new ClassNotFoundException(var1, var7.getException());
}
}
}
}
URLClassLoader的findClass方法(ExtClassLoader和AppClassLoader的父类都是URLClassLoader):根据class文件url返回class对象
protected Class<?> findClass(final String name)
throws ClassNotFoundException
{
final Class<?> result;
try {
result = AccessController.doPrivileged(
new PrivilegedExceptionAction<Class<?>>() {
public Class<?> run() throws ClassNotFoundException {
//这里替换路径是因为 通常类文件存的路径是a/b/c,所以把a.b.c转换为a/b/c
String path = name.replace('.', '/').concat(".class");
Resource res = ucp.getResource(path, false);
if (res != null) {
try {
return defineClass(name, res);
} catch (IOException e) {
throw new ClassNotFoundException(name, e);
} catch (ClassFormatError e2) {
if (res.getDataError() != null) {
e2.addSuppressed(res.getDataError());
}
throw e2;
}
} else {
return null;
}
}
}, acc);
} catch (java.security.PrivilegedActionException pae) {
throw (ClassNotFoundException) pae.getException();
}
if (result == null) {
throw new ClassNotFoundException(name);
}
return result;
}
类加载过程总结:
- 在Launcher类中定义了内部类AppClassLoader和ExtClassLoader(由于BootStrapClassLoader是c++实现的,所以java代码中肯定找不到),在Launcher的构造方法中,定义了AppClassLoader和ExtClassLoader的父子关系(这里并不是类之间的父子关系),并且调用了AppClassLoader的loadClass方法。
- AppClassLoader的loadClass方法是继承了ClassLoader的,ClassLoader的loadClass方法的逻辑为,从调用这个方法的对象开始(即AppClassLoader对象),从下往上递归的去判断该类加载器是否加载过这个要加载的类,如果没有,就到定义的该类加载器的父类加载器中去找。如果都找不到,则开始出栈,依次从最顶的类加载器(BootStrapLoader)开始调用findClass方法尝试加载这个类文件,获得其类对象。如果findClass方法成功返回了类对象(加载成功),则推出递归,否则依次从上往下的尝试加载该类文件。注意:这里不同类加载器能加载的类范围,除了和其findClass方法实现有关,也和其定义的能加载的类的范围有关。
到这里我们可以总结出:1.Launcher的构造方法中定义了类加载器之间的父子关系 2.ClassLoader的loadClass方法中定义了类加载器加载类的顺序 3.各类加载器的findClass方法即为加载类文件(入参是类文件全类名,返回一个类对象)
双亲委派机制:
上述的类加载过程形象的形容就是双亲委派机制。
一个class文件需要被load进内存时的执行过程(即ClassLoader类中的loadClass方法的执行逻辑):
-
自底向上检查该类是否已经被加载过,中间如果找到了就返回该类对象。
**a.**如果自定义过ClassLoader,就从自定义的ClassLoader开始,看这个类是否已经被加载进来
这里有一个疑问,自定义的ClassLoader的父加载器是AppClassLoader是在哪里声明的呢? 事实上我们并不需要在自定义的ClassLoader中手动写一个构造函数并把AppClassLoader传进入以此来声明它的父类加载器是AppClassLoader,我们什么都不做也能完成这一步,这是为什么呢?
这就要看ClassLoader的构造方法了://ClassLoader无参构造方法 protected ClassLoader() { this(checkCreateClassLoader(), getSystemClassLoader()); } protected ClassLoader(ClassLoader parent) { this(checkCreateClassLoader(), parent); } private ClassLoader(Void unused, ClassLoader parent) { this.parent = parent; if (ParallelLoaders.isRegistered(this.getClass())) { parallelLockMap = new ConcurrentHashMap<>(); package2certs = new ConcurrentHashMap<>(); assertionLock = new Object(); } else { // no finer-grained lock; lock on the classloader instance parallelLockMap = null; package2certs = new Hashtable<>(); assertionLock = this; } }
在 Java 中,当你创建一个新的类加载器实例而没有显式指定父类加载器时,实际上是在类加载器的构造函数中隐式地使用了当前线程的上下文类加载器作为其父类加载器。这一行为是在 ClassLoader 类的构造函数中实现的。
具体来说,在 ClassLoader 类中有一个无参的构造函数,它会调用另一个带有 ClassLoader 参数的构造函数,并将当前线程的上下文类加载器作为参数传递。
在上面的代码片段中,checkCreateClassLoader() 是一个安全检查方法,用于确保创建类加载器的操作符合安全要求。getSystemClassLoader() 方法返回系统类加载器,它通常是应用程序类加载器(AppClassLoader)。
当你创建自己的类加载器时,如果你使用了无参构造函数,那么实际上你的类加载器会调用 ClassLoader 类的无参构造函数,进而调用带有当前线程上下文类加载器的构造函数,将其设置为父类加载器。例如:
public class MyClassLoader extends ClassLoader {
public MyClassLoader() {
super(); // 调用 ClassLoader 的无参构造函数
}
// ...
}
这样,MyClassLoader 的实例将继承当前线程的上下文类加载器作为其父类加载器。
问题2:这里又有一个疑问,是不是我们自定义好了自定义类加载器,重写了findClass方法。在之后每次java加载类的时候就会自动按照自定义类加载器->应用类加载器->扩展类加载器->系统类加载器的顺序去加载类呢?
不是的
b. 如果CustomClassLoader没加载过这个类,就查看AppClassLoader是否加载过。
c. 如果AppClassLoader中也没加载过,就查看ExtClassLoader是否加载过。
d. 如果ExtClassLoader中也没加载过,就查看BootstrapClassLoader是否加载过这个类。
- 自顶向下进行实际类文件的查找和加载,如果中间加载成功就返回结果。
a. BootstrapClassLoader先尝试加载,如果BootstrapClassLoader加载不了这个类(体现为findClass返回的类对象为null),就委托给ExtClassLoader加载。
b. 如果ExtClassLoader能够加载这个类就加载,如果不行就委托给AppClassLoader加载。
c. 如果AppClassLoader能够加载这个类加载,如果不行就委托给CustomClassLoader加载。
d. 如果CustomClassLoader也加载不了这个类,就跑异常ClassNotFoundException。
为什么要搞双亲委派机制?
主要是为了安全。试想如果没有双亲委派机制。我可以创建一个java.lang.String来覆盖java本来的java.lang.String,在这个我们新建的String中实现一个把所有创建的String对象都发送给我们的逻辑。然后因为自定义类加载器可以加载所有类,我们先使用自定义类加载器来加载这个类,当系统类加载器想要加载java.lang.String的时候,会发现:诶 这个类已经被加载过了(实际上是被我们自己先加载了),于是它就不重复加载了。那么我们把这个工程给别人使用的时候,用户在写密码的时候都要创建我们的这个String类型的对象,所有密码就被偷偷摸摸的发送到我们这里来了。
如果使用了双亲委派机制,划分了类加载器能够加载的类的范围和先后顺序呢?首先核心类只能由系统类加载器进行加载,系统类加载了核心类java.lang.String后,最后到我们的自定义类加载器这里,再想加载我们自定义的java.lang.String的话,会发现 这个类已经被加载过了,就不加载我们自定义的java.lang.String。减少了java核心类库被替换的风险。
java虚拟机只会在不同的类的类名相同并且加载该类的类加载器都是同一个的时候才会判定这是同一个类。如果没有双亲委派机制,同一个类可能会被多个类加载器加载,如此本来一个相同的类可能会被识别为两个不同的类,在赋值时问题就会出现。双亲委派机制能够保证在多类加载器加载某个类时,加载这个类的类加载器总是同一个,确保最终加载结果相同。
如果没有双亲委派模型,让所有类加载器自行加载的话,加入用户自己编写了一个java.lang.Object的类,并放在程序的classpath中,系统中就会出现多个类不同的Object类(AppClassLoader也可能加载,BootStrapClassLoader也可能加载)。Java类型体系中的基础行为就无法得到保证,应用程序就会变得一片混乱。
双亲委派机制保证类加载器能够:自下而上的委派,又自上而下的加载,保证每一个类只会由一个类加载器加载。一个非常明显的目的就是保证java官方的类库<JAVA_HOME>\lib 和扩展类库<JAVA_HOME>\lib\ext的加载安全性,保证这些核心类库不会被开发者覆盖。
例如java.lang.Object,它存放在rt.jar中。无论哪个类加载器要加载这个类,最终都是委派给启动类加载器进行加载,因此Object类载程序的各种类加载器环境中总是同一个类,不会被开发者自己写的java.lang.Object覆盖,也不会出现不同类加载器加载java.lang.Object得到歧义类对象的结果。
如果开发者自己开发开源框架,也可以自定义类加载器,同时利用双亲委派机制,来保护自己框架需要加载的类不被别人覆盖。

注意:如果我们自定义了ClassLoader,并且重写了findClass方法。当调用其loadClass方法时(继承自ClassLoader),所遵循的类加载链条就是 自定义类加载器->应用类加载器->扩展类加载器->启动类加载器。自定义类加载器的父类加载器为什么是应用类加载器前文已经说明
父加载器:
父加载器不代表类加载器的父类加载器。
双亲委派是一个孩子向父亲方向检查类是否被加载过,然后父亲向孩子方向委托加载的过程。
为什么要搞双亲委派?为了安全性,为了java给我们提供的类库不会被覆盖(如果两个类的类名相同并且类加载器相同,java就认为它们是同一个类)
从下面这个例子我们可以看到每个类加载器的parent属性(即他们的父类加载器)
package day02.example;
/**
* @author zhaoyu
* #Description T02_ParentAndChild
* #Date: 2023-02-24 17:14
*/
public class T02_ParentAndChild {
public static void main(String[] args) {
System.out.println(T02_ParentAndChild.class.getClassLoader());
//sun.misc.Launcher$AppClassLoader@18b4aac2
System.out.println(T02_ParentAndChild.class.getClassLoader().getClass().getClassLoader());
//null
System.out.println(T02_ParentAndChild.class.getClassLoader().getParent());
//sun.misc.Launcher$ExtClassLoader@4554617c
System.out.println(T02_ParentAndChild.class.getClassLoader().getParent().getParent());
//null
}
}
自定义类加载器:
怎么加载一个class文件?
a.获取这个类的类加载器 b.调用这个类加载器的loadClass(path)方法,获得一个class对象
根据设计模式中的模版模式,我们只需要继承ClassLoader,重写findClass方法,就可以定义好我们自己的类加载器了。
ps:class文件在加载进内存的时候会创建一个class对象,这个class对象指向这个class文件,反射就是用class对象去访问它在内存中指向的二进制的class文件,并调用其方法/访问其属性/或者创建对象等。
多态+反射是框架兼容我们自定义类的惯例。
什么时候需要自定义ClassLoader?在写框架写类库的时候要用到。
类加载器的加载范围是指定的path下的class文件们。
自定义一个类加载器,把c:/test下的class文件加载进内存并返回一个class对象。
package day02.example;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
/**
* @author zhaoyu
* #Description T03_ZYClassLoader
* #Date: 2023-02-24 18:04
*/
//加载c:/test/下的class文件(c:/test/不在class.path下 所以AppClassLoader也加载不了 从硬盘读到内存) 并返回class对象
public class T03_ZYClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
//根据传进来的全路径名创建一个文件f
File f = new File("c:/test/",name.replaceAll(".","/").concat(".class"));
try{
//从文件里读出来f文件中的内容
FileInputStream fis = new FileInputStream(f);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int b = 0;
while((b=fis.read())!=0){
//把文件内容写进内存中 (即把硬盘中的class文件加载进内存中)
baos.write(b);
}
byte[] bytes = baos.toByteArray();
baos.close();
fis.close();
//使用defineClass(class文件名,class文件中的二进制代码,offset起始,offset终止)方法把二进制字节数组转换为class对象
return defineClass(name,bytes,0,bytes.length);
}catch (Exception e){
e.printStackTrace();
}
return super.findClass(name);
}
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
ClassLoader l = new T03_ZYClassLoader();
Class<?> clazz = l.loadClass("全类名");
//用反射去创建对象 (通过class对象创建对象) 正常来说 都是先创建对象 隐式的把类加载进内存 然后生成class对象 但是反射就是先把class文件加载进内存 生成class对象 再通过class对象来new对象
Object o = clazz.newInstance();
o.toString();
System.out.println(o.getClass().getClassLoader());
System.out.println(l.getParent());
}
}
加密class文件:
通过自定义ClassLoader可以给class文件加密,不让别人反编译。
比如下面这个case,我们从c:/test中读取到class文件,并先进行一次异或加密(模仿的场景时加密的class文件,这里用来疑惑的整数就是密钥),然后在我们的自定义类加载器中,用密钥进行二次异或,即解密。这样就实现了别人无法反编译我们的class文件(因为class文件被一次异或加密过),只有我们的类加载器能够加载这个class文件并返回class对象 使其能够被正常使用(因为我们的类加载器持有密钥)。
package day02.example;
import java.io.ByteArrayOutputStream;
import java.io.File;
import java.io.FileInputStream;
/**
* @author zhaoyu
* #Description T03_ZYClassLoader
* #Date: 2023-02-24 18:04
*/
//加载c:/test/下的class文件(c:/test/不在class.path下 所以AppClassLoader也加载不了 从硬盘读到内存) 并返回class对象
public class T03_ZYClassLoader extends ClassLoader {
@Override
protected Class<?> findClass(String name) throws ClassNotFoundException {
//根据传进来的全路径名创建一个文件f
File f = new File("c:/test/",name.replaceAll(".","/").concat(".class"));
try{
//从文件里读出来f文件中的内容
FileInputStream fis = new FileInputStream(f);
ByteArrayOutputStream baos = new ByteArrayOutputStream();
int b = 0;
while((b=fis.read())!=0){
//把文件内容写进内存中 (即把硬盘中的class文件加载进内存中)
baos.write(b);
}
byte[] bytes = baos.toByteArray();
baos.close();
fis.close();
//使用defineClass(class文件名,class文件中的二进制代码,offset起始,offset终止)方法把二进制字节数组转换为class对象
return defineClass(name,bytes,0,bytes.length);
}catch (Exception e){
e.printStackTrace();
}
return super.findClass(name);
}
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
ClassLoader l = new T03_ZYClassLoader();
Class<?> clazz = l.loadClass("全类名");
//用反射去创建对象 (通过class对象创建对象) 正常来说 都是先创建对象 隐式的把类加载进内存 然后生成class对象 但是反射就是先把class文件加载进内存 生成class对象 再通过class对象来new对象
Object o = clazz.newInstance();
o.toString();
System.out.println(o.getClass().getClassLoader());
System.out.println(l.getParent());
}
}
编译器:
class文件->load进内存->解释执行
Java语言既是一个解释型语言,又是一个编译型语言。
默认java是混合模式(-Xmixed 默认为混合模式):默认先将字节码文件解释执行(字节码文件指示一种中间文件,这里jvm有自己的jvm字节码指令集,会逐行解释执行字节码文件),如果发现有一段代码的执行频率特别高,就把这段代码编译成对应平台的机器码(字节码->机器码),降来执行这段代码的时候就不用解释了 直接执行。
这就是混合使用解释器(bytecode interpreter) + 热点代码编译(JIT Just In-Time compiler)
起始阶段采用解释执行,后续会进行热点代码检测
热点代码的定义:1.多次被调用的方法(方法计数器:检测方法的执行频率)2.多次被调用的循环(循环计数器:检测循环的执行频率)。
以此判断出哪些代码属于热点代码并进行编译
如果单纯使用编译模式,每次运行程序前都需要把整个文件编译完了再执行的话,如果文件很大,每次执行前都要等很久的时间。
- -Xmixed:混合模式(默认)启动速度较快,还会有JIT对热点代码进行实时监测和编译
- -Xint:使用纯解释模式 启动很快 执行稍慢
- -Xcomp:使用纯编译模式 执行很快 启动稍慢
编译:把高级语言代码翻译成二进制代码
javac的编译:把高级程序语言翻译成字节码(虽然字节码也是二进制代码,但是需要通过查找JVM的操作表才能翻译成机器指令,即机器码)
JIT的编译:把字节码翻译成机器码(CPU可以直接解读的代码)
ps:hotSpot的意思就是热点监测,即它本身的含义就是支持混合模式
如果没有JIT编译的话,一个方法要循环10000次,每次都是纯解释的话 会非常的慢。
但是如果纯编译的话,在程序跑之前要等很长时间的编译,不过编译后就会跑的很快了。对于频繁停止启动/修改的代码这样也不好。
JVM的懒加载模式:
JVM并不是一开始在启动程序的时候就把所有的类,相关的类库都加载进内存的,这样内存也根本承载不了。
Class File -> Class Loader -> JVM运行时数据区(方法区、本地方法栈、Java虚拟机栈、堆、程序计数器)-> 运行时数据区可以调用本地方法库
是不是所有的Class文件都会在程序启动的时候被全部加载呢?不是
Java当中类的分类:1.系统类 jdk自带的类 2.拓展类 eg:对接mysql的类 3.自己写的类 即应用类
不同的类会被不同的类加载器加载,根据类加载器的加载流程,已经被加载到内存中的类不会被反复加载。
正因为核心类库的类只能被启动类加载器加载,并且已经被加载过的类不会被再次加载,java通过这种方式来保证核心类库的类不会被用户覆盖。(配合双亲委派机制,就算用户想写一个核心类库的重名类 比如String,在从顶到下加载的过程中,也只会加载jdk中预定义的String类,从而不会被用户的恶意代码覆盖)

JVM是懒加载的,还用不到的类是不加载的。
eg:Demo2 demo2 = null 这个赋空值的Demo2是不加载的
JVM会先把保证程序运行的基本类都加载到JVM中,剩下的类等用到了再加载。
Part 2总结
Part2包含的内容有:
- Loading 双亲委派机制(从下到上判断是否加载过该类,再从上到下委托加载)
- 为什么需要双亲委派机制(出于安全考虑)
- ClassLoader源码
- 如何自定义ClassLoader(模板模式 继承ClassLoader 重写findClass方法 使用defineClass方法把byte[]字节码->Class clazz class对象)
- JVM的混合模式(JIT编译+解释器) JVM的懒加载
ps:类对象(class对象),存在metaSpace(方法区)中。
Part 3预告
class -> loading -> linking(verification -> preparation -> resolution) -> initializing -> GC
上述类生命周期中的:
- Linking(Verification -> Preparation -> Resolution)
- Initializing
Part 3
Part 2复习
- class文件 -> loading 双亲委派机制 -> linking(verification -> preparation静态变量赋初始值 -> resolution) -> initializing静态变量赋值。
- 自定义ClassLoader:模板方法,继承ClassLoader 重写findClass方法 利用defineClass方法返回class对象。
- 双亲委派机制:每个ClassLoader中的parent属性指定了上一层的ClassLoader,不是继承关系。双亲委派机制的模型在ClassLoader类的loadClass方法中已经被写死了,建立双亲委派机制的初衷是为了安全考虑。
- ps:private final ClassLoader parent;就算我们的自定义ClassLoader中没通过传入parent来构造自定义ClassLoader对象,这个Custom ClassLoader的父加载器默认还是AppClassLoader,这主要是因为在创建子类对象的时候,会调用父类的构造方法,在父类ClassLoader的构造方法中设置了parent属性为加载当前类的类加载器(而加载我们自己写的类的类加载器就是AppClassLoader)
- 怎么手动给自定义ClassLoader指定父加载器?在自定义的类加载器中创建一个入参带ClassLoader parent属性的构造方法
package day03.example;
import day02.example.T03_ZYClassLoader;
/**
* @author zhaoyu
* #Description T01_Parent
* #Date: 2023-02-25 13:47
*/
public class T01_Parent {
private static T03_ZYClassLoader parent = new T03_ZYClassLoader();
private static class MyLoader extends ClassLoader{
public MyLoader(){
//指定这个自定义加载器的父加载器为自定义加载器T03_ZYClassLoader 如果不指定的话 就是AppClassLoader
super(parent);
}
}
}
- 如何打破双亲委派机制?重写ClassLoader中的loadClass方法。在loadClass方法中写死了双亲委派机制,并调用了findClass方法来得到class对象(具体是findClass中调用了defineClass来得到class对象)。findClass主要是根据class文件路径找到类文件,然后把字节码文件的内容加载进内存,根据字节码文件的内容返回class对象是defineClass的主要工作。
- 什么时候需要打破双亲委派机制?1.JDK 1.2之前,还没有findClass模板方法,自定义ClassLoader都必须重写loadClass()方法 2.ThreadContextClassLoader可以实现基础类调用实现类代码 通过thread.setContextClassLoader指定 3.热启动、热部署:osgi tomcat都有自己的模块指定classLoader(可以加载同一类库的不同版本)
- JVM是默认解释和JIT编译混合执行的,也可以通过参数指定为纯编译执行,或者纯解释执行。
初始化
loading讲完了之后,我们来看linking。
linking分为:verification -> preparation -> resolution
- verification:验证加载进来的class文件是否符合JVM规定 eg:前4个字节是不是CAFE BABE
- preparation:给静态成员变量赋默认值 eg:static int i = 8; 静态变量i在这一步被赋初始值为0(注意,实例对象被赋值的阶段不在类加载的时候,而是在对象创建的时候。)
- resolution:将类、方法、属性等符号引用解析为直接引用,即将各种引用解析为指针、偏移量等内存地址的直接引用。
loading之后的initializing:给静态变量赋初始值static int i = 8; i在这一步被赋值为8
一道面试题:体现了对象的半初始化过程
package day03.example;
/**
* @author zhaoyu
* #Description T02_ClassLoadingProcedure
* #Date: 2023-02-25 14:11
*/
public class T02_ClassLoadingProcedure {
public static void main(String[] args) {
//T.count是几?
System.out.println(T.count); //2
//当我们调用T.count的时候 ClassLoader把T load到内存 在linking的preparation部分 t是null count是0
//initializing给这些值赋初始值 先给t赋初始值 在调用构造方法的时候 count++为1 然后赋初始值count=2
//如果public static int count = 2;public static T t = new T(); 按这个顺序 输出的就是3
}
static class T{
public static T t = new T();
public static int count = 2;
private T(){
count++;
System.out.println("--"+count); //--1
}
}
}
ps:出了类加载时候对静态变量的赋值分两步 1.默认值 2.初始值。创建对象的时候,对对象中的成员变量的赋值也分为两步 1.赋默认值 2.赋初始值 (为什么要这么设计?为了安全)
小总结:
总而言之:
load -> 静态变量赋默认值 -> 静态变量赋初始值
new -> 申请内存 -> 成员变量赋默认值 -> 成员变量赋初始值
单例模式 双重检查
DCL单例(Double Check Loading)
package day03.example;
import java.util.concurrent.ConcurrentHashMap;
/**
* @author zhaoyu
* #Description T03_DCL
* #Date: 2023-02-25 14:27
*/
//DCL Double Check Loading
//lazy loading 懒汉式加载 虽然达到了按需初始化的目的 但也带来了线程不安全的问题 可以通过synchronized解决 但也带来效率下降
public class T03_DCL {
private static volatile T03_DCL instance;
ConcurrentHashMap chm = null;
public static T03_DCL getInstance(){
//业务逻辑代码省略 如果不为null 就不用加锁new了 直接返回
//这一层检查的主要目的是减少锁的争用
if(instance==null){
//双重检查
synchronized (T03_DCL.class){
//为什么要进行这次检查? 害怕第一次检查到加锁期间 这个instance被别的线程初始化了
if(instance==null){
try{
Thread.sleep(1000);
}catch (InterruptedException e){
e.printStackTrace();
}
instance = new T03_DCL();
}
}
}
return instance;
}
}
为什么要给instance属性加volatile关键字?禁止指令重排序
如果不加volatile,指令可能会发生重排序。举个例子:线程1挣抢到了这个锁,执行new T03_DCL()创建对象,此时发生了指令重排序,当这个初始化T03的动作做到一半时(即到了instance半初始化为默认值的之后),这个时候另一个线程2来判断,instance对象不为空了(线程2不知道线程1是在半初始化状态还是初始化完成了),直接就返回了instance对象,而这个instance对象中的属性值都是默认值(因为没完成初始化动作)。
具体来说:
在上面的代码中,instance = new T03_DCL();这行代码并非原子操作,它可以分解为以下几个步骤:
- 分配内存空间。
- 初始化对象。
- 将instance指向分配的内存地址。
如果没有volatile关键字,编译器可能会对这些指令进行重排序,导致第三步在第二步之前执行。这种情况下,如果有另一个线程在第三步执行完毕,但第二步尚未执行时进入第一个检查,它将看到instance不为null并返回一个尚未完全构造的对象。
再举一个例子:Object o = new Object();
0 new #2 申请内存空间
3 dup
4 invokespecial #3 调用构造方法,为对象中的成员变量赋初始值
7 astore_1 把o引用指向这个对象的这片内存空间
8 return
我们加volatile关键字就是为了防止astore_1和invokespecial发生了指令重排序(只要是不会对单线程的执行结果发生影响的指令都可能会发生重排序,所以这两条指令是可能发生重排序的)
硬件层数据一致性
JMM: Java Memory Model Java内存模型
硬件层的并发优化基础知识:
存储器的层次结构:
L0 寄存器 -> L1 高速缓存(cache,每个CPU独享) -> L2 高速缓存(cache,每个CPU独享) -> L3 高速缓存(所有的CPU共享)-> L4 主存 -> L5 磁盘 -> L6 远程文件存储
从上到下存储容量更大,速度更慢,成本更低。从下往上存储容量更小,速度更快,价格越高。总结来说就是离CPU越近,速度越快,容量越小,价格越高。
CPU为了提高计算效率,按照空间局部和时间局部的原则,每次去内存中取数据不会只取那一条,而是取一个cache line放到cache中。
这样的话,如果不同的CPU把同一个cache line放到自己独享的缓存中,一个CPU中的线程把自己的混存中cache line中的数据改了,此时数据不一致了,另一个CPU中的线程怎么知道呢?
为了解决这个问题,缓存一致性协议就应运而生了。
硬件层面具体怎么解决呢?
1.锁总线 每次只让一个CPU中的线程访问内存,其他CPU中的线程不允许访问内存。老的CPU是这样的,但是效率很低。
2.新的CPU通过各种各样的一致性协议来保证缓存之间的数据一致性。eg:MESI Cache一致性协议,给每一个缓存行做了一个相比于数据在主存中原内容的标记(Modify Exclusive Shared Invalid)
eg:CPU1的缓存行 CPU2中的一个线程修改了CPU2缓存中相同的缓存行,就把CPU1的缓存行的状态置为invalid。
MESI协议的目的是让不同CPU中的相同缓存行能够保持一致性,如果有失效的cache line,就到内存中去重新读。
MESI被称为缓存锁,但是对于有些无法被缓存的数据(数据特别大)或者跨越多个缓存行的数据,还是需要总线锁来保证数据的一致性。
现在CPU的数据一致性是通过缓存锁(eg:MESI缓存一致性协议可以实现)+总线锁来实现的
缓存行 伪共享
eg:int i = 12; 4字节的i,CPU为了提高效率,不会只把i读到cache里,而是会把一个64字节的cache line的内容都读进来。
缓存行虽然本意上是为了提高CPU效率,但是因为缓存一致性协议的存在,有时候会出现诡异的效率降低问题:@Contented 之后多线程会举这个例子。
伪共享:位于同一缓存行的两个不同数据,被两个不同CPU锁定,两个CPU使用的是同一个缓存行中的不同数据,本身不置缓存失效也没关系,但是由于缓存一致性协议,反而导致效率降低的问题。
硬件层的数据一致性就聊到这里。
乱序问题(指令重排序):
CPU的指定重排序也是为了提高执行效率。只要不影响单线程下的最终一致性,指令就可以乱序执行。
指令重排序的例子我们也放到多线程中一起举。
硬件级别如何保证指令有序:
我们知道,volatile关键字可以预防指令重排序问题,它是如何做到的呢?
它是通过硬件层面的汇编指令:fence(CPU级别的内存屏障,不是JVM级别的内存屏障)来做到的。
内存屏障后的指令不能和内存屏障前的指令交换顺序。
JVM级别的内存屏障:
JVM规范要求实现的4个内存屏障(需要依赖于硬件来具体实现):
- RRBarrier
- RWBarrier
- WWBarrier
- WRBarrier
硬件级别的lock指令也可以实现有序性。
Part 3总结
- ClassLoader遗留问题(如何制定父类加载器,如何打破双亲委派机制)
- Linking(verification -> preparation -> resolution)
- 类加载/对象创建时候的半初始化问题
- DCL单例
- 缓存行
- volatile如何保证有序性
ps:线程的工作缓存是根据JVM虚拟机具体实现决定的(JMM只是个规范 CPU -> 工作缓存1 -> 工作缓存2 -> … -> 主存),这个工作缓存的实现可以是CPU高速缓存的抽象,甚至可以是物理内存的一部分,具体要看虚拟机是怎么实现的。















 974
974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









