







简介:
Hadoop为分布式系统框架,本文章将讲述搭建入门级Hadoop分部署集群(请注意,本文是高可用HA模式的Hadoop集群):
- HDFS
- MapReduce
- YARN
- Zookeeper
入门级分布式集群搭建
1、前期准备
1.1 虚拟机
tips:这个软件是收费的,所以各显神通吧
1.2 软件
- Linux,推荐 centOS 。
【此版本为centOS-7.9版本,点我直接现在,来源为清华大学镜像网站资源】 - jdk 1.8
- Hadoop 2.8.1
- XShell ,非常好用的远程连接终端,有个人免费版
- Xftp ,文件管理的,上传下载非常方便,同样有个人免费版
tips:关于开源方面,开源的项目直接GitHub,开源宝库;
开源软件资源方面,主推阿里云镜像:https://developer.aliyun.com/
另外清华大学的镜像网站个人感觉非常棒:https://mirrors.tuna.tsinghua.edu.cn/
1.3 虚拟机准备
- 利用上诉条件安装成功后,使用VMware创建5台虚拟机(奇数),
1.3.1 修改主机名
vim /etc/hostname # 将其修改为你期望的主机名

1.3.2 添加主机名映射
vim /etc/hosts
192.168.134.20 ha
192.168.134.21 ha1
192.168.134.22 ha2
192.168.134.23 ha3
192.168.134.24 ha4

1.3.3 修改IP
vim /etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static /不适用动态IP,修改为静态
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=04433d28-9172-406e-81fa-ff56d248bed2
DEVICE=ens33
ONBOOT=yes #启动生效
IPADDR=192.168.134.20 # 当前主机IP
GATEWAY=192.168.134.2 # 网关
NETMASK=255.255.255.0 # 子网掩码
DNS1=114.114.114.114 # DNS
DNS2=8.8.8.8

2、配置环境
2.1 jdk安装与环境变量
# 软件安装-二进制解压
tar -zxvf [jdk压缩包] -C [解压的目标目录]
# 如:
tar -zxvf jdk-8u45-linux-x64.tar.gz -C /opt/apps/
# 环境变量
vim /etc/profile
# 命令模式下G切到文件末尾,在后面添加如下变量,其作用可以见名知意
export JAVA_HOME=/opt/apps/jdk1.8.0_45
export HADOOP_HOME=/opt/apps/hadoop-2.8.1
export ZK_HOME=/opt/apps/zookeeper-3.4.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
expor tPATH=$PATH:$ZK_HOME/bin
export CLASS_PATH=.:$JAVA_HOME/lib
# 编译配置文件
source /etc/profile
# 检验是否配置成功,也可以用java,javac,java -version来检查
echo $JAVA_HOME

2.2 免密登录
# 使用ssh设置免密登录
ssh-keygen # 生成密钥对
ssh-copy-id [IP]# 发送公钥
ssh [ip] # 使用ssh登录到IP为[ip]的主机
2.3 关闭防火墙
systemctl status firewalld # 查看防火墙状态
systemctl stop firewalld # 关闭
systemctl disable firewalld # 禁用-下次开机后不会启动防火墙
3、安装Hadoop
3.1 解压
- 上面已经示例了解压基本用法,这里不再赘述
3.2 环境变量
- 如果你细心的话就会发现,在配置Java环境变量时其实已经将所需的环境变量都配好了
3.3 Hadoop配置文件
重头戏来了
3.3.1 core-site.xml
cd $HADOOP_HOME/etc/hadoop

vim core-site.xml # 添加以下内容
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns</value>
</property>
<!-- 日志 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/apps/hadoop-2.8.1/hdpdata/journal/node/local/data</value>
</property>
<!-- hdpdata目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/apps/hadoop-2.8.1/hdpdata/</value>
</property>
<!-- 日志管理器 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>ha2:2181,ha3:2181,ha4:2181</value>
</property>

3.3.2 hdfs-site.xml
<configuration>
<!-- ha服务名称 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ha服务对应两个namenode的名称 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- ha服务对应两个namenode的名称和指定服务器进行绑定 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>ha:9000</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>ha1:9000</value>
</property>
<!-- ha服务对应两个namenode的名称和指定服务器的webui进行绑定 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>ha:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>ha1:50070</value>
</property>
<!-- ha服务指定namenode上传或下载日志的url -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ha2:8485;ha3:8485;ha4:8485/ns</value>
</property>
<!-- ha服务自动故障转移的底层的实现类 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- ha服务的补刀策略 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 开启自动故障迁移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
3.3.3 slaves
- 这里配置的是你要搭建zookeeper的主机名,你也可以使用IP,由于我们在hosts文件中配置过了主机名映射,所以在这里直接使用主机名,也方便排错
3.3.4 mapred-site.xml.template
- 持续更新中
3.3.5 yarn-site.xml
- 持续更新中
4、安装Zookeeper
- 解压、环境变量
4.1 配置文件
进入zookeeper安装目录
cd $ZK_HOME

4.1.1 创建zkdata文件夹
# 在当前目录即zookeeper安装目录下创建
mkdir zkdata
# 进入zkdata目录创建myid文件并添加服务器编号
[root@ha2 zkdata]# vim myid
# 文件内容
1
请注意:这里每台zookeeper服务器的编号是不一样的,比如我配置了三台zookeeper服务器,那么编号应该分别为1,2,3;当然,其实这个数字没什么意义,重要的是要然后与zoo.cfg配置文件中的server.1上的数字对应,往下看

4.1.1 zoo.cfg
- 在安装目录下有一个conf目录,cd进入,这里面会有一个zoo_sample.cfg的文件,将其重命名为zoo.cfg
[root@ha conf]# rename zoo_sample.cfg zoo.cfg zoo_sample.cfg

2. 修改文件内容
dataDir=/opt/apps/zookeeper-3.4.5/zkdata
server.1=ha2:2888:3888
server.2=ha3:2888:3888
server.3=ha4:2888:3888

5、启动
5.1 启动zookeeper
zkServer.sh start #启动
zkServer.sh status # 查看状态
zkServer.sh stop # 停止
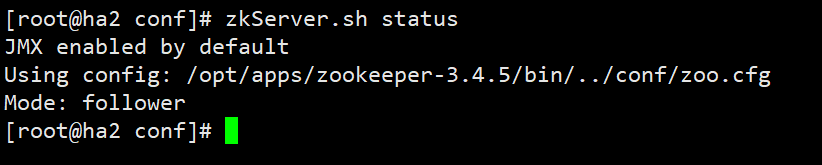
tips:出现mode时即启动成功启动zookeepe
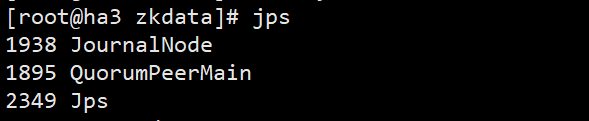
5.2 启动journalnode
hadoop-daemon.sh start journalnode
tips:journalnode需要zookeeper环境,所以注意启动顺序
5.3 格式化namenode与zkfc
hdfs namenode -format
hdfs zkfc -formatZK
5.4 启动hdfs
start-dfs.sh
- 当看到:三台datanode与zookeeper服务器出现
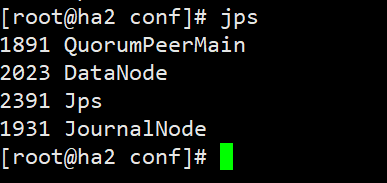
- namenode服务器上
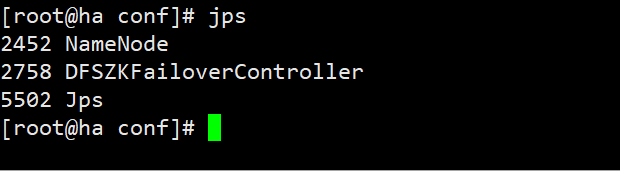
- 访问主节点的IP



即为成功,搞定收工。
感谢你的浏览,觉得有帮助可以收藏,会持续学习并更新














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









