







String 字符串函数常见用法
字符串倒置
// 方式1:
#include <algorithm>
reverse(str1.begin(),str1.end());
// 方式2:
void revers()
{
int c=getchar();
if(c!='\n')
revers();
putchar(c);
}
//方式1的reverse方法可以实现类似“China”字符串的倒置输出的,但是对于“I love my nation”的倒置输出就无能为力了
//方式2的reverse不但可以完成第一个搞定的,而且可以搞定甚至是字符句子,Like:I love you!的倒置输出!!
//请看下面:
#include <iostream>
int main()
{
void revers();
revers();
printf("\n");
return 0;
}
// substr有2种用法:
假设:string s = "0123456789";
string sub1 = s.substr(5); //只有一个数字5表示从下标为5开始一直到结尾:sub1 = "56789"
string sub2 = s.substr(5, 3); //从下标为5开始截取长度为3位:sub2 = "567"
s.find(c); //在字符串s中查找第一个字符c或子串的位置,返回下标,如果没有返回string::npos
cout<<s.find("123"); // 0
cout<<(s.find("999")==string::npos); // 1
erase()函数
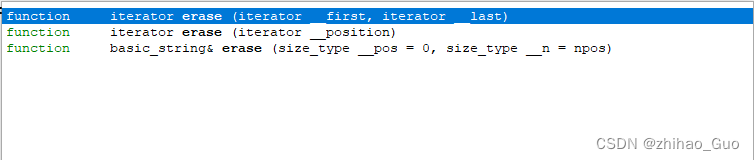
string s = "123456";
it = s.begin();//返回s的首字符的指针(迭代器)
s.erase(it); //在字符串中删除指针it所指向的字符 s.begin();
s.erase(0); //删除下标0的字符
s.erase(0,3)// 删除从下标0开始的三个字符
字符串转数字
atoi(line) // 将字符串转换成int
atof(line) // 将字符串转换成double
常用库函数
C++中有一些库函数
#include <algorithm>中包含:
1.求较大值
int _MAX(int a,int b);
2.求数组中元素的最小值
* min_element(maxLen+1,maxLen+N+1);
//第一个maxLen+1=maxLen[1],第二个maxLen+N+1等于maxLen[N]
3.求数组中元素的最大值
* max_element(maxLen+1,maxLen+N+1);
//第一个maxLen+1=maxLen[1],第二个maxLen+N+1等于maxLen[N]
3.求数组中元素的第k小值
nth_element(a,a + k, a + n)
第k个数有序,前面皆小于或等于它,后面皆大于或等于它,k从0开始
求数组中元素的第k大值(k从0开始)
nth_element(a, a + k, a + n, cmp); 需自定义比较函数
nth_element(a, a + k, a + n, greater<int>())
sort(数组名+n1,数组名+n2);
将数组中下标范围为[n1,n2)的元素从小到大排序,下标n2的元素不在排序的区间内
sort(数组名+n1,数组名+n2,greater<T>());对元素类型为T的基本数组从大到小排序
int a[]={15,4,3,9,2,7,6}
例如 sort(a+1,a+4,greater<int>());
例题
A.整数排序
单点时限:2.0 sec
内存限制:512MB
题面
输入若干个int类型整数,将整数按照位数由大到小排序,如果位数相同,则按照整数本身从小到大排序。例如,
输入:10 -3 1 23 89 100 9 -123
输出:-123 100 10 23 89 -3 1 9
输入的整数个数最多不超过个。
输入格式
在一行中输入若干个整数,整数之间用一个空格分隔。
输出格式
在一行中输出排序好的整数,整数之间用一个空格分隔。
样例
input
10 -3 1 23 89 100 9 -123
ouput
-123 100 10 23 89 -3 1 9
input
1 -2 12
ouput
12 -2 1
1.这是一类经典的条件排序问题,它就是排序问题的小变形。由于题目说明了数组长度n = 。所以就不要自己写冒泡排序等比较慢的排序了。在C++可直接使用STL中的排序函数函数:sort()。
2.就算是你会手写快排,也不建议这么做。因为一方面是比赛的时候浪费时间,另一方面是STL中的sort加了很多优化,它比你手写的快排还会更快。
使用方法
// 1.需要的头文件
#include <algorithm>
// 如果不想记这么多繁杂的头文件,你永远可以相信<万能头文件>,它包罗万象了,至少各种比赛,机试是够用的。
#include <bits/stdc++.h>
// 2.sort的使用方法
sort (起始地址,结束地址的下一位,自定义排序函数的函数名)
// 起始/结束地址:传入对应的指针,一定要注意是结束的地址的下一位!
// 自定义排序函数:告诉sort函数将如何比较两个数,谁放在前面,谁放在后面。不传参时默认是升序排序。
// 3.具体案例1:给定一个整数数组a,我们希望对其下标为[l,r]的区域<升序>排序
sort(a + l , a + r + 1)
回到这道题,它的关键其实就是构造自定义排序函数。我们来展开讲一讲这一点。
//具体案例2:给定一个整数数组a,我们希望对其下标为[l,r]的区域<降序>排序
//这时我们可以自己构造一个自定义排序的函数cmp(函数名随意命名),然后将函数名填入第三个参数(这个在语法上叫做函数传参,本质是传递函数指针)
sort(a + l , a + r + 1 , cmp);
// 返回值为bool型,传入两个参数a , b
// 这个函数的作用是告诉sort函数将如何比较两个数。当返回true的时候将a放在b之前,返回false的时候将b放在a之前
bool cmp (const int& a , const int& b){
//if (a > b) return true;
//else return false;
//利用语法特性,直接返回逻辑表达式
return a > b;
}
// 更多解释:1.利用引用变量是为了加快速度,减少拷贝时间。2.使用const修饰是为了防止我们误改内容。
//所以你不加这两个,直接写int a , int b 也不会有问题,只是不规范罢了。
所以这题的关键就是构造自定义排序函数cmp。代码如下:
#include <bits/stdc++.h>
using namespace std;
struct Val{
int dig; // 数位长度
int val; // 数字
};
Val a[1000006];
// 获得数位长度
int getDig (int val){
val = abs(val);
int ans = 0;
while (val){
ans ++;
val /= 10;
}
return ans;
}
int cmp (const Val & a , const Val& b){
if (a.dig != b.dig)
return a.dig > b.dig;
return a.val < b.val;
}
int main() {
int x , n = 0;
while (cin >> x) {
a[++n].val = x;
a[n].dig = getDig(a[n].val);
}
sort(a + 1 , a + n + 1 , cmp);
for (int i = 1 ; i <= n ; i++){
cout << a[i].val;
if (i == n) cout << endl;
else cout << " ";
}
return 0;
}
B.位运算
单点时限:2.0 sec
内存限制:512MB
题面
给定一个int型整数x,将x的二进制表示中第i位和第j位的值互换。0 ≤ i , j ≤ 31
注意: x的二进制表示的最右边为第0位。
输入格式
在一行中输入三个整数,x , i , j , 整数之间用一个空格分隔。
输出格式
在一行中输出互换后的结果
样例
input
38 2 4
ouput
50
input
1 0 2
ouput
4
思路
思路很自然:获取二进制表示中的第i位与第j 位。之后将他们互换即可。
问题在于:实现方法很多
1.将其转化成二进制数组a,然后模拟swap(a[i] , a[j])后再转换回十进制数
2.利用位运算的技巧去做
第一步:获得二进制第i,j位置上的值。
具体的:将数右移i/j位然后将其与上1。
a = ( x > > i ) & 1
b = ( x > > j ) & 1
第二步:互换,具体的,
只有当a ≠ b 时才需要交换。而交换的结果就是取反即可。而取反我们可以利用<异或1>来完成。
if (a != b){
x ^= (1 << i);
x ^= (1 << j);
}
实现
#include <bits/stdc++.h>
using namespace std;
int main() {
int x , i , j;
cin >> x >> i >> j;
int a = (x >> i) & 1;
int b = (x >> j) & 1;
// 更简洁的表示方法,甚至可以省去判断
x ^= ((a ^ b) << i);
x ^= ((a ^ b) << j);
cout << x << endl;
return 0;
}
常见题型及模板
https://www.acwing.com/blog/content/405/
模拟
基本上每年都会有一道送分题,比如去年第一题就是写一个while循环对一个数反复操作,还有根据“1+1”一类的算式形式的字符串计算结果等等。但是也有比较复杂的模拟题,比如22年的罗马数字,如果根据这道题的题面条件,一步步模拟这些操作,是较为困难的,可以通过考虑打表来简化问题。
字符串
字符串主要还是和模拟相关的一些题目,建议大家平时多练练一些字符串的模拟题(回文字符串之类的),搞明白字典序,避免逻辑正确却写出来一些莫名其妙的bug。
字典序:字典序(dictionary order),又称 字母序(alphabetical order),原因是表示英文单词在字典中的先后顺序,在计算机领域中扩展成两个任意字符串的大小关系。
思维
去年机试有一道字符串相关的思维题,做思维题的时候不要想当然,建议拿纸笔好好推演一下能想到的情况,光凭脑子想是不够的。感觉一些比较简单的贪心题也可能会出现,平常可以在eoj、洛谷和codeforce等oj上找一些简单的思维题练练手。往年题目中比较难的思维题有一道叫蛇形矩阵,正解好像是能推出来公式,不过位置在最后一题,不建议大家死磕这种看似题面简单实则位置很靠后的题。
蛇形矩阵:https://leetcode.cn/problems/spiral-matrix/description/?envType=study-plan-v2&envId=top-100-liked
class Solution {
public:
int dirX[4] = {0,1,0,-1};
int dirY[4] = {1,0,-1,0};
vector<vector<bool>> visited;
int row,col;
vector<int> res;
vector<vector<int>> matrix;
void dfs(int curX,int curY,int preDir) {
// printf("curX:%d, curY:%d\n",curX,curY);
for(int i=0;i<4;i++) {
int nextX = curX + dirX[preDir];
int nextY = curY + dirY[preDir];
if(nextX<0 || nextX>= row || nextY<0 || nextY>=col ) {
// 越过矩阵,换个防线
preDir = (++preDir)%4;
continue;
}
if(visited[nextX][nextY]) {
// 已经访问过
preDir = (++preDir)%4;
continue;
}
visited[nextX][nextY] = true;
res.push_back(matrix[nextX][nextY]);
dfs(nextX,nextY,preDir);
}
}
vector<int> spiralOrder(vector<vector<int>>& matrix) {
this->matrix = matrix;
this->row = matrix.size();
this->col = matrix[0].size();
visited.resize(row,vector<bool>(col,false));
res.push_back(matrix[0][0]);
visited[0][0] = true;
dfs(0,0,0);
return res;
}
};
排序
诚然,尊贵的c++选手有一手sort,但是如果拿出大数(超过long long范围的整数),阁下将如何应对?光会调用sort是不够的,面对大数你需要写一个字符串排序(往年考过一次,这里不得不提python的好处…),解决一些贪心算法还需要自定义结构体排序,这些基本功大家都要好好练。
https://leetcode.cn/problems/custom-sort-string/description/
class Solution {
public:
string customSortString(string order, string s) {
sort(s.begin(),s.end(),[&](char &c1,char &c2){return order.find(c1)<order.find(c2);});
return s;
}
};
//优先队列的使用
头文件包含include<queue>
#include <iostream>
#include <queue>
#include <algorithm>
#define MAX_N 50010
using namespace std;
int N;
struct Cow{
int s;
int e;
int No;
bool operator < (const Cow & c)const{
return s<c.s;
}
}cows[MAX_N];
struct Stall{
int e;
int No;
bool operator < (const Stall &s)const{
return e>s.e;
}
Stall(int ee,int Noo):e(ee),No(Noo){};
};
int position[MAX_N];//position[i]代表编号为i的牛去挤奶栅栏的编号
priority_queue<Stall> q;
int main(){
scanf("%d",&N);
for(int i=1;i<=N;i++){
scanf("%d%d",&cows[i].s,&cows[i].e);
cows[i].No=i;
}
int total=0;
sort(cows,cows+N+1);
for(int i=1;i<=N;i++){
if(q.empty()){
total++;
q.push(Stall(cows[i].e,total));
position[cows[i].No]=total;
}
else{
Stall s=q.top();
if(cows[i].s>s.e){
q.pop();
q.push(Stall(cows[i].e,s.No));
position[cows[i].No]=s.No;
}
else{
total++;
q.push(Stall(cows[i].e,total));
position[cows[i].No]=total;
}
}
}
printf("%d\n",total);
for(int i=1;i<=N;i++){
printf("%d\n",position[i]);
}
return 0;
}
动态规划
“爬楼梯”这种经典的动态规划问题一定要会,结合去年压轴题的情况,建议认真学一下背包问题(记住二维形式就够了,有时间可以多了解一下滚动数组)
https://leetcode.cn/problems/climbing-stairs/description/
class Solution {
public:
int step[50];
int dfs(int num){
if(num ==2){
return 2;
}
if(num==1){
return 1;
}
if(step[num]){
return step[num];
}
if(num==1){
step[num] = 1;
return 1;
}
int res = dfs(num-1)+dfs(num-2);
step[num] = res;
return res;
}
int climbStairs(int n) {
for(int i=0;i<50;i++){
step[i] = 0;
}
return dfs(n);
}
};
质数筛
划重点!23机试两道题和筛有关!首先你要学会最朴素的筛法(好像对去年的数据范围来说也够用了),然后埃氏筛和线性筛里面选一个学明白,会用板子就好。
int primes[N], cnt; // primes[]存储所有素数
bool st[N]; // st[x]存储x是否被筛掉
void get_primes(int n)
{
for (int i = 2; i <= n; i ++ )
{
if (!st[i]) primes[cnt ++ ] = i;
for (int j = 0; primes[j] <= n / i; j ++ )
{
//每次都从最小的素数开始枚举
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
暴力
华师的机试是按点给分的,即按照你通过的测试点的数量给分。所以大家平常看到不会写的题时,可以尝试写一写暴力练手(不过平常在eoj刷题时好像是到错误测试点就停止评测了?不太记得了)。所谓暴力就是枚举每一种情况来找到正确答案,简单的可以大力for循环出奇迹,复杂一些的可能需要写dfs进行暴搜。枚举和搜索算法一定要会写!
低频考点
二分
我个人认为二分法是一个很实用的算法,可惜在华师往年题里很少出现(22年倒数第二题好像需要用二分的思想解决,不过那道题整体偏难)
图论
近几年没有考过,最可能考的应该是最小生成树和最短路(毕竟是408里的考点),这两类如果考的话记好板子应该就行(不至于考太复杂的应用
朴素dijkstra算法 —— 模板题 AcWing 849. Dijkstra求最短路 I
时间复杂是 O(n2+m), n 表示点数,m表示边数
int g[N][N]; // 存储每条边
int dist[N]; // 存储1号点到每个点的最短距离
bool st[N]; // 存储每个点的最短路是否已经确定
// 求1号点到n号点的最短路,如果不存在则返回-1
int dijkstra()
{
memset(dist, 0x3f, sizeof dist);
dist[1] = 0;
for (int i = 0; i < n - 1; i ++ )
{
int t = -1; // 在还未确定最短路的点中,寻找距离最小的点
for (int j = 1; j <= n; j ++ )
if (!st[j] && (t == -1 || dist[t] > dist[j]))
t = j;
// 用t更新其他点的距离
for (int j = 1; j <= n; j ++ )
dist[j] = min(dist[j], dist[t] + g[t][j]);
st[t] = true;
}
if (dist[n] == 0x3f3f3f3f) return -1;
return dist[n];
}
Kruskal算法 —— 模板题 AcWing 859. Kruskal算法求最小生成树
时间复杂度是 O(mlogm), n 表示点数,m 表示边数
int n, m; // n是点数,m是边数
int p[N]; // 并查集的父节点数组
struct Edge // 存储边
{
int a, b, w;
bool operator< (const Edge &W)const
{
return w < W.w;
}
}edges[M];
int find(int x) // 并查集核心操作
{
if (p[x] != x) p[x] = find(p[x]);
return p[x];
}
int kruskal()
{
sort(edges, edges + m);
for (int i = 1; i <= n; i ++ ) p[i] = i; // 初始化并查集
int res = 0, cnt = 0;
for (int i = 0; i < m; i ++ )
{
int a = edges[i].a, b = edges[i].b, w = edges[i].w;
a = find(a), b = find(b);
if (a != b) // 如果两个连通块不连通,则将这两个连通块合并
{
p[a] = b;
res += w;
cnt ++ ;
}
}
if (cnt < n - 1) return INF;
return res;
}
约瑟夫环
好像软院之前出过一道题,挺有意思的,大家可以抽空看一看
KMP
近几年没有考过,不过很多算法书上应该会有这部分内容,大家408都学过KMP的原理,但是可能代码接触的不是很多,可以记个板子
背包九讲
背包九讲
01背包问题
题目
有N件物品和一个容量为V的背包。第i件物品的费用是c[i],价值是w[i]。求解将哪些物品装入背包可使这些物品的费用总和不超过背包容量,且价值总和最大。
基本思路
这是最基础的背包问题,特点是:每种物品仅有一件,可以选择放或不放。
用子问题定义状态:即f[i][v]表示前i件物品恰放入一个容量为v的背包可以获得的最大价值。则其状态转移方程便是:f[i][v]=max{f[i-1][v],f[i-1][v-c[i]]+w[i]}。
这个方程非常重要,基本上所有跟背包相关的问题的方程都是由它衍生出来的。所以有必要将它详细解释一下:“将前i件物品放入容量为v的背包中”这个子问题,若只考虑第i件物品的策略(放或不放),那么就可以转化为一个只牵扯前i-1件物品的问题。如果不放第i件物品,那么问题就转化为“前i-1件物品放入容量为v的背包中”;如果放第i件物品,那么问题就转化为“前i-1件物品放入剩下的容量为v-c[i]的背包中”,此时能获得的最大价值就是f [i-1][v-c[i]]再加上通过放入第i件物品获得的价值w[i]。
注意f[i][v]有意义当且仅当存在一个前i件物品的子集,其费用总和为v。所以按照这个方程递推完毕后,最终的答案并不一定是f[N] [V],而是f[N][0…V]的最大值。如果将状态的定义中的“恰”字去掉,在转移方程中就要再加入一项f[i][v-1],这样就可以保证f[N] [V]就是最后的答案。至于为什么这样就可以,由你自己来体会了。
优化空间复杂度
以上方法的时间和空间复杂度均为O(N*V),其中时间复杂度基本已经不能再优化了,但空间复杂度却可以优化到O(V)。
先考虑上面讲的基本思路如何实现,肯定是有一个主循环i=1…N,每次算出来二维数组f[i][0…V]的所有值。那么,如果只用一个数组f [0…V],能不能保证第i次循环结束后f[v]中表示的就是我们定义的状态f[i][v]呢?f[i][v]是由f[i-1][v]和f[i-1] [v-c[i]]两个子问题递推而来,能否保证在推f[i][v]时(也即在第i次主循环中推f[v]时)能够得到f[i-1][v]和f[i-1][v -c[i]]的值呢?事实上,这要求在每次主循环中我们以v=V…0的顺序推f[v],这样才能保证推f[v]时f[v-c[i]]保存的是状态f[i -1][v-c[i]]的值。伪代码如下:
for i=1…N
for v=V…0
f[v]=max{f[v],f[v-c[i]]+w[i]};
其中的f[v]=max{f[v],f[v-c[i]]}一句恰就相当于我们的转移方程f[i][v]=max{f[i-1][v],f[i- 1][v-c[i]]},因为现在的f[v-c[i]]就相当于原来的f[i-1][v-c[i]]。如果将v的循环顺序从上面的逆序改成顺序的话,那么则成了f[i][v]由f[i][v-c[i]]推知,与本题意不符,但它却是另一个重要的背包问题P02最简捷的解决方案,故学习只用一维数组解01背包问题是十分必要的。
总结
01背包问题是最基本的背包问题,它包含了背包问题中设计状态、方程的最基本思想,另外,别的类型的背包问题往往也可以转换成01背包问题求解。故一定要仔细体会上面基本思路的得出方法,状态转移方程的意义,以及最后怎样优化的空间复杂度。
P02: 完全背包问题
题目
有N种物品和一个容量为V的背包,每种物品都有无限件可用。第i种物品的费用是c[i],价值是w[i]。求解将哪些物品装入背包可使这些物品的费用总和不超过背包容量,且价值总和最大。
基本思路
这个问题非常类似于01背包问题,所不同的是每种物品有无限件。也就是从每种物品的角度考虑,与它相关的策略已并非取或不取两种,而是有取0件、取1件、取2件……等很多种。如果仍然按照解01背包时的思路,令f[i][v]表示前i种物品恰放入一个容量为v的背包的最大权值。仍然可以按照每种物品不同的策略写出状态转移方程,像这样:f[i][v]=max{f[i-1][v-kc[i]]+kw[i]|0<=kc[i]<= v}。这跟01背包问题一样有O(NV)个状态需要求解,但求解每个状态的时间则不是常数了,求解状态f[i][v]的时间是O(v/c[i]),总的复杂度是超过O(VN)的。
将01背包问题的基本思路加以改进,得到了这样一个清晰的方法。这说明01背包问题的方程的确是很重要,可以推及其它类型的背包问题。但我们还是试图改进这个复杂度。
一个简单有效的优化
完全背包问题有一个很简单有效的优化,是这样的:若两件物品i、j满足c[i]<=c[j]且w[i]>=w[j],则将物品j去掉,不用考虑。这个优化的正确性显然:任何情况下都可将价值小费用高得j换成物美价廉的i,得到至少不会更差的方案。对于随机生成的数据,这个方法往往会大大减少物品的件数,从而加快速度。然而这个并不能改善最坏情况的复杂度,因为有可能特别设计的数据可以一件物品也去不掉。
转化为01背包问题求解
既然01背包问题是最基本的背包问题,那么我们可以考虑把完全背包问题转化为01背包问题来解。最简单的想法是,考虑到第i种物品最多选V/c [i]件,于是可以把第i种物品转化为V/c[i]件费用及价值均不变的物品,然后求解这个01背包问题。这样完全没有改进基本思路的时间复杂度,但这毕竟给了我们将完全背包问题转化为01背包问题的思路:将一种物品拆成多件物品。
更高效的转化方法是:把第i种物品拆成费用为c[i]*2k、价值为w[i]*2k的若干件物品,其中k满足c[i]*2k<V。这是二进制的思想,因为不管最优策略选几件第i种物品,总可以表示成若干个2k件物品的和。这样把每种物品拆成O(log(V/c[i]))件物品,是一个很大的改进。但我们有更优的O(VN)的算法。 * O(VN)的算法这个算法使用一维数组,先看伪代码:














 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









