







一.order by:
order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个Reducer,会导致当输入规模较大时,消耗较长的计算时间。
二.sort by:
sort by不是全局排序,其在数据进入reducer前完成排序,因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只会保证每个reducer的输出有序,并不保证全局有序。sort by不同于order by,它不受hive.mapred.mode属性的影响,sort by的数据只能保证在同一个reduce中的数据可以按指定字段排序。使用sort by你可以指定执行的reduce个数(通过set mapred.reduce.tasks=n来指定),对输出的数据再执行归并排序,即可得到全部结果。
三.distribute by:
distribute by是控制在map端如何拆分数据给reduce端的。hive会根据distribute by后面列,对应reduce的个数进行分发,默认是采用hash算法。sort by为每个reduce产生一个排序文件。在有些情况下,你需要控制某个特定行应该到哪个reducer,这通常是为了进行后续的聚集操作。distribute by刚好可以做这件事。因此,distribute by经常和sort by配合使用。
注:Distribute by和sort by的使用场景
1.Map输出的文件大小不均。
2.Reduce输出文件大小不均。
3.小文件过多。
4.文件超大。
四.cluster by:
cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是倒叙排序,不能指定排序规则为ASC或者DESC。
五.ROW_NUMBER() OVER函数的基本用法
语法:ROW_NUMBER() OVER(PARTITION BY COLUMNORDER BY COLUMN)
详解:
row_number() OVER (PARTITION BY COL1 ORDERBY COL2)表示根据COL1分组,在分组内部根据COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(该编号在组内是连续并且唯一的)。
场景描述:
在Hive中employee表包括empid、depid、salary三个字段,根据部门分组,显示每个部门的工资等级。
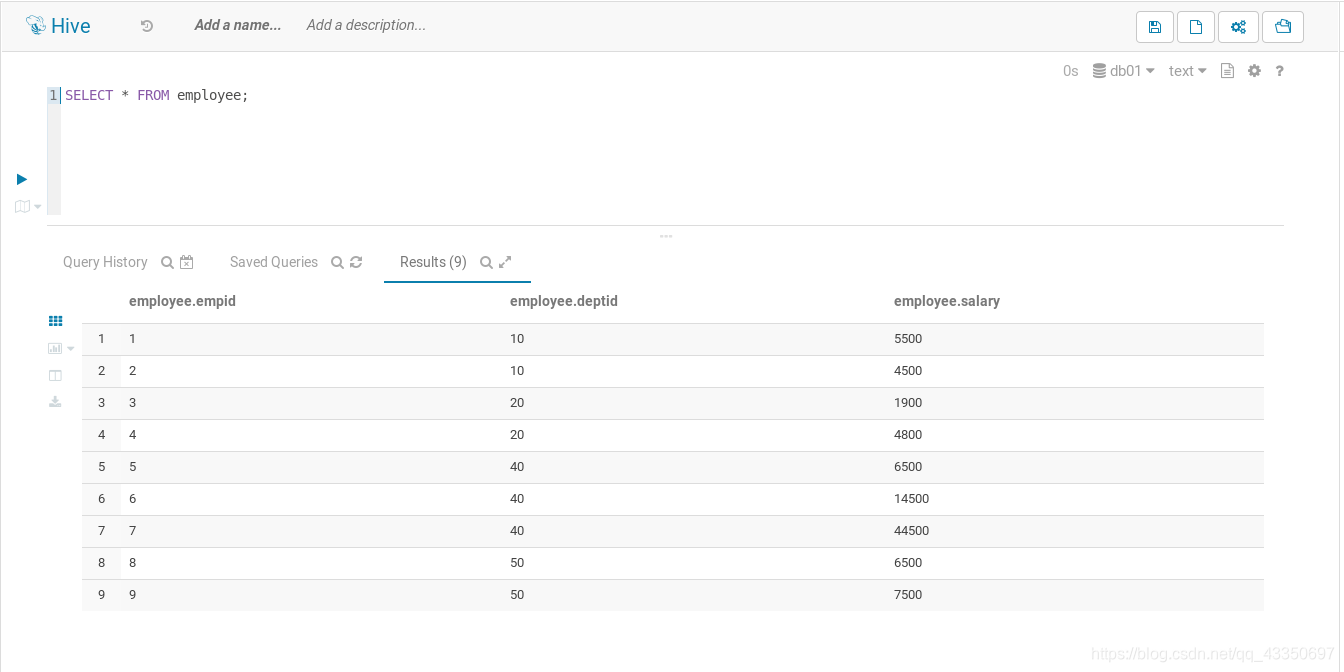
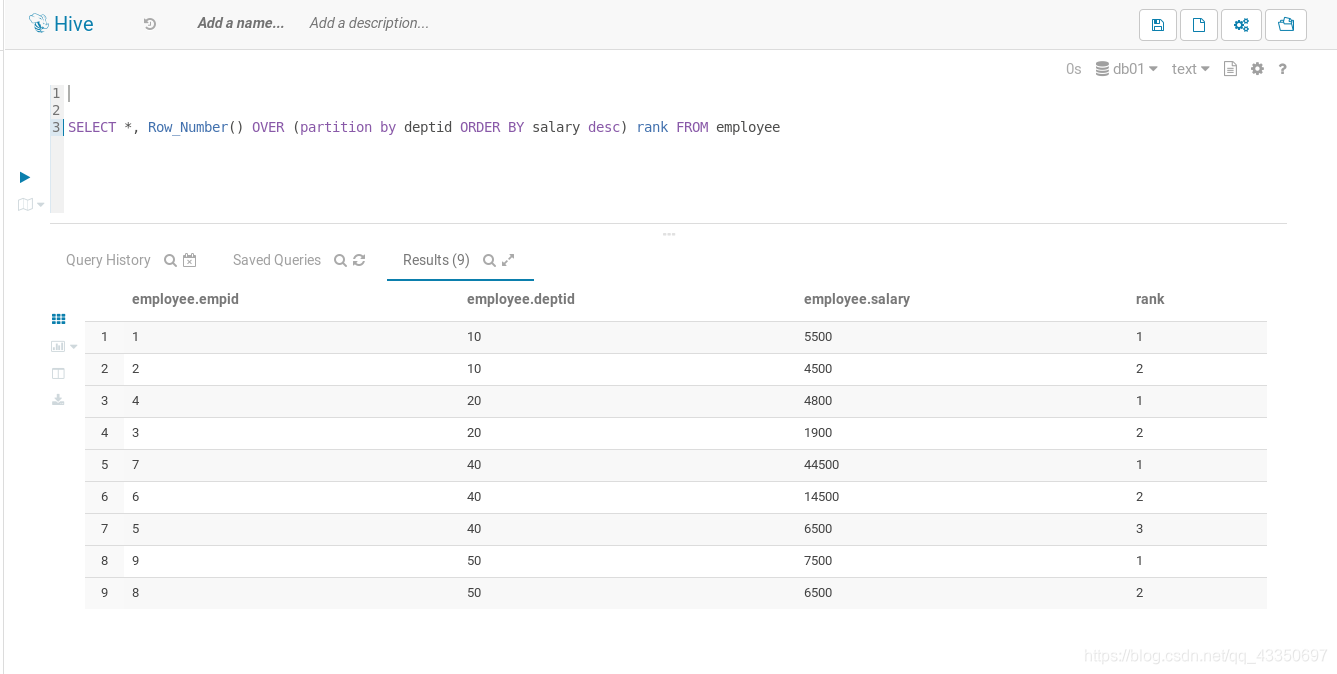














 643
643











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









