







文末也可直接获取实验文档,代码以及相关数据
机器学习实验四—基于朴素贝叶斯的wine数据集分类预测
1、 在NaiveBayes.py中定义朴素贝叶斯类,

2、 在类中定义方法
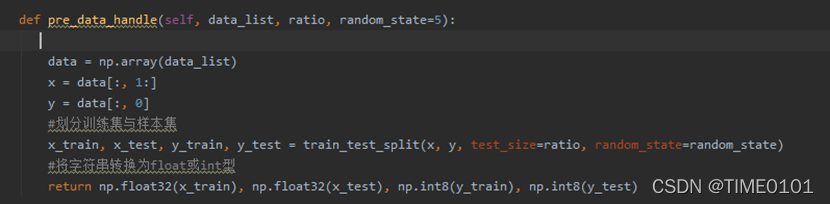
(1) 数据预处理
其中data_list是样本集,ratio是训练集与样本集的比例,random是随机种子。
数据预处理部分包括划分训练集与样本集,将字符串转换为float或int型。
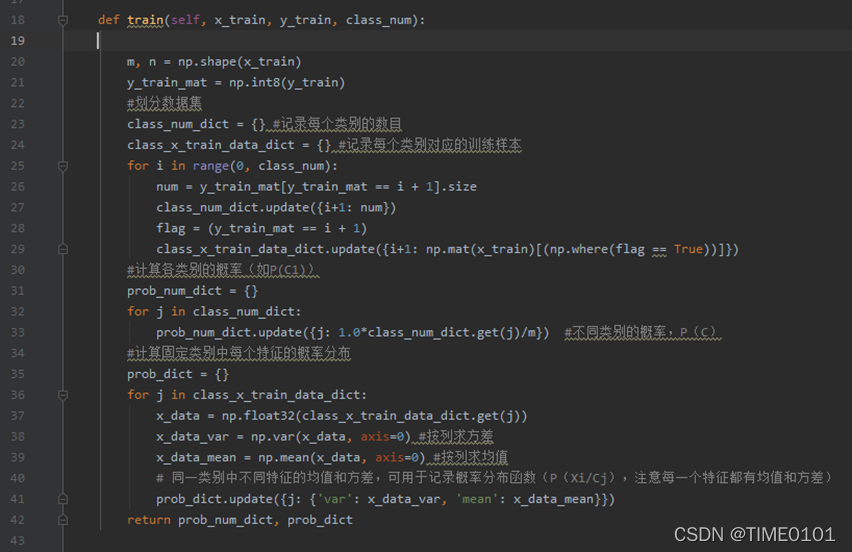
(2) 进行贝叶斯训练
其中x_train是训练样本特征,y_train是训练样本类别,class_num是分类类别数目
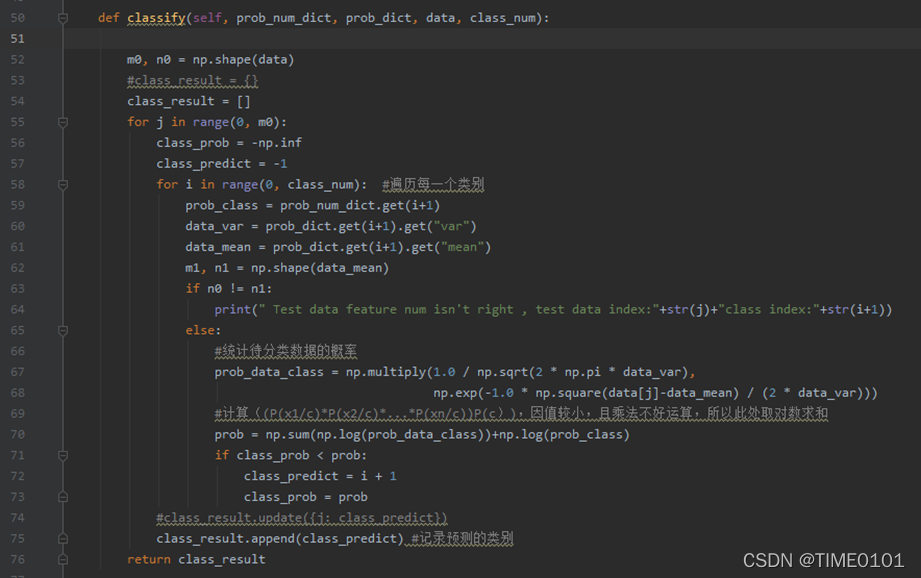
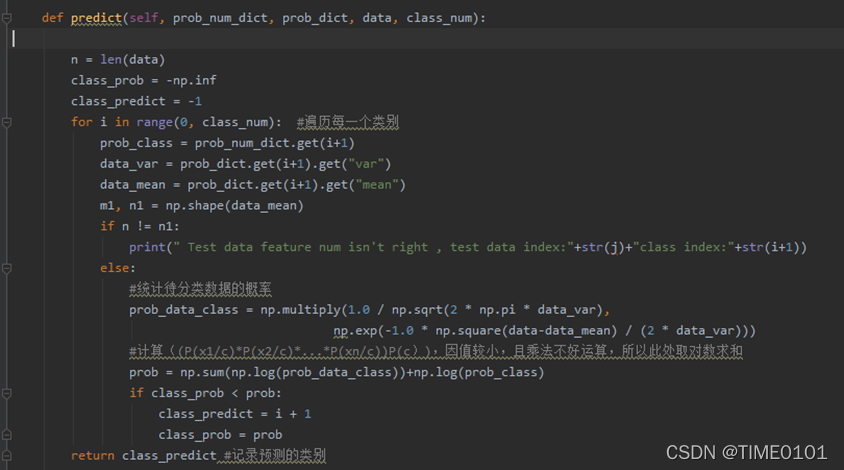
(3) 根据训练得到的概率密度函数,对待测数据分类,(多维数据)
其中prob_num_dict是 P(Xi/C),prob_dict: P(C),data: 待测数据,class_num: 类别个数
这个方法返回的是预测的数据类别。
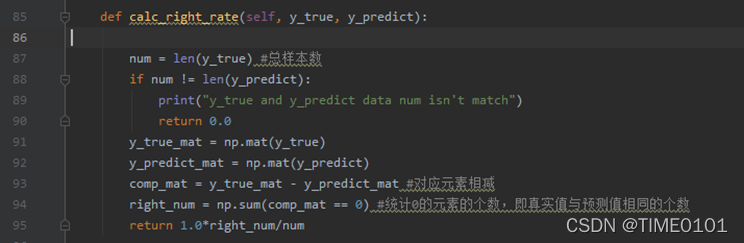
(4) 统计正确率
其中y_true: 真实类别, y_predict: 预测类别,这个方法返回的是正确率。
(5) 根据训练得到的概率密度函数,对待测数据分类(一维)
其中prob_num_dict: P(Xi/C),prob_dict: P(C),data: 待测数据,class_num: 类别个数,此方法返回的是预测的数据类别。
3,test.py
(1) 先导入刚才定义的类和numpy
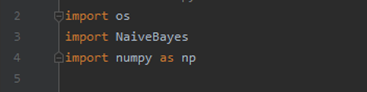
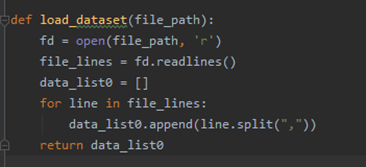
(2)定义一个加载数据的方法
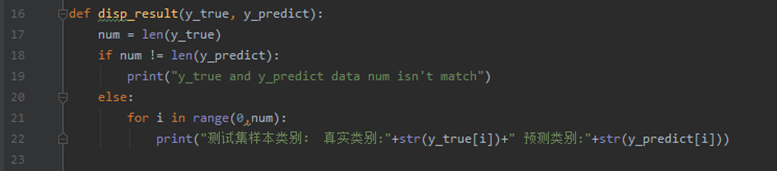
(3)定义对于测试结果输出
(4)定义主函数,调用了前面定义的函数,并且有输出正确率,以及对测试数据的分类预测。
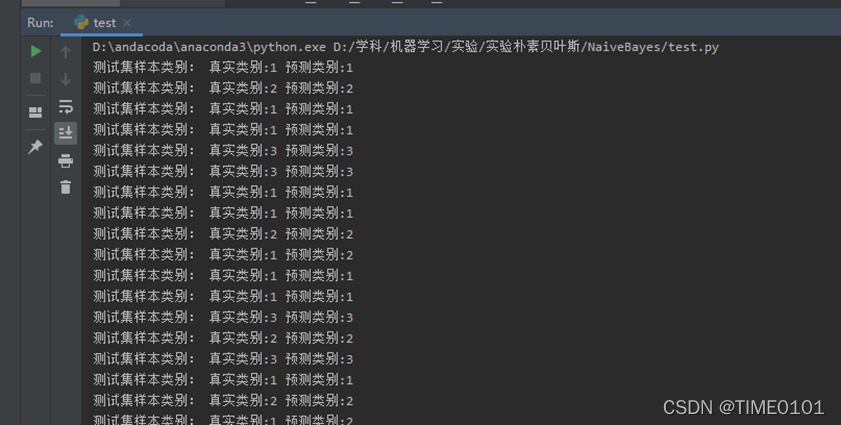
4运行结果
可以发现此训练模型对于测试集的正确率为0,94,并且对于给的一组样本进行了分类预测,预测结果是类别3
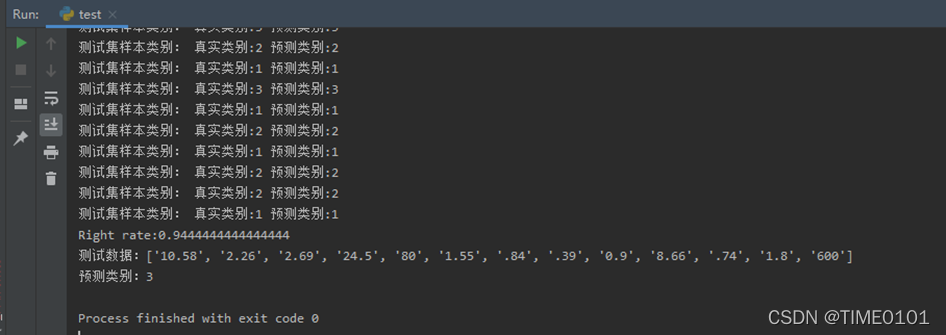
总结:在这次试验中我基本掌握朴素贝叶斯分类模型并进行了贝叶斯网络的应用,以及进行了wine分类预测。
在这个实验中,整体的思路还是比较通畅的,在结合实验与书本的内容后,我对朴素贝叶斯网络有了更深的理解,它是一种相比其他算法简单但极为强大的预测建模算法。它假设每个输入变量是独立的,这个假设很硬,现实生活中根本不满足,但对于绝大部分的复杂问题却非常有效。
关注公众号:Time木
回复:贝叶斯
可获得相关代码,数据,文档
更多大学课业实验实训可关注公众号回复相关关键词
学艺不精,若有错误还望指点
)
















 3192
3192











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











