







编译流程

内部组成
栈:

三部分:类装载子系统+内存模型+字节码执行引擎
内存模型:
虚拟机栈(线程栈):局部变量就是放在栈帧里

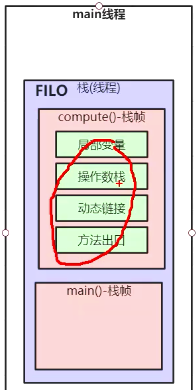
操作数栈:和字节码+程序计数器有关。程序在运行过程中放数字的(例如a=1的1),临时存放数字的空间。
程序计数器:程序计数器是用于存放执行指令的地方。 为了保证程序(在操作系统中理解为进程)能够连续地执行下去,CPU必须具有某些手段来确定下一条指令的地址。而程序计数器正是起到这种作用,所以通常又称为指令计数器。 它的值是字节码执行引擎来修改的。
动态链接:把符号引用转变为直接引用。方法放到方法区有一个地址,通过动态链接即可以找到。
方法出口:执行完方法返回到main方法的哪一行代码开始执行。
main方法:也有局部变量表,但是和别的有一些区别。如下图所示。
 方法区(元空间):常量+静态信息+类信息。
方法区(元空间):常量+静态信息+类信息。
堆:

先eden,满了轻gc,进入幸存区。。。。
可达性分析算法:

可以达到,有连接的留下,别的gc掉。
调优
https://blog.csdn.net/qq_41307443/article/details/107124037
dashboard
thread 8直接定位到出问题的代码
jad 反编译 看有没有发布成功

调优的目的:减少gc(尤其是full gc)gc会带来stw
stw:会停掉用户线程(提交订单之类的用户引发的执行线程)用户的感受就是点了提交订单但是卡顿了。
为什么要stw?如果没有这个机制,产生full gc的时候,可达性分析找完所有对象,标记为非垃圾,线程不停的话有的就直接把局部变量销毁掉了。非垃圾又变成垃圾了。gc不可能重头再找一遍。因此不如直接把用户线程停了。


如何几乎不full gc:

把年轻代设置为2个g,来年代变成1个g
不触发动态年龄判断



让生命周期短的在年轻代直接干掉。
G1垃圾收集器





















 95
95











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









