







简单工厂模式
我们先来写一个运算类
template<typename T>
class Operation
{
public:
void setNum(T a,T b)
{
num1 = a;
num2 = b;
}
T operation(char op)
{
switch(op)
{
case '+':
return num1 + num2;
case '-':
return num1 - num2;
case '*':
return num1 * num2;
case '/':
return num1 / num2;
default:
break;
}
throw "运算符错误";
}
private:
T num1;
T num2;
};
int main()
{
Operation<int> obj;
obj.setNum(10,20);
cout << obj.operation('+') << endl;
return 0;
}
这段代码虽然实现了基本的功能,但是代码的复用性,可维护性不强,加入现在有另外的一个类需要用到加减乘除四则运算,则需要重新再将现在的代码再写一遍。
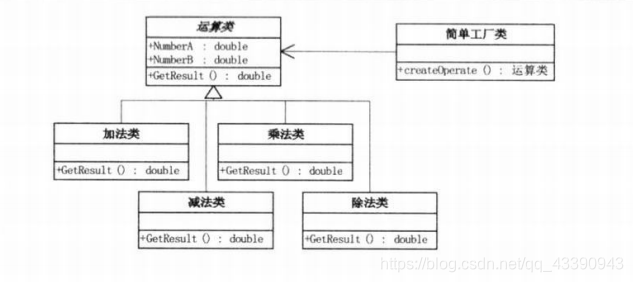
这里我们可以加减乘除四个运算发用四个类进行封装,其他的功能中如果要用到这四个方法,只要实例化一个对象就可以了。
如果要添加功能的话,例如乘方,我们只要再添加一个类,然后再swtch 添加一个分支即可。
优点:工厂类是整个模式的关键.包含了必要的逻辑判断,根据外界给定的信息,决定究竟应该创建哪个具体类的对象.通过使用工厂类,外界可以从直接创建具体产品对象的尴尬局面摆脱出来,仅仅需要负责“消费”对象就可以了。而不必管这些对象究竟如何创建及如何组织的.明确了各自的职责和权利,有利于整个软件体系结构的优化
缺点:由于工厂类集中了所有实例的创建逻辑,违反了高内聚责任分配原则,将全部创建逻辑集中到了一个工厂类中;它所能创建的类只能是事先考虑到的,如果需要添加新的类,则就需要改变工厂类了。
当系统中的具体产品类不断增多时候,可能会出现要求工厂类根据不同条件创建不同实例的需求.这种对条件的判断和对具体产品类型的判断交错在一起,很难避免模块功能的蔓延,对系统的维护和扩展非常不利
template<typename T>
class Add
{
public:
T operatorAdd(T a,T b)
{
return a + b;
}
};
template<typename T>
class Sub
{
public:
T operatorSub(T a,T b)
{
return a - b;
}
};
template<typename T>
class Mul
{
public:
T operatorMul(T a,T b)
{
return a * b;
}
};
template<typename T>
class Div
{
public:
T operatorDiv(T a,T b)
{
if(b == 0)
{
throw "除数为0";
}
return a / b;
}
};
template<typename T>
class Opention
{
public:
T Oper(char op)
{
switch (op)
{
case '+':
{
Add<T> *obj = new Add<T>();
return obj->operatorAdd(num1,num2);
}
case '-':
{
Sub<T> *obj = new Sub<T>();
return obj->operatorSub(num1,num2);
}
case '*':
{
Mul<T> *obj = new Mul<T>();
return obj->operatorMul(num1,num2);
}
case '/':
{
Div<T> *obj = new Div<T>();
return obj->operatorDiv(num1,num2);
}
default:
break;
}
throw "错误";
}
void setNum(T a, T b)
{
num1 = a;
num2 = b;
}
private:
T num1;
T num2; //两个运算数
};
int main()
{
Opention<int> op;
int a,b;
cin >> a >> b;
op.setNum(a,b);
cout << op.Oper('+') << endl;
return 0;
}
简单工厂类对产品(这里是加减乘除)进行了封装,有工厂统一生产,这样只要增减产品的种类,只要添加一个新的产品的类,再工厂中添加相应的生产接口就可以了。














 5940
5940











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









