






问题:数据库抛出异常:Incorrect string value: ‘\xE7\xA8\x8B\xE5\xBA\x8F…’ for column ‘字段名’ at row 1
当插入一条数据时,出现了下面错误:

解决:
出现该情况,说明mysql编码字符集不是UTF8格式
使用show create table表名可以查看当前字符集编码格式

需要将 latin1 字符集进行修改成为 utf8 或者 utf8md4 字符集
设置数据库编码格式,这将更新数据库的默认字符集和排序规则。
ALTER DATABASE database_name CHARACTER SET utf8 COLLATE utf8_general_ci;
更改表的字符集和排序规则,这将更新表中所有列的字符集和排序规则。
ALTER TABLE table_name CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;
更改表中某个特定列的编码格式,这将更改列的字符集和排序规则。
ALTER TABLE table_name MODIFY column_name VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_general_ci;
还可以使用以下语句将新表设置为特定的字符集和排序规则:
CREATE TABLE table_name (
id INT NOT NULL AUTO_INCREMENT,
name VARCHAR(255)NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
创建一个名为 table_name 的新表,并将其设置为使用字符集 utf8mb4 和排序规则 utf8mb4_unicode_ci。
问题:使用MySQL中的Rank语法,实现排序生成序号
使用Rank语法时,需要用到MySQL中的变量。变量需要在SELECT语句中定义并初始化,然后在ORDER BY语句中使用它们进行排序。
SELECT
score,
@rank := @rank + 1 rank
FROM
student,
(SELECT @rank := 0) r
ORDER BY
score DESC
解析:
(SELECT @rank := 0) r 定义变量@rank,并初始化为0。
FROM student 选择需要使用的数据表。
SELECT score, @rank := @rank + 1 rank 除了score字段之外,还定义了一个新的字段rank。通过使用变量来计算每个学生的排名
ORDER BY score DESC 对score字段进行降序排列。
结果:

问题:java 根据对象某个属性进行去重
public class test {
public static void main(String[] args) {
List<Person> ps=new ArrayList<>();
ps.add(new Person(11,"tom"));
ps.add(new Person(11,"张三"));
ps.add(new Person(12,"tom"));
ps.add(new Person(11,"tom"));
//根据name进行去重
List<Person> list = ps.stream().collect(
Collectors.collectingAndThen(Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(p -> p.getName()))), ArrayList::new)
);
list.forEach(System.out::println);
System.out.println("-----------");
//根据name与age进行去重
List<Person> list1 = ps.stream().collect(
Collectors.collectingAndThen(Collectors.toCollection(
() -> new TreeSet<>(Comparator.comparing(p -> p.getName()+";"+p.getAge()))), ArrayList::new)
);
list1.forEach(System.out::println);
}
}
@Data
class Person{
String name;
int age;
Person(int age,String name){
this.name=name;
this.age=age;
}
}
利用Collectors.toCollection去重
List<Person> ps=new ArrayList<>();
ps.add(new Person(11,"tom"));
ps.add(new Person(11,"张三"));
ps.add(new Person(12,"tom"));
ps.add(new Person(11,"tom"));
ps.stream()
.collect(Collectors.toCollection(() ->
new TreeSet<>(Comparator.comparing(Person::getName))))
.stream()
.forEach(System.out::println); //打印
利用TreeSet原理去重,TreeSet内部使用的是TreeMap,使用指定Comparator比较元素,如果元素相同,则新元素代替旧元素,如果不想要返回TreeSet类型,那也可以使用Collectors.collectingAndThen转换成ArrayList,也可以用new ArrayList(set),原理一样,如下:
List<Person> list = ps.stream().collect(Collectors.collectingAndThen(Collectors.toCollection(()
-> new TreeSet<>(Comparator.comparing(Person::getName))), ArrayList::new));
** 如果想根据多个去重,可以将上述方法中的Comparator.comparing(Person::getName))修改为Comparator.comparing(p -> p.getName() +“;” + p.getAge() )) 这样就是根据两个字段去重,中间的 ; 作用就是为了增加辨识度,也可以不加这个 ; ,无论多少个字段去重只用在这里用+连接就可以了
问题:java中split无法分割连续符号
在split方法多加一个-1参数,就可以解决无法连续分割的问题
public static void main(String[] args) {
String s="1|2||||";
String[] a=s.split("\\|",-1); // 如果没有 '-1' 会识别为 ["1","2"] 有就是,["1","2","","","",""]
System.out.println(a.length);
}
问题:mysql将数据 ‘aaa,bbb,ccc,ddd’ 数据创建临时表查询-查询没有的数据也显示
解决:
例子:有一组手机号,查询mysql库里有的是会员,没有的标记为非会员,按序号顺序显示
- 先把一组手机号作为一个字段
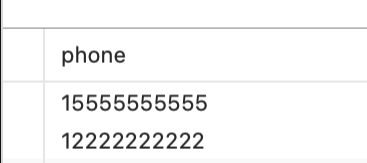
SELECT '15555555555,12222222222' AS phone FROM DUAL
效果:

2.把这个字段分割成一列数据
SELECT
substring_index(
substring_index( a.phone, ',', b.help_topic_id + 1 ),
',', - 1 ) AS phone
FROM
( SELECT '15555555555,12222222222' AS phone FROM DUAL ) a
INNER JOIN mysql.help_topic b ON b.help_topic_id < (
length( a.phone ) - length(
REPLACE ( a.phone, ',', '' )) + 1
)
效果:
3. 关联对应的mysql数据库其他表,把字段对应好,查出来
SELECT
aaa.phone '会员手机号',
IF
( ISNULL( mmm.phone ), '非会员', '会员' ) '是否会员'
FROM
(
SELECT
substring_index(
substring_index( a.phone, ',', b.help_topic_id + 1 ),
',', - 1 ) AS phone
FROM
( SELECT '15555555555,12222222222' AS phone FROM DUAL ) a
INNER JOIN mysql.help_topic b ON b.help_topic_id < ( length( a.phone ) - length( REPLACE ( a.phone, ',', '' )) + 1 )) aaa
LEFT JOIN member mmm ON aaa.phone = mmm.phone
效果:

4.自带排序的序号
SELECT
@1 := @1+1 AS '序号',
aaa.phone '会员手机号',
IF
( ISNULL( mmm.phone ), '非会员', '会员' ) '是否会员'
FROM
(
SELECT
substring_index(
substring_index( a.phone, ',', b.help_topic_id + 1 ),
',', - 1 ) AS phone
FROM
( SELECT '15555555555,12222222222' AS phone FROM DUAL ) a
INNER JOIN mysql.help_topic b ON b.help_topic_id < ( length( a.phone ) - length( REPLACE ( a.phone, ',', '' )) + 1 )) aaa
LEFT JOIN member mmm ON aaa.phone = mmm.phone,(SELECT @1 := 0 ) r
效果:

问题:idea 撤回 commit 提交的文件
执行commit后,还没执行push时,想要撤销这次的commit,该怎么办?
- 找到
VCS--Git--Reset HEAD,不同的idea版本位置可能不一样
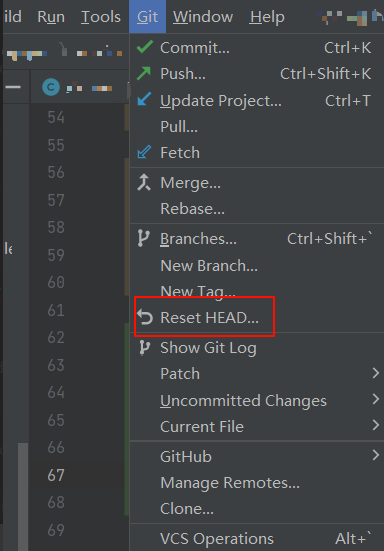
- 在To Commit中的HEAD后面加上
^,点击Reset即可撤回最近一次的尚未push的commit

Reset Type 有三种:
- Mixed(默认方式),保留本地源码,回退 commit 和 index 信息,最常用的方式
- Soft 回退到某个版本,只回退了 commit 的信息,不撤销git add file,不删除工作空间的改动代码 。如果还要提交,直接 commit
- Hard 彻底回退,本地源码也会变成上一个版本内容,不保留之前 commit 的代码
HEAD^表示上一个版本,即上一次的commit,也可以写成HEAD~1,如果进行两次的commit,想要都撤回,可以使用HEAD~2
问题:idea 中用git提交代码时忽略文件的设置
在用intellijidea开发时,经常会用git或其他版本管理工具提交代码到远程,但是idea默认会把所有只要本地与远程不同的文件都会列出来,实际上像后缀名是.iml, .idea这类文件是不需要提交的。

如果每次都手动取消这些文件,都是些重复性的操作。
按如下操作可一次性设置好,以后提交代码就会自动忽略这些文件: .iml, .idea,target 文件夹
1.进入idea设置界面
Windows环境:File - Settings - Editor - File Types
Mac环境:Preferences.. - Editor - File Types
2.在下面的 ignore files and folders 框里加入 *.iml;.idea;target;

确定后在提交代码就会自动屏蔽掉这些文件。
问题:使用命令删除已上传到gitlab上的文件夹
解决:
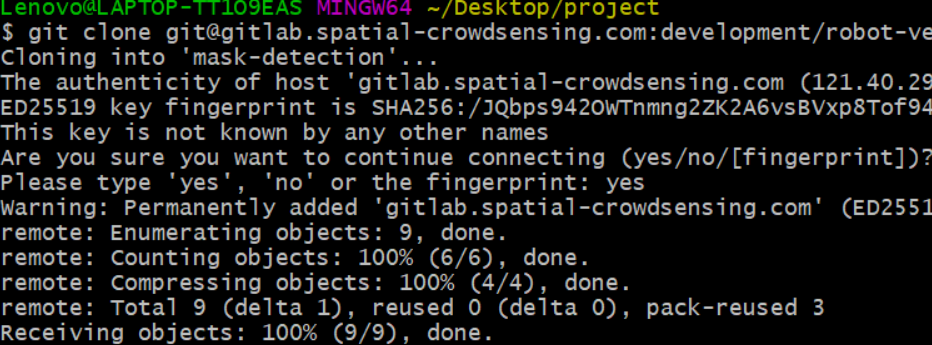
- git clone git地址,将远程仓库代码克隆到本地仓库
git clone git@gitlab.xxxx
- 创建新的 Git 仓库
cd 文件名
git init

项目中生成了 .git 这个子目录,就是 Git 仓库
- 输入命令ls 或者dir ,可查看当前文件夹下的所有文件,使用cd 文件名,可进入自己想要进的文件夹中
ls or dir

- 使用命令git rm -r xxx(文件夹名称) 可删除此文件夹以及文件夹中的所有内容,-r的意思是递归删除文件夹中的所有文件
git rm -r xxx(文件夹名称)

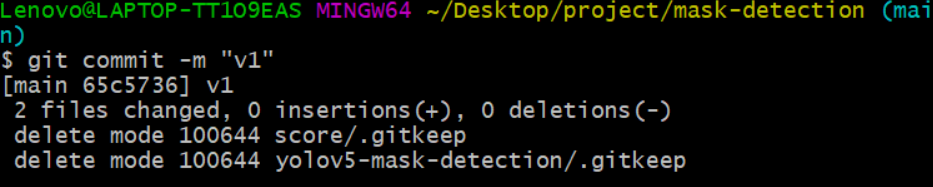
- git commit -m “提交信息”
git commit -m "提交信息"
- 输入命令git push,将修改好的项目代码重新推到gitlab上去
git push

问题:清理linux磁盘空间
解决:
- 查看各挂载点 总容量和可用容量的情况
df -h

- 进入想要清理的目录,查看文件及文件夹大小
du -sh *
- 删除大文件
rm -rf XXX
- 删除文件后,若通过 df -h 发现可用容量没有变化,此时可以执行命令
lsof -n | grep delete
列出之前删除的文件哪些是被进程占用了,直接 使用 kill -9 进程号,杀死进程,释放空间即可

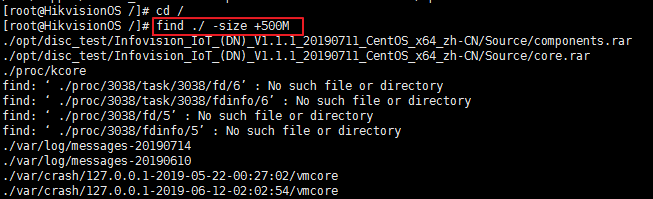
使用 find ./ -size +500M 查找大于500M的文件
问题:mysql根据中文名称首字母排序
解决:
如果表字段使用的GBK编码的话,我们可以直接order by value ,因为GBK本身就是按照拼音字母排序ABCDEFGHIGK…,当第一位相同的时候会比较第二位,以此类推。
如果表字段使用的UTF-8编码的话,通常我们都会的编码,这样我们可以使用MySQL的convert方法开转换gbk进行排序。
eg:
select * from user ORDER BY CONVERT(name USING GBK) ASC;
问题: 标签的src用后端get请求通过流写出
/**
* 获取图片文件
*/
@GetMapping("/getImgFile")
public void getImgFile(@RequestParam String filePath, HttpServletResponse rsp) throws IOException {
System.out.println("filePath:"+filePath);
File file=new File(filePath);
if(file.exists()){
// 注意设置类型 否则图片无法通过 <img> 标签显示
rsp.setContentType(MediaType.IMAGE_JPEG_VALUE);
ServletOutputStream out = rsp.getOutputStream();
InputStream inputStream=new FileInputStream(file);
int len = 0;
byte[] b = new byte[1024];
while ((len = inputStream.read(b)) != -1) {
out.write(b, 0, len);
}
out.flush();
}
}
/**
* 获取pdf文件
*/
@GetMapping("/getPdfFile")
public void getPdfFile(@RequestParam String filePath, HttpServletResponse rsp)throws IOException{
System.out.println("filePath:"+filePath);
File file=new File(filePath);
if(file.exists()){
// 注意设置类型
rsp.setContentType(MediaType.APPLICATION_PDF_VALUE);
ServletOutputStream out = rsp.getOutputStream();
InputStream inputStream=new FileInputStream(file);
int len = 0;
byte[] b = new byte[1024];
while ((len = inputStream.read(b)) != -1) {
out.write(b, 0, len);
}
out.flush();
}
}
问题:java 后端返回Long类型值溢出
前端根据id发起请求查找对象的时候一直返回找不到对象,然后查看了请求报文,发现前端传给后台的数据id不对,原本的id是1435421253099634623,可前端传过来的id是 1435421253099634700,后三位变成了700。出现这种情况的原因是
前端的js语言最大支持16位的数字,而后台用的是19位的雪花id,所以导致前端处理时精度溢出了。
解决:
-
**第一种:**修改对应后端的类,返回的VO对象Long类型字段转换为String类型,或者新定义一个String类型的字段将原始的Long类型值 toString()后存入即可。这样改的缺点就是需要改动的代码较多,不推荐。
-
**第二种:**使用 @JsonSerialize(using = ToStringSerializer.class) (按需配置)
import com.fasterxml.jackson.databind.annotation.JsonSerialize;
import com.fasterxml.jackson.databind.ser.std.ToStringSerializer;
@JsonSerialize(using = ToStringSerializer.class)
private Long id;
- **第三种:**通过全局控制添加转换器 通过fastJson的转换 或者jackson 来实现全局将long类型转为String(简单粗暴、不需要每个地方都去配置,影响全局)
FastJson
@Configuration
public class SessionConfig implements WebMvcConfigurer{
@Override
public void configureMessageConverters(List<HttpMessageConverter<?>> converters) {
FastJsonHttpMessageConverter fastJsonConverter = new FastJsonHttpMessageConverter();
FastJsonConfig fjc = new FastJsonConfig();
SerializeConfig serializeConfig = SerializeConfig.globalInstance;
serializeConfig.put(Long.class , ToStringSerializer.instance);
serializeConfig.put(Long.TYPE , ToStringSerializer.instance);
fjc.setSerializeConfig(serializeConfig);
fastJsonConverter.setFastJsonConfig(fjc);
converters.add(fastJsonConverter);
}
}
Jackson
@Configuration
public class SerializerConfig {
/**
* 解决主键Long类型返回给页面时,页面精度丢失的问题,时间格式化返回
*/
@Bean
public ObjectMapper objectMapper() {
ObjectMapper objectMapper = new ObjectMapper();
SimpleModule simpleModule = new SimpleModule();
simpleModule.addSerializer(Long.class, ToStringSerializer.instance).addSerializer(Long.TYPE, ToStringSerializer.instance);
simpleModule.addDeserializer(LocalDateTime.class, new LocalDateTimeDeserializer(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
simpleModule.addDeserializer(LocalDate.class, new LocalDateDeserializer(DateTimeFormatter.ofPattern("yyyy-MM-dd")));
simpleModule.addDeserializer(LocalTime.class, new LocalTimeDeserializer(DateTimeFormatter.ofPattern("HH:mm:ss")));
simpleModule.addSerializer(LocalDateTime.class, new LocalDateTimeSerializer(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));
simpleModule.addSerializer(LocalDate.class, new LocalDateSerializer(DateTimeFormatter.ofPattern("yyyy-MM-dd")));
simpleModule.addSerializer(LocalTime.class, new LocalTimeSerializer(DateTimeFormatter.ofPattern("HH:mm:ss")));
objectMapper.registerModule(simpleModule);
return objectMapper;
}
}
问题:Java 判断两个Long类型是否相等
解决:使用 .longValue() 或 .equals() 进行比较
Long类型的值在-128到127之间会使用缓存,超过就会创建一个对象,所以使用==判断两个值是相等的也会false。若没有超过这个范围,使用==也是可以进行判断的
问题:使用Java8流式API实现分组统计
解决:使用Java8中的Stream将集合转为流,使用Collectors.groupingBy()方法进行分组
// 假设有一个List集合,需要按照age字段对其中的Person对象进行分组统计
List<Person> personList = new ArrayList<>();
// 使用Java8流式API实现分组统计
Map<Integer, Long> ageCountMap = personList.stream()
.collect(Collectors.groupingBy(Person::getAge, Collectors.counting()));
// 遍历Map输出按照age分组统计的结果
for (Map.Entry<Integer, Long> entry : ageCountMap.entrySet()) {
System.out.println("age = " + entry.getKey() + ", count = " + entry.getValue());
}
问题:mysql 获取上个月的时间
解决:
NOW()函数返回当前日期和时间
DATE_SUB()函数可以用于获取日期或时间戳的前一段时间
DATE_SUB(NOW(), INTERVAL 1 MONTH) 可以获取上个月的时间,INTERVAL 1 MONTH表示减去一个月的时间间隔,例如当前是2021年6月份,则返回2021年5月份的日期
问题:Java的split方法使用多种分隔符切分字符串
解决:
方法一:
多个分隔符使用|分开,例如:
String str = "abc;123,456?999|haha";
String[] strs=str.split(";|,");
for(String s : strs){
System.out.println(s);
}
输出:
abc
123
456?999|haha
方法二:
使用中括号括起来[ … ],例如:
String str = "abc;123,456?999|haha";
String[] strs = str.split("[;,?|25]");
for(String s : strs){
System.out.println(s);
}
输出:
abc
1
3
4
6
999
haha
问题:数据库连接超时:“The last packet successfully received from the server was xxx milliseconds ago”
产生的原因:应用方的数据库连接有效期时间,大于数据库自己设置的有效期
解决:
一、修改druid配置(对性能会有一定影响)
spring.datasource.druid.validationQuery=select 1
spring.datasource.druid.testWhileIdle=true
spring.datasource.druid.testOnBorrow=true
spring.datasource.druid.testOnReturn=true
二、修改数据库连接配置
在数据库连接上,加&autoReconnect=true&failOverReadOnly=false配置
三、修改数据库连接有效时间
在数据库配置上设置,把数据库连接有效时间设置长一点,比如设置12小时或者24小时
问题:springboot配置fastjson替代Jackson时,响应map格式的,都会在前后多加一个双引号
解决:
@Configuration
public class WebConfig {
@Bean
public HttpMessageConverters fastJsonHttpMessageConverters() {
// 1.定义一个converters转换消息的对象
FastJsonHttpMessageConverter fastConverter = new FastJsonHttpMessageConverterExtension();
// 2.添加fastjson的配置信息,比如: 是否需要格式化返回的json数据
FastJsonConfig fastJsonConfig = new FastJsonConfig();
fastJsonConfig.setSerializerFeatures(SerializerFeature.PrettyFormat);
// 3.在converter中添加配置信息
fastConverter.setFastJsonConfig(fastJsonConfig);
// 4.将converter赋值给HttpMessageConverter
HttpMessageConverter<?> converter = fastConverter;
// 5.返回HttpMessageConverters对象
return new HttpMessageConverters(converter);
}
public class FastJsonHttpMessageConverterExtension extends FastJsonHttpMessageConverter {
FastJsonHttpMessageConverterExtension() {
List<MediaType> mediaTypes = new ArrayList<>();
mediaTypes.add(MediaType.valueOf(MediaType.TEXT_HTML_VALUE + ";charset=UTF-8"));
mediaTypes.add(MediaType.valueOf(MediaType.APPLICATION_JSON_VALUE + ";charset=UTF-8"));
setSupportedMediaTypes(mediaTypes);
}
}
}
配置
HttpMessageConverters与@JsonFormat(shape = JsonFormat.Shape.STRING, pattern = "yyyy-MM-dd", timezone = "GMT+8")注解不兼容,会失效,可以用@JSONField(format = "yyyy-MM-dd")注解替换,建议复杂对象不要用map装
问题:@Select注解中加入字段判断
错误代码:
@Select({"<script>",
"select a.*,b.uuid,b.dept_name as deptName from t_user a left join t_dept b on a.uuid=b.uuid ",
"where 1=1 and ifnull(b.uuid,1)!=1",
"<if test='userQuery.userName !=null and userQuery.userName!="" '>" ,
" and a.username like concat('%',#{userQuery.userName},'%')" ,
"</if> ",
"<if test='userQuery.deptName !=null and userQuery.deptName !="" '>" ,
" and b.dept_name like concat('%',#{userQuery.deptName},'%') " ,
"</if> ",
"</script>"})
List<User> queryList(@Param("userQuery") UserQuery userQuery);
会报如下错误:if元素类型必须后跟属性规范、">“或"/>”,这是因为我们在写sql时候没有转义导致的!
解决:
正确写法:
@Select({"<script>",
"select a.*,b.uuid,b.dept_name as deptName from t_user a left join t_dept b on a.uuid=b.uuid ",
"where 1=1 and ifnull(b.uuid,1)!=1",
"<if test='userQuery.userName !=null and userQuery.userName!=\"\" '>" ,
" and a.username like concat('%',#{userQuery.userName},'%')" ,
"</if> ",
"<if test='userQuery.deptName !=null and userQuery.deptName !=\"\" '>" ,
" and b.dept_name like concat('%',#{userQuery.deptName},'%') " ,
"</if> ",
"</script>"})
List<User> queryList(@Param("userQuery") UserQuery userQuery);
\"\"在判断不等于空字符串的时候需要加上转义
问题:使用NOT EXISTS 替换 NOT IN
如果查询语句使用了 not in 那么内外表都进行全表扫描,没有用到索引;而 not extsts 的子查询依然能用到表上的索引。
所以无论那个表大用not exists都比not in要快。
所以推荐使用not exists或者外连接来代替:
解决:
select * from a where not exists(select id from b where id=a.id);
或者
select * from a left join b on a.id = b.id where b.id is null;
问题:使用IFNULL()方法替换NOT IN NULL
解决:
表:

查询语句:SELECT IFNULL(age, 1) FROM user WHERE id = 1
查询结果:IFNULL(age,1)的值为1
mysql 的查询中,如果使用 (not in 进行 子查询) 或者 (is not null) 后,会让查询速度变得很慢,不建议使用。
代替 (not in 进行 子查询 ):将子查询 转变为 表连接,相关的逻辑写在 表连接 的关系上
代替 (is not null):将 is not null 的字段,使用 ifnull()替换为其他值,然后 ifnull()!=其他值
问题:在xml里写sql大于小于等特殊符号转译写法
解决:
| 符号 | 转义 |
|---|---|
| < | 转译为:< |
| <= | 转译为:<= |
| > | 转译为:> |
| >= | 转译为:>= |
| & | 转译为:amp; |
| ’ | 转译为:' |
| " | 转译为:" |
问题:使用Java 8 Stream通过filter()方法筛选出对象List不被另一个对象List包含的元素
解决:
// 假设A和B是两个对象数组
List<Stu> A = new ArrayList<>();
List<Stu> B = new ArrayList<>();
// 使用 Stream API 进行筛选
List<Stu> collect = A.stream()
.filter(a -> !B.stream()
.anyMatch(b -> a.id().equals(b.id())))
.collect(Collectors.toList());
// collect就是A集合里面不包含B集合元素的集合
java8 stream接口终端操作 anyMatch,allMatch,noneMatch
- anyMatch:判断的条件里,任意一个元素成功,返回true
- allMatch:判断条件里的元素,所有的都是,返回true
- noneMatch:与allMatch相反,判断条件里的元素,所有的都不是,返回true
问题:解决 @Value 给 static变量赋值问题
使用 @Value 给static变量赋值时,static变量会先于@Value加载,赋值失败
解决:
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Configuration;
/**
* 使用 @Value 必须交给 spring 管理 bean
*/
@Configuration
public class Test {
public static boolean testEnable;
// 使用 set() 方法赋值
@Value("${test.data.enable}")
public void setTestEnable(boolean testEnable){
Test.testEnable=testEnable;
}
}
注意:把@Value(“${path.url}”)放在静态变量的set方法上面需要注意
set方法要去掉static,有些时候快捷键生成set方法而没有去掉static,导致还是赋值失败
问题:mysql设置创建时间字段和更新字段自动获取时间,填充时间
解决:
-- 修改 create_time 设置默认时间 CURRENT_TIMESTAMP
ALTER TABLE `table_name`
MODIFY COLUMN `create_time` datetime(3) DEFAULT CURRENT_TIMESTAMP(3) COMMENT '创建时间' ;
-- 修改 update_time 设置默认时间 ON UPDATE CURRENT_TIMESTAMP
ALTER TABLE `table_name`
MODIFY COLUMN `update_time` datetime(3) DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT '更新时间' ;
问题:时间排序问题:mysql存储数据时间精确到毫秒
解决:
建表:
CREATE TABLE test (
id int(11) NOT NULL AUTO_INCREMENT,
created_time datetime(3) DEFAULT CURRENT_TIMESTAMP(3) COMMENT ‘创建时间’,
updated_time datetime(3) DEFAULT CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) COMMENT ‘更新时间’,
PRIMARY KEY (`id``)
) ENGINE=InnoDB AUTO_INCREMENT=50 DEFAULT CHARSET=utf8 COMMENT='test';
将 datetime 长度设置为3,即可精确到毫秒。(如果没有设置3,则默认是精确到秒)
CURRENT_TIMESTAMP(3) 表示 插入数据时默认当前数据库的时间,到毫秒。如果不加长度3,默认是到秒
CURRENT_TIMESTAMP(3) ON UPDATE CURRENT_TIMESTAMP(3) 表示更新数据时自动设置为数据库的当前时间,精确到毫秒

问题:对接查询出来的数据进行分页
例如查询出来一个数据集合:List<User> users
解决:
import cn.hutool.core.collection.ListUtil;
import com.baomidou.mybatisplus.core.metadata.IPage;
import java.util.List;
...
// 查询数据
List<User> users = getData();
// 进行数据分页,hutool工具page的pageNumber从0开始
List<User> pageData = ListUtil.page(pageNumber - 1, pageSize, users);
// 封装返回Page类
IPage page = new Page(pageNumber,pageSize,users.size()).setRecords(pageData);
问题:报错:jdbc:oracle:thin:@XXX.XXX.165.8:1522:XXXX, errorCode 923, state 42000
ERROR com.alibaba.druid.pool.DruidDataSource:2699 - create connection SQLException, url: jdbc:oracle:thin:@ip:1521/**, errorCode 923, state 42000
java.sql.SQLSyntaxErrorException: ORA-00923: 未找到要求的 FROM 关键字
解决:
druid的数据库配置validationQuery的属性值出错,对于不同的数据库,validationQuery的值是不同的。druid通过validationQuery来判断数据库联通性的,所以validationQuery的值是在当前配置数据库中执行查询,返回不为空数据的一句sql。

| DataBase | validationQuery |
|---|---|
| hsqldb | select 1 from INFORMATION_SCHEMA.SYSTEM_USERS |
| Oracle | select 1 from dual |
| DB2 | select 1 from sysibm.sysdummy1 |
| MySql | select 1 |
| Microsoft SqlServer | select1 |
| postgresql | select version() |
| ingres | select 1 |
| derby | values 1 |
| H2 | select 1 |
问题:mysql中排序将非null前排并升序
解决:
1.默认排序,会将null值排在首位
select * from student order by age

2.null值后排
select * from student order by ISNULL(age)

3.null值后排,非null升序
select * from student order by ISNULL(age), age

问题:在mybatis-plus中跟新时间字段为null,但是mp会自动忽略值为null的字段
解决:
如果直接在实体类字段中添加下面这个注解,那么所有涉及到这个实体类的跟新只要不传时间的值都会设置为null
@TableField(updateStrategy = FieldStrategy.IGNORED)
那么就有下面这个方法:
LambdaUpdateWrapper<Announcement> wrapper = new LambdaUpdateWrapper();
wrapper.eq(Announcement::getId,dto.getId());
wrapper.set(Announcement::getReleaseDate, null);
this.announcementMapper.update(announcement,wrapper);
问题:mysql查询保留2位小数
解决:
1、round(x,d),四舍五入。round(x) ,其实就是round(x,0),也就是默认d为0
select round(109.456,2);
109.46
2、TRUNCATE(x,d),直接截取需要保留的小数位
select TRUNCATE(109.456,2);
109.45
3、FORMAT(x,d),四舍五入,保留d位小数,返回string类型
select FORMAT(109.456,2);
109.46
4、CONVERT(x, DECIMAL(10,d)); 转型,会四舍五入,保留d位小数
select CONVERT(109.456, DECIMAL(10,2));
109.46
5、CEILING(x); 直接取整,个位+1
select CEILING(100.56);
101
6、FLOOR(x); 直接取整
select FLOOR(100.56);
100
问题:多个字段排序查询
解决:
order by
order by 的默认排序是升序排序,
order by(字段)asc表示升序,效果是跟默认一样的。order by (字段)desc表示降序
升序:
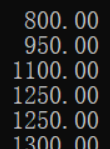
多个字段排序
语法:order by(字段一) (升序/降序),(字段二)(升序/降序),(字段n)(升序/降序)…
# 先按照age降序,age相同再按照birth升序排列
select * from t_user order by age desc,birth asc;
挨着order by 最近的字段一起主导作用,当前面的字段一无法判断时,才采用后面的字段二,字段n。
问题:MySQL里判断某个字符串是否包含某个字符串的3种方法
解决:
- 使用通配符%
通配符也就是模糊匹配,可以分为前导模糊查询、后导模糊查询和全导匹配查询,适用于查询某个字符串中是否包含另一个模糊查询的场景。
- 第一种
select * from user where hobby like "%test%";
- 第二种
select * from t_user where name like concat('%',#{name,jdbcType=VARCHAR},'%')
- 使用MySQL提供的字符串函数find_in_set()
MySQL有提供一个字符串函数find_in_set(str1,str2)函数,用于返回str2中str1所在的位置索引,如果找到了,则返回true(1),否则返回false(0),其中str2必须以半角符号的逗号【,】分割开。
select * from user where find_in_set('test', column);
- 使用MySQL提供的字符串函数locate()函数
MySQL还提供一个字符串函数locate(substr,str)函数,用于返回str中substr所在的位置索引,如果找到了,则返回一个大于0的数,否则返回0
select * from user where locate('test', column ) > 0;
适用的场景和find_in_set()函数差不多,两个函数的区别大概只有返回值上的不同
问题:先以字母排序然后以数字排序,排序后的效果如:a a1 a2 b b1 b2 c1 c2
解决:
SELECT * FROM "t_room" ORDER BY
cast(floor AS DECIMAL),
SUBSTRING(layer FROM '^(.*?)(\\d+)?$'),
COALESCE(SUBSTRING(layer FROM ' (\\d+)$')::INTEGER, 0)
问题:使用if和when进行判断
解决:
if表达式:IF(expr1,expr2,expr3) 如果 expr1 是 true,则 IF()的返回值为expr2; 否则返回值则为 expr3。IF() 的返回值为数字值或字符串值,具体情况视其所在语境而定。if语句还可以相互嵌套:IF(IF(expr1,expr2,expr3),expr2,expr3)
SELECT
name, gender,
IF(age IS NULL , '其他',
IF(age < 20, '20岁以下',
IF(age BETWEEN 20 AND 24, '20-24岁', '25岁及以上'))) AS age_cut // 三层嵌套
FROM
users;
when表达式
- 第一种
CASE
WHEN 条件判断 THEN 结果
......
WHEN 条件判断 THEN 结果
ELSE 其他结果
END
ELSE就是java当中的default
第一种与if嵌套使用:WHEN 条件判断 THEN 结果,其中条件判断可以改为if
SELECT
name, gender,
CASE
WHEN age < 20 THEN '20岁以下'
WHEN age < 25 THEN '20-24岁'
WHEN age >= 25 THEN '25岁及以上'
ELSE '其他'
END
AS age_cut
FROM
users;
- 第二种
CASE 列值
WHEN 值1 THEN 结果1
......
WHEN 值2 THEN 结果2
ELSE 其他结果
END
SELECT
CASE gender
WHEN 'male' THEN '男'
WHEN 'female' THEN '女'
ELSE '其他'
END AS gender
FROM
users;
问题:数据库是字符串类型,进行范围比较大小
解决:
DATE_FORMAT(T.CREATE_TIME,'%Y-%m-%d') BETWEEN #{startTime} and #{endTime}
问题:mybatis-plus 的 QueryWrapper 中使用 where 语句
解决:
Page<UserEntity> queryPage=new Page<>(page,limit);
QueryWrapper<UserEntity> queryWrapper=new QueryWrapper<>();
queryWrapper.eq(StrUtil.isNotEmpty(state),"state",state);
// queryWrapper.apply(StrUtil.isNotEmpty(time),"DATE_FORMAT(year,'%Y-%m-%d %H:%i:%s') ='"+time+"'");
queryWrapper.apply(StrUtil.isNotEmpty(time),"DATE_FORMAT(year,'%Y-%m-%d %T') ='"+time+"'");
DATE_FORMAT() 函数说明
DATE_FORMAT(date,format)
| 格式 | 描述 |
|---|---|
| %a | 缩写星期名 |
| %b | 缩写月名 |
| %c | 月,数值 |
| %D | 带有英文前缀的月中的天 |
| %d | 月的天,数值(00-31) |
| %e | 月的天,数值(0-31) |
| %f | 微秒 |
| %H | 小时 (00-23) |
| %h | 小时 (01-12) |
| %I | 小时 (01-12) |
| %i | 分钟,数值(00-59) |
| %j | 年的天 (001-366) |
| %k | 小时 (0-23) |
| %l | 小时 (1-12) |
| %M | 月名 |
| %m | 月,数值(00-12) |
| %p | AM 或 PM |
| %r | 时间,12-小时(hh:mm:ss AM 或 PM) |
| %S | 秒(00-59) |
| %s | 秒(00-59) |
| %T | 时间, 24-小时 (hh:mm:ss) |
| %U | 周 (00-53) 星期日是一周的第一天 |
| %u | 周 (00-53) 星期一是一周的第一天 |
| %V | 周 (01-53) 星期日是一周的第一天,与 %X 使用 |
| %v | 周 (01-53) 星期一是一周的第一天,与 %x 使用 |
| %W | 星期名 |
| %w | 周的天 (0=星期日, 6=星期六) |
| %X | 年,其中的星期日是周的第一天,4 位,与 %V 使用 |
| %x | 年,其中的星期一是周的第一天,4 位,与 %v 使用 |
| %Y | 年,4 位 |
| %y | 年,2 位 |
问题:mybatis-plus 去重复查询
解决:
QueryWrapper<User> queryWrapper=new QueryWrapper<>();
queryWrapper.select("DISTINCT year");
List<User> list= baseMapper.selectList(queryWrapper);
问题:mybatis-plus apply 防止Sql注入
解决:
QueryWrapper<UserEntity> queryWrapper=new QueryWrapper<>();
queryWrapper.eq("userId",userVO.getUserId());
// queryWrapper.apply("DATE_FORMAT(create_time,'%Y-%m-%d %H:%i:%s') BETWEEN {0} and {1}",userVO.getStartTime(),userVO.getEndTime());
Object[] params={userVO.getStartTime(),userVO.getEndTime()};
queryWrapper.apply("DATE_FORMAT(create_time,'%Y-%m-%d %T') BETWEEN {0} and {1}",params);
问题:使用 mybatis-plus 删除时,自动拼接 deleted = 0
解决:
去除实体类上的注解:@TableLogic(value = "0",delval = "1")
注释掉配置文件里的 logic-delete-value: 1 和 logic-not-delete-value: 0
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # 全局逻辑删除的实体字段名,也可实体类字段上加上@TableLogic注解
logic-delete-value: 1 # 逻辑已删除值
logic-not-delete-value: 0 # 逻辑未删除值
问题:获取前七天的时间(包括当前时间)
解决:
SELECT
date_format(date_sub( curdate( ), INTERVAL 6 day ),'%m-%d') AS FDATE UNION -- 获取间隔一天的时间 date_sub( curdate( ), INTERVAL 1 week ) 获取间隔一周的时间
SELECT
date_format(date_sub( curdate( ), INTERVAL 5 day ),'%m-%d') AS FDATE UNION
SELECT
date_format(date_sub( curdate( ), INTERVAL 4 day ),'%m-%d') AS FDATE UNION
SELECT
date_format(date_sub( curdate( ), INTERVAL 3 day ),'%m-%d') AS FDATE UNION
SELECT
date_format(date_sub( curdate( ), INTERVAL 2 day ),'%m-%d') AS FDATE UNION
SELECT
date_format(date_sub( curdate( ), INTERVAL 1 day ),'%m-%d') AS FDATE UNION
SELECT
date_format(curdate( ),'%m-%d') AS FDATE FROM DUAL
问题:使用 QueryWrapper 构造器进行自定义条件sql查询
解决:
service文件:
public IPage<UserEntity> getUsersPage(UserVO userVO) {
QueryWrapper queryWrapper = new QueryWrapper<>();
Object[] params = {userVO.getStartTime(), userVO.getEndTime()};
queryWrapper.eq(StrUtil.isNotEmpty(userVO.getName()), "name", userVO.getName())
.eq(StrUtil.isNotEmpty(userVO.getUsername()), "username", userVO.getUsername())
.apply(ObjectUtil.isNotEmpty(userVO.getStartTime()) && ObjectUtil.isNotEmpty(userVO.getEndTime()), "DATE_FORMAT(create_time,'%Y-%m-%d %T') BETWEEN {0} and {1}", params)
.orderByDesc("create_time");
// 如果想临时不分页,可以在初始化IPage时size参数传 <0 的值 eg:Page page = new Page(userVO.getPageNumber(),-1);
Page page = new Page(userVO.getPageNumber(), userVO.getPageSize());
return this.baseMapper.getUsersPage("users",page, queryWrapper);
}
mapper文件:
/**
* 使用方法
* `自定义sql` + ${ew.customSqlSegment}
* 1.逻辑删除需要自己拼接条件 (之前自定义也同样)
* 2.不支持wrapper中附带实体的情况 (wrapper自带实体会更麻烦)
* 3.用法 ${ew.customSqlSegment} (不需要where标签包裹,切记!)
* 4.ew是wrapper定义别名,可自行替换
*/
IPage<UserEntity> getUsersPage(IPage page,
@Param("table_name") String table_name,
@Param(Constants.WRAPPER) QueryWrapper queryWrapper);
xml文件:
<select id="getUsersPage" resultType="com.zl.entity.UserEntity">
SELECT
${ew.sqlSelect} // 这里拼接select后面的语句
FROM
${table_name} //如果是单表的话,这里可以写死
${ew.customSqlSegment}
</select>
动态查找
@Select("select ${ew.sqlSelect} from ${table_name} ${ew.customSqlSegment}")
IPage<UserEntity> getUsersPage(IPage page,
@Param("table_name") String table_name,
@Param("ew") Wrapper wrapper);
说明:
${ew.sqlSelect} 拼接select SQL主体
${ew.sqlSet} 拼接update SQL主体
${ew.sqlSegment} 拼接where后的语句
${ew.customSqlSegment} 拼接where后的语句(包括where。需注意在动态SQL中勿处于标签内)
问题:mysql如何查询一段时间记录
解决:
-- 查询24小时内记录(即86400秒)
WHERE UNIX_TIMESTAMP(NOW())-UNIX_TIMESTAMP(时间字段)<=86400
-- N天内记录
WHERE TO_DAYS(NOW()) - TO_DAYS(时间字段) <= N
-- 今天的记录
where date(时间字段)=date(now())
或者
where to_days(时间字段) = to_days(now());
-- 查询一周:
mysql> select * from table where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(column_time);
-- 查询一个月:
mysql> select * from table where DATE_SUB(CURDATE(), INTERVAL 1 MONTH) <= date(column_time);
-- 查询选择所有 date_col 值在最后 30 天内的记录。
mysql> SELECT something FROM tbl_name WHERE TO_DAYS(NOW()) - TO_DAYS(date_col) <= 30;
-- DAYOFWEEK(date)
-- 返回 date 的星期索引(1 = Sunday, 2 = Monday, ... 7 = Saturday)。索引值符合 ODBC 的标准。
mysql> SELECT DAYOFWEEK(’1998-02-03’);
-> 3
-- WEEKDAY(date)
-- 返回 date 的星期索引(0 = Monday, 1 = Tuesday, ... 6 = Sunday):
mysql> SELECT WEEKDAY(’1998-02-03 22:23:00’);
-> 1
mysql> SELECT WEEKDAY(’1997-11-05’);
-> 2
-- DAYOFMONTH(date)
-- 返回 date 是一月中的第几天,范围为 1 到 31:
mysql> SELECT DAYOFMONTH(’1998-02-03’);
-> 3
-- DAYOFYEAR(date)
-- 返回 date 是一年中的第几天,范围为 1 到 366:
mysql> SELECT DAYOFYEAR(’1998-02-03’);
-> 34
-- MONTH(date)
-- 返回 date 中的月份,范围为 1 到 12:
mysql> SELECT MONTH(’1998-02-03’);
-> 2
-- DAYNAME(date)
-- 返回 date 的星期名:
mysql> SELECT DAYNAME("1998-02-05");
-> ’Thursday’
-- MONTHNAME(date)
-- 返回 date 的月份名:
mysql> SELECT MONTHNAME("1998-02-05");
-> ’February’
-- QUARTER(date)
-- 返回 date 在一年中的季度,范围为 1 到 4:
mysql> SELECT QUARTER(’98-04-01’);
-> 2
-- WEEK(date)
-- WEEK(date,first)
-- 对于星期日是一周中的第一天的场合,如果函数只有一个参数调用,返回 date 为一年的第几周,返回值范围为 0 到 53 (是的,
可能有第 53 周的开始)。两个参数形式的 WEEK() 允许你指定一周是否以星期日或星期一开始,以及返回值为 0-53 还是 1-52。这
里的一个表显示第二个参数是如何工作的:
-- 值 含义
-- 0 一周以星期日开始,返回值范围为 0-53
-- 1 一周以星期一开始,返回值范围为 0-53
-- 2 一周以星期日开始,返回值范围为 1-53
-- 3 一周以星期一开始,返回值范围为 1-53 (ISO 8601)
mysql> SELECT WEEK(’1998-02-20’);
-> 7
mysql> SELECT WEEK(’1998-02-20’,0);
-> 7
mysql> SELECT WEEK(’1998-02-20’,1);
-> 8
mysql> SELECT WEEK(’1998-12-31’,1);
-> 53
-- 注意,在版本 4.0 中,WEEK(#,0) 被更改为匹配 USA 历法。 注意,如果一周是上一年的最后一周,当你没有使用 2 或 3 做
为可选参数时,MySQL 将返回 0:
mysql> SELECT YEAR(’2000-01-01’), WEEK(’2000-01-01’,0);
-> 2000, 0
mysql> SELECT WEEK(’2000-01-01’,2);
-> 52
-- 你可能会争辩说,当给定的日期值实际上是 1999 年的第 52 周的一部分时,MySQL 对 WEEK() 函数应该返回 52。我们决定返回
0 ,是因为我们希望该函数返回“在指定年份中是第几周”。当与其它的提取日期值中的月日值的函数结合使用时,这使得 WEEK() 函数
的用法可靠。如果你更希望能得到恰当的年-周值,那么你应该使用参数 2 或 3 做为可选参数,或者使用函数 YEARWEEK() :
mysql> SELECT YEARWEEK(’2000-01-01’);
-> 199952
mysql> SELECT MID(YEARWEEK(’2000-01-01’),5,2);
-> 52
-- YEAR(date)
-- 返回 date 的年份,范围为 1000 到 9999:
mysql> SELECT YEAR(’98-02-03’);
-> 1998
-- YEARWEEK(date)
-- YEARWEEK(date,first)
-- 返回一个日期值是的哪一年的哪一周。第二个参数的形式与作用完全与 WEEK() 的第二个参数一致。注意,对于给定的日期参数是一
年的第一周或最后一周的,返回的年份值可能与日期参数给出的年份不一致:
mysql> SELECT YEARWEEK(’1987-01-01’);
-> 198653
-- 注意,对于可选参数 0 或 1,周值的返回值不同于 WEEK() 函数所返回值(0), WEEK() 根据给定的年语境返回周值。
-- HOUR(time)
-- 返回 time 的小时值,范围为 0 到 23:
mysql> SELECT HOUR(’10:05:03’);
-> 10
-- MINUTE(time)
-- 返回 time 的分钟值,范围为 0 到 59:
mysql> SELECT MINUTE(’98-02-03 10:05:03’);
-> 5
-- SECOND(time)
-- 返回 time 的秒值,范围为 0 到 59:
mysql> SELECT SECOND(’10:05:03’);
-> 3
-- PERIOD_ADD(P,N)
-- 增加 N 个月到时期 P(格式为 YYMM 或 YYYYMM)中。以 YYYYMM 格式返回值。 注意,期间参数 P 不是 一个日期值:
mysql> SELECT PERIOD_ADD(9801,2);
-> 199803
-- PERIOD_DIFF(P1,P2)
-- 返回时期 P1 和 P2 之间的月数。P1 和 P2 应该以 YYMM 或 YYYYMM 指定。 注意,时期参数 P1 和 P2 不是 日期值:
mysql> SELECT PERIOD_DIFF(9802,199703);
-> 11
-- DATE_ADD(date,INTERVAL expr type)
-- DATE_SUB(date,INTERVAL expr type)
-- ADDDATE(date,INTERVAL expr type)
-- SUBDATE(date,INTERVAL expr type)
-- 这些函数执行日期的算术运算。ADDDATE() 和 SUBDATE() 分别是 DATE_ADD() 和 DATE_SUB() 的同义词。 在 MySQL 3.23 中,
如果表达式的右边是一个日期值或一个日期时间型字段,你可以使用 + 和 - 代替 DATE_ADD() 和 DATE_SUB()(示例如下)。 参数
date 是一个 DATETIME 或 DATE 值,指定一个日期的开始。expr 是一个表达式,指定从开始日期上增加还是减去间隔值。expr 是一
个字符串;它可以以一个 “-” 领头表示一个负的间隔值。type 是一个关键词,它标志着表达式以何格式被解释。
问题:json首字母大写的映射实体失败
解决:
@JsonProperty("USERNAME")
private String username;
问题:mysql创建用户并授权
创建用户
- 使用命令创建
#使用 CREATE
CREATE USER 'username'@'%' IDENTIFIED BY 'password';
# CREATE USER '你的用户名'@'可以访问数据库的ip,%表示所有' IDENTIFIED BY '数据库密码
# 使用GRANT USAGE,USAGE表示没有任何权限。
GRANT USAGE ON *.* TO 'username'@'localhost';
- sql语句创建
INSERT INTO user (Host,User,Password) values('ip','用户名','密码')
用户授权
- 使用命令授权
# GRANT ALL all 表示拥有数据库所有权限,还有SELECT,INSERT,UPDATE,delete,drop,create等等。建议不使用all
# ON database.* 数据库名称.表名,*代表所有数据库或所有表
# TO 'username'@'%'; 用户名称以及ip
GRANT ALL ON database.* TO 'username'@'%';
- sql语句授权
INSERT INTO user (Host, User, Password)
(HOST,Db, USER,
Select_priv,Insert_priv,Update_priv,Delete_priv,Create_priv,Drop_priv)
VALUES
('ip','数据库','用户名',
'Y','Y','Y','Y','Y','Y');
授权之后需要用户重连MySQL,才能获取相应的权限。
用以上命令授权的用户不能给其它用户授权,如果想开通该授权,用以下命令:
GRANT ALL ON database.* TO ‘username’@‘%’ WITH GRANT OPTION; # 加上 WITH GRANT OPTION
其他命令
# 查看用户授权
SHOW GRANTS FOR 'username'@'%';
# 设置与更改用户密码
SET PASSWORD FOR 'username'@'指定ip' = PASSWORD('密码');
# 如果是当前登陆用户直接用:
SET PASSWORD = PASSWORD("密码");
# eg:
SET PASSWORD FOR 'username'@'%' = PASSWORD("123456");
# 撤销用户权限
REVOKE ALL ON database.* FROM 'username'@'指定ip';
# eg:
REVOKE SELECT ON *.* FROM 'username'@'%'; # 撤销SELECT权限
# 删除用户
DROP USER 'username'@'指定ip'; # 方式一
delete from mysql.user where user="username"; # 方式二
如果你给用户
'username'@'%'授权的命令为(或类似的):GRANT SELECT ON test.user TO 'username'@'%',那么使用REVOKE SELECT ON *.* FROM 'username'@'%'命令并不能撤销该用户对test数据库中user表的SELECT 操作。相反,如果授权使用的是GRANT SELECT ON *.* TO 'username'@'%';那么REVOKE SELECT ON test.user FROM 'username'@'%'命令也不能撤销该用户对test数据库中user表的Select权限。(授权表的范围需要一致)
问题:IDEA Git 合并分支
团队协作中,开发人员分别在feature分支上进行功能开发,并push代码到远端feature上。当测试人员需要对功能进行测试的时候,我们需要把feature上新增的功能代码合并到develop分支上去。
步骤:
-
1、将feature上新增的代码push到远端feature上。
-
2、切换分支到develop分支。(就是切换到将要合并的目标分支)
-
3、拉取代码,确保develop分支为远端最新的代码。
-
4、合并分支(目前在develop分支上,在Local Branches中选择feature版本分支点击merge into curren(合并到当前分支:将所选分支合并到当前分支)) 这样就会把feature分支代码就会合并到develop分支上了。

-
5、有冲突,先解决冲突后再合并,没有冲突则合并成功。
-
6、push代码到远端develop分支上去。(最后一步不要忘记了,不然Git不会显示)
问题:mybatis-plus使用集合
mapper xml 方式:
<select id="selectByIds" resultMap="BaseResultMap">
SELECT
*
from t_user
WHERE 1=1
<if test="idList!=null ">
and id in
<foreach collection="idList" item="item" index="index" open="(" close=")" separator=",">
#{item}
</foreach>
</if>
</select>
- collection:该属性的对应方法的参数类型可以是List、数组、Map。如果方法的参数类型不属于前三种,则必须和方法参数@Param指定的元素名一致。
- item: 表示迭代过程中每个元素的别名。可以随便起名,但是必须跟元素中的#{}里面的名称一致。
- index:表示迭代过程中每次迭代到的位置(下标)
- open:前缀
- close:后缀
- separator:分隔符,表示迭代时每个元素之间以什么分隔。`
QueryWrapper 方式:
// 构建出 LambdaQueryWrapper
QueryWrapper<UserPO> queryWrapper = new QueryWrapper();
LambdaQueryWrapper<UserPO> lambdaQueryWrapper = queryWrapper.lambda();
// 假设这个list集合中的元素全都是用来与 id 做模糊查询的
if(CollectionUtils.isNotEmpty(idList){
// 添加 .and() 将 or 嵌套在 and之中,相当于 and( .or() .or() )
lambdaQueryWrapper.and(wrapper ->{
for(String str : idList){
wrapper.or(wq -> wq.like(UserPO::getId(), str));
}
});
}
问题:mysql查询多行合并成一行
- 语法:group_concat( [distinct] 要连接的字段 [order by 排序字段 asc/desc ] [separator ‘分隔符’] )
说明:通过使用distinct可以排除重复值;如果希望对结果中的值进行排序,可以使用order by子句;separator是一个字符串值,缺省为一个逗号。
SELECT
age,
group_concat(username ORDER BY age separator ',')
FROM
user
WHERE
age = '20'
GROUP BY
age;
问题:删除重复数据
解决:
数据库数据为:

删除 name 重复的数据
DELETE FROM `t_user`
WHERE name IN ( select a.name from (SELECT name FROM t_user GROUP BY `name` HAVING count( name ) > 1) a)
AND
id NOT IN (select a.id from (SELECT min(id) as id FROM t_user GROUP BY `name` HAVING count( name ) > 1) a)
结果:

解释:
查询
name重复的数据:SELECT name FROM t_user GROUP BY name HAVING count( name ) > 1
查询重复数据里面每个最小的id:SELECT min(id) as id FROM t_user GROUP BY name HAVING count( name ) > 1
注意:删除之前一定要先查询,然后再删除。
问题:使用mybatis-plus的saveBatch(list)仍然是一条条插入
解决:
在数据库连接后面添加 &allowMultiQueries=true
mybatis-plus的saveBatch(list)没有添加 &allowMultiQueries=true 默认是单条插入,添加后是批量插入,默认是1000条为一组
allowMultiQueries=true的作用:
- 1.可以在sql语句后携带分号,实现多语句执行。
- 2.可以执行批处理,同时发出多个SQL语句。
问题:使用navicat生成数据库设计文档
我们在写数据库设计文档的时候,会需要对数据库表进行设计的编写,手动写的话会很费时间费精力。
解决:
1、首先在Navicat中点击查询,然后输入以下SQL语句:
pgsql:
SELECT
A.attnum AS "序号",
C.relname AS "表名",
CAST ( obj_description ( relfilenode, 'pg_class' ) AS VARCHAR ) AS "表名描述",
A.attname AS "字段名",
A.attnotnull as 是否为空,
---IF(A.attnotnull='f','是','否') AS '必填',
concat_ws ( '', T.typname, SUBSTRING ( format_type ( A.atttypid, A.atttypmod ) FROM '\(.*\)' ) ) AS "数据类型",
d.description AS "注释"
FROM
pg_class C,
pg_attribute A,
pg_type T,
pg_description d
WHERE
-- C.relname = '实际表名' AND
A.attnum > 0
AND A.attrelid = C.oid
AND A.atttypid = T.oid
AND d.objoid = A.attrelid
AND d.objsubid = A.attnum
ORDER BY
C.relname DESC,
A.attnum ASC
完整属性pgsql:
select
c.relname as 表名,
CAST ( obj_description ( relfilenode, 'pg_class' ) AS VARCHAR ) AS "表名描述",
a.attname as 列名,
(case
when a.attnotnull = true then '是'
else '否' end) as 是否非空,
(case
when (
select
count(pg_constraint.*)
from
pg_constraint
inner join pg_class on
pg_constraint.conrelid = pg_class.oid
inner join pg_attribute on
pg_attribute.attrelid = pg_class.oid
and pg_attribute.attnum = any(pg_constraint.conkey)
inner join pg_type on
pg_type.oid = pg_attribute.atttypid
where
pg_class.relname = c.relname
and pg_constraint.contype = 'p'
and pg_attribute.attname = a.attname) > 0 then '是'
else '否' end) as 是否是主键,
concat_ws('', t.typname) as 字段类型,
(case
when a.attlen > 0 then a.attlen
else a.atttypmod - 4 end) as 长度,
d.description as 备注
from
pg_class c,
pg_attribute a ,
pg_type t,
pg_description d
where
a.attnum>0
and a.attrelid = c.oid
and a.atttypid = t.oid
and d.objoid = a.attrelid
and d.objsubid = a.attnum
-- and c.relname = 'your_table_name'
order by
c.relname desc,
a.attnum asc
mysql:
SELECT
TABLE_NAME 表名,
COLUMN_KEY 主键,
COLUMN_NAME 字段名称,
DATA_TYPE 字段类型,
CHARACTER_MAXIMUM_LENGTH 长度,
IS_NULLABLE 可否为空,
COLUMN_COMMENT 注释
FROM
INFORMATION_SCHEMA.COLUMNS
where
-- test 为数据库名称,复制粘贴改为你的数据库名称即可
table_schema ='test'
-- 输出所有该数据库所有表含字段
ORDER BY TABLE_NAME, COLUMN_KEY DESC
mysql 可查询列信息:
| 列名 | 数据类型 | 描述 |
|---|---|---|
| TABLE_CATALOG | nvarchar(128) | 表限定符。 |
| TABLE_SCHEMA | nvarchar(128) | 表所有者。 |
| TABLE_NAME | nvarchar(128) | 表名。 |
| COLUMN_NAME | nvarchar(128) | 列名。 |
| ORDINAL_POSITION | smallint | 列标识号。 |
| COLUMN_DEFAULT | nvarchar(4000) | 列的默认值。 |
| IS_NULLABLE | varchar(3) | 列的为空性。如果列允许 NULL,那么该列返回 YES。否则,返回 NO。 |
| DATA_TYPE | nvarchar(128) | 系统提供的数据类型。 |
| CHARACTER_MAXIMUM_LENGTH | smallint | 以字符为单位的最大长度,适于二进制数据、字符数据,或者文本和图像数据。否则,返回 NULL。有关更多信息,请参见数据类型。 |
| CHARACTER_OCTET_LENGTH | smallint | 以字节为单位的最大长度,适于二进制数据、字符数据,或者文本和图像数据。否则,返回 NULL。 |
| NUMERIC_PRECISION | tinyint | 近似数字数据、精确数字数据、整型数据或货币数据的精度。否则,返回 NULL。 |
| NUMERIC_PRECISION_RADIX | smallint | 近似数字数据、精确数字数据、整型数据或货币数据的精度基数。否则,返回 NULL。 |
| NUMERIC_SCALE | tinyint | 近似数字数据、精确数字数据、整数数据或货币数据的小数位数。否则,返回 NULL。 |
| DATETIME_PRECISION | smallint | datetime 及 SQL-92 interval 数据类型的子类型代码。对于其它数据类型,返回 NULL。 |
| CHARACTER_SET_CATALOG | varchar(6) | 如果列是字符数据或 text 数据类型,那么返回 master,指明字符集所在的数据库。否则,返回 NULL。 |
| CHARACTER_SET_SCHEMA | varchar(3) | 如果列是字符数据或 text 数据类型,那么返回 DBO,指明字符集的所有者名称。否则,返回 NULL。 |
| CHARACTER_SET_NAME | nvarchar(128) | 如果该列是字符数据或 text 数据类型,那么为字符集返回唯一的名称。否则,返回 NULL。 |
| COLLATION_CATALOG | varchar(6) | 如果列是字符数据或 text 数据类型,那么返回 master,指明在其中定义排序次序的数据库。否则此列为 NULL。 |
| COLLATION_SCHEMA | varchar(3) | 返回 DBO,为字符数据或 text 数据类型指明排序次序的所有者。否则,返回 NULL。 |
| COLLATION_NAME | nvarchar(128) | 如果列是字符数据或 text 数据类型,那么为排序次序返回唯一的名称。否则,返回 NULL。 |
| DOMAIN_CATALOG | nvarchar(128) | 如果列是一种用户定义数据类型,那么该列是某个数据库名称,在该数据库名中创建了这种用户定义数据类型。否则,返回 NULL。 |
| DOMAIN_SCHEMA | nvarchar(128) | 如果列是一种用户定义数据类型,那么该列是这种用户定义数据类型的创建者。否则,返回 NULL。 |
| DOMAIN_NAME | nvarchar(128) | 如果列是一种用户定义数据类型,那么该列是这种用户定义数据类型的名称。否则,返回 NULL。 |
2、运行结果:

3、导出结果:


这样就导出了一个数据库设计表

问题:Linux配置DNS域名解析
解决:linux下配置域名解析有三种方法
- HOST本地解析
# vi /etc/hosts
eg: 127.0.0.1 wwww.baidu.com
- 网卡配置文件DNS服务地址
# vi /etc/sysconfig/network-scripts/ifcfg-eth0
eg: DNS1='112.112.112.11'
- 系统默认DNS配置
# vi /etc/resolv.conf
eg: nameserver 112.112.112.12
系统解析的优先级为:1>2>3
链接
- 解决项目中java heap space的问题:
https://blog.csdn.net/smh0310/article/details/90664598 - Java读取resources下的文件及资源路径:
https://blog.csdn.net/run65536/article/details/131316095
https://www.cnblogs.com/lshan/p/13405288.html - @Configuration、@Bean、@Component区别:
https://blog.csdn.net/xiaoqj123456789/article/details/126492415















 3689
3689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









