







概述、定位、功能
- 是什么:zookeeper是一个分布式的协调服务软件(distributed coordination)。
分布式:多台机器的环境。
协调服务:在分布式环境下,如何控制大家有序的去做某件事。顺序、一致、共同、共享。
zookeeper的本质:分布式的小文件存储系统
- 存储系统:存储数据、存储文件 目录树结构
- 小文件:上面存储的数据有大小限制 ,通常不会超过1M
- 分布式:可以部署在多台机器上运行,对比单机来理解。
- 问题:zk这个存储系统和我们常见的存储系统不一样。基于这些不一样产生了很多应用。
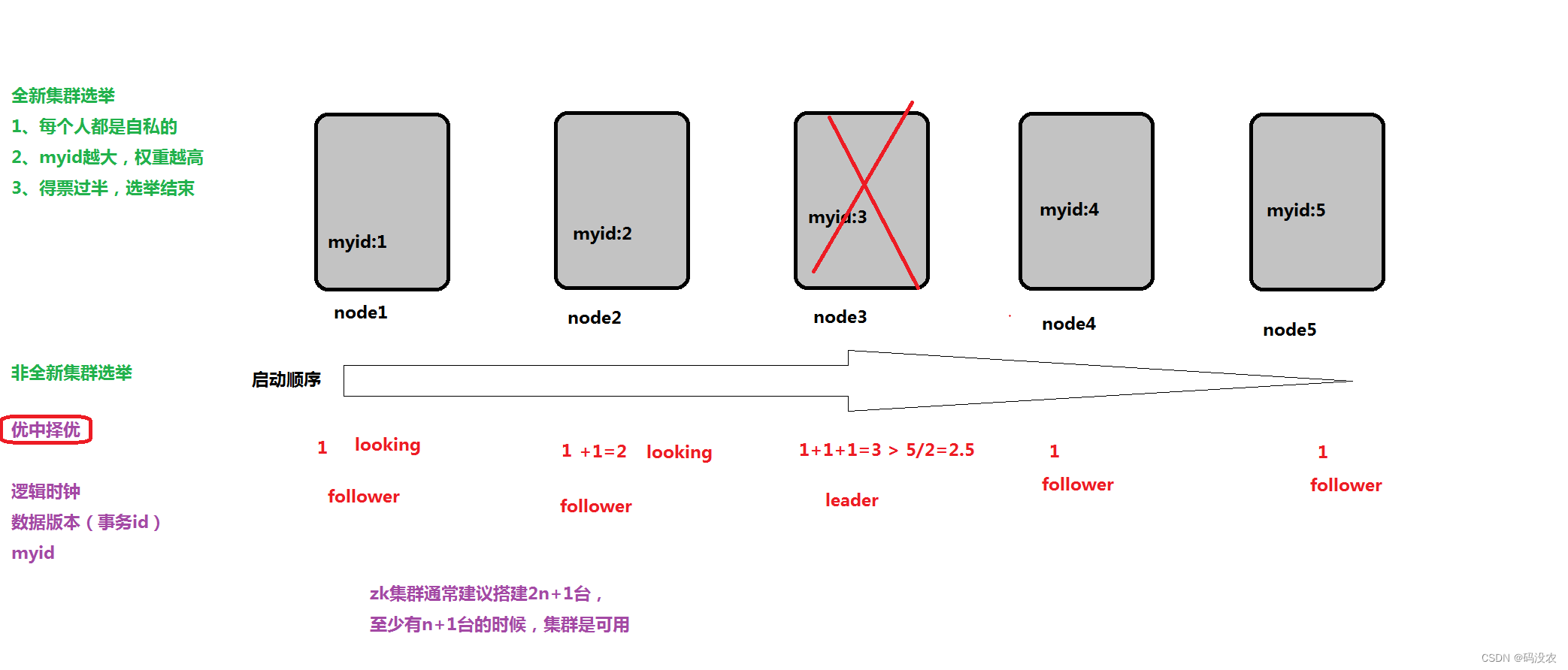
zookeeper是一个标准的主从架构集群。(MS架构)
全局数据一致性
zk集群中每个服务器保存一份相同的数据副本,客户端无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征。
如何保证数据的一致性:
客户端操作:
- 读操作(非事务性操作):查
- 写操作(事务性操作):增删改
如何保证:leader把所有的事务性请求根据请求时间编号;事务编号,根据编号依次执行。
集群的架构与角色职责
- 主角色(leader):事务性请求的唯一调度和处理者。
- 从角色(follower):
处理非事务性操作 ,转发事务性操作给leader;
参与zk内部选举机制。 - 观察者角色(Observer):
处理非事务性操作,转发事务性操作给leader;
不参与zk内部选举机制。
集群搭建
- zk集群在搭建部署的时候,通常选择==2n+1==奇数台。底层 Paxos 算法支持(过半成功)。
- zk部署之前,保证服务器基础环境正常、JDK成功安装。
服务器基础环境【3台机器】:
#IP
#主机名
#hosts映射
#防火墙关闭
#时间同步
#ssh免密登录
JDK环境
zk具体安装部署(选择node1安装 scp给其他节点)
- 安装包:zookeeper-3.4.6.tar.gz
- 上传安装包,解压、重命名
- 修改配置文件 zoo.cfg
#zk默认加载的配置文件是zoo.cfg 因此需要针对模板进行修改。保证名字正确。
cd /export/server/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
#修改
dataDir=/export/data/zkdata
#文件最后添加 2888心跳端口 3888选举端口
server.1=node1:2888:3888
server.2=node2:2888:3888
server.3=node3:2888:3888
扩展:心跳机制
- 分布式软件中从角色向主角色进行心跳 heartbeat
- 目的:报活
myid
#在每台机器的dataDir指定的目录下创建一个文件 名字叫做myid
#myid里面的数字就是该台机器上server编号。server.N N的数字就是编号
[root@node1 conf]# mkdir -p /export/data/zkdata
[root@node1 conf]# echo 1 >/export/data/zkdata/myid
- 把安装包同步到其他节点上
cd /export/server
scp -r zookeeper/ node2:$PWD
scp -r zookeeper/ node3:$PWD
- 创建其他机器上myid和datadir目录
[root@node2 ~]# mkdir -p /export/data/zkdata
[root@node2 ~]# echo 2 > /export/data/zkdata/myid
[root@node3 ~]# mkdir -p /export/data/zkdata
[root@node3 ~]# echo 3 > /export/data/zkdata/myid
集群启停、进程查看、日志查看
zk集群的启动
每台机器上单独启动服务
#在哪个目录执行启动命令 默认启动日志就生成当前路径下 叫做zookeeper.out
/export/server/zookeeper/bin/zkServer.sh start|stop|status
/export/server/zookeeper/bin/zkServer.sh start #启动
/export/server/zookeeper/bin/zkServer.sh stop #关闭
/export/server/zookeeper/bin/zkServer.sh status #查看状态
#3台机器启动完毕之后 可以使用status查看角色是否正常。
#还可以使用jps命令查看zk进程是否启动。
[root@node3 ~]# jps
2034 Jps
1980 QuorumPeerMain #看我,我就是zk的java进程
扩展:编写shell脚本 一键脚本启动。
本质:在node1机器上执行shell脚本,由shell程序通过ssh免密登录到各个机器上帮助执行命令。
一键关闭脚本
[root@node1 ~]# vim stopZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "/export/server/zookeeper/bin/zkServer.sh stop"
done
一键启动脚本
[root@node1 ~]# vim startZk.sh
#!/bin/bash
hosts=(node1 node2 node3)
for host in ${hosts[*]}
do
ssh $host "source /etc/profile;/export/server/zookeeper/bin/zkServer.sh start"
done
-
注意:关闭java进程时候 根据进程号 直接杀死即可就可以关闭。启动java进程的时候 需要JDK。
-
shell程序ssh登录的时候不会自动加载/etc/profile 需要shell程序中自己加载。
数据模型、znode类型(4种)
数据模型
结构上看:目录树
特殊之处:没有文件夹、文件之分,统称为znode
znode种类:
1.永久节点【非序列化】(PERSISTENCE)
一旦创建,不管客户端是否断开、离开,除非手动强制删除,否则的话将会一直存在。
2.临时节点【非序列化】(EPHEMERAL)
如果客户端断开和zk连接,会话结束,znode就被删除。
注意: 临时节点不允许创建子节点。
3.永久节点序列化(PERSISTENCE_SEQUENTIAL)
4.临时节点序列化(EPHEMERAL_SEQUENTIAL)
shell命令行操作(CRUD)
zk的操作:自带shell客户端
/export/server/zookeeper/bin/zkCli.sh -server ip
#如果不加-server 参数 默认去连接本机的zk服务 localhost:2181
#如果指定-server 参数 就去连接指定机器上的zk服务
#退出客户端端 ctrl+c
基本操作
创建查看
[zk: node2(CONNECTED) 28] ls /itcast #查看指定路径下有哪些节点
[aaa0000000000, bbbb0000000002, aaa0000000001]
[zk: node2(CONNECTED) 29] get /
zookeeper itcast
[zk: node2(CONNECTED) 29] get /itcast #获取znode的数据和stat属性信息
1111
cZxid = 0x200000003 #创建事务ID
ctime = Fri May 21 16:20:37 CST 2021 #创建的时间
mZxid = 0x200000003 #上次修改时事务ID
mtime = Fri May 21 16:20:37 CST 2021 #上次修改的时间
pZxid = 0x200000009
cversion = 3
dataVersion = 0 #数据版本号 只要有变化 就自动+1
aclVersion = 0
ephemeralOwner = 0x0 #如果为0 表示永久节点 如果是sessionID数字 表示临时节点
dataLength = 4 #数据长度
numChildren = 3 #子节点个数
更新节点数据
set path data
删除节点
[zk: node2(CONNECTED) 43] ls /itcast
[aaa0000000000, bbbb0000000002, aaa0000000001]
[zk: node2(CONNECTED) 44] delete /itcast/bbbb0000000002
[zk: node2(CONNECTED) 45] delete /itcast
Node not empty: /itcast
[zk: node2(CONNECTED) 46] rmr /itcast #递归删除
监听机制watch
ZooKeeper中,引入了Watcher机制来实现这种分布式的通知功能。ZooKeeper允许客户端向服务端注册一个Watcher监听,当服务端的一些事件触发了这个Watcher,那么就会向指定客户端(一对多)发送一个事件通知来实现分布式的通知功能。
- 触发事件种类很多,如:节点创建,节点删除,节点改变,子节点改变等。
总的来说可以概括Watcher为以下三个过程:
- 客户端向服务端注册Watcher
- 服务端事件发生触发Watcher
- 客户端回调Watcher得到触发事件情况
watch机制特点
-
一次性触发
事件发生触发监听,一个watcher event就会被发送到设置监听的客户端,这种效果是一次性的,后续再次发生同样的事件,不会再次触发。 -
事件封装
ZooKeeper使用WatchedEvent对象来封装服务端事件并传递。
WatchedEvent包含了每一个事件的三个基本属性:
通知状态(keeperState),事件类型(EventType)和节点路径(path) -
event异步发送
watcher的通知事件从服务端发送到客户端是异步的。 -
先注册再触发
Zookeeper中的watch机制,必须客户端先去服务端注册监听,这样事件发送才会触发监听,通知给客户端。
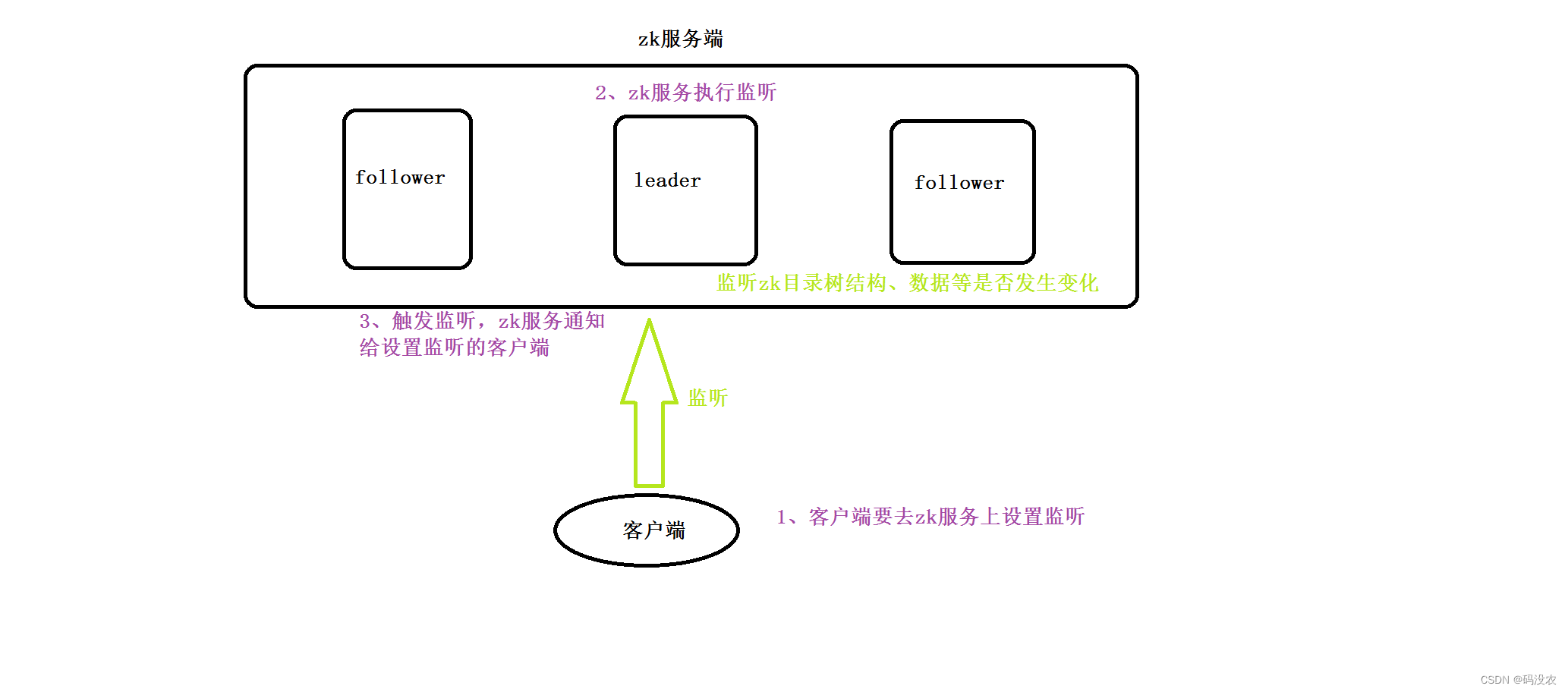
Shell 客户端设置watcher
-
设置节点数据变动监听:

-
通过另一个客户端更改节点数据:

-
此时设置监听的节点收到通知:

Zookeeper典型应用
数据发布/订阅
数据发布/订阅系统即所谓的配置中心,也就是发布者将数据发布到ZooKeeper的一个节点上,提供订阅者进行数据订阅,从而实现动态更新数据的目的,实现配置信息的集中式管理和数据的动态更新。
主要用到了:监听机制。
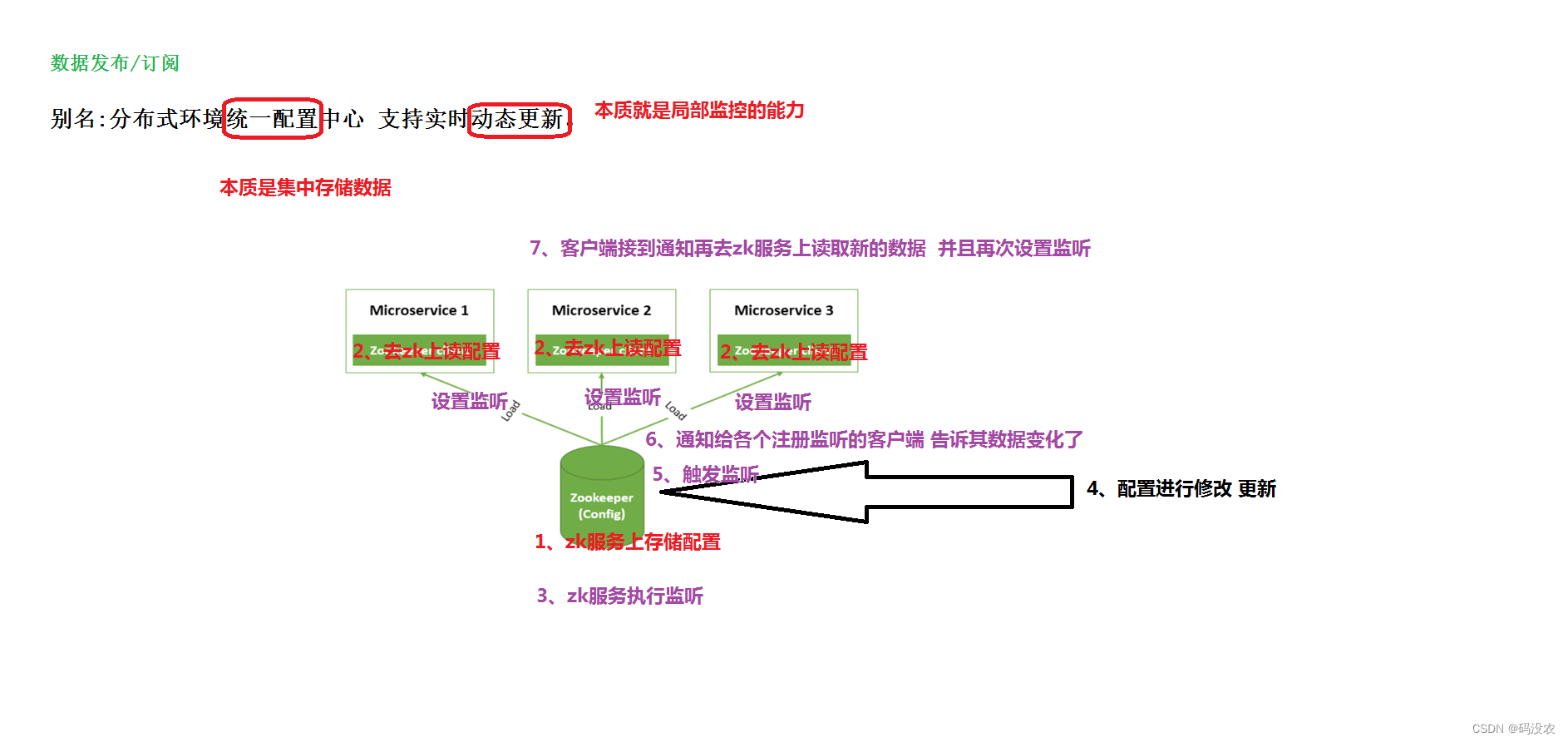
提供集群选举
临时,序列化
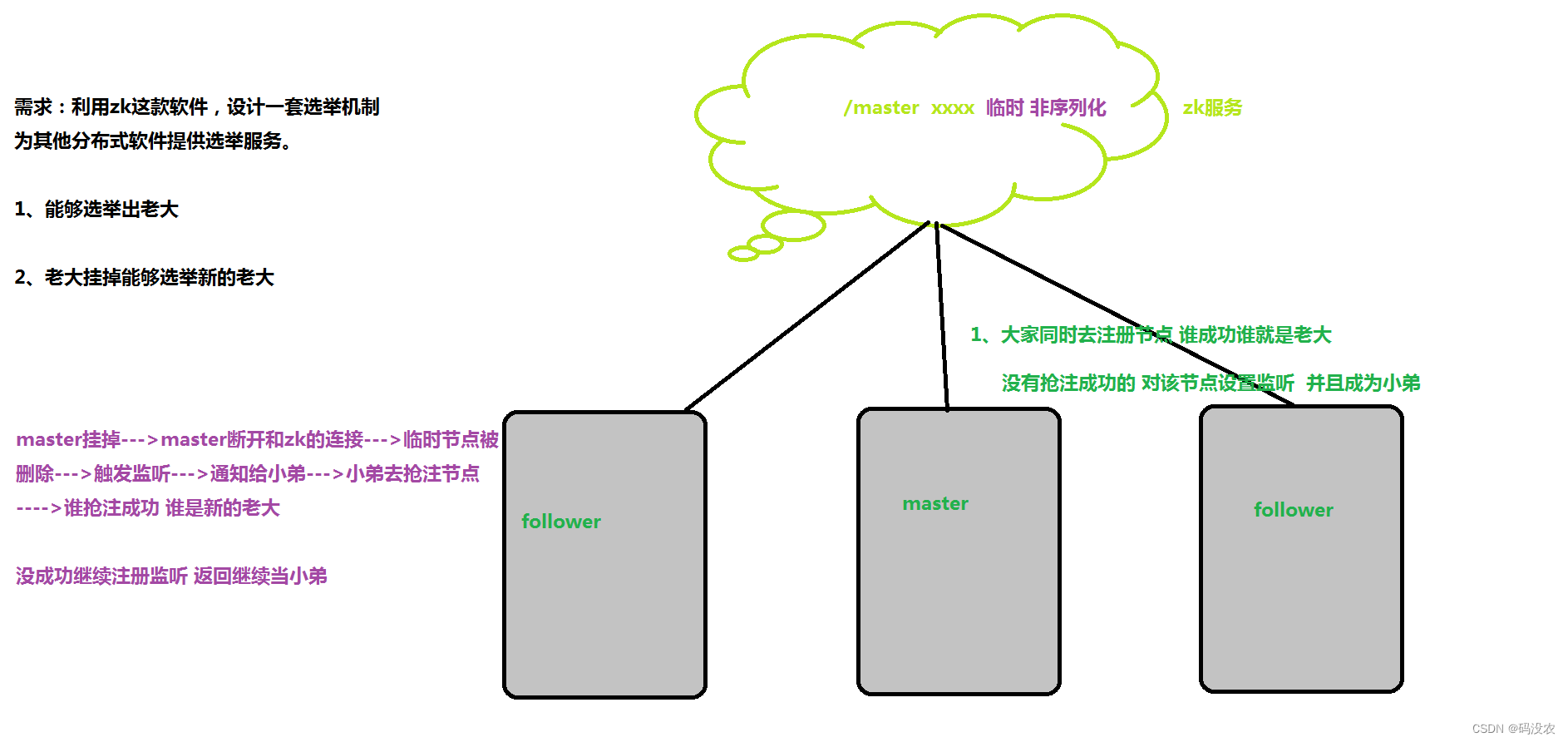
分布式锁
原理和选举差不多,只是换了个应用场景。















 240
240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









