






翻译程序
翻译程序的含义
-
将某一种程序设计语言写的程序翻译成等价的另一种语言的程序的程序
-
源程序->翻译软件->目标程序或执行结果
翻译程序的分类
-
编译程序:高级语言->汇编语言/机器语言
-
汇编程序:汇编语言->机器语言
-
解释程序:直接执行源程序的翻译程序
典型的编译程序模型
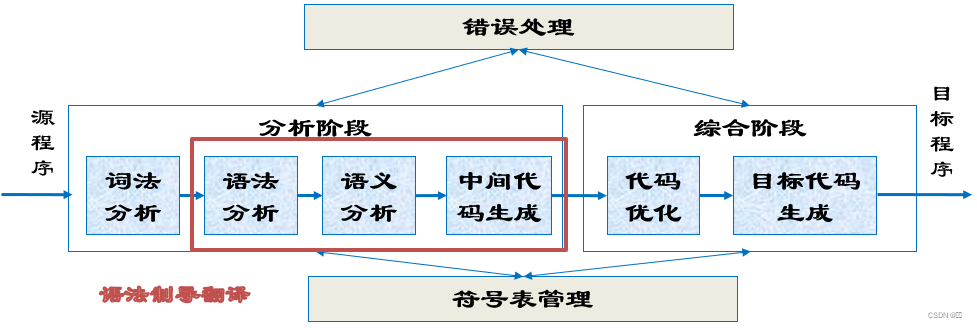
端、遍的概念
“端”的概念
-
前端主要与源语言有关,包括词法分析、语法分析、语义分析和中间代码生成、符号表的建立以及相应的错误处理和符号表操作。
-
后端主要与目标机器有关、包括代码优化、目标代码生成以及相应的错误处理和符号表操作。
-
把编译程序分为前端和后端的优点是便于移植、编译程序的构造。
“遍”的概念
-
对源程序或源程序的中间形式从头到尾的扫描一遍,并做有关的分析加工,生成新的源程序的中间形式或生成目标代码。
-
“遍”设置的考虑因素
-
宿主机存储存储容量
-
编译程序功能的强弱
-
源语言的繁简及约束
-
优化因素
-
设计、实现的环境、工具及人员因素等
文法与语言
符号串和集合的操作
字母表
例:A = {a, b, c, +, *}, Σ = {0, 1}
符号串
-
概念:“符号串”是由字母表上0个或多个符号所组成的任何有穷序列。
ε也是字母表上的符号串,它由0个符号组成
-
符号串的长度:指符号串x中所含符号的个数,记为|x|
例:|abc| = 3, |abcc+*abc| = 8, 而|ε| = 0
-
符号串相等:若x、y是字母表Σ上的两个符号串,那么当且仅当组成x的各符号与组成y的各符号依次相等时,则符号串x与符号串y相等,记作x=y
例:
-
当 x = abbc, y = abbc时,则x=y
-
当 x = ab,y = ba时,则x≠y
-
-
符号串的前缀:指从符号串x的末尾删除0或多个符号后得到的符号串。
例:ε、a、ab、abc、abcd都是abcd的前缀
-
符号串的后缀:指从符号串x的开头删除0或多个符号后得到的符号串。
例:ε、d、cd、bcd、abcd都是abcd的后缀
-
符号串的子串:指从符号串x的开头和末尾删除0或多个符号后得到的符号串。
例:ε、a、b、c、ab、bc、cd、abc、bcd、abcd是abcd的子串, 而ac,ad,cb,bd,ba等都不是子串
符号串的前缀、后缀都是它的子串
-
符号串的连接:
-
若x、y是两个符号串,则xy表示连接,是将符号串y连接在符号串x的后面。
-
若x、y是字母表Σ上的两个符号串,则xy也是字母表Σ上的符号串
例:x=ab,y=ba,那么xy=abba
-
连接没有交换律,即xy≠yx
-
而对于空串ε有εx=xε=x
-
-
符号串的幂运算:若x是符号串,则x的幂运算定义为:x0=ε,x1=x,x2=xx,...,xn=xx...x=xxn-1=xn-1x,其中n>0
例:x=abc, x0=ε, x1=abc, x2=abcabc, ...
集合
-
集合的乘积运算:令A、B为两个符号串集合,A和B的乘积AB定义为:AB=\{xy|x\in A, y\in B\}。
例:A={a, b},B={c, d},则AB={ac, ad, bc, bd}
-
{ε}A=A{ε}=A
-
∅A=A∅=∅,其中∅为空集
-
∅={}≠{ε}
-
-
集合的幂运算:设A为符号串集合,则A的幂运算定义为:A^0={\varepsilon}, A^1=A, A^2=AA, ..., A^n=AA...A=AA^{n-1}=A^{n-1}A,其中n>0,显然有:A^{i+j}=A^iA^j。
例:A={a, b},则A0={ε},A1={a, b},A2={aa, ab, ba, bb}
-
集合的并运算:设P、Q为符号串集合,则P∪Q为P和Q的并,它的元素是P或Q中的集合。
例:P={0, 1, 01},Q={0, 10, 11, 00},则P∪Q={0, 1, 01, 10, 11, 00}
-
集合的正闭包:设A为一个集合,则A的正闭包记作A+,则有:A+ =A1 ∪ A2 ∪ ... ∪ An ...
例:A={a, b},A+={a, b, aa, ab, ba, bb, aaa, aab,...}
-
集合的闭包:用A*表示,则有:A=A0 ∪ A+ = {ε}∪A+ = A+∪{ε}
例:A={a, b},A*={ε, a, b, aa, ab, ba, bb, aaa, aab,...}
EBNF文法
G=(Vn, Vt, P, Z),Vn为非终结符号集合,Vt为终结符号集合
设V是文法G的符号集,则有V=Vt∪Vn,Vt∩Vn=∅
元符号
-
“|”:表示“或”。对于具有相同左部的那些规则。
例:如α->β1、...、α->βn,可以缩写为: α->β1|β2|...|βn
-
“<”和“>”:用于括起由中文字组成的非终结符号或由多个字母组成的符号。
-
“{”和“}”:表示可重复连接,\{t\}_n^m表示符号串t可重复连接n~m次,而{t}表示符号串t可重复连接0到无穷次。
例:<无符号整数> -> <数字>|<数字><数字>|<数字><数字><数字> --> <无符号整数> -> \{<数字>\}_{1}^{3}
-
“[”和“]”:表示括起的内容可有可无。
-
“(”和“)”:•表示括号内的成分优先,常用于在规则中提取公因子。
例:U->xy|xw|...|xz --> U->x(y|w|...|z)
推导与归约
推导
-
概念:给定了文法之后,就可以从文法的开始符号并根据文法规则进行推导,通过推导可以产生文法定义的句子。
-
直接推导:利用产生式α->β将符号串xαy中的非终结符号α用β替换,从而得到符号串xβy。
表示为:xαy => xβy
归约
-
如果存在直接推导序列α0=>α1=>...=>αn,其中n>0
那么说α0产生αn或αn归约到α0,并记作α0=+>αn(经过正数步推导),推导长度为n。
-
如果有α0=+>αn或α0=αn,即n>=0,则记作α0=*>αn(经过若干(可以是0)步推导)。

规范推导
-
对于直接推导xαy => xβy来说,如果x(y)只包含终结符号或为空符号串,那么就把这种推导称为最左(右)推导。
-
最右推导又叫规范推导,记作:xαy =| => xβy,其中y ∈ Vt*
-
如果推导α0==+>αn的每一步都是规范的,那么推导α0==+>αn称为规范的,且记作:α0 =|=+>αn
句子与句型
-
句型的定义:如果Z=*>x, 且x∈V*,则称x是文法G[Z]的一个句型。
-
Z经过若干步能推导出文法符号串x。
-
一个句型中既可以包含终结符,又可以包含非终结符,也可能是空串。
-
-
句子的定义: 如果Z=+>x,且x∈Vt*,则称x是文法G[Z]的一个句子。
-
Z经过若干步能推导出终结符号串x,句子是特殊的句型。
-
句子是不包含非终结符号的句型,推导长度>=1。
-
递归文法
概念
-
若文法中至少包含一条递归规则,则称文法是直接递归的。
-
有些文法,表面看上去没有递归规则,但经过几步推导,也能造成文法的递归性,则称为间接递归。
-
递归文法使我们能用有穷的文法刻画无穷的语言。
用语言描述
例:判定如下文法所描述的原因呢是否是又穷的:
Z -> aBa B -> bB|b
该文法描述的语言为:L(G)={abna|n>=1}
短语、简单短语、句柄
-
短语:每个子树的叶子节点
-
简单短语:倒数第二层节点的叶子节点
-
句柄:最左边简单短语的叶子节点
例:
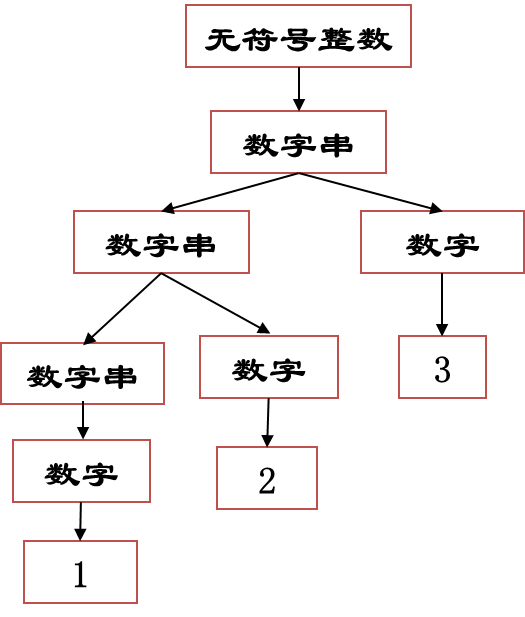
| 树根 | 叶子节点 | 短语 | 类型 |
|---|---|---|---|
| <无符号整数> | 1、2、3 | 123 | 短语 |
| <数字串> | 1、2、3 | 123 | 短语 |
| <数字串> | 2、3 | 23 | 短语 |
| <数字串> | 3 | 3 | 短语 |
| <数字> | 1 | 1 | 短语,简单短语,句柄 |
| <数字> | 2 | 2 | 短语,简单短语 |
| <数字> | 3 | 3 | 短语,简单短语 |
文法的分类
0型文法(短语结构文法)
-
产生式形如:α->β
-
解释:左边有非终结符,右边有终结符。
-
例:S->aQb
1型文法(上下文有关文法)
-
产生式形如:αUβ → αuβ
-
解释:式子左边可以有多个字符,但必须有一个非终结符;式子右边可以有多个字符,可以是终结符,也可以是非终结符,但必须左部长度必须小于右部长度。
-
例:A->ε(特例),aUb->aABBaab
2型文法(上下文无关文法)
-
产生式形如:U->u
-
解释:在1型文法的基础上,产生式左部必须得是一个非终结符。
-
例:A->aB
3型文法(正则文法)
-
产生式形如:U->a或U->Wa(左线性)或U->aW(右线性)
-
解释:产生式规则的右侧只能包含一个终结符后跟一个非终结符,或者只包含一个终结符,或者是空串。
-
例:A->bA(右线性),B->Ab(左线性)
词法分析
单词符号种类及词法分析输出
单词符号
-
定义:单词符号是语言中具有独立意义的最小语法单位。
例:A*B 单词符号是“A”、“*”和“B”
-
通常程序语言的单词符号有:
-
保留字:if,while,for...
-
标识符:由用户定义,用来表示各种名字,如变量名、函数名、数组名等等。
-
无符号数:125,0.788,15.2...
-
分界符:如+、-、*、/、;、(、)等单分界符,还有>=、<=、!=、++等双分界符。
-
词法分析输出
词法分析的输出常采用二元式|单词类别|单词值|
例:
{
int a;
a = 10;
}

正则文法及状态图,判断句子是否合法
正则文法及状态图
规则:
文法中的每个非终结符号对应状态图中的一个结点,即图中的每个结点代表一个非终结符号。
增设一个结点代表开始状态S,而文法中的开始符号对应的结点为结束状态。
对于文法中的每一条形如U->a的规则,画一条从结点S指向结点U的弧线,并在弧上标记a。
对于文法中每一条形如U->Wa的规则,画一条从结点W指向结点U的弧线,并在弧上标记a。
例:
G[Z]: Z->U0|V1 U->Z1|1 V->Z0|0
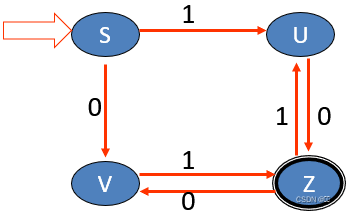
判断句子是否合法
例:上面的题目,根据上面的状态图对句子0110进行分析
| 步骤 | 状态 | 扫描的字符 | 余留部分 |
|---|---|---|---|
| 1 | S | 0 | 110 |
| 2 | V | 1 | 10 |
| 3 | Z | 1 | 0 |
| 4 | U | 0 | |
| 5 | Z |
语法分析
FIRST集合和FOLLOW集合
FIRST
操作方法:
-
相应字母在->左边,查找->右边第一个东西
-
可以对终结符号(Vt)、非终结符号(Vn)、符号串求FIRST集
-
可以有ε,没有#
例子:
E->TE' E'->+TE' E'->ε T->FT' T'->*FT' T'->ε F->(E)|i
该文法非终结符号为{E,E’,T,T’,F}
FIRST(E) = FIRST(T) = FIRST(F) = { ( ,i }
FIRST(E’) = { + ,ε }
FIRST(T’) = { * ,ε }
求文法中各产生式右部符号串的FIRST集:
FIRST(TE’) = FIRST(T) = FIRST(F) = { ( ,i }
FIRST(+TE’) = { + }
FIRST(ε) = { ε }
FIRST(FT’) = FIRST(F) = { ( ,i }
FIRST(*FT’) = { * }
FIRST((E)) = { ( }
FIRST(i) = { i }
FOLLOW
操作方法:
-
相应字母在→右边,查找相应字母的右边的东西
-
对非终结符号求FOLLOW集,没有ε,可以有#
注意规则
若A是文法的开始符号,令#∈FOLLOW(A)。
若有产生式B→Aα,则将终结符α加进FOLLOW(A)
若有产生式B→αAC,则将FIRST(C)中的一切非ε符号加进FOLLOW(A)。
若有产生式B→αA、或B→αAC且ε∈FIRST(C),则FOLLOW(B)中的全部元素均属于FOLLOW(A)。
例子:
G(E): E->TE' E'->+TE'|ε T->FT' T'->*FT'|ε F->(E)|i
| FIRST | FOLLOW |
|---|---|
| FIRST(E)={(, i} | FOLLOW(E)={#, )} |
| FIRST(E')={+, ε} | FOLLOW(E')=FOLLOW(E)∪FOLLOW(E')={#, )} |
| FIRST(T)={(, i} | FOLLOW(T)=FIRST(E')∪FOLLOW(E)∪FOLLOW(E')={+, #, )} |
| FIRST(T')={*, ε} | FOLLOW(T')=FOLLOW(T)∪FOLLOW(T')={+, #, )} |
| FIRST(F)={(, i} | FOLLOW(F)=FIRST(T')∪FOLLOW(T)∪FOLLOW(T')={*, +, ), #} |
递归下降分析以及存在的问题
左递归
对于非终结符A,存在A=+>Aα(解决办法:EBNF、右递归)
例:E->E+T|T
-
EBNF:E -> T{+T}
-
右递归:E->TE', E'->+TE'|ε
回溯
间接左递归会产出回溯
假设文法中有规则U::=xV|xW
-
提取公因子,将规则变成U::=x(V|W)
-
加入一个新的非终结符号A,令A=V|W,则将规则改为:U::=xA,A::=V|W
语法制导翻译
活动序列、翻译文法、对偶的含义
翻译文法
-
定义:在描述语言文法规则的右部适当位置加入动作符号得到的。
-
例:若输入串是a+b*c,输出abc*+,则翻译器的输入输出动作是:
READ(a)PRINT(a)READ(+)READ(b)PRINT(b)READ(*)READ(C)PRINT(C)PRINT(*)PRINT(+)
在该序列中,若用输入符号本身直接表示读操作,用@表示输出操作,则上述序列可简化为: a@a+b@bc@c@@+
活动序列
-
上面例子中a@a+b@bc@c@@+,这种带有@的符号串称为活动序列
-
•称@为动作符号标记,由符号@开始的符号串称为一个动作符号。
-
上面的活动序列中就有5个动作符号,分别为:@a,@b,@c,@*,@+
对偶
由给定翻译文法所定义的翻译(输入序列,动作序列)
例:上述例子中,输入序列为a+b*c,动作序列@a@b@c@*@+,对偶为(a+b*c,@a@b@c@*@+)
符号的属性
-
符号的属性分综合属性和继承属性两种
-
综合属性:使用↑表示
-
自底向上传递信息
-
根据产生式右部符号的属性计算左部符号的综合属性
-
语法树:根据该节点自身的属性和其子节点的属性来计算该节点的综合属性
-
-
继承属性:使用↓表示
-
自顶向下传递信息
-
根据产生式右部符号的属性和左部符号的属性计算右部符号的继承属性
-
语法树:根据该节点自身的属性和其父节点、兄弟节点的属性来计算该节点的继承属性
-
例:S->E↑q@ANSWER↓r
属性计算语法树
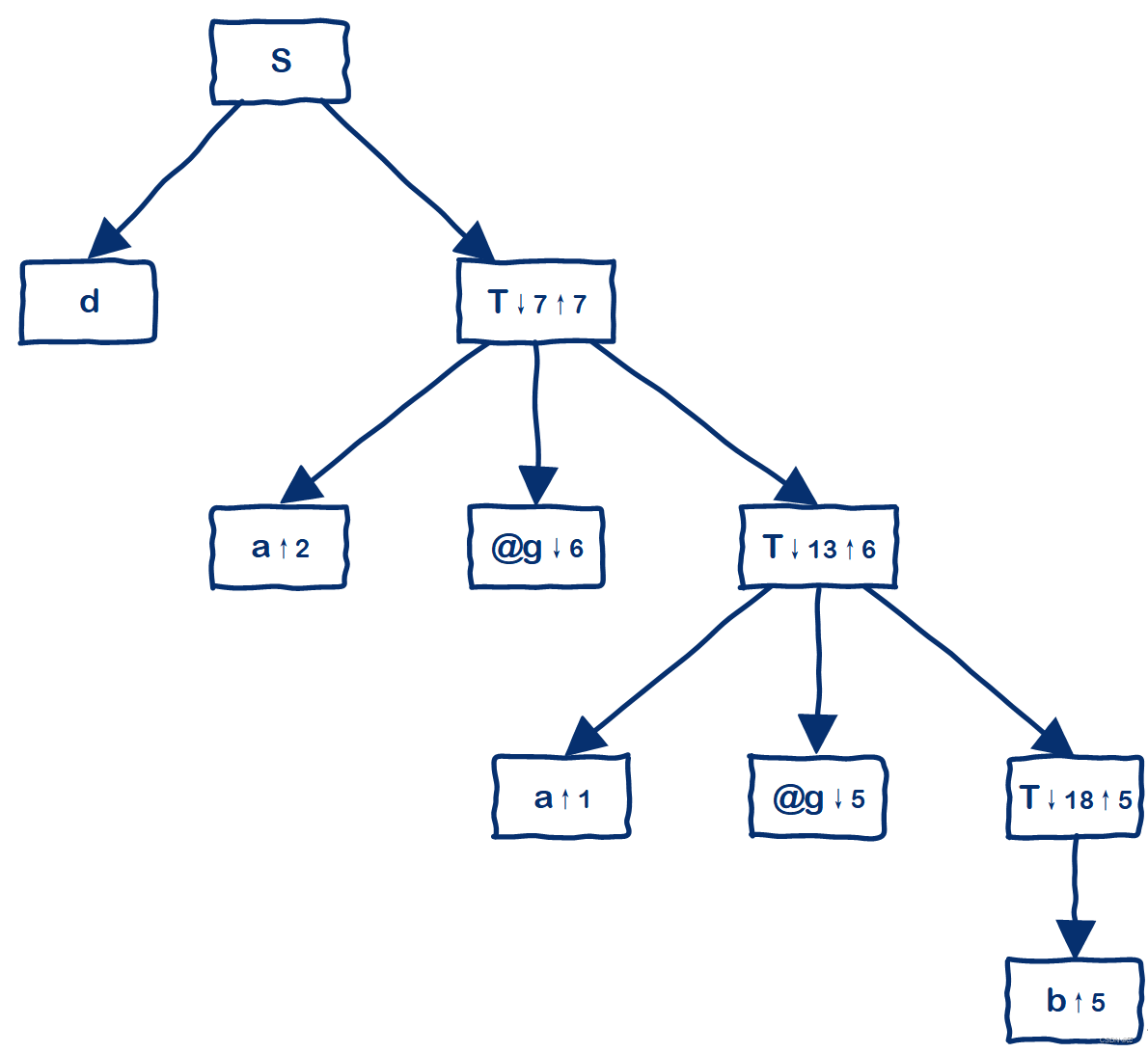
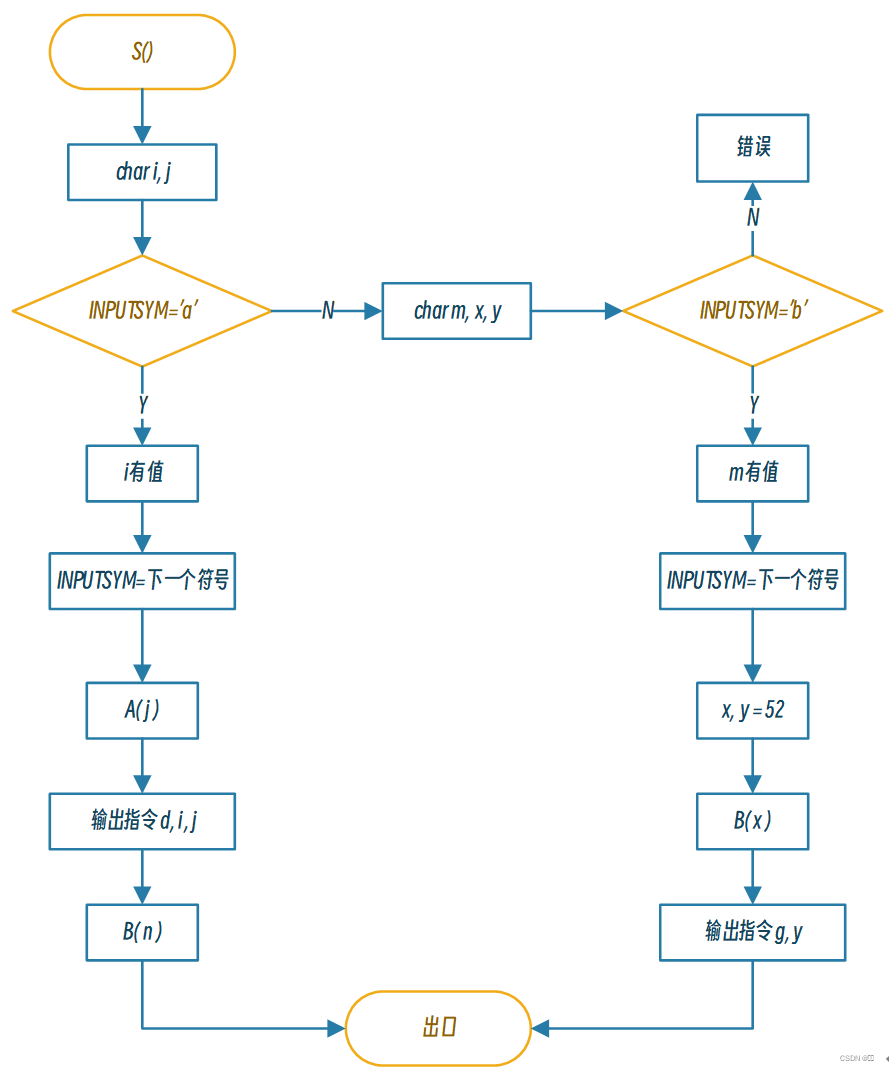
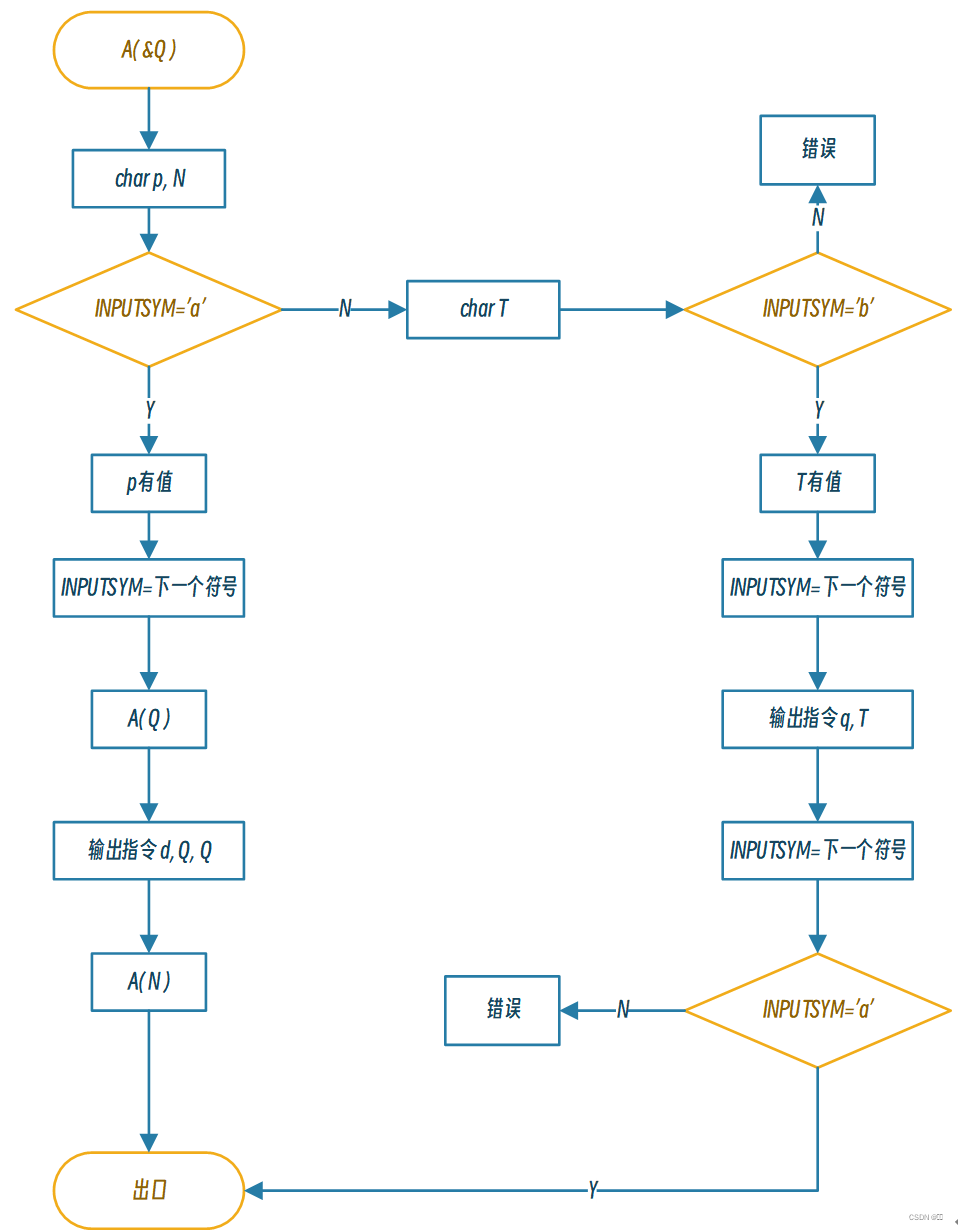
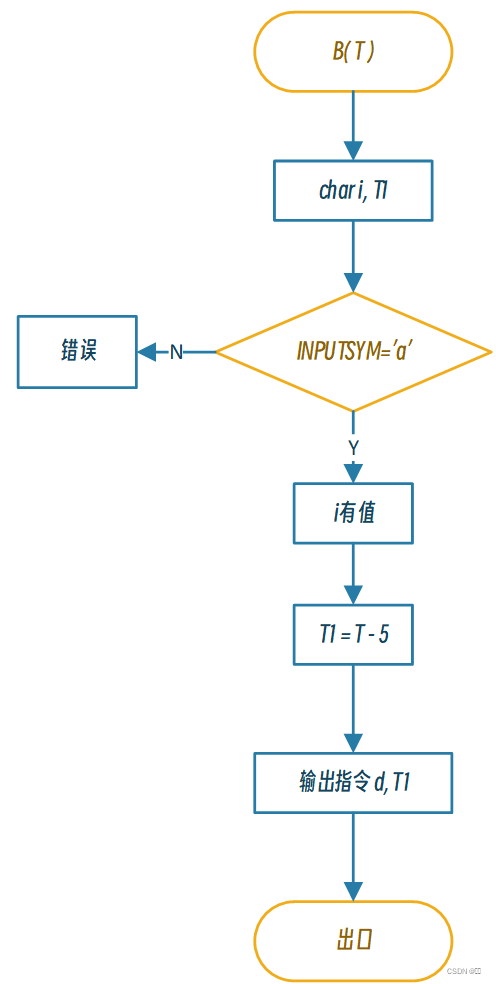
递归下降翻译处理(流程图)
















 657
657

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









