




 本文详细介绍了Spark的RDD(弹性分布式数据集)的核心特性,包括RDD的五大特性,如数据本地性、计算逻辑和依赖管理。讨论了如何创建RDD,如从现有集合或Hadoop文件系统,以及如何自定义分区。还深入讲解了RDD的分区策略,如默认分区和自定义分区器。此外,文章还涵盖了RDD之间的依赖关系,包括窄依赖和宽依赖,以及shuffle过程和stage划分。最后,探讨了RDD的持久化、checkpoint机制以及如何利用共享变量(如累加器和广播变量)来优化性能。
本文详细介绍了Spark的RDD(弹性分布式数据集)的核心特性,包括RDD的五大特性,如数据本地性、计算逻辑和依赖管理。讨论了如何创建RDD,如从现有集合或Hadoop文件系统,以及如何自定义分区。还深入讲解了RDD的分区策略,如默认分区和自定义分区器。此外,文章还涵盖了RDD之间的依赖关系,包括窄依赖和宽依赖,以及shuffle过程和stage划分。最后,探讨了RDD的持久化、checkpoint机制以及如何利用共享变量(如累加器和广播变量)来优化性能。
RDD五大特性
A list of partitions
RDD是一个由多个partition(某个节点里的某一片连续的数据)组成的的list;将数据加载为RDD时,一般会遵循数据的本地性(一般一个hdfs里的block会加载为一个partition)。A function for computing each split
一个函数计算每一个分片,RDD的每个partition上面都会有function,也就是函数应用,其作用是实现RDD之间partition的转换。A list of dependencies on other RDDs
RDD会记录它的依赖 ,依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作时出错或丢失会进行重算。Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
可选项,如果RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区,例如这里自定义的Partitioner是基于key进行分区,那则会将不同RDD里面的相同key的数据放到同一个partition里面Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
可选项,最优的位置去计算,也就是数据的本地性。(移动计算而不是移动数据)
RDD创建
宏观上看,每个Spark应用程序都由一个驱动程序组成,该驱动程序运行用户的main方法,并在集群上执行各种并行操作。Spark提供的主要抽象是一个弹性分布式数据集(RDD),它是跨集群节点划分的元素集合,可以并行操作。rdd是通过从Hadoop文件系统(或任何其他Hadoop支持的文件系统)中的一个文件或驱动程序中现有的Scala集合开始创建的,并对其进行转换。用户还可能要求Spark在内存中持久化一个RDD,以便在多个并行操作中有效地重用它。并且,rdd可以自动从节点故障中恢复。
-
从驱动程序中现有的Scala集合开始创建
def createFromMemory() = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD1") val sc = new SparkContext(sparkConf) val data = Array(1, 2, 3, 4, 5) //val distData = sc.parallelize(data) // 底层调用parallelize val distData = sc.makeRDD(data) distData.collect().foreach(println) sc.stop() } -
通过从Hadoop文件系统(或任何其他Hadoop支持的文件系统)中的一个文件创建
def createFromFile() = { val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD2") val sc = new SparkContext(sparkConf) // path路径默认以当前环境的根路径(SparkLearning)为基准 val rddFile = sc.textFile("datas") // wholeTextFiles 返回元组 含文件位置信息,整个文件的内容 val rddWholeFile = sc.wholeTextFiles("datas") rddFile.collect().foreach(println) rddWholeFile.collect().foreach(println) sc.stop() } }
RDD分区
默认分区数量
如果是本地模式,默认分区数量就是本机的cpu核心总数。 standalone 或者 yarn 模式,默认分区数就取集合所有cpu的核心总数与2的较大值。
- parallelize()方法创建RDD时的分区
分区规则相关源码:

import org.apache.spark.{SparkConf, SparkContext}
object ParallelRdd {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("App")
val sc = new SparkContext(sparkConf)
// 并行度/分区
// 【1】,【2,3】,【4,5】
val rdd = sc.parallelize(
List(1, 2, 3, 4, 5), 3
)
rdd.saveAsTextFile("output")
sc.stop()
}
}
- textFile()方法读取文件分区数量计算
spark对文件的读取底层其实就是hadoop对文件的读取

hadoop分片时,当剩余数据小于分片的10%时,会和另一个分片合并
当剩余数据大于分片的10%时,会产生一个新的分片

import org.apache.spark.{SparkConf, SparkContext}
object ParallelRdd {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("App")
val sc = new SparkContext(sparkConf)
/*
默认最小分区数
def defaultMinPartition = math.min(defaultParallelism,2)
默认实际分区数
见图
*/
val rdd = sc.textFile("datas",3)
rdd.saveAsTextFile("output")
sc.stop()
}
}
RDD自定义partitioner
import org.apache.spark.{Partitioner,SparkConf,SparkContext}
/**
* 自定义分区器
* @param partitions 分区数量
*/
class MyPartitioner(partitions: Int) extends Partitioner {
override def numPartitions: Int = partitions
/**
* 自定义分区规则 返回分区id
* @param key RDD中没条数据的key值
* @return 分区ID
*/
override def getPartition(key: Any): Int = {
// 分区规则
key.toString.toInt % numPartitions
}
}
/**
* 使用自定义分区器对数据进行分区
*/
object TestMyPartitioner {
def main(args : Array[String]) : Unit = {
val conf = new SparkConf()
conf.setAppName("test")
conf.setMaster("local[*]")
val sc = new SparkContext(conf)
val data = sc.parallelize(1 to 5)
data.map((_,1)).partitionBy(new MyPartitioner(5)).saveAsTextFile("output")
}
}
RDD依赖
在spark中,对RDD的每一次转化操作都会生成一个新的RDD,由于RDD的懒加载特性,新的RDD会依赖原有的RDD,因此RDD之间存在类似流水线的前后依赖关系。这种依赖关系分为两种:窄依赖和宽依赖。
-
窄依赖
父RDD的一个分区最多被子RDD的一个分区所用。例如map(),filter(),union()。 -
宽依赖
父RDD的一个分区被子RDD的多个分区所用。例如groupByKey(),reduceByKey(),sortByKey()。
Shuffle
在宽依赖中,RDD会根据每条记录的key进行不同的分区数据聚集,数据聚集的过程称作shuffle。spark中的shuffle就是不同分区之间的数据聚集或者说数据混洗。shuffle是一项耗费资源的操作,
它涉及磁盘I/O,数据序列化和网络I/O。因为聚合的数据可能不在同一个分区,甚至不在同一个节点上。
Stage
将rdd间的依赖关系用带方向的直线表示,会形成一个关于计算路径的有向无环图。Spark会根据DAG将整个计算阶段分成多个阶段,每个阶段就是一个stage,每个stage由多个task任务并行计算。每个task任务作用在一个分区上。stage的划分依据为是否有宽依赖,即是否有shuffle。
RDD持久化
Spark中的RDD是懒加载的,只有当遇到行动算子时才会从头计算所有RDD。而且当同一个RDD被多次使用时,每次都需要重新计算一遍,这样会严重增加消耗。为了避免重复计算同一个RDD,可以将RDD持久化。
可以在RDD上使用persist()或cache()方法来标记要持久化的RDD(cache()底层就是调用persist()。在第一次行动操作时将对数据进行计算,并缓存在节点的内存中。spark的缓存是容错的:如果缓存的RDD的任何分区丢失,spark就会按照该RDD庲的转换过程自动重新计算并缓存。
RDD的部分存储级别(只有persist()方法可以自定义存储级别):
MEMORY_ONLY只存储在内存中,如果内存不够,部分分区不会被缓存。MEMORY_AND_DISK先存储到内存,将溢出的数据存储到磁盘。DISK_ONLY只存储在磁盘上
var rdd = sc.parallelize(List(1,2,3,4,5))
// 默认存储级别为 StorageLevel.MEMORY_ONLY
rdd.persist()
// rdd.persist(StorageLevel.DISK_ONLY)
// rdd.persist(StorageLevel.MEMORY_AND_DISK)
// 第一次行动算子计算时,将对标记为持久化的RDD进行持久化操作
val res = rdd.collect()
// 第二次行动算子计算时,将直接从持久化的目的地读取数据进行操作,而不是从头开始计算
rdd.collect()
同时,Spark自动监视每个节点上的缓存使用情况,并以最近最少使用(LRU)的方式丢弃旧的数据分区。如果要手动删除RDD而不是等待它被丢弃,请使用RDD.unpersist()方法。
checkpoint
流应用程序必须全天候运行,因此必须考虑与应用程序逻辑无关的故障(例如,系统故障、JVM崩溃等)修复。所以Spark Streaming需要对容错存储系统进行足够的信息检查点,以便从故障中恢复。
与RDD的持久化persist的区别:
- persis将数据存储于机器本地的内存或磁盘,当机器发生故障时无法对数据进行恢复,而checkpoint是将RDD数据存储于外部的共享文件系统(例如HDFS),共享文件系统的副本机制保证了数据的可靠性。
- 在spark应用程序结束后,persist存储的数据将被清空,而checkpoint存储的数据可以永久存在。因此persist只能用于当前spark应用程序,而checkpoint可以用于下一个spark应用程序。
所以综合看来,persist的存在旨在减少重复计算以及加快数据读取的速度,加快程序执行。而checkpoint更多是为了故障修复而存在的。
相关代码段:
// 设置检查点数据存储路径
sc.setCheckpointDir("hdfs://master:8020/spark-ck")
// 标记为checkpoint
resRdd.checkpoint()
// 在第一次行动算子计算时,将把标记为checkpoint的数据存储到文件系统指定路径中
Spark建议,在将RDD标记为checkpoint之前,最好将RDD持久化到内存,因为spark将单独启动一个任务将标记为checkpoint的RDD的数据写入文件系统,如果RDD的数据已经持久化到了内存,将直接从内存中读取数据,然后进行写入,提高数据写入效率,否则需要重复计算一遍RDD的数据。
共享变量
Spark算子中的函数func会被发送到远程的多个Worker节点上执行,如果一个算子中使用了某个外部变量,该变量就会被复制到Worker节点的每个Task任务重,各个Task任务对变量的操作相互独立。
累加器
累加器提供了将Worker节点的值聚合到Driver的功能,可以用于实现计数和求和。
由于sum变量在Driver中定义,而累加操作sum+=x会发送到Executor中执行,因此输出结果不正确。
var sum=0
var rdd=sc.makeRDD(Array(1,2,3,4,5))
rdd.foreach(x=>sum+=x)
println(sum) // 输出0
使用累加器对数组进行求和。累加器只能在Driver端定义,在Executor端更新。
val myacc=sc.longAccumulator("My Accumulator")
val rdd=sc.makeRDD(Array(1,2,3,4,5))
rdd.foreach(x=>myacc.add(x))
println(myacc.value) // 输出15
广播变量
广播变量将一个变量通过广播的形式发送到每个Worker节点的缓存中,而不是发送到每个Task任务中,各个task任务可以共享该变量的数据。因此,广播变量是只读的。
-
默认情况下的变量的传递
代码中传递给
map()算子的函数line=>(line,arr)会被发送到Executor端执行,而变量arr将发送到Worker节点的所有Task任务中。

val arr = Array(1,2,3,4,5) val lines = sc.textFile(Path) val res = lines.map(line => (line, arr)) -
使用广播变量时变量的传递
使用
broadcast()方法向集群广播了一个只读变量,该方法只发送一次,缓存在集群的每个Worker节点中。Worker节点的每个Task任务共享唯一的一份广播变量,大大减少了网络传输和内存开销。
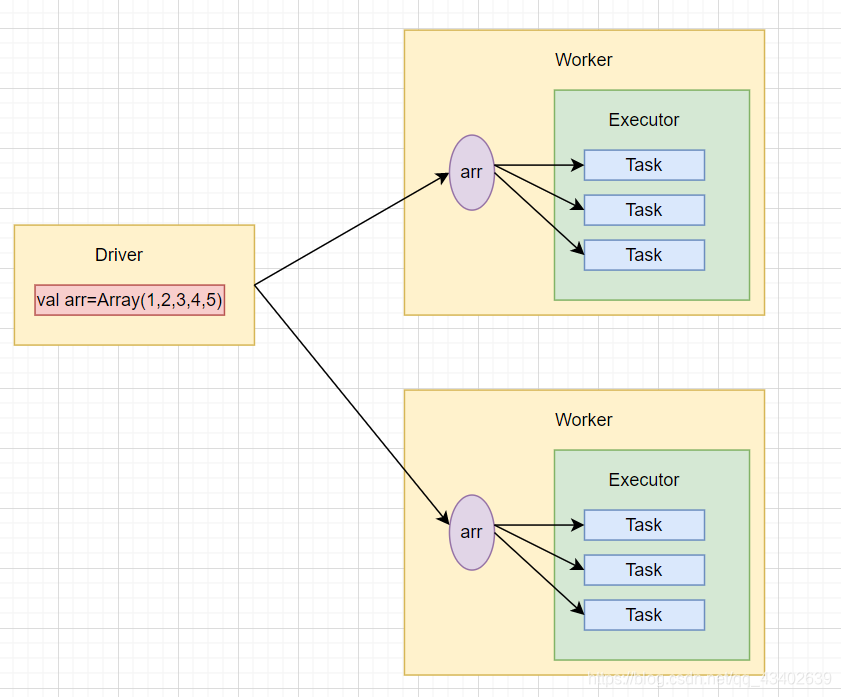
val arr = Array(1,2,3,4,5) var broadcastVar = sc.broadcast(arr) val lines = sc.textFile(Path) val res = lines.map(line => (line, broadcastVar))
代码来源教材:spark大数据分析实战

















 747
747

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









