







视频地址:https://www.bilibili.com/video/BV11A411L7CK?p=25
参考教材:Spark大数据分析实战
文章内容:
- 在maven上部署spark依赖,运行wordcount
- 上传jar包在集群上运行wordcount
- map & flatMap
wordcount流程:


5. maven项目
用maven构建spark运行环境
项目依赖pom.xml
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.1</version>
</dependency>
</dependencies>
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext};
object WordCount {
def main(args: Array[String]): Unit = {
// 建立和spark框架的连接 连接配置
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount");
val sc = new SparkContext(sparkConf);
// 执行业务操作
// 1. 读取文件 获取一行一行数据
val lines:RDD[String] = sc.textFile("datas");
// 2. 将一行数据进行拆分 扁平化
// val words = lines.flatMap(_.split(" "))
val words:RDD[String] = lines.flatMap(line=>{line.split(" ")});
// 3. 将原数据映射为我们想要的的数据
val wordToOne = words.map(
word => (word,1)
)
// 4. 在新数据上聚合计算
val wordCount = wordToOne.reduceByKey((x,y)=>x + y)
// 5. 打印结果
val array = wordCount.collect()
//array.foreach(println)
array.foreach(item => println(item))
// 关闭连接
sc.stop();
}
}
- 在集群上运行
打包jar
package my.test
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Spark RDD单词计数程序
*/
object WordCount {
def main(args: Array[String]): Unit = {
//创建SparkConf对象
val conf = new SparkConf()
//设置应用程序名称,可以在Spark WebUI中显示
conf.setAppName("Spark-WordCount")
//设置集群Master节点访问地址
conf.setMaster("yarn");
//创建SparkContext对象,该对象是提交Spark应用程序的入口
val sc = new SparkContext(conf);
//读取指定路径(取程序执行时传入的第一个参数)中的文件内容,生成一个RDD集合
val linesRDD: RDD[String] = sc.textFile(args(0))
//将RDD数据按照空格进行切分并合并为一个新的RDD
val wordsRDD: RDD[String] = linesRDD.flatMap(_.split(" "))
//将RDD中的每个单词和数字1放到一个元组里,即(word,1)
val paresRDD: RDD[(String, Int)] = wordsRDD.map((_, 1))
//对单词根据key进行聚合,对相同的key进行value的累加
val wordCountsRDD: RDD[(String, Int)] = paresRDD.reduceByKey(_ + _)
//按照单词数量降序排列
val wordCountsSortRDD: RDD[(String, Int)] = wordCountsRDD.sortBy(_._2, false)
//保存结果到指定的路径(取程序执行时传入的第二个参数)
wordCountsSortRDD.saveAsTextFile(args(1))
//停止SparkContext,结束该任务
sc.stop();
}
}
打包得到一个.jar文件
wordcount.jar
传到集群上,启动dfs和yarn,用spark on yarn模式运行
首先在hdfs上创建一个 input文件夹存放输入数据
1.提交任务

2. 运行过程部分截图
提交任务到resourcemanager,RM选择节点分配container,并要求其启动AppMaster
AM开始启动任务
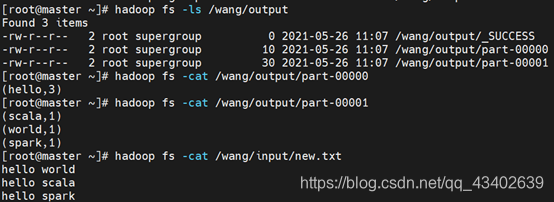
3. 结果
到对应output文件查看结果
map & flatMap
In Scala, flatMap() method is identical to the map() method, but the only difference is that in flatMap the inner grouping of an item is removed and a sequence is generated. It can be defined as a blend of map method and flatten method. The output obtained by running the map method followed by the flatten method is same as obtained by the flatMap(). So, we can say that flatMap first runs the map method and then the flatten method to generate the desired result.
map + flatten => flatMap
scala> val name = Seq("HELLO","WORLD")
name: Seq[String] = List(HELLO, WORLD)
scala> val res1 = name.map(_.toLowerCase)
res1: Seq[String] = List(hello, world)
scala> val res2 = res1.flatten
res2: Seq[Char] = List(h, e, l, l, o, w, o, r, l, d)
scala> name.flatMap(_.toLowerCase)
res0: Seq[Char] = List(h, e, l, l, o, w, o, r, l, d)
flatMap
scala> val text = List[String]("hello world","hello scala")
text: List[String] = List(hello world, hello scala)
scala> text.flatMap(_.split(" "))
res1: List[String] = List(hello, world, hello, scala)
RDD算子:https://blog.csdn.net/qq_43402639/article/details/117288236














 1669
1669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









