







要用到的工具和依赖
| scrapy | mysql 8.0.19 |
|---|---|
| pymysql | pytharm编辑器 |
在mysql里创建python001数据库,然后创下面的表
CREATE TABLE `movie_douban` (
`id` int NOT NULL AUTO_INCREMENT,
`movie_name` text NOT NULL COMMENT '电影名',
`introduce` text NOT NULL COMMENT '电影介绍',
`star` text NOT NULL COMMENT '电影评分',
`evaluate` text NOT NULL COMMENT '电影评论数',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
要耐心的看哟
第一步
当你都安装好上面的工具和依赖就和可在终端初始scrapy项目啦
#项目名为 two
scrapy startproject two
运行上面命令它会自动创建一个文件夹,然后用pytharm打开它,
然后在终端输入下面的命令就会得到上面的movie_douban.py文件(🦐记得是在spiders目录下输入哟🦐)
#moive_douban :爬虫的名字, movie.douban.com:要爬的域名
scrapy genspider movie_douban movie.douban.com
在项目更目录下创建start.py文件,在文件内写入以下代码(这个文件是方便我们在pycharm运行这个爬虫)
from scrapy import cmdline
cmdline.execute("scrapy crawl movie_douban".split())
如果你不写入上面文件也是个可以的,但你运行爬虫时必须在spiders目录终端下输入下面命令才能运行爬虫程序
scrapy crawl movie_douban
然后到settings.py文件里把一下代码的注释去掉,并找到在DEFAULT_REQUEST_HEADERS里加入请求头信息(User-Agent),把ROBOTSTXT_OBEY改为 False(ROBOTSTXT_OBEY = False)
ITEM_PIPELINES = {
'two.pipelines.TwoPipeline': 300,
}

弄好上面的步骤我们就到豆瓣网站看看
我们要爬的网站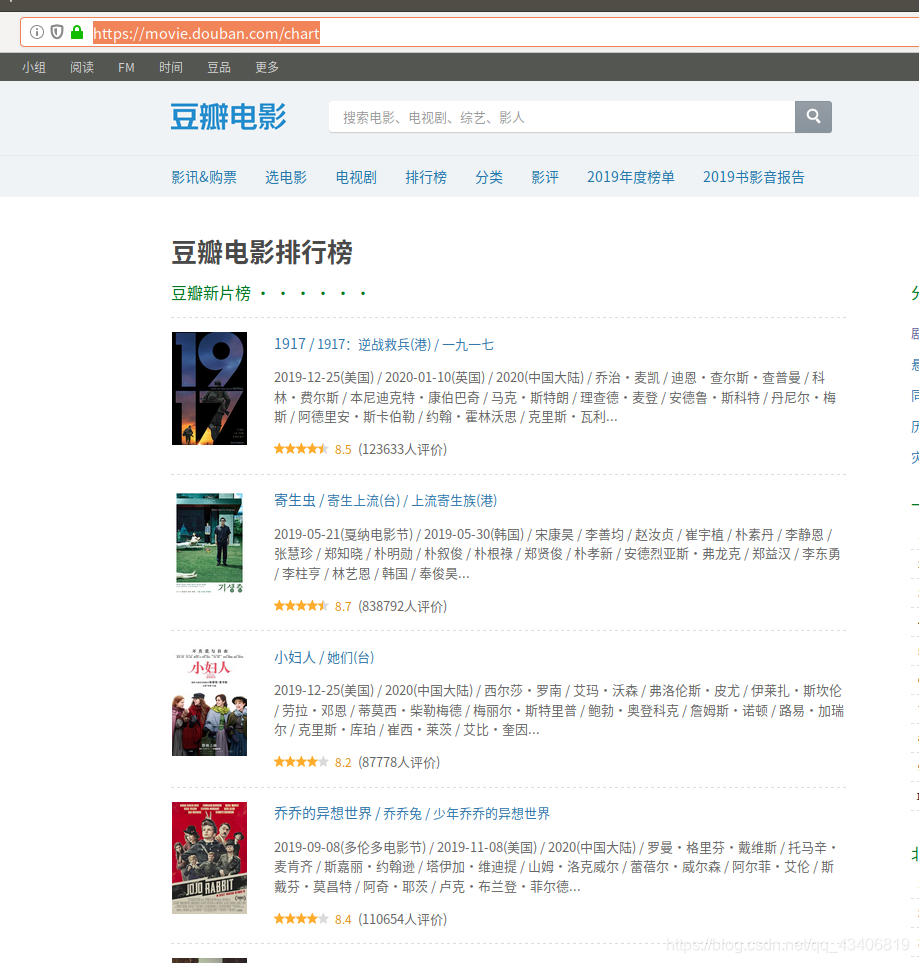
然后我们复制网站的网址到我们的spiders目录下的movie_douban.py文件里
其内容为
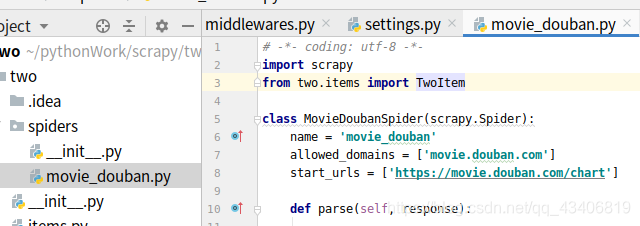
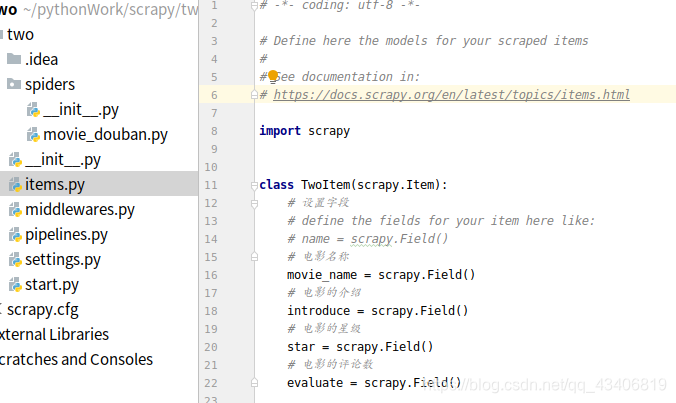
然后我们到items.py写入以下内容哦(里面是我们要存入mysql用到的键值对)
import scrapy
class TwoItem(scrapy.Item):
# 设置字段
# define the fields for your item here like:
# name = scrapy.Field()
# 电影名称
movie_name = scrapy.Field()
# 电影的介绍
introduce = scrapy.Field()
# 电影的星级
star = scrapy.Field()
# 电影的评论数
evaluate = scrapy.Field()
分析我们要的数据在网站的位置
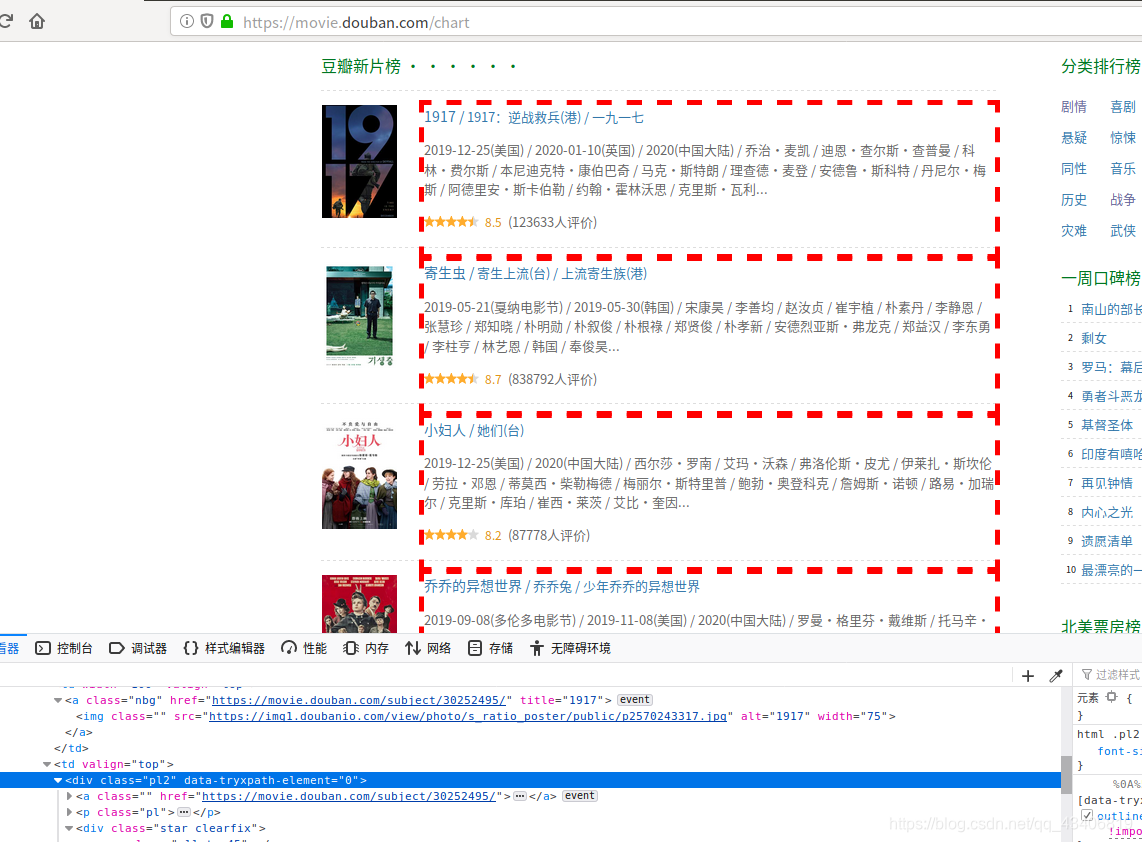
通过查看元素我们可知道我们要的数据在一个有class='pl2’的div里,那我们就用它作我们爬虫时循环爬下里面的数据,此时我们应该在movie_douban.py文件里的parse函数写下以下代码:
#获取包含我们想要数据的div,这里我们用xpath语法来定位
all_movie = response.xpath("//div[@class='pl2']")
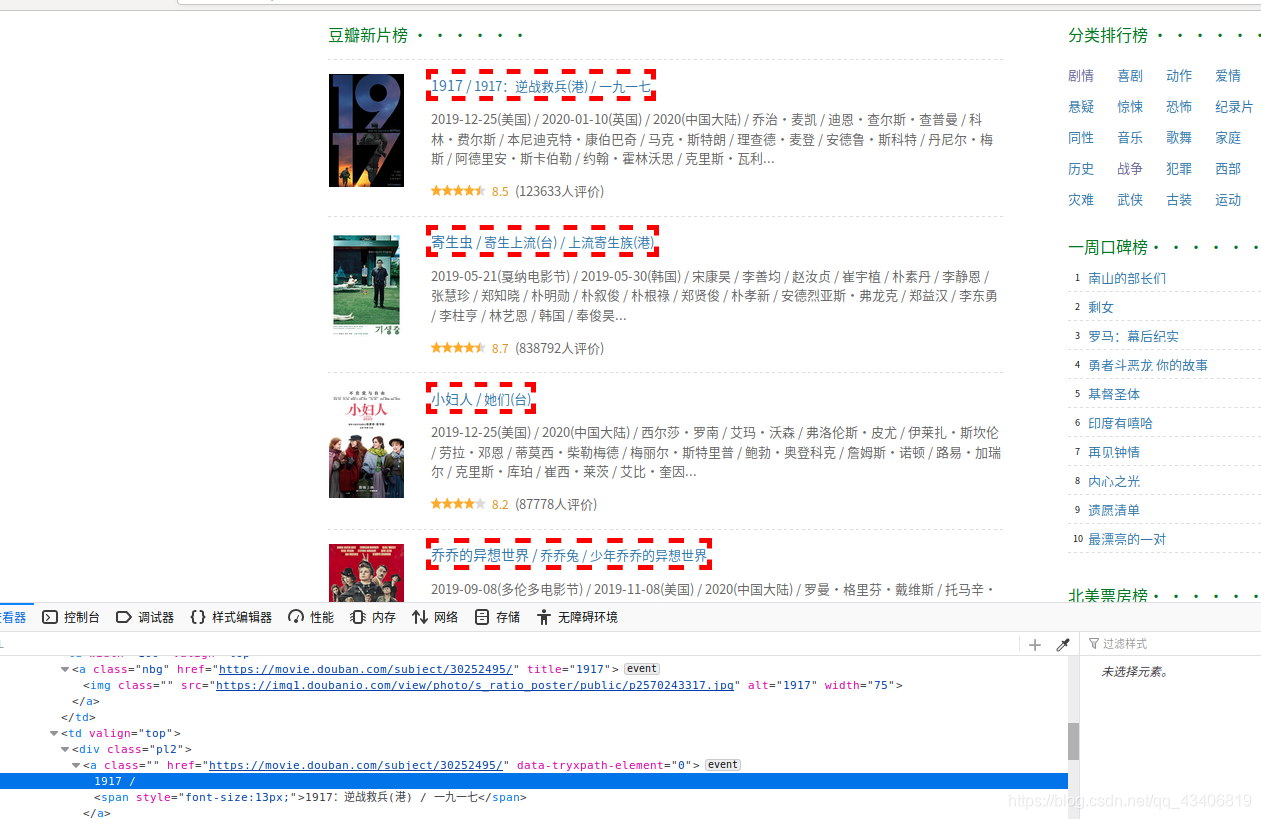
然后我通过分析得到电影名在刚刚div下的一个a标签里所以我们可以这样描述电影名的位置
#这里我们得清洗一下数据否着它连标签也会
name = ''.join(有的i.xpath("./a//text()").get().split())
item['movie_name'] = ''.join(name.split('/'))
其它评分,电影描述等我们到可以分析得到,我们直接看movie_douban.py的代码应该写下这样的内容:
import scrapy
#导入刚刚我们写的itmes.py文件
from two.items import TwoItem
class MovieDoubanSpider(scrapy.Spider):
这个爬虫的名字
name = 'movie_douban'
#要爬的域名
allowed_domains = ['movie.douban.com']
#开始爬的url
start_urls = ['https://movie.douban.com/chart']
def parse(self, response):
# 返回帕取下来的网页
# print(response.text)
#包涵我们要的数据div位置
all_movie = response.xpath("//div[@class='pl2']")
item = TwoItem()
for i in all_movie:
name = ''.join(i.xpath("./a//text()").get().split())
把清洗好的电影名赋我们等下要给mysql传值的对象
item['movie_name'] = ''.join(name.split('/'))
content = i.xpath("./p//text()").get()
#电影的介绍
item['introduce'] = content
#电影的星级
item['star'] = i.xpath("./div/span[@class='rating_nums']//text()").get().split()
#电影的评论数
item['evaluate'] = i.xpath("./div/span[@class='pl']//text()").get()
把数据传到pipelines.py文件里的process_item函数
yield item
保存爬取的数据
到这里我们就要保存数据啊,scrapy保存数据是在pipelines里保存的,所以我们以下的代码要写入pipelines.py文件里
# -*- coding: utf-8 -*-
#导入mysql的依赖
import pymysql
class TwoPipeline(object):
def __init__(self):
print('开始拉')
#连接mysql的ip、用户名、密码、数据库编码
self.sql = pymysql.connect('localhost','用户名','密码','python001',charset='utf8')
#获取游标
self.cursor = self.sql.cursor()
def process_item(self, item, spider):
#插入sql语句
data = "insert into movie_douban ( movie_name, introduce, star,evaluate ) values (%s, %s, %s, %s)"
#data里的%s就是对应的以下的itme['xxx'],他们都是我们在itmes里定义好的
value = (item['movie_name'],item['introduce'],item['star'],item['evaluate'])
#打印一下看看是否有数据
print(item['movie_name'])
try:
#执行刚刚的sql语句
self.cursor.execute(data,value)
#提交事务
self.sql.commit()
except:
self.sql.rollback()
return item
def close_spider(self,spider):
# self.fp.close()
#关闭游标和mysql数据库
self.cursor.close()
self.sql.close()
print('爬虫结束')
然好到start.py文件右击运行start就可以运行这个爬虫了
好啦到此结束啦!
以下是爬取数据的展览


如果有侵权请联系博主,我会第一时间删掉















 426
426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









