







序列化
-
自定义一些对RDD的操作时,初始化工作是在Driver端进行的,实际运行程序是在Executor端进行的,此时,涉及到了进程之间的通信,需要进行序列化。可以简单的认为SparkContext代表Driver。
-
普通的类不具备序列化能力,但也有相应的解决方案
-
如果在方法、函数的定义中引用了不可序列化的对象,也会导致任务不能序列化,延迟创建的解决方案较为简单,适用性广
import org.apache.spark.{SparkConf, SparkContext} class MyClass1(x: Int){ val num: Int = x } case class MyClass2(num: Int) class MyClass3(x: Int) extends Serializable { val num: Int = x } object SerializableDemo { def main(args: Array[String]): Unit = { // 初始化 val conf = new SparkConf().setAppName(this.getClass.getCanonicalName.init).setMaster("local[*]") val sc = new SparkContext(conf) sc.setLogLevel("WARN") val o1 = new MyClass1(8) // println(s"o1.num = ${o1.num}") val rdd1 = sc.makeRDD(1 to 20) // 方法 def add1(x: Int) = x + 100 // 函数 val add2 = add1 _ // 函数、方法都具备序列化和反序列化的能力 // rdd1.map(add1(_)).foreach(println) // println("****************************************************") // rdd1.map(add2(_)).foreach(println) val object1 = new MyClass1(20) val i = 20 // rdd1.map(x => object1.num + x).foreach(println) // 解决方案一:使用case class val object2 = MyClass2(20) // rdd1.map(x => object2.num + x).foreach(println) // 解决方案二:MyClass1 实现 Serializable 接口 val object3 = new MyClass3(20) rdd1.map(x => object3.num + x).foreach(println) // 解决方案三:延迟创建 println("解决方案三:延迟创建") lazy val object4 = new MyClass1(20) rdd1.map(x => object4.num + x).foreach(println) sc.stop() } }
RDD依赖关系
-
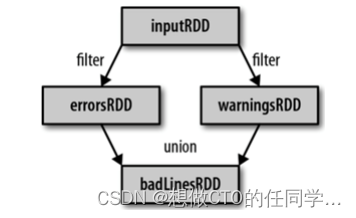
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。
-
RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,可根据这些信息来重新运算和恢复丢失的数据分区。
-
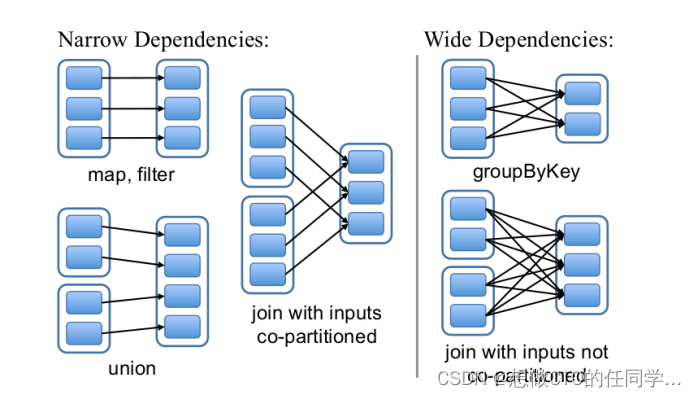
RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrowdependency)和宽依赖(wide dependency)。 窄依赖:1:1 或 n:1。宽依赖:n:m;意味着有 shuffle
-
依赖有2个作用:其一用来解决数据容错;其二用来划分stage。
-
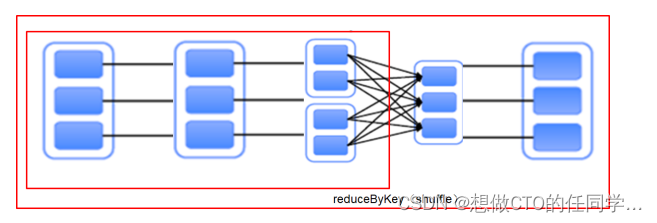
DAG(Directed Acyclic Graph) 有向无环图。原始的RDD通过一系列的转换就就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage:
- 对于窄依赖,partition的转换处理在Stage中完成计算
- 对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算
- 宽依赖是划分Stage的依据
-
RDD任务切分中间分为:Driver programe、Job、Stage(TaskSet)和Task
- Driver program:初始化一个SparkContext即生成一个Spark应用
- Job:一个Action算子就会生成一个Job
- Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage
- Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task
- Task是Spark中任务调度的最小单位;每个Stage包含许多Task,这些Task执行的计算逻辑相同的,计算的数据是不同的
- 注意:Driver programe->Job->Stage-> Task每一层都是1对n的关系。
RDD持久化/缓存
-
缓存是将计算结果写入不同的介质,用户定义可定义存储级别(存储级别定义了缓存存储的介质,目前支持内存、堆外内存、磁盘);
-
通过缓存,Spark避免了RDD上的重复计算,RDD持久化或缓存是Spark构建迭代式算法和快速交互式查询的关键因素;
-
Spark速度非常快的原因之一,就是在内存中持久化(或缓存)一个数据集。当持久化一个RDD后,每一个节点都将把计算的分片结果保存在内存中,并在对此数据集(或者衍生出的数据集)进行的其他动作(Action)中重用。这使得后续的动作变得更加迅速;
-
使用persist()方法对一个RDD标记为持久化。之所以说“标记为持久化”,是因为出现persist()语句的地方,并不会马上计算生成RDD并把它持久化,而是要等到遇到第一个行动操作触发真正计算以后,才会把计算结果进行持久化;

-
通过persist()或cache()方法可以标记一个要被持久化的RDD,持久化被触发,RDD将会被保留在计算节点的内存中并重用;
-
一般情况下,如果多个动作需要用到某个 RDD,而它的计算代价又很高,那么就应该把这个 RDD 缓存起来;缓存有可能丢失,或者存储于内存的数据由于内存不足而被删除。RDD的缓存的容错机制保证了即使缓存丢失也能保证计算的正确执行。通过基于RDD的一系列的转换,丢失的数据会被重算。RDD的各个Partition是相对独立的,因此只需要计算丢失的部分即可,并不需要重算全部Partition。
-
persist()的参数可以指定持久化级别参数;使用cache()方法时,会调用persist(MEMORY_ONLY),即:
cache() == persist(StorageLevel.Memeory_ONLY) -
使用unpersist()方法手动地把持久化的RDD从缓存中移除;cache RDD 以 分区为单位;程序执行完毕后,系统会清理cache数据;
| 存储级别 | 描述 |
|---|---|
| MEMORY_ONLY | 将RDD 作为反序列化的对象存储JVM 中。如果RDD不能被内存装下,一些分区将不会被缓存并且在需要的时候被重新计算。 默认的缓存级别 |
| MEMORY_AND_DISK | 将RDD 作为反序列化的的对象存储在JVM 中。如果RDD不能被与内存装下,超出的分区将被保存在硬盘上,并且在需要时被读取 |
| MEMORY_ONLY_SER | 将RDD 作为序列化的的对象进行存储(每一分区一个字节数组)。 通常来说,这比将对象反序列化的空间利用率更高,读取时会比较占用CPU |
| MEMORY_AND_DISK_SER | 与MEMORY_ONLY_SER 相似,但是把超出内存的分区将存储在硬盘上而不是在每次需要的时候重新计算 |
| DISK_ONLY | 只将RDD 分区存储在硬盘上 |
| DISK_ONLY_2等带2的 | 与上述的存储级别一样,但是将每一个分区都复制到集群的两个结点上 |
RDD容错机制Checkpoint
- Spark中对于数据的保存除了持久化操作之外,还提供了检查点的机制;检查点本质是通过将RDD写入高可靠的磁盘,主要目的是为了容错。检查点通过将数据写入到HDFS文件系统实现了RDD的检查点功能。
- Lineage过长会造成容错成本过高,这样就不如在中间阶段做检查点容错,如果之后有节点出现问题而丢失分区,从做检查点的RDD开始重做Lineage,就会减少开销。
- cache 和 checkpoint 是有显著区别的,缓存把 RDD 计算出来然后放在内存中,但是 RDD 的依赖链不能丢掉, 当某个点某个 executor 宕了,上面 cache 的RDD就会丢掉, 需要通过依赖链重放计算。不同的是,checkpoint 是把 RDD 保存在 HDFS中,是多副本可靠存储,此时依赖链可以丢掉,所以斩断了依赖链。
- 当DAG中的Lineage过长,如果重算,则开销太大时,以及在宽依赖上做 Checkpoint 获得的收益更大时,很适合使用检查点机制,与cache类似 checkpoint 也是 lazy 的。
- checkpoint的文件作业执行完毕后不会被删除
val rdd1 = sc.parallelize(1 to 100000) // 设置检查点目录 sc.setCheckpointDir("/tmp/checkpoint") val rdd2 = rdd1.map(_*2) rdd2.checkpoint // checkpoint是lazy操作 rdd2.isCheckpointed // checkpoint之前的rdd依赖关系 rdd2.dependencies(0).rdd rdd2.dependencies(0).rdd.collect // 执行一次action,触发checkpoint的执行 rdd2.count rdd2.isCheckpointed // 再次查看RDD的依赖关系。可以看到checkpoint后,RDD的lineage被截断,变成从checkpointRDD开始 rdd2.dependencies(0).rdd rdd2.dependencies(0).rdd.collect //查看RDD所依赖的checkpoint文件 rdd2.getCheckpointFile















 429
429











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









