







6.8 等价类及其表示
6.8.1 等价关系与等价类
- 等价关系
等价关系是一个自反的、对称的和传递的关系。 - 等价类
- 一般地,一个集合S中的所有对象可以通过价关系划分为m个互不相交的子集S1,S2, …,Sm,即对于S中的任何两个元素x和y(x、y∈S),如果x和y是等价的(x≡y),则x和y被划分在同一个子集S中(i=1,2…,m)。这些子集被称为等价类。
- 利用等价关系把集合S划分成若干等价类的算法分以下两步走。
1)首先把S中的每一个对象看成是一个等价类。
2)依次处理各个等价对(x≡y):
若x∈S、 y∈S,且i≠j,则把集合Si,Sj合并成一个集合。

6.8.2 并查集
- 在把n个不同的元素的集合划分为若千个等价类时,先把每一个对象看作是一个单元素集合,然后依次将一个等价对中两个元素所在的集合合并。在此过程中将反复使用查找运算,确定两个元素所在的集合,并将两个集合合并。
- 能够完成查找、合并功能的集合就是并查集它支持以下三种操作。
- Ufsets(n):构造函数,将并查集中,个元索初始化为n个只有一个单元素的子集合。
- Union(S1,S2):把集合S2并入集合S1中。要求S2与S1,互不相交,否则没有结果。
3)Find(d): 查找单元素d所在的集合,并返回该集合的名字。
- 对于并查集来说,每个子集(等价类)用一棵树表示,子集合中每个元素用树中的一个结点表示。为了处理简单,用树的根结点来代表相应的等价类集合。
(1)在此,等价类树用双亲表示法表示(当然根据需要可以建立集合名字表示该集合的树的根结点之间的对应关系);此外,树的根结点的双亲域的值设为-k(parent=-k), 其中k为该树中的结点数(即所代表等价类中的元素数目)。
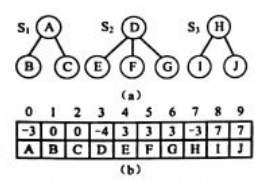
在这种表示方法中,可以方便地实现并查集的合并和查找操作。
- 对于任意给定的集合元素 D,只要通过双亲指针向上一直走到树的根结点,就可以得到元素D所在的等价类(用根结点代表相应的等价类)。
(2)对于两个集合的并,只要将其中一个集合的根结点设置为另一个集合的根结点的孩子即可。
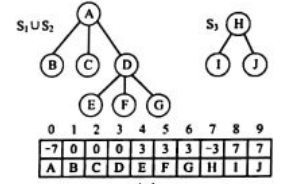
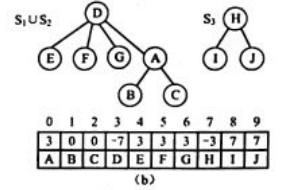
- 并查集的实现
(1)结点类
#include <iostream>
using namespace std;
template<class type> struct UFNode
{
type data;
int parent;
UFNode(){parent=-1;}
UFNode(type d,int p=-1)
{
data=d;
parent=p;
}
};
(2)部分函数
#include "UFNode.h"
#include <stack>
template<class type>class UFSets
{
protected:
UFNode<type> *Sets;//储存结点的双亲
int size;//结点个数
int Height(int r);//求以s为根的集合深度
int FindChild(int parent,stack<int> &s);//把parent的孩子编号压入栈中,返回本层高度
public:
UFSets(type es[],int n);
virtual ~UFSets();
type GetElem(int p)const;//根据指定下标p取元素值
int GetOrder(type e)const;//取指定元素在数组中的下标
int GetRoot(type e)const;//返回元素e的等价类的根
void Union(type a,type b);//合并a,b所在的等价类
void WeightedUnion(type a,type b);//Union加权规则
int CollapsingFind(type e)const;//折叠规则压缩路径
void HeightUnion(type a,type b);//根据高度合并,高度大的根为合并后的根
bool Differ(type a,type b);//判断元素a,b是否在同一个等价类
UFSets(const UFSets &t);
UFSets& operator=(const UFSets &t);
void Print();
};
template<class type> type UFSets<type>::GetElem(int p)const
{
if(0<=p&&p<size)
return Sets[p].data;
else
return (type)-1;
}
template<class type> int UFSets<type>::GetOrder(type e)const//取指定元素在数组中的下标
{
int p=0;
while(p<size&&Sets[p].data!=e)
p++;
if(p==size)//集合中不存在e
return -1;
else
{
while(Sets[p].parent>-1)
p=Sets[p].parent;//查找e所在的等价类的根
return p;
}
}
template<class type> void UFSets<type>::Union(type a,type b)//合并a,b所在的等价类
{
int r1=GetOrder(a);
int r2=GetOrder(b);
if(r1!=r2&&r1!=-1&&r2!=-1)
{
Sets[r1].parent+=Sets[r2].parent;
Sets[r2].parent=r1;
}
}
template<class type> void UFSets<type>::WeightedUnion(type a,type b)
{
int r1=GetOrder(a);
int r2=GetOrder(b);
if(r1!=r2&&r1!=-1&&r2!=-1)
{
int temp=Sets[r1].parent+Sets[r2].parent;
if(Sets[r1].parent<=Sets[r2].parent)
{
Sets[r2].parent=r1;//r2中结点个数少,r2指向r1
Sets[r1].parent=temp;
}
else
{
Sets[r1].parent=r2;
Sets[r2].parent=temp;
}
}
}
template<class type> int UFSets<type>::CollapsingFind(type e)const//折叠规则压缩路径
{
int i,k,p=0;
while(p<size&&Sets[p].data!=e)
p++;
if(p==size)
return -1;
for(i=p;Sets[i].parent>=0;i=Sets[i].parent);//查找p的根节点的序号i
if(p!=i)
{
while(i!=Sets[p].parent)//从p开始向上逐层压缩
{
k=Sets[p].parent;
Sets[p].parent=i;
p=k;
}
}
return i;
}
template<class type> int UFSets<type>::FindChild(int r,stack<int> &s)
{
int num;num=0;
int preparent=r;
for(int i=0;i<size;i++)
{
if(Sets[i].parent==preparent)
{
s.push(i);
num++;
}
}
return num;
}
template<class type> int UFSets<type>::Height(int r)
{
int preparent,count,n;
int height;height=0;
stack<int> s;
n=FindChild(r,s);
while(n>0)
{
height++;count=0;
for(int i=0;i<n;i++)
{
preparent=s.top();s.pop();
count+=FindChild(preparent,s);
}
n=count;
}
return height+1;
}
template<class type> void UFSets<type>::HeightUnion(type a,type b)//根据高度合并,高度大的根为合并后的根
{
int r1=GetOrder(a);
int r2=GetOrder(b);
int height1=Height(r1);
int height2=Height(r2);
if(r1!=r2&&r1!=-1&&r2!=-1)
{
if(height1>=height2)
{
Sets[r1].parent=Sets[r1].parent+Sets[r2].parent;
Sets[r2].parent=r1;
}
else
{
Sets[r2].parent=Sets[r1].parent+Sets[r2].parent;
Sets[r1].parent=r2;
}
}
}
Union()函数为了提高效率进行三次改进:
初始简单合并,n棵树可能合并退化为一个单链表,如此查找所需时间为O(n2)。
改进一:加权规则 WeightedUnion()
先判断两个集合个数,将个数少的作为孩子。

查找所需时间O(1)。Find()查找时间上界不超过树的高度+1。
进一步改进:折叠规则压缩路径CollapsingFind()

设j是i为根的树中的一个节点,则对于从j到根i的路径上每一个结点k,如果sets[k].parent!=i,就把i设置为k的双亲。
即当我们经过"递推"找到祖先节点后,"回溯"的时候顺便将它的子孙节点都直接指向祖先,这样以后再次Find()时复杂度就变成O(1)了。
可见,路径压缩方便了以后的查找。














 612
612











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









