




 本文介绍如何使用并查集解决特定类型的数学问题。通过并查集的【查询】与【合并】操作,处理动态连通性问题。文章详细解析了算法实现过程,包括预处理变量映射、并查集构建及查询步骤。
本文介绍如何使用并查集解决特定类型的数学问题。通过并查集的【查询】与【合并】操作,处理动态连通性问题。文章详细解析了算法实现过程,包括预处理变量映射、并查集构建及查询步骤。
题目
题解
这道题用并查集解决,那么什么是并查集呢?
并查集(不相交集合)用于处理动态连通性问题,最典型的应用是求解最小生成树的Kruskal算法
并查集支持【查询】、【合并】两个操作
并查集只回答两个结点是不是在一个连通分量中(连通性问题),并不回答路径问题
如果一个问题具有传递性质,可以考虑并查集
并查集最常见的一种设计思想是:把同在一个连通分量的结点组织成一个树形结构(代表元法)
并查集使用【路径压缩】和【按秩合并】解决树的高度增加带来的查询性能消耗问题
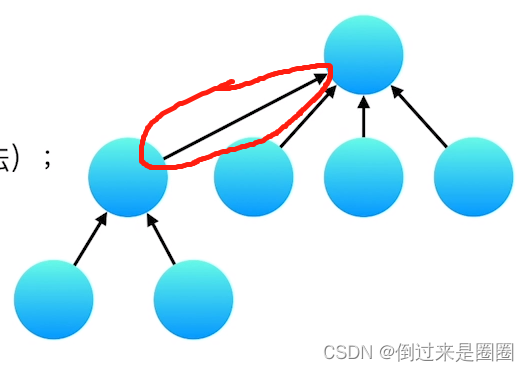
例1的解释如下图:

利用并查集【路径压缩】,维护权值变化,
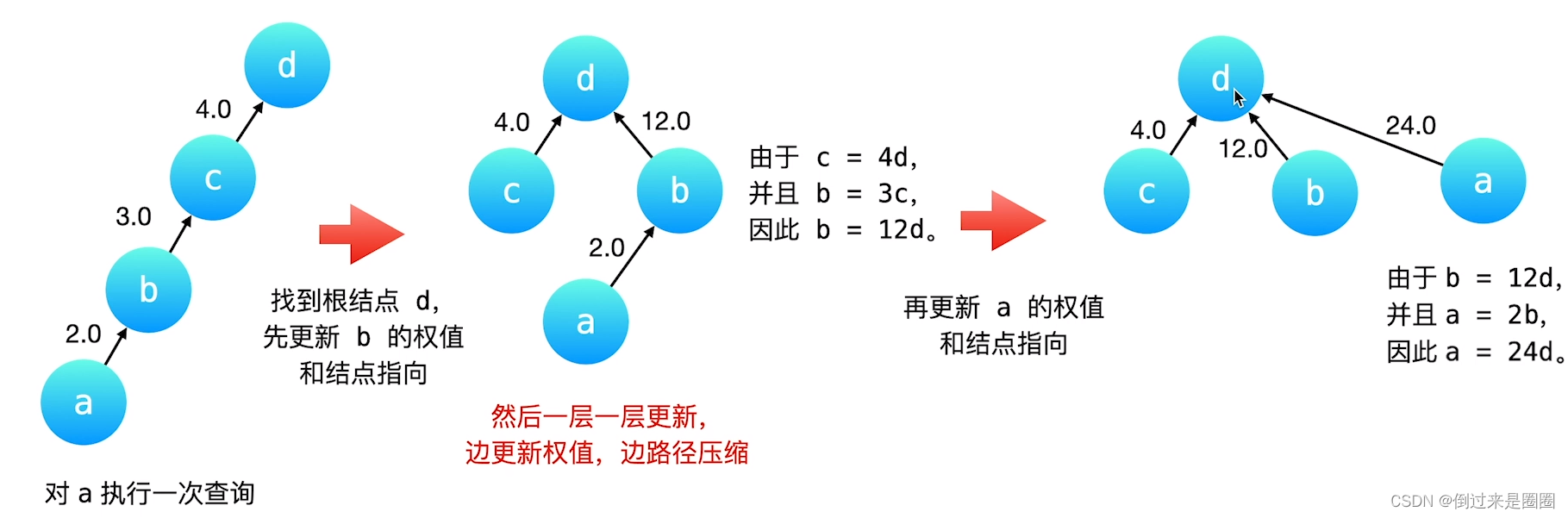
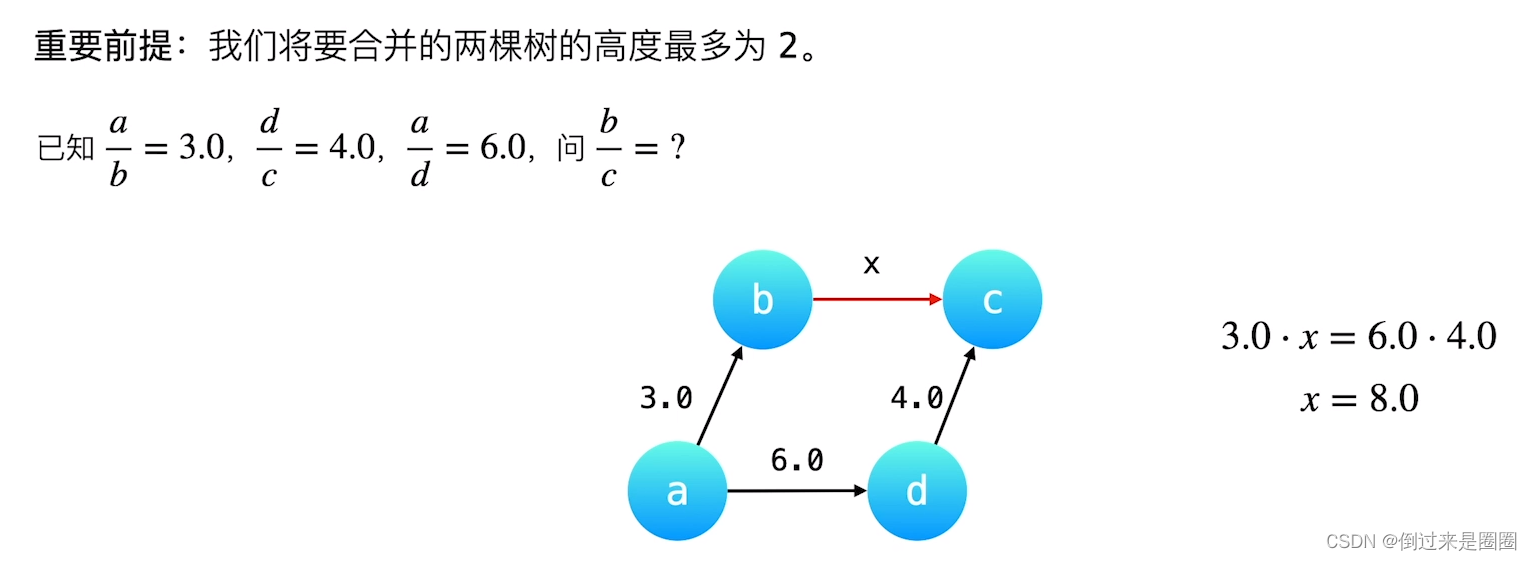
在【合并】中维护权值的变化,
p.s 并查集的问题一般都可以用 dfs 或者 bfs 实现
class Solution {
public double[] calcEquation(List<List<String>> equations, double[] values, List<List<String>> queries) {
int equSize=equations.size();
UnionFind unionFind=new UnionFind(2*equSize);//一个equations对应的两个变量都不相同时,底层并查集需要使用的长度就是2*equSize
//第1步:预处理,将变量的值与id进行映射
Map<String,Integer>hashMap=new HashMap<>(2*equSize);//并查集底层操作数字更方便,因此存储变量和整数的对应关系
int id=0;
for(int i=0;i<equSize;i++){
List<String>equation=equations.get(i);
String var1=equation.get(0);
String var2=equation.get(1);
if(!hashMap.containsKey(var1)){
hashMap.put(var1,id);
id++;
}
if(!hashMap.containsKey(var2)){
hashMap.put(var2,id);
id++;
}
//合并
unionFind.union(hashMap.get(var1),hashMap.get(var2),values[i]);
}
//第2步:做查询
int queriesSize=queries.size();
double[] res=new double[queriesSize];
for(int i=0;i<queriesSize;i++){
String var1=queries.get(i).get(0);
String var2=queries.get(i).get(1);
Integer id1=hashMap.get(var1);
Integer id2=hashMap.get(var2);
if(id1==null||id2==null)
res[i]=-1.0;
else
res[i]=unionFind.isConnected(id1,id2);//对应父结点权值的比值
}
return res;
}
private class UnionFind{
private int[] parent;//每个结点父结点的id
private double[] weight;//结点指向父结点的权值
public UnionFind(int n){
this.parent=new int[n];
this.weight=new double[n];
for(int i=0;i<n;i++){
parent[i]=i;
weight[i]=1.0;
}
}
//合并
public void union(int x,int y,double value){
int rootX=find(x);
int rootY=find(y);
if(rootX==rootY)
return;
parent[rootX]=rootY;
weight[rootX]=weight[y]*value/weight[x];
}
//路径压缩,返回根节点id
public int find(int x){
if(x!=parent[x]){
int origin=parent[x];
parent[x]=find(parent[x]);
weight[x]*=weight[origin];
}
return parent[x];
}
//对应父结点权值的比值
public double isConnected(int x,int y){
int rootX=find(x);
int rootY=find(y);
if(rootX==rootY)//两个变量指向同一个根节点
return weight[x]/weight[y];
else//两个变量不在同一个集合之中
return -1.0;
}
}
}
时间复杂度: O ( ( N + Q ) l o g A ) O((N+Q)logA) O((N+Q)logA),其中N是equations中方程数目,Q是queries长度,A是变量的总数,对每个方程的合并和查找的均摊时间复杂度都是O(logA)。
空间复杂度: O ( A ) O(A) O(A),parent和weight长度均为A。
第一次在力扣写这么长的代码。。。

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









