






转义字符与字符串
\ #转义字符。例:
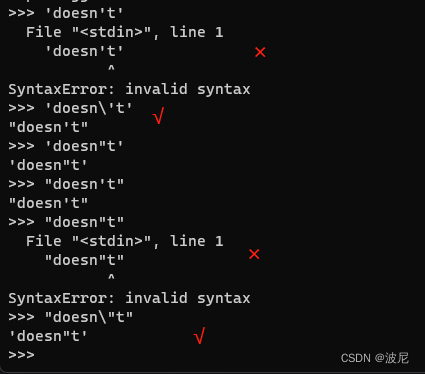
如果不希望前置 \ 的字符转义成特殊字符,可以使用 原始字符串,在引号前添加 r 即可:
>>>print('C:\some\name') # here \n means newline!
C:\some
ame
>>>print(r'C:\some\name') # note the r before the quote
C:\some\name
字符串包含多行时可以使用三重引号:"""..."""或'''...''',例:
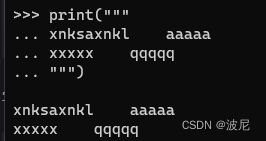
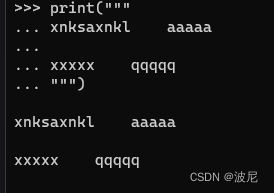
如果不想要字符串中间的空行可以这样:
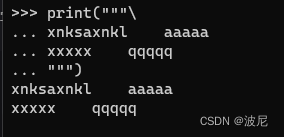

字符串的切片:
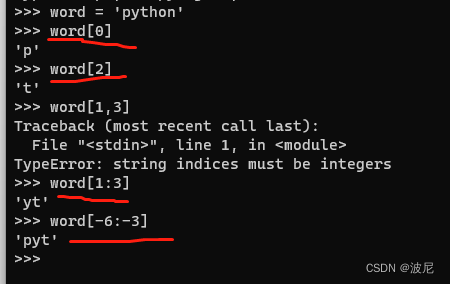
可以这么理解word = ‘Python’
+---+---+---+---+---+---+
| P | y | t | h | o | n |
+---+---+---+---+---+---+
0 1 2 3 4 5 6
-6 -5 -4 -3 -2 -1
append() 方法 可以在列表结尾添加新元素
>>>cubes.append(216) # add the cube of 6
>>>cubes.append(7 ** 3) # and the cube of 7
>>>cubes
[1, 8, 27, 64, 125, 216, 343]
为切片赋值可以改变列表大小,甚至清空整个列表:
>>>letters = ['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>>letters
['a', 'b', 'c', 'd', 'e', 'f', 'g']
# replace some values
>>>letters[2:5] = ['C', 'D', 'E']
>>>letters
['a', 'b', 'C', 'D', 'E', 'f', 'g']
# now remove them
>>>letters[2:5] = []
>>>letters
['a', 'b', 'f', 'g']
# clear the list by replacing all the elements with an empty list
>>>letters[:] = []
>>>letters
[]
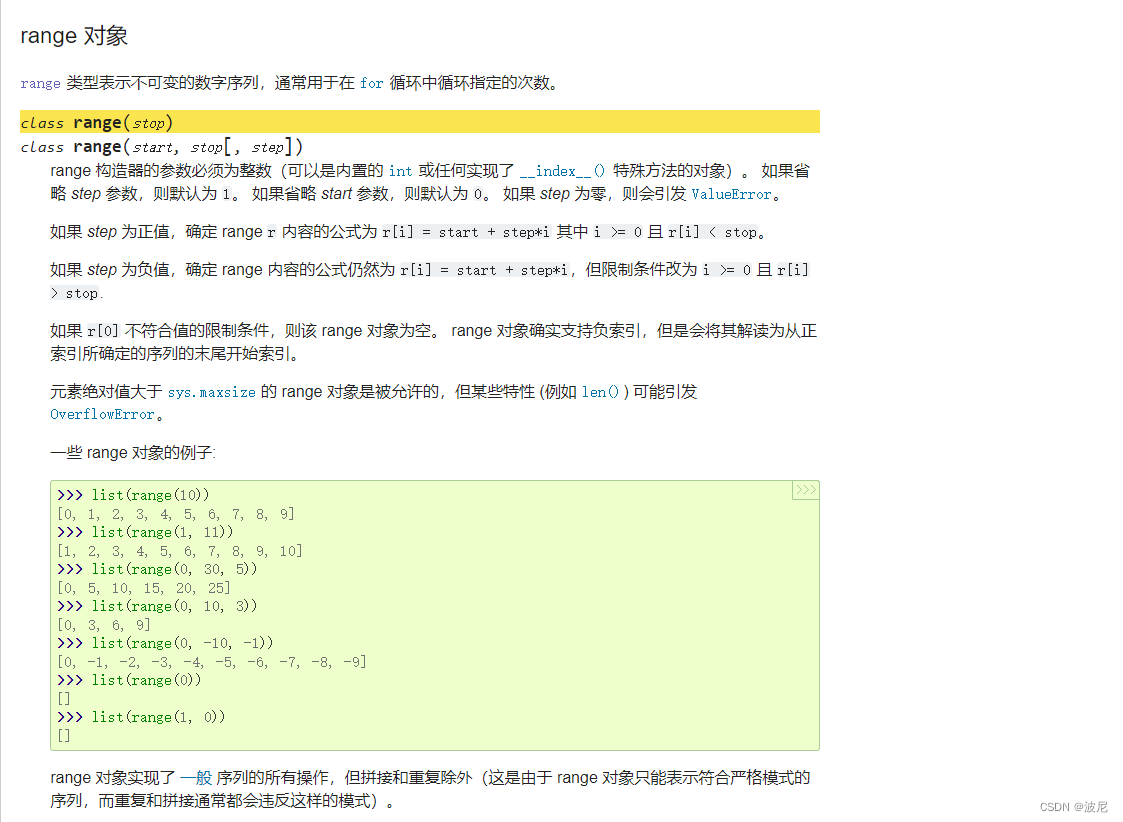
range对象:
match语句
类似于c++中的switch语句
def http_error(status):
match status:
case 400:
return "Bad request"
case 404:
return "Not found"
case 418:
return "I'm a teapot"
case _:
return "Something's wrong with the internet"
“变量名” _ 被作为 通配符 并必定会匹配成功。 这里的case_相当于最后的else。
如果没有 case 语句匹配成功,则不会执行任何分支。
变量赋值:
>>> a,b = 0,1
>>> a,b
(0, 1)
>>> a,b = b,a+b
>>> a,b
(1, 1)
>>> a,b = b,a+b
>>> a,b
(1, 2)
>>> a,b = b,a+b
>>> a,b
(2, 3)
>>>
关键字参数和位置参数
# 例:
def parrot(voltage, state='a stiff', action='voom', type='Norwegian Blue'):
print("-- This parrot wouldn't", action, end=' ')
print("if you put", voltage, "volts through it.")
print("-- Lovely plumage, the", type)
print("-- It's", state, "!")
# 可用以下方式调用
parrot(1000) # 1 positional argument
parrot(voltage=1000) # 1 keyword argument
parrot(voltage=1000000, action='VOOOOOM') # 2 keyword arguments
parrot(action='VOOOOOM', voltage=1000000) # 2 keyword arguments
parrot('a million', 'bereft of life', 'jump') # 3 positional arguments
parrot('a thousand', state='pushing up the daisies') # 1 positional, 1 keyword
# 函数调用时,关键字参数必须跟在位置参数后面。
特殊参数
指定某些位置只能填写位置参数或者关键字参数
仅限位置形参应放在 / (正斜杠)前。
把形参标记为 仅限关键字,应在参数列表中第一个 仅限关键字 形参前添加 *。
def f(pos1, pos2, /, pos_or_kwd, *, kwd1, kwd2):
----------- ---------- ----------
| | |
| Positional or keyword |
| - Keyword only
-- Positional only
#函数示例:
>>>def standard_arg(arg):
print(arg)
>>>def pos_only_arg(arg, /):
print(arg)
>>>def kwd_only_arg(*, arg):
print(arg)
>>>def combined_example(pos_only, /, standard, *, kwd_only):
print(pos_only, standard, kwd_only)
#对于第一个函数,第一个函数定义 standard_arg 是最常见的形式,对调用方式没有任何限制,可以按位置也可以按关键字传递参数:
>>>standard_arg(2)
2
>>>standard_arg(arg=2)
2
# 第二个函数 pos_only_arg 的函数定义中有 /,仅限使用位置形参:
>>>pos_only_arg(1)
1
>>>pos_only_arg(arg=1)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: pos_only_arg() got some positional-only arguments passed as keyword arguments: 'arg'
# 第三个函数 kwd_only_args 的函数定义通过 * 表明仅限关键字参数:
>>>kwd_only_arg(3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: kwd_only_arg() takes 0 positional arguments but 1 was given
>>>kwd_only_arg(arg=3)
3
# 最后一个函数在同一个函数定义中,使用了全部三种调用惯例:
>>>combined_example(1, 2, 3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: combined_example() takes 2 positional arguments but 3 were given
>>>combined_example(1, 2, kwd_only=3)
1 2 3
>>>combined_example(1, standard=2, kwd_only=3)
1 2 3
>>>combined_example(pos_only=1, standard=2, kwd_only=3)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: combined_example() got some positional-only arguments passed as keyword arguments: 'pos_only'
循环的技巧
在字典中循环时,用 items() 方法可同时取出键和对应的值:
>>>knights = {'gallahad': 'the pure', 'robin': 'the brave'}
>>>for k, v in knights.items():
... print(k, v)
gallahad the pure
robin the brave
在序列中循环时,用 enumerate() 函数可以同时取出位置索引和对应的值:
>>>for i, v in enumerate(['tic', 'tac', 'toe']):
... print(i, v)
0 tic
1 tac
2 toe
同时循环两个或多个序列时,用 zip() 函数可以将其内的元素一一匹配:
>>>questions = ['name', 'quest', 'favorite color']
>>>answers = ['lancelot', 'the holy grail', 'blue']
>>>for q, a in zip(questions, answers):
... print('What is your {0}? It is {1}.'.format(q, a))
What is your name? It is lancelot.
What is your quest? It is the holy grail.
What is your favorite color? It is blue.
逆向循环序列时,先正向定位序列,然后调用 reversed() 函数:
>>>for i in reversed(range(1, 10, 2)):
... print(i)
9
7
5
3
1
按指定顺序循环序列,可以用 sorted() 函数,在不改动原序列的基础上,返回一个重新的序列:
# https://docs.python.org/zh-cn/3/library/functions.html#sorted
sorted(iterable, /, *, key=None, reverse=False)
根据 iterable 中的项返回一个新的已排序列表
>>>basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>>for i in sorted(basket):
... print(i)
apple
apple
banana
orange
orange
pear
使用 set() 去除序列中的重复元素。使用 sorted() 加 set() 则按排序后的顺序,循环遍历序列中的唯一元素:
>>>basket = ['apple', 'orange', 'apple', 'pear', 'orange', 'banana']
>>>for f in sorted(set(basket)):
... print(f)
apple
banana
orange
pear
优先级
or < and < not
Python 与 C 不同,在表达式内部赋值必须显式使用 海象运算符 :=
序列和其他类型的比较¶
序列对象可以与相同序列类型的其他对象比较。这种比较使用 字典式 顺序:
首先,比较前两个对应元素,如果不相等,则可确定比较结果;
如果相等,则比较之后的两个元素,
以此类推,直到其中一个序列结束。
如果要比较的两个元素本身是相同类型的序列,则递归地执行字典式顺序比较。如果两个序列中所有的对应元素都相等,则两个序列相等。如果一个序列是另一个的初始子序列,则较短的序列可被视为较小(较少)的序列。 对于字符串来说,字典式顺序使用 Unicode 码位序号排序单个字符。例:
(1, 2, 3) < (1, 2, 4)
[1, 2, 3] < [1, 2, 4]
'ABC' < 'C' < 'Pascal' < 'Python'
(1, 2, 3, 4) < (1, 2, 4)
(1, 2) < (1, 2, -1)
(1, 2, 3) == (1.0, 2.0, 3.0)
(1, 2, ('aa', 'ab')) < (1, 2, ('abc', 'a'), 4)
模块导入
# 将fibo模块中的fib fib2模块导入
>>>from fibo import fib, fib2
>>>fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
# 导入fibo模块中的所有模块。这种方式会导入所有不以下划线(_)开头的名称。大多数情况下,不要用这个功能,这种方式向解释器导入了一批未知的名称,可能会覆盖已经定义的名称。
#注意,一般情况下,不建议从模块或包内导入 *, 因为,这项操作经常让代码变得难以理解。不过,为了在交互式编译器中少打几个字,这么用也没问题。
>>>from fibo import *
>>>fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377
将fibo模块导入,并以fib名字在脚本中使用
import fibo as fib
fib.fib(500)
0 1 1 2 3 5 8 13 21 34 55 89 144 233 377















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









