









Transformer 与 CNN 又打起来了,替换 DiT!本文引入一种紧凑的通道注意力机制,可以促进更多不同通道的激活,这催生了扩散卷积神经网络 (DiCo):一系列完全由标准卷积神经网络 (ConvNet) 模块构建的扩散模型,具有强大的生成性能和显著的效率提升,DiCo 在图像质量和生成速度方面均优于之前的扩散模型!

论文:DiCo: Revitalizing ConvNets for Scalable and Efficient Diffusion Modeling
代码:https://github.com/shallowdream204/DiCo(即将开源)
0、摘要
扩散 Transformer(Diffusion Transformer,简称 DiT)是一种有前景的视觉生成扩散模型,它展示了令人印象深刻的性能,但同时也带来了显著的计算开销。有趣的是,对预训练的 DiT 模型的分析表明,全局自注意力(global self-attention)往往是多余的,主要捕捉的是局部模式——这突显了更高效替代方案的潜力。(卷积与 Transformer 的地位之战)
本文重新审视了卷积作为构建高效且表达力强的扩散模型的替代构建模块。然而,简单地用卷积替换自注意力机制通常会导致性能下降。本文的研究将这种性能差距归因于 ConvNets 与 Transformer 相比具有更高的通道冗余。
为了解决这个问题,本文引入了一种紧凑的通道注意力机制,该机制促进了更多多样化通道的激活,从而增强了特征多样性。这引出了扩散卷积网络(Diffusion ConvNet,DiCo)的产生,这是一系列完全由标准卷积网络模块构建的扩散模型,它在显著提高效率的同时提供了强大的生成性能。
在 class-conditional ImageNet 基准测试中,DiCo 在图像质量和生成速度方面都超越了以前的扩散模型。值得注意的是,DiCo-XL 在 256×256 分辨率下达到了 2.05 的 FID,在 512×512 分辨率下达到了 2.53 的 FID,与 DiT-XL/2 相比,速度分别提高了 2.7 倍和 3.1 倍。此外,最大的模型 DiCo-H,扩展到 10 亿参数,在 ImageNet 256×256 上达到了 1.90 的 FID,而且在训练期间没有任何额外的监督。
1、引言
1.1、研究现状与研究意义
扩散模型在生成学习领域引发了一场变革性的进步,展示了在合成高度逼真的视觉内容方面显著的能力。它们的多功能性和有效性已经导致了在广泛的实际应用中的广泛采用,包括文本到图像的生成、图像编辑、图像修复、视频生成,以及 3D 内容创作。(Diffusion 顶流)
早期的扩散模型(例如,ADM 和 Stable Diffusion)主要采用了混合 U-Net 架构,这种架构将卷积层与自注意力机制相结合。最近,Transformers 作为一种更强大、更可扩展的骨干网络出现,促使人们转向完全 Transformer-based 的设计。因此,Diffusion Transformers(DiTs)正逐渐取代传统的 U-Net,这一点在诸如 Stable Diffusion 3、FLUX 和 Sora 等领先的扩散模型中得到了体现。(Transformer-based 的扩散模型原来有那么多了…)
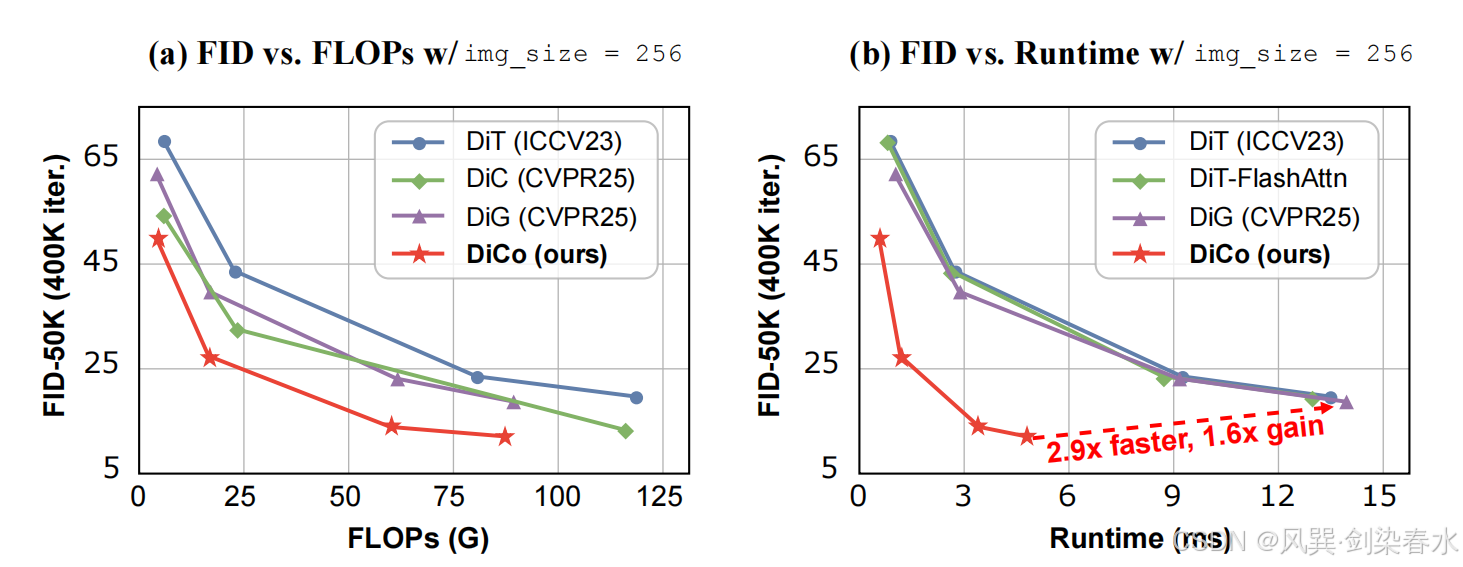
Figure 2 | 在 ImageNet 256×256 上与最先进的扩散模型(DiT、DiC 和DiG)的性能和效率比较:本文提出的 DiCo 在保持高效率的同时实现了最佳性能,与采用 CUDA 优化的 Flash Linear Attention 的 DiG-XL/2 相比,DiCo-XL 运行速度提高了 2.9×,并且 FID 提升了 1.6×;
然而,self-attention 的二次计算复杂度带来了巨大的挑战,尤其是对于高分辨率图像合成。最近的研究探索了更高效的替代方案,专注于线性复杂度的 RNN-like 架构,例如 Mamba 和门控线性注意力(Gated Linear Attention)。
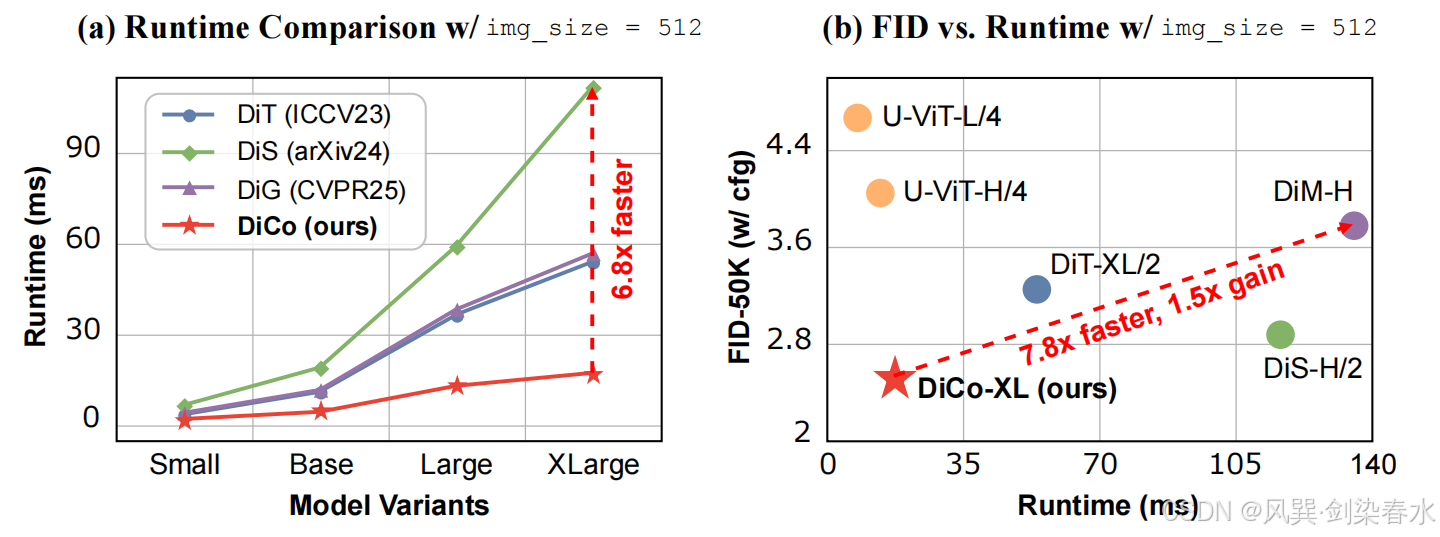
虽然这些模型提高了效率,但它们的因果设计本质上与视觉生成的双向特性相冲突(因果设计只考虑过去信息,双向特性指全局理解能力是双向的,即模型需要同时考虑已有的和待生成的信息),限制了它们的有效性。此外,如 图3 所示,即使在高度优化的 CUDA 实现下,它们在高分辨率设置下的运行时间优势相对于传统的 DiTs 仍然有限。
Figure 3 | :(a) 在512×512分辨率下,DiT(采用注意力机制)、DiS(采用Mamba)、DiG(采用门控线性注意力)与本文的 DiCo 在运行时间上的比较。在小型模型规模上,DiCo 比 DiS 快 3.3 倍,在 XL 规模上快 6.8 倍;(b) 在 ImageNet 512×512 上各种方法的 FID(生成图像与真实图像分布的差异度量)与运行时间的对比。DiCo-XL 在保持高效率的同时,达到了最先进的 FID 值 2.53;
这使我们面临一个关键问题:是否有可能设计出一种硬件效率高的扩散骨干网络,同时保留像 DiTs 这样的强生成能力?
为了探讨这一问题,本文首先考察了 DiTs 生成能力背后的特点。在视觉识别任务中,Vision Transformer 的成功通常归功于自注意力机制捕捉长距离依赖关系的能力(嗯,听过很多遍了)。然而,在生成任务中,本文观察到不同的动态。
如 图4 所示,对于预训练的类条件(DiT-XL/2)和文本到图像(PixArt-
α
α
α 和 FLUX)的 DiT 模型,当查询一个 anchor token 时,注意力主要集中在附近的空间标记(spatial tokens)上,而很大程度上忽略了远处的标记。这一发现表明,计算全局注意力对于生成可能具有冗余性,强调了局部空间建模的重要性。与识别任务中长距离交互对于全局语义推理至关重要不同,在生成任务中,似乎更强调精细的纹理和局部结构保真度。这些观察揭示了 DiTs 中注意力的固有局部化特性,并激励我们追求更高效的架构。
Figure 4 | 对知名 DiT 模型的注意力图进行可视化展示,包括 DiT-XL/2、PixArt-α 和 FLUX.1-dev:蓝色颜色的强度表示注意力得分的大小,在这些模型的不同层之间的自注意力中,只有少数邻近的标记对给定锚定标记(红色框)的注意力分布有显著贡献,导致生成的表示高度冗余且局部化;

1.2、本文研究与贡献
本文重新审视了卷积神经网络(ConvNets),并提出了扩散卷积网络(Diffusion ConvNet,DiCo),这是一个简单但高效的卷积骨干网络,专为扩散模型量身定制。与自注意力相比,卷积操作更适应硬件,为大规模和资源受限的部署提供了显著优势。虽然用卷积替代自注意力显著提高了效率,但通常会导致性能下降。如 图5 所示,这种简单的替换引入了明显的通道冗余,许多通道在生成过程中保持不活跃。本文假设这源于自注意力相比卷积具有本质上更强的表示能力。
Figure 5 | 不同扩散模型的通道激活分数比较:通道激活分数是通过在最后一层的自注意力或卷积输出上使用 ReLU 激活函数后接全局平均池化来计算的,在 DiT 中直接用卷积替换自注意力会引入显著的通道冗余,因为大多数通道激活分数都保持在相对较低的水平;
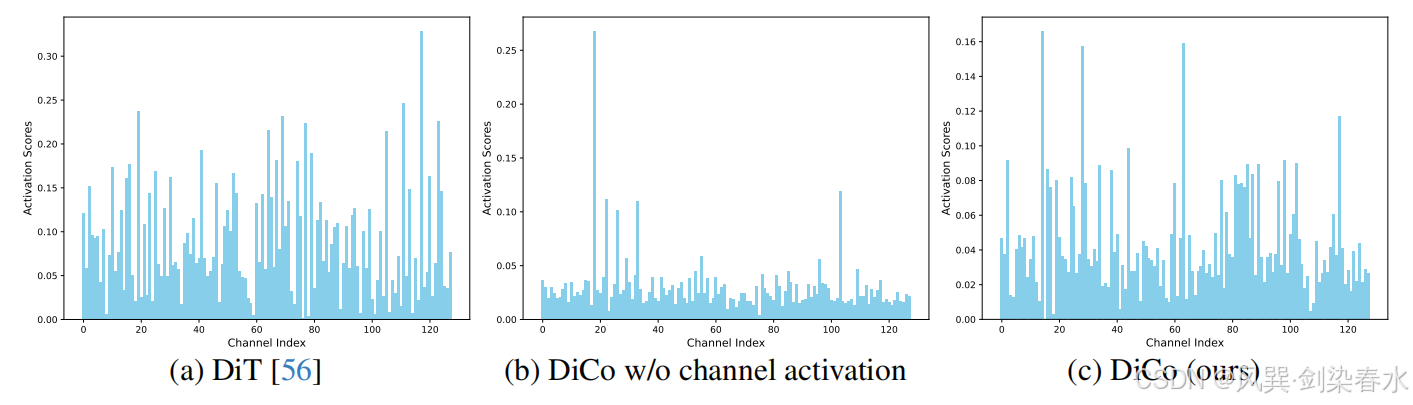
为了解决这个问题,本文引入了一种紧凑的通道注意力(compact channel attention,CCA)机制,它通过轻量级的线性投影动态激活信息丰富的通道。作为一种逐通道的全局建模方法,CCA 在保持低计算开销的同时,增强了模型的表征能力和特征多样性。与依赖于大型、高成本卷积核的现代判别卷积网络不同,DiCo 采用了一种基于高效的 1×1 逐点卷积(pointwise convolutions)和 3×3 深度卷积(depthwise convolutions)的简化设计。尽管其架构简单,但 DiCo 提供了强大的生成性能。
如 图2 和 图3 所示,DiCo 模型在 ImageNet 256×256 和 512×512 基准测试中的表现均超越了现有的先进扩散模型。值得注意的是,本文的 DiCo-XL 模型在 256×256 和 512×512 分辨率下分别取得了 2.05 和 2.53 的出色 FID 分数。除了性能提升之外,DiCo 模型相较于基于注意力、基于 Mamba 以及基于线性注意力的扩散模型展现出显著的效率优势。
具体来说,在 256×256 分辨率下,DiCo-XL 实现了 Gflops 减少 26.4%,并且比 DiT-XL/2 快 2.7 倍。在 512×512 分辨率下,DiCo-XL 分别比基于 Mamba 的 DiM-H 和 DiS-H/2 模型快 7.8 倍和 6.7 倍。本文最大的模型 DiCo-H 拥有10亿参数,在 ImageNet 256×256 上进一步将 FID 降低到 1.90。这些结果共同突显了 DiCo 在基于扩散的生成模型中的强劲潜力。
本文贡献总结:
(1)分析了预训练的 DiT 模型,揭示了其全局注意力机制中的显著冗余和局部性,这些发现可能激发研究人员开发更高效的策略,以构建高性能的扩散模型;
(2)提出 DiCo,一种简单、高效且强大的卷积神经网络骨干,用于扩散模型。通过引入紧凑的通道注意力机制,DiCo 显著提升了表示能力和特征多样性,同时不牺牲效率;
(3)在 ImageNet 256×256 和 512×512 基准上进行了广泛的实验。DiCo 在生成质量和速度方面均优于现有的扩散模型。据本文所知,这是首次证明精心设计的全卷积骨干网络能够在基于扩散的生成建模中实现 SOTA 性能;
2、方法
2.1、基础工作
2.1.1、Diffusion formulation
首先回顾扩散模型的基本概念,扩散模型的特点是前向噪声过程,该过程逐步向数据样本
x
0
x_0
x0 注入噪声。具体来说,这个前向过程可以表示为:
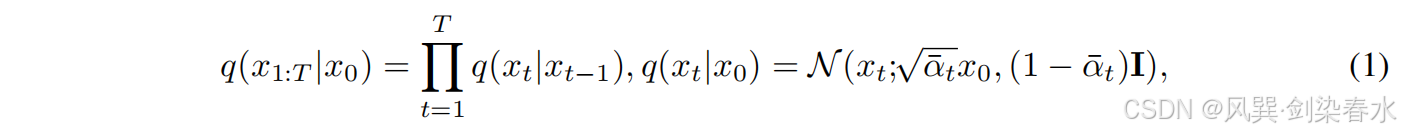
其中
α
ˉ
t
\bar α_t
αˉt 是预定义的超参数。扩散模型的目标是学习逆过程:
p
θ
(
x
t
−
1
∣
x
t
)
=
N
(
μ
θ
(
x
t
)
,
Σ
θ
(
x
t
)
)
p_θ(x_{t−1}|x_t)=\mathcal N(\mu_θ(x_t),Σ_θ(x_t))
pθ(xt−1∣xt)=N(μθ(xt),Σθ(xt)),其中神经网络参数化了该过程的均值和方差。训练涉及优化
x
0
x_0
x0 的对数似然函数的变分下界,简化后为:
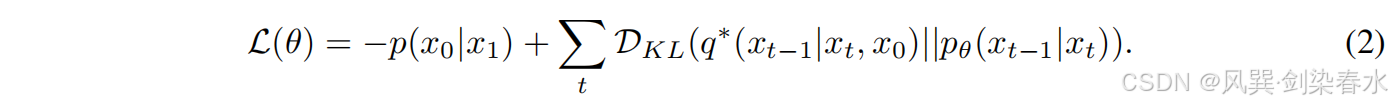
为了简化训练,模型预测的均值
μ
θ
\mu_θ
μθ 可以重新参数化为噪声预测器
ϵ
θ
ϵ_θ
ϵθ。然后,目标简化为预测噪声与真实噪声之间的简单均方误差
ϵ
t
:
L
s
i
m
p
l
e
(
θ
)
=
∣
∣
ϵ
θ
(
x
t
)
−
ϵ
t
∣
∣
2
2
ϵ_t: \mathcal L_{simple}(θ)=||ϵ_θ(x_t)−ϵ_t||^2_2
ϵt:Lsimple(θ)=∣∣ϵθ(xt)−ϵt∣∣22。遵循 DiT 的方法,使用简化后的损失函数
ϵ
t
:
L
s
i
m
p
l
e
ϵ_t: \mathcal L_{simple}
ϵt:Lsimple 来训练噪声预测器
ϵ
θ
ϵ_θ
ϵθ 而协方差
Σ
θ
Σ_θ
Σθ 则通过完整的损失函数
L
\mathcal L
L 来进行优化。(相信大家已经非常熟悉了~)
2.1.2、Classifier-free guidance
无分类器引导(Classifier-free Guidance,简称CFG)是一种有效提升条件扩散模型中样本质量的方法。它通过引导采样过程朝着与给定条件 c c c 强烈相关的输出方向发展,从而实现这种增强。
具体来说,它修改预测噪声以获得高 p ( x ∣ c ) p(x|c) p(x∣c),公式如下: ϵ ^ θ ( x t , c ) = ϵ θ ( x t , ∅ ) + s ⋅ ∇ x ⋅ l o g p ( x ∣ c ) ∝ ϵ θ ( x t , ∅ ) + s ⋅ ( ϵ θ ( x t , c ) − ϵ θ ( x t , ∅ ) ) \hat ϵ_θ(x_t,c)=ϵ_θ(x_t,∅)+s·∇x·log p(x|c)∝ϵ_θ(x_t,∅)+s·(ϵ_θ(x_t,c)−ϵ_θ(x_t,∅)) ϵ^θ(xt,c)=ϵθ(xt,∅)+s⋅∇x⋅logp(x∣c)∝ϵθ(xt,∅)+s⋅(ϵθ(xt,c)−ϵθ(xt,∅))。其中 s ≥ 1 s≥1 s≥1 控制引导强度, ϵ θ ( x t , ∅ ) ϵ_θ(x_t,∅) ϵθ(xt,∅) 是通过在训练过程中随机省略条件信息获得的无条件预测。根据先前的工作,本文采用此技术来提高生成样本的质量。
2.2、网络结构
目前,扩散模型主要分为三种架构类型:
(1) 没有下采样层的各向同性架构,如 DiT 中所见;
(2) 带有长跳跃连接的各向同性架构,例如 U-ViT;
(3) U 形架构,如 U-DiT;
受图像去噪中多尺度特征关键作用的启发,本文采用 U 形设计来构建一个层次化模型。本文还进行了广泛的消融研究,系统地比较 表3 中这些不同架构选择的性能。
如 图6(a) 所示,DiCo 采用了一个由堆叠的 DiCo 模块组成的三阶段 U 形架构。模型以 VAE 编码器生成的空间表示
z
z
z 作为输入。对于一个大小为
256
×
256
×
3
256×256×3
256×256×3 的图像,相应的
z
z
z 的维度为
32
×
32
×
4
32×32×4
32×32×4。为了处理这个输入,DiCo 应用了一个
3
×
3
3×3
3×3 的卷积,将
z
z
z 转换为具有
D
D
D 个通道的初始特征图
z
0
z_0
z0。对于条件信息——具体来说,时间步
t
t
t 和类别标签
y
y
y —— 采用多层感知机(MLP)和嵌入层,分别作为时间步和标签的嵌入器。在 DiCo 的每个块l中,特征图
z
l
−
1
z_{l−1}
zl−1 通过第
l
l
l 个 DiCo 块生成输出
z
l
z_l
zl。
Figure 6 | 所提出的 DiCo 模型的总体架构:由(b)DiCo Block、(c)Conv Module 和(d)Compact Channel Attention(CCA)组成,DConv 表示深度卷积;
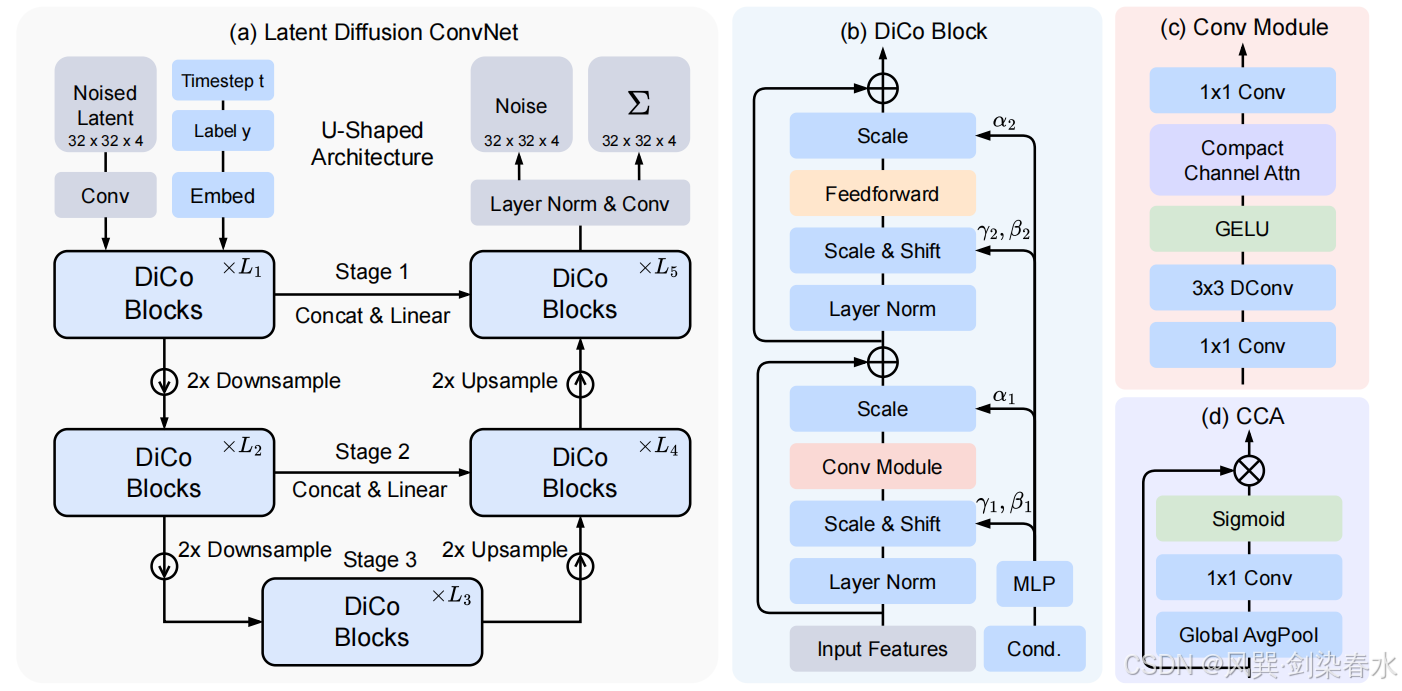
在每个阶段中,编码器和解码器之间的跳过连接促进了中间特征的有效信息流动。拼接后,应用 1×1 卷积以降低通道维度。为了实现跨阶段的多尺度处理,本文使用 pixel-unshuffle 操作进行下采样,以及 pixel-shuffle 操作进行上采样。最后,输出特征 z L z_L zL 经过归一化,并通过一个 3×3 卷积头来预测噪声和方差。
2.3、DiCo Block
2.3.1、Motivation
如 图4 所示,DiT 模型中的自注意力计算——无论是类别条件还是文本到图像生成——都表现出明显的局部结构和显著的冗余。这一观察结果促使本文用更高效的操作来替代 DiT 中的全局自注意力。一个自然的替代方案是卷积,它以其能够高效地建模局部模式而闻名。本文首先尝试用 1×1 pointwise 卷积和 3×3 depthwise 卷积的组合来替代自注意力机制。
然而,直接替换会导致生成性能的下降。如 图5 所示,与 DiT 相比,修改后的模型中有许多通道仍然处于非激活状态,这表明存在大量的通道冗余。本文推测这种性能下降源于自注意力机制是动态的且依赖于内容,其表征能力比依赖静态权重的卷积更强。为了解决这一局限性,本文引入了一种紧凑的通道注意力机制,以动态激活有用的信息通道。在下面详细描述了这一完整的设计。
2.3.2、Block designs
DiCo 的核心设计以 Conv Module 为中心,如 图6(c)所示,首先应用 1×1 卷积聚合像素级跨通道信息,然后应用 3×3 深度卷积捕捉通道级空间上下文。采用 GELU 激活进行非线性变换,为进一步解决通道冗余问题,引入 compact channel attention(CCA)机制,以激活更多具有信息量的通道。
如 图6(d) 所示,CCA 首先通过全局平均池化(GAP)在空间维度上聚合特征,然后应用一个可学习的 1×1 卷积,再通过 sigmoid 激活生成通道级注意力权重。Conv Module 的整个过程可以描述为:
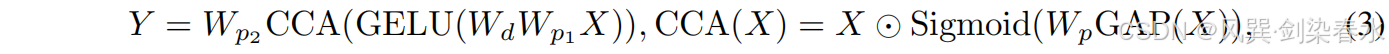
其中
W
p
(
⋅
)
W_{p(·)}
Wp(⋅) 是 1×1 点卷积,
W
d
W_d
Wd 是深度卷积,
⊙
⊙
⊙ 表示通道乘法。如 图5(c)所示,这种简单而高效的设计有效减少了特征冗余,增强了模型的表示能力。为了结合时间步和标签的条件信息,本文遵循 DiT 的方法,添加输入时间步嵌入
t
t
t 和标签嵌入
y
y
y,并用它们来预测尺度参数
α
α
α、
γ
γ
γ 和位移参数
β
β
β。
2.4、结构变体
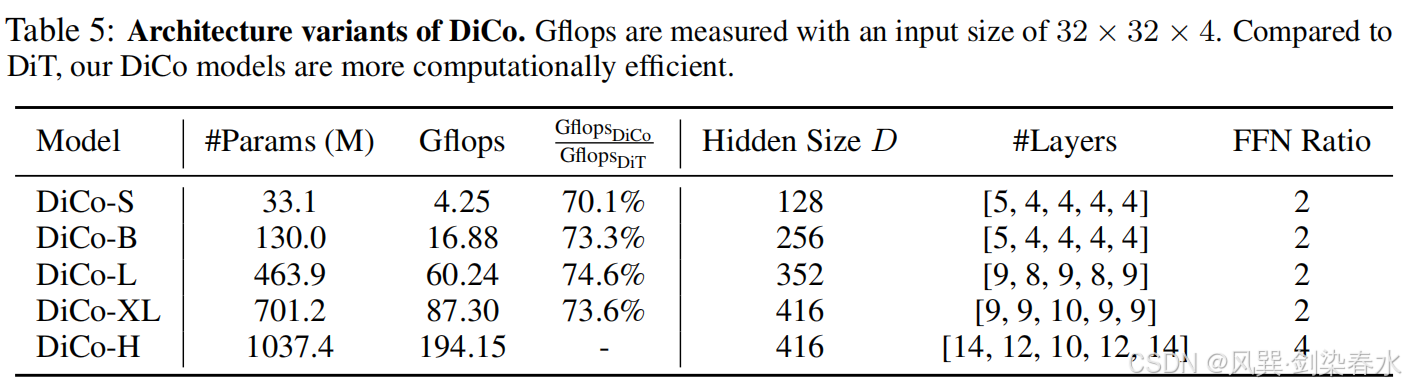
本文建立了四种模型变体——DiCo-S、DiCo-B、DiCo-L 和 DiCo-XL,其参数数量分别与 DiT-S/2、DiT-B/2、DiT-L/2 和 DiT-XL/2 保持一致。与相应的 DiT 模型相比,DiCo 模型在计算成本上实现了显著降低,其 Gflops 仅为 DiT 的 70.1% 到 74.6%。此外,为了探索本文设计的潜力,本文将 DiCo 扩展到 10 亿参数,从而产生了 DiCo-H。
模型的架构配置如下:
3、实验
3.1、实验设置
(1)数据集与评估指标:遵循以往的研究工作,在 256×256 和 512×512 分辨率下对 class conditional ImageNet-1K 图像生成基准进行了实验。使用 Fréchet Inception Distance(FID) 作为主要指标来评估模型性能。此外,还报告了 Inception Score(IS)、精确度(Precision)和召回率(Recall)作为次要指标。所有这些指标均通过 OpenAI 的 TensorFlow 评估工具包计算得出。
(2)实现细节:对于 DiCo-S/B/L/XL,采用了与 DiT 完全相同的实验设置。具体来说,我们使用了恒定的学习率 1 × 1 0 − 4 1×10^{−4} 1×10−4,不使用权重衰减,并将 batch size 设置为 256。唯一应用的数据增强是随机水平翻转。在训练过程中,保持一个指数移动平均(EMA)的 DiCo 权重,其衰减率为 0.9999。预训练的 VAE 用于提取潜在特征。对于最大模型 DiCo-H,遵循 U-ViT 的训练设置,将学习率提高到 2 × 1 0 − 4 2×10^{−4} 2×10−4,并将 batch size 扩展到 1024,以加速训练。
更多细节如下:
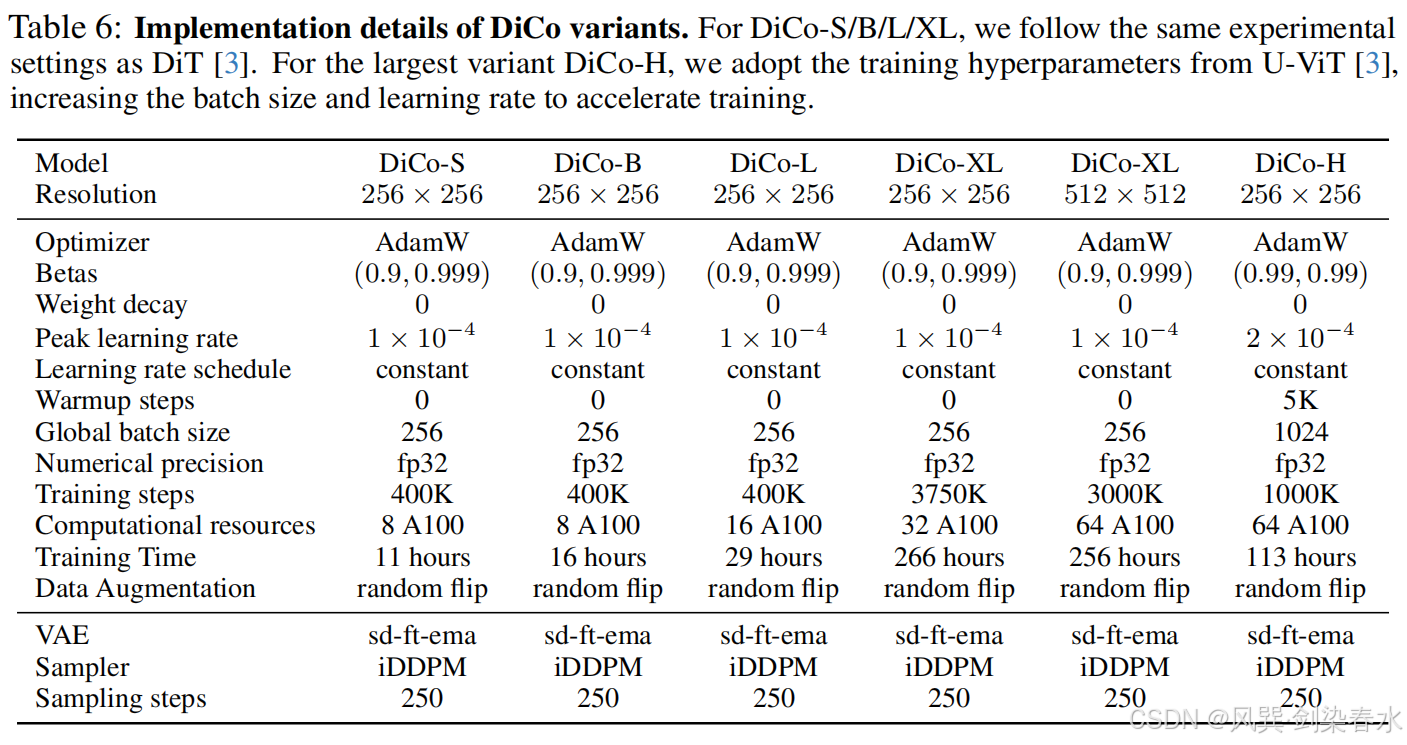
3.2、主要结果
Table 1 | 在 ImageNet 256×256 上与最先进的扩散模型进行比较:使用了与 DiT、DiC 和 DiG 相同的训练超参数;报告的是在 400K 训练步数时的性能,且未使用 CFG(分类器引导机制);用加粗的方式标注了每个模型规模的最佳结果,吞吐量是在 A100 GPU 上,使用 64 的 batch size 以及 fp32 精度进行测量的;DiT 和 DiG 分别通过 FlashAttention-2 和 Flash Linear Attention 进行优化;
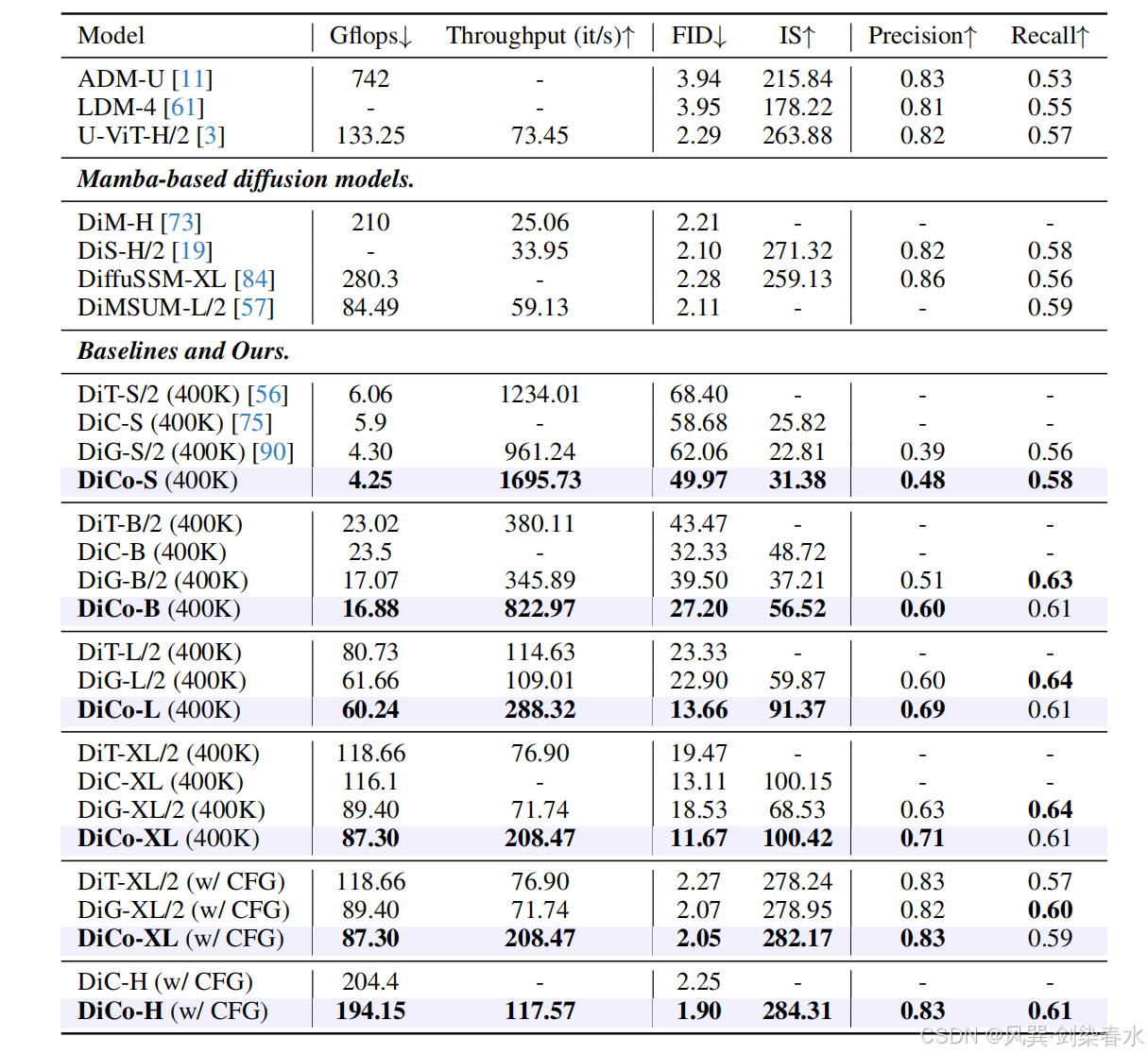
Table 2 | 在 ImageNet 512×512 上与最先进的扩散模型进行比较:用粗体标记了使用 CFG 时的最佳性能;在 1.3M/3M 训练步骤时报告的性能未使用 CFG;
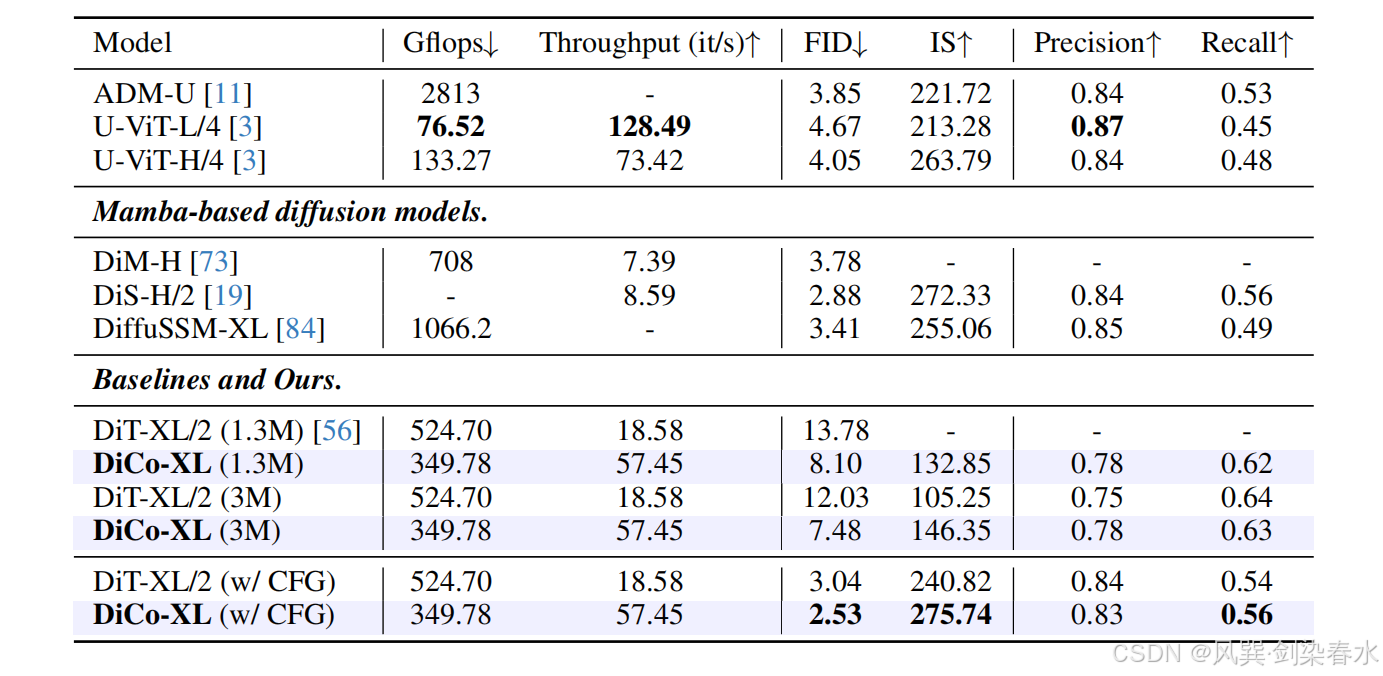
3.3、消融实验
Table 3 | 结构设计消融研究:比较了不同的架构变体,包括各向同性、带跳过连接的各向同性和 U 形;对于所有设计,DiCo始终优于DiT;
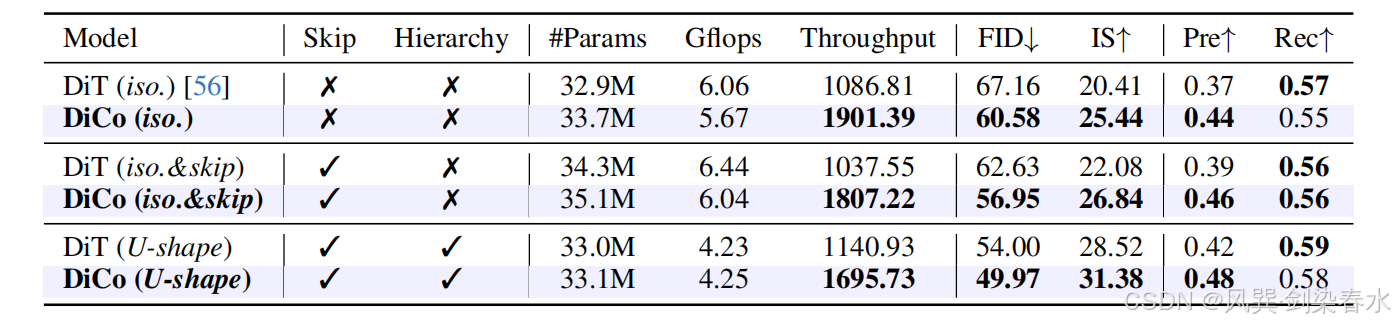
Table 4 | DiCo 组件的消融研究:表明模型的深度和宽度经过调整以实现公平比较;分析了激活函数、深度可分离卷积(DWC)核大小、紧凑通道注意力(CCA)以及卷积模块(CM)的影响;对于 CM,将其与几种先进的高效注意力机制进行比较,以验证其有效性和效率;
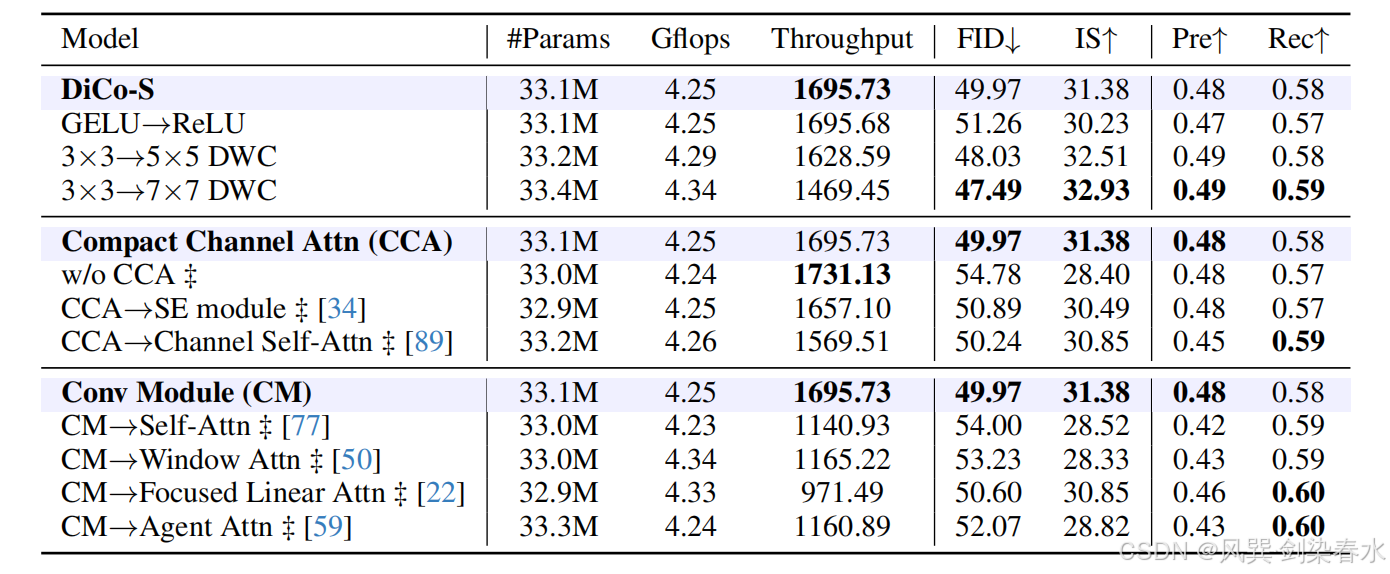
Figure 7 | CCA 能有效减少信道冗余,增强特征多样性:左:DiCo 第一阶段的特征,不使用CCA;右:DiCo 第一阶段的特征;

打起来,打起来(●’◡’●)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









