







一、遍历矩阵时间比较
用c语言写一个大规模矩阵遍历的程序,在不同规模的数据下运行,比较按行遍历快还是按列遍历快。
(一) 程序
//
// main.c
// bianli
//
// Created by mac on 2021/4/30.
//
#include <stdio.h>
#include <stdlib.h>
#include<time.h>
int main()
{
for(int n = 8; n < 40960; n = n*2)
{
const int MAX_ROW = n;
const int MAX_COL = n;
int (*a)[MAX_COL]=(int(*)[MAX_COL])malloc(sizeof(int)*MAX_ROW*MAX_COL);
clock_t start, finish;
//先行后列遍历
start = clock();
for (int i = 0; i<MAX_ROW; i++)
for (int j = 0; j<MAX_COL; j++)
a[i][j] = 1;
finish = clock();
clock_t cost = (finish-start);
printf("The time of traversing the matrix(%d*%d) in a row-first-column manner is %lf μs\n",MAX_ROW ,MAX_COL,(double)cost);
//先列后行遍历
start = clock();
for (int i = 0; i<MAX_COL; i++)
for (int j = 0; j<MAX_ROW; j++)
a[j][i] = 1;
finish = clock();
cost = (finish - start);
printf("The time of traversing the matrix(%d*%d) in a column-first-row manner is %lf μs\n",MAX_ROW ,MAX_COL,(double)cost);
printf("\n");
}
return 0;
}
(二) 运行截图

图1-2 不同规模矩阵遍历时间截图
(三) 结果说明
编写程序时,设定遍历矩阵的规模从88至3276832768。从结果截图来看,遍历的时间在矩阵规模较小时几乎无差异;但神奇的是,随着矩阵规模逐渐变大,“先行后列”的遍历方式的优势逐渐凸显出来,遍历所需时间相较于“先列后行”的方式更短。
经查阅资料,可作以下解释:
1. 在c语言中,数组在内存中是按行存储的,按行遍历时可以由指向数组第一个数的指针一直向后遍历,由于二维数组的内存地址是连续的,当前行的尾与下一行的头相邻,所以可以直接到下一行。
2. CPU高速缓存:在计算机系统中,CPU高速缓存(英语:CPU Cache,在本文中简称缓存)是用于减少处理器访问内存所需平均时间的部件。在金字塔式存储体系中它位于自顶向下的第二层,仅次于CPU寄存器。其容量远小于内存,但速度却可以接近处理器的频率。当处理器发出内存访问请求时,会先查看缓存内是否有请求数据。如果存在(命中),则不经访问内存直接返回该数据;如果不存在(失效),则要先把内存中的相应数据载入缓存,再将其返回处理器。缓存之所以有效,主要是因为程序运行时对内存的访问呈现局部性(Locality)特征。这种局部性既包括空间局部性(Spatial Locality),也包括时间局部性(Temporal Locality)。有效利用这种局部性,缓存可以达到极高的命中率。(百度百科解释)。
3. 缓存从内存中抓取一般都是整个数据块,所以它的物理内存是连续的,几乎都是同行不同列的,而如果内循环以列的方式进行遍历的话,将会使整个缓存块无法被利用,而不得不从内存中读取数据,而从内存读取速度是远远小于从缓存中读取数据的。随着数组元素越来越多,按列读取速度也会越来越慢。
二、调用f(35)
在你的PC上,调用f(35)所需要的时间大概是多少?
(一)程序
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int max(int a,int b)
{
return a>b?a:b;
}
int f(int x) {
int s=0;
while(x-- >0) s+=f(x);
return max(s,1);
}
int main(int argc, const char * argv[]) {
clock_t start, end;
start = clock();
f(35);
end = clock();
clock_t cost = (end-start)/CLOCKS_PER_SEC;
printf("The time is %lf s\n",(double)cost);
return 0;
}
(二) 运行结果截图

图2-1 f(35)调用时间截图
(三)结果说明
说来惭愧,上大学以来,写这种控制台程序,还真没遇到过,写完老长时间都没反应。所以一开始,我以为,自己的程序写错了。
后来发现,果然,老师给的程序有小小纰漏——
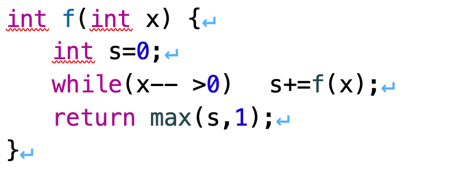
图2-2 程序纰漏说明
这里的while(x-- >0)应该是x–,而非x++。否则就是死循环了哈哈~
解决了这个问题之后,程序还是老样子,长时间没反应。我又开始自我怀疑了“难不成我的printf()函数出问题了?”。于是上网搜索一通,无解……
那肯定是方向错了,所以我又开始回归程序。没准,是这个函数调用的递归规模忒大了!
经过测试,的确是这样,当调用f(3)甚至f(30)时,我几乎都没有等待,秒出结果。于是乎,耐住性子又等了一会,数分钟过,终于蹲到了f(35)的调用时间,如截图2-2所示。

图2-2 调用f(35)程序运行时间截图(单位有误)
但是机智的我,把这个毫秒数换算成分钟之后,发现事情不对,于是去调查clock()资料去了。
关于clock()函数的说明:
clock函数返回的是cpu时间,并不是秒数,真正的一秒钟可能包含若干个CPU时间,这个值通常是由宏CLOCKS_PER_SEC来定义,表示一秒中有CLOCKS_PER_SEC这么多个cpu时间,不同的编译器可能不同,比如,linux C中,它是1000000,在VC6中,它是1000,用cost除以CLOCKS_PER_SEC即可得到实际的秒数。
CLOCKS_PER_SEC是标准c的time.h头函数中宏定义的一个常数,表示一秒钟内CPU运行的时钟周期数,用于将clock()函数的结果转化为以秒为单位的量,但是这个量的具体值是与操作系统相关的, macOS系统中该值是10^6。
所以,我的程序打印的时间,单位用错了(题目一和题目二都是,所以题目一我也翻了个工(╥╯^╰╥),为了看起来更清晰明了,题目一的结果已经是翻工之后的正确结果了),f(35)真正调用时间为图2-1所示。
这个程序告诉我们,当递f(35)归层数太多时,会严重影响程序运行效率。















 5893
5893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









