







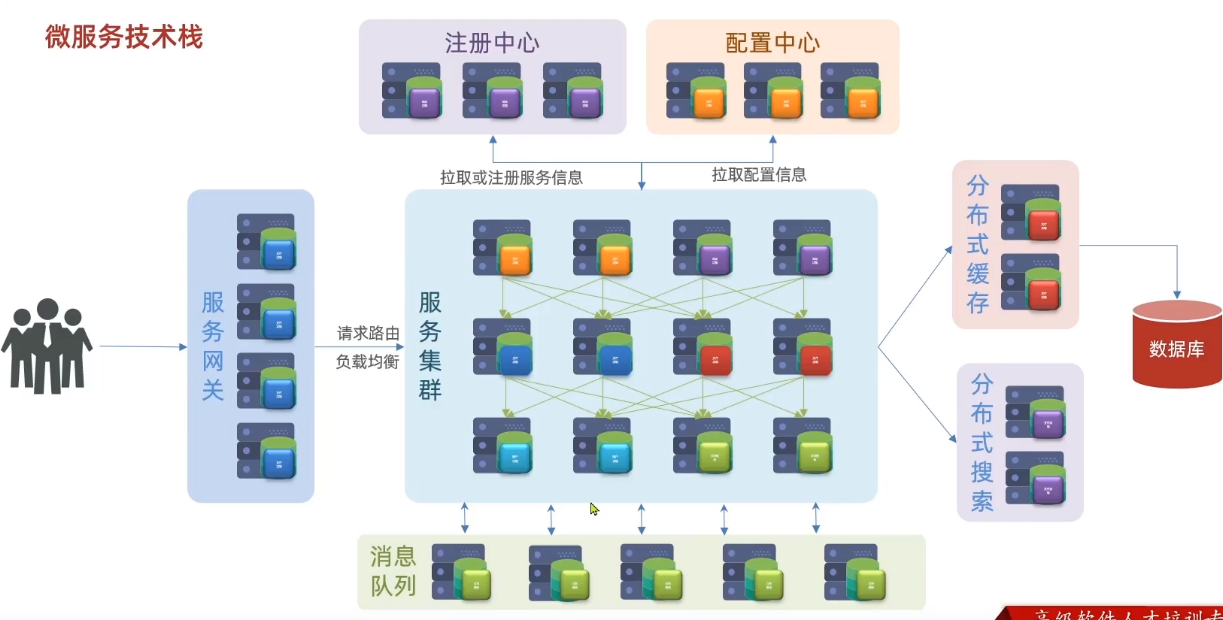
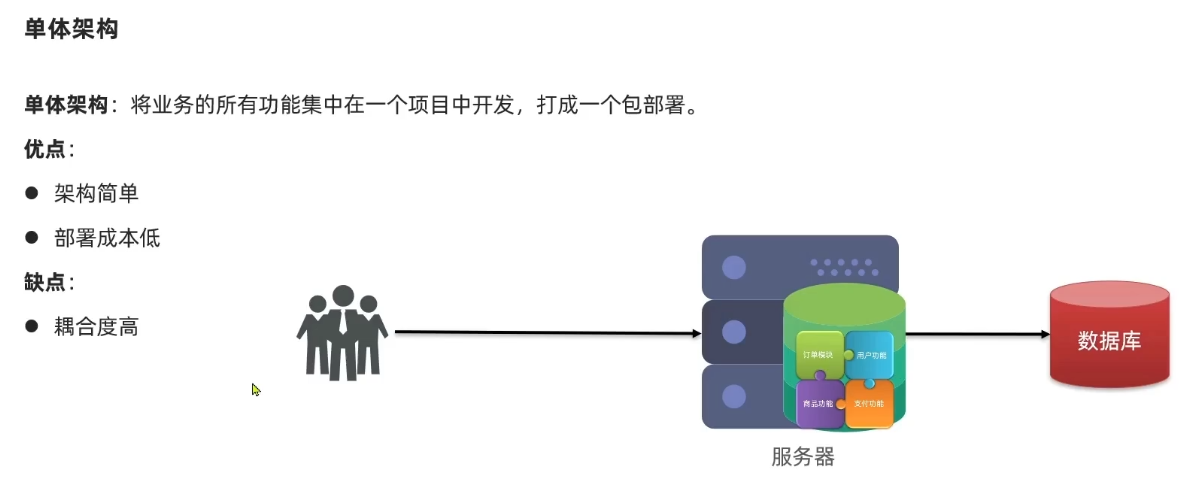
微服务做的第一件事就是拆分,因为传统的单体架构,所有的业务功能都写在一起,随着业务越来越多,代码耦合度越来越高,将来升级维护就会很困难。
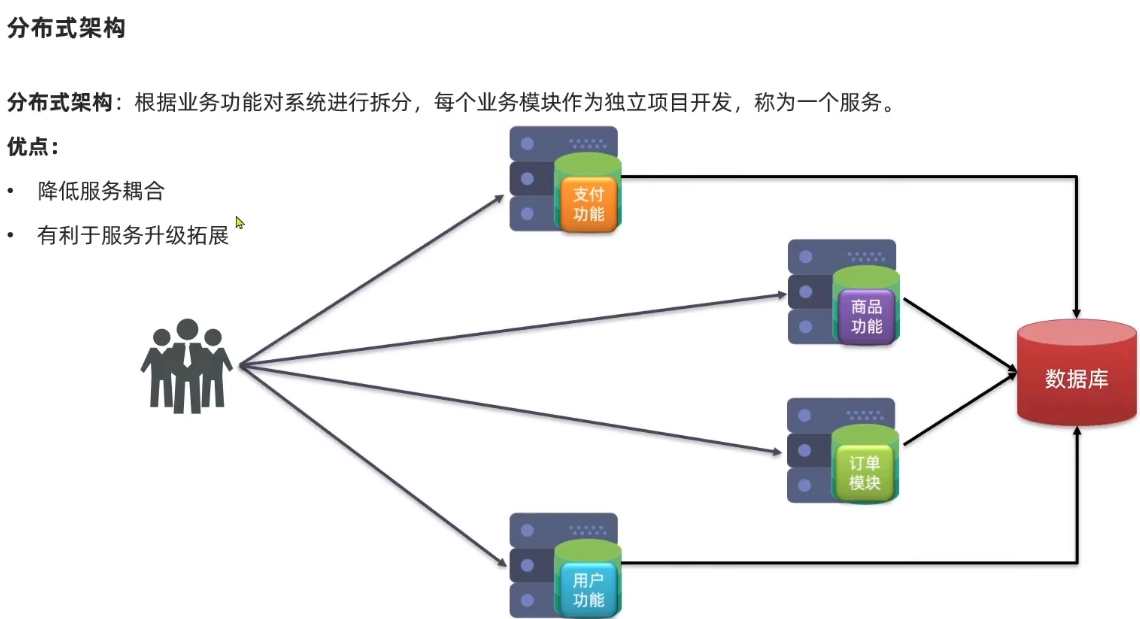
建一个单体的项目拆分为多个独立的项目,每个项目完成一部分业务功能,将来独立开发和维护,将一个独立的项目称为服务。一个大型的项目会包含多个服务,最终构成一个服务集群。
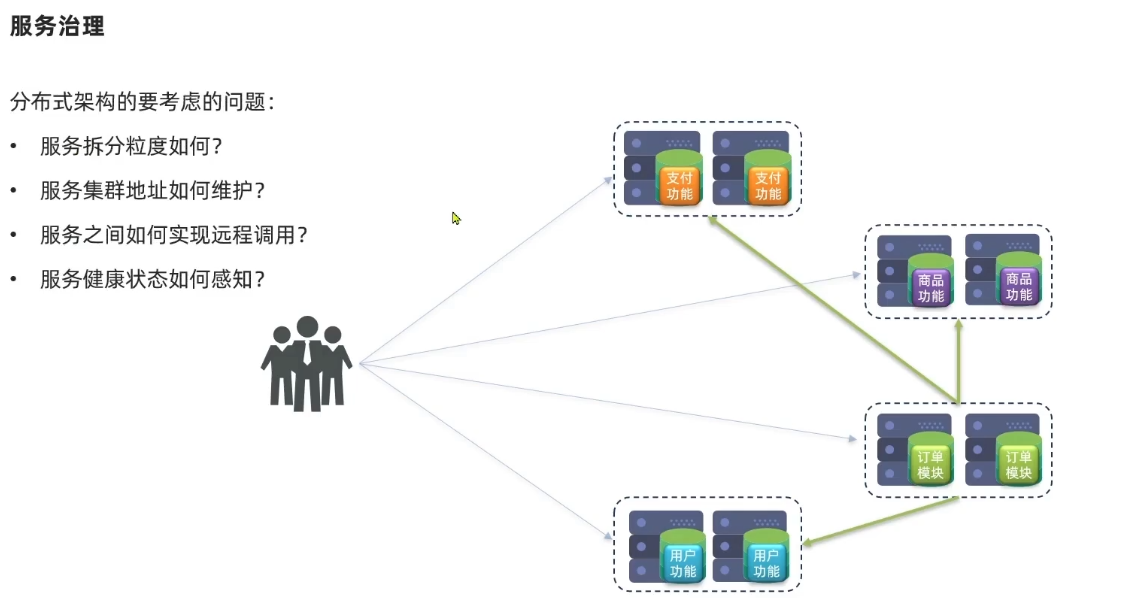
一个业务可能需要多个服务完成。比如一个请求来了,先去调用服务A,再去调用服务B,这种调用关系由微服务中的注册中心来管理,记录微服务中每一个服务的ip和端口,以及它能做什么。当一个服务需要调用其他的服务时,只需要去找注册中心即可,去注册中心拉去对应的服务信息。
每个服务都有自己的配置,在微服务中还有一个配置中心,统一的管理整个服务集群的成千上百的配置。如果你有什么配置需要更改,只需要去找配置中心,它会去通知相关的微服务,实现配置的热更新。
当用户去访问服务集群的时候还需要一个服务网关(对用户身份的校验,将用户的请求路由到具体的请求(还可以将请求进行负载均衡))
为了抗住高并发的流量会引入分布式缓存。将数据的数据放入到内存中。
搜索功能,简单查询可以走缓存,一些海量数据的搜索统计和分析,缓存也做不了,这个时候需要用到分布式搜索功能。
数据库主要用来做写操作、对事务安全要求比较高的存储操作。
异步通信的消息队列组件:对于分布式服务或者微服务来说,业务往往会跨越多个服务,整个调用的链路就会很长,性能有一定的下降。
异步通知的意思是请求来了,服务A并不是去调用服务B、服务C,而是发消息通知他俩,让他俩去干活,这时服务A就结束了,业务链路变短了,响应时间变短了。
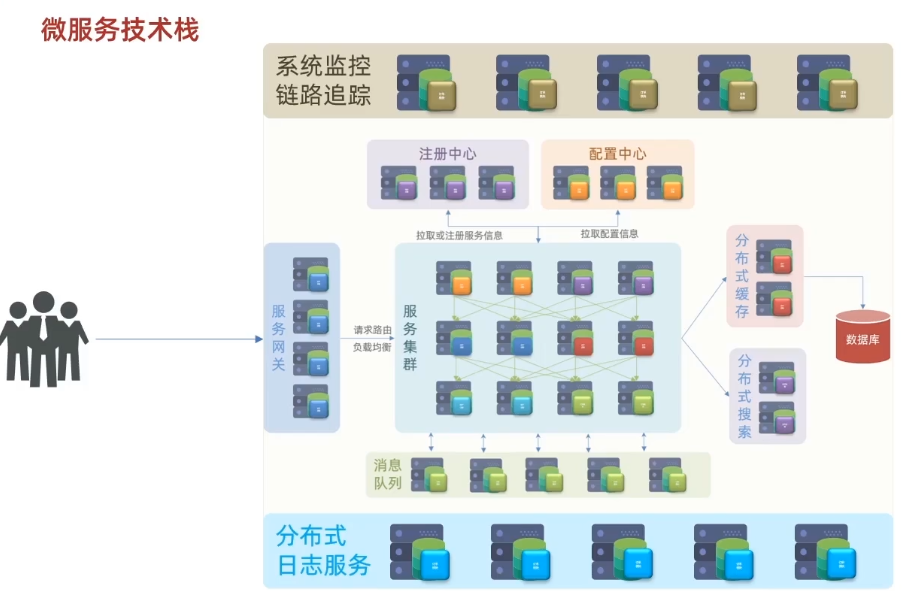
出了问题怎么排查呢?
分布式日志服务:用来记录整个服务集群中的日志操作,统计,分析,将来出现问题好进行定位。
系统监控链路追踪:实时监控每个服务中的运行状态:cpu的负载、内存的占用等。一旦出现问题可以直接定位到具体的方法,栈信息。
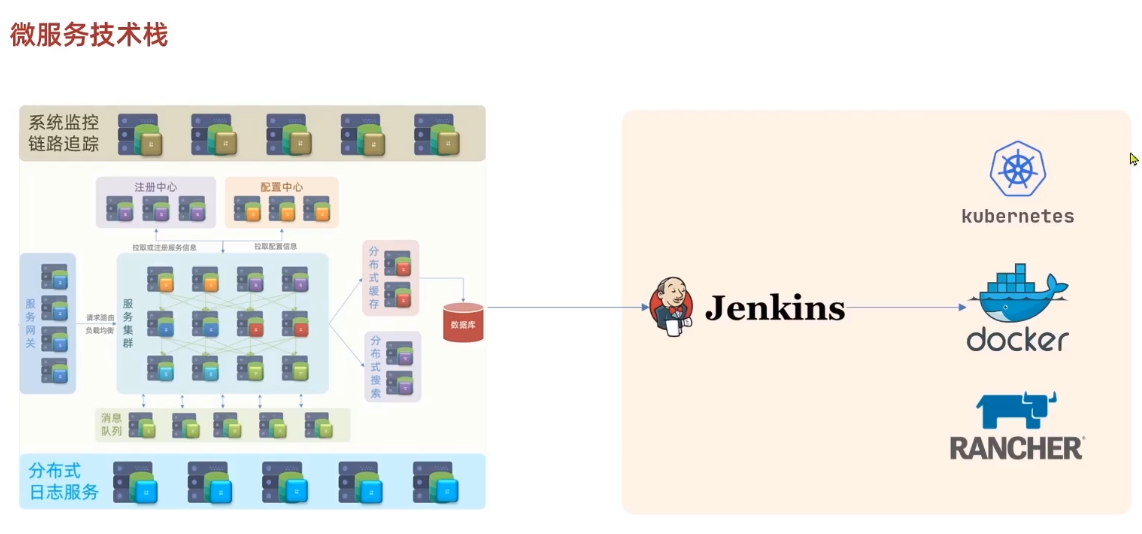
那如此庞大怎么部署呢?
微服务集群需要一个自动化的部署,利用Jenkins工具,自动化的对这些微服务进行编译,再利用docker进行打包形成镜像。再利用RANCHER、kubernetes实现自动化的部署。这成为持续集成。
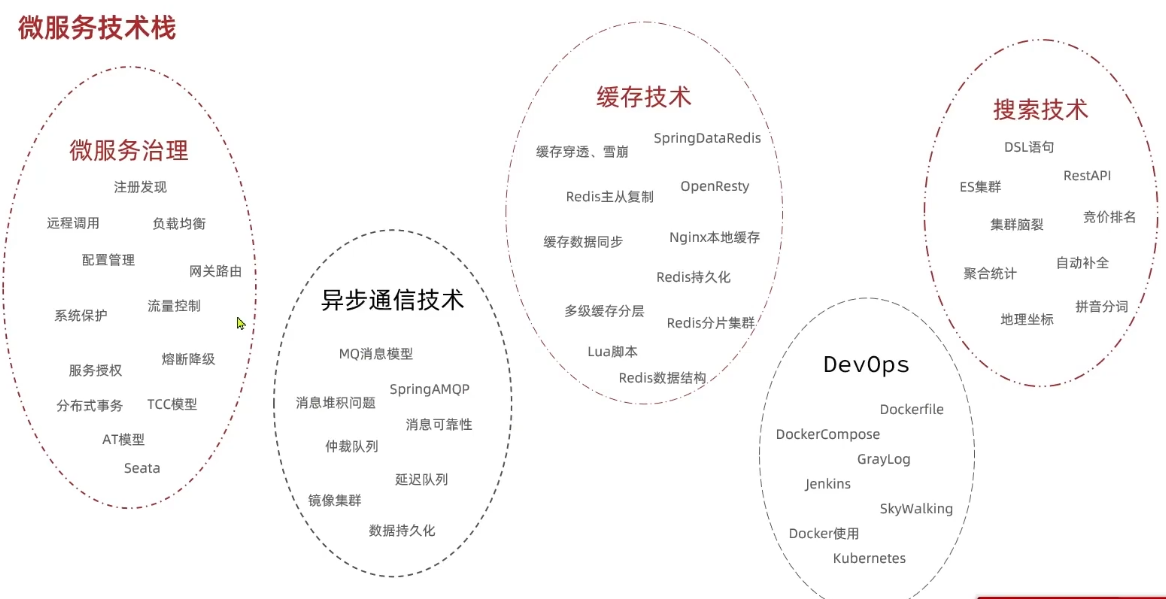
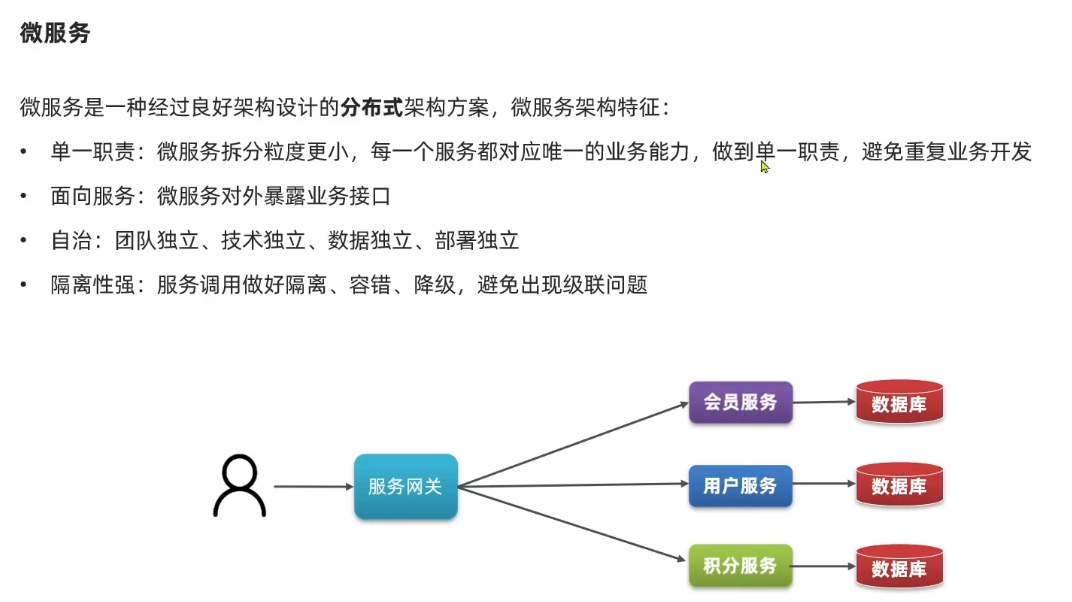
总结:高内聚低耦合
















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









