







Kafka 3.x
1、定义
Kafka 传统定义
Kafka是一个分布式的基于发布/订阅模式的消息队列,主要用于大数据实时处理领域。消息的发布者不会将消息直接发送给订阅者,而是将消息分成不同的类别,订阅者只接受自己感兴趣的消息
Kafka最新定义
Kafka是一个开源的分布式事件流平台,被数千家公司用于高性能数据管道、流分析、数据集成和关键人物应用。
在我们常见使用的电商平台如淘宝,京东中,会根据用户的操作,如浏览,点击,评论,点赞等进行埋点,将获取的数据收集到日志收集系统中,然后交给大数据进行分析处理,也就是我们常说的千人千面系统,能够实现对用户的精准推荐
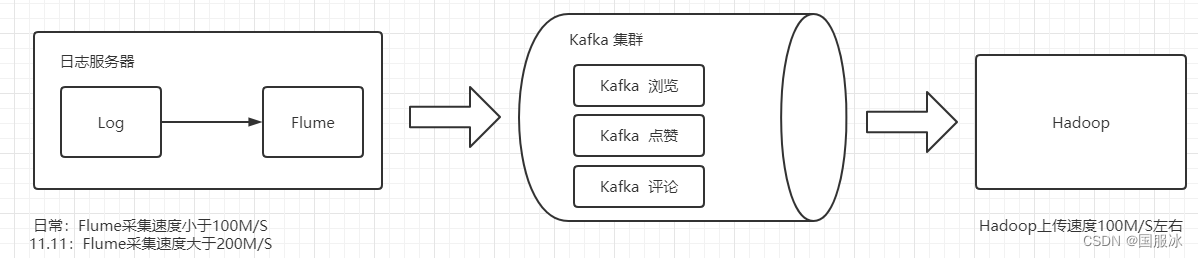
在日常运行中由于数据量不大,我们的Flume采集速度可能在100M/S,但是当遇到618或者双11的大促时,数据量会大幅度增加,此时Flume采集速度可能在200M/S,但是由于我们的Hadoop上传速度在100M/S左右,此时引入Kafka进行消息数据的缓冲,Hadoop可以按照自己的速率根据不同的主题到Kafka中进行消费,从而达到削峰的效果
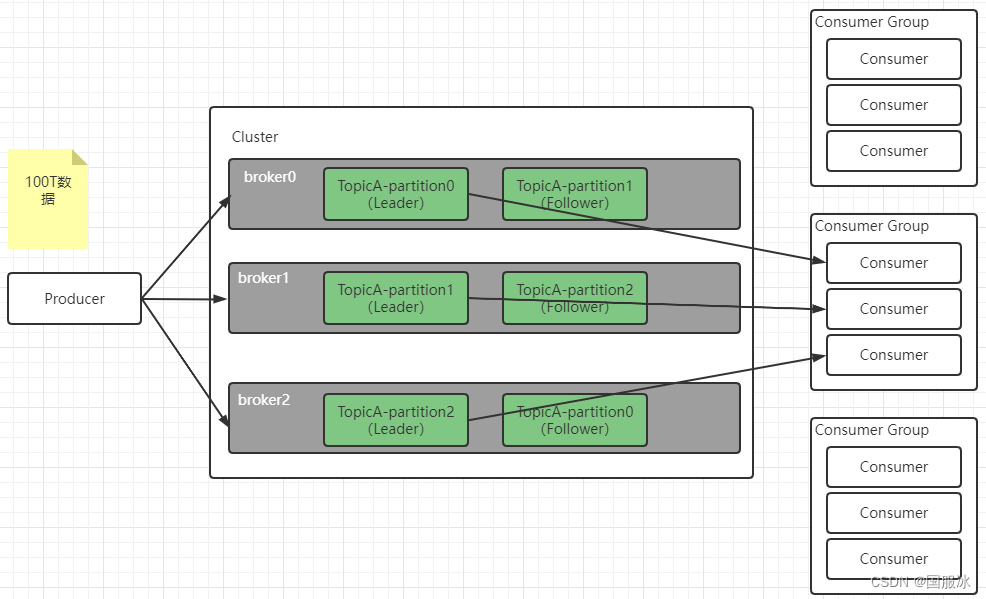
Kafka基础架构
假如现在有100T的数据需要经过Kafka,我们的单台服务器基本上不会直接存储100T的数据,所以Kafka采用分而治之的思想,将数据分块存放,在Kafka中,一个Topic对应多个broker(节点服务器)或者说partition(分区)
由于数据分在不同区中存储,所以Kafka的消费者也采用了分组的操作,consumer group下可以有一个或多个consumer instance,consumer instance可以是一个进程也可以是一个线程,一个消费者组对应一个topic的消费,在消费者组中的消费者是并行消费的,也就是每个分区只能由一个消费者组中的一个消费者进行消费,同一个组中的其他消费者则不能消费该分区的消息(不同组可以消费)
为了提高可用性,为每个partition增加了若干个副本进行容灾,也就是主从的结构,只有leader节点进行消息的消费,当leader挂掉之后,follower才能有条件成为新的leader
在2.8.x之前会存在zookeeper存放kafka节点,分区,主题,主从相关信息,但是在3.x zookeeper不是必选项,因为随着版本的迭代,kafka的瓶颈受到了zookeeper的限制,所以未来kafka会朝着去zookeeper方向跟进














 206
206











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









