







Nacos集群CP架构底层Raft协议实现
一、CAP定理
百度百科:CAP原则又称CAP定理,指的是在一个分布式系统中, 一致性(Consistency)、可用性(Availability)、 分区容错性(Partition tolerance)。CAP 原则指的是,这三个要素最多只能同时实现两点,不可能三者兼顾
分区容错性
分区指的是由于网络或者一些不可控因素导致集群中某些节点不连通的情况,而分区容错性指的是当我们的分布式系统出现了分区的情况时,还能够对外提供正常的服务,叫做分区容错性
在目前看来,分区容错性在一个分布式系统中基本上是必备,如下图就是在Nacos集群中出现了网络分区的情况,导致部分节点间无法进行数据同步
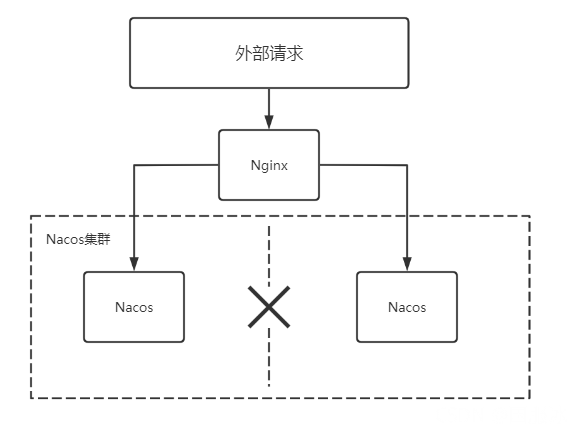
在一个分布式系统中,由于分区容错性是一定要存在的,那么我们就需要在可用性和一致性上做相关的取舍,下面我们来分析为什么C与A两种状态不能同时存在
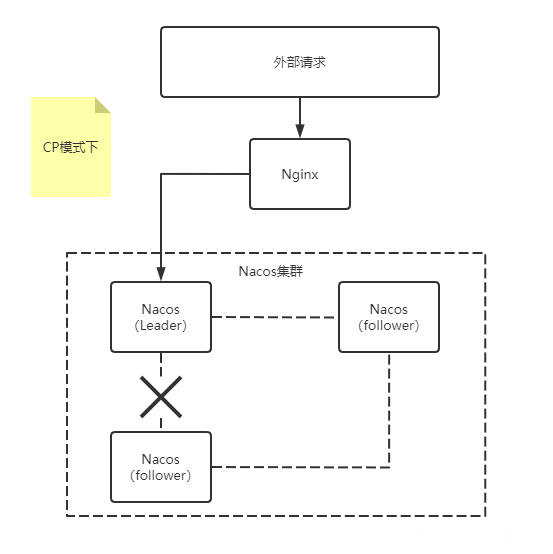
CP模式
现在我们的Nacos集群中存在三个节点,一个主节点,两个从节点,当主节点与一个从节点出现了分区后,如果我们的前提是需要保证整个系统的一致性,也就是需要保证Consistency这个状态存在
整个集群会发起主节点的重新选举,选举完成后同步所有的数据来保持数据的一致性,那么在选主的过程中,一定会导致一段时间的不可用,当然这个时间会极短,从而不能保证完全可用性
AP模式
在AP模式下我们的集群没有主从的概念,所有的节点都是平等的,并且每个节点间的数据都互通
如果两个节点中间发生了分区情况,两个节点不再连通,但是我们的系统又必须保证整体的可用性,所以节点间会出现一段时间的数据不一致,直到分区恢复

二、Raft算法
在学术界中分布式一致性算法的基石还是Paxos为代表,Paxos算法是Lamport宗师提出的一种基于消息传递的分布式一致性算法,使其获得2013年图灵奖。
由于Paxos难以理解,而且很难落地到工程实践,所以Paxos在工程中运用的并不多
取而代之的是易理解易实现的Raft算法,号称几乎等同于Paxos,但是性能肯定不及Paxos
分布式一致性算法也称为共识算法,是指在大型分布式系统中,在遇到请求时,各个节点的数据能够保持一致,并且在遇到部分机器宕机时,也能保证整体服务的数据一致性
学习Raft算法最好的方式则是阅读论文:https://raft.github.io/raft.pdf
关于Raft协议步骤动画:http://thesecretlivesofdata.com/raft/
这里我们了解Raft算法中核心逻辑,Raft算法中其实大致分为三个子问题
Leader Election 、Log Replication、Safety,对应的也就是选主,日志复制,安全性(通过安全性原则来处理一些特殊 case,保证 Raft 算法的完备性)
所以Raft的核心流程可以归纳为:
- 首先选出
leader,leader节点负责接收外部的数据更新/删除请求 - 然后日志复制到其他
follower节点,同时通过安全性的准则来保证整个日志复制的一致性 - 如果遇到 leader 故障,
followers会重新发起选举出新的leader
Raft节点有三种状态:
- Leader(领导者)
- Follower(跟随者)
- Candidate(候选人)
Leader Election 领导选举
- 所有节点一开始都是
follower状态,一定时间未收到leader的心跳,则进入candidate(候选人)状态,参与选举 - 选出
leader后,leader通过向follower发送心跳来表明存活状态,若leader故障,则整体退回到重新选举状态 - 每次选举完成后,会产生一个
term,term本身是递增的,充当了逻辑时钟的作用
具体的选举过程:领导者与跟随者建立心跳(心跳时间随机,为了避免大多数跟随者在同一时间进行选举)并等待,若超时未等到,准备选举 ----> current term ++,转变为candidate(候选人)状态 ----> 给自己投票,然后给其他节点发送投票请求 ----> 等待选举结果
具体投票过程有三个约束:
- 在同一任期内,单个节点最多只能投一票
- 候选人知道的信息不能比自己的少(
Log与term) first-come-first-served先来先得
选举结果有三种情况:
- 收到大部分(超过半数)的投票(含自己的一票),则赢得选举,成为
leader - 被告知别人已当选,那么自行切换到
follower - 一段时间内没有收到超过半数以上的投票,则保持
candidate状态,重新发出选举。(ps:如果是遇到平票现象,则会增加系统不可用时间,因此,raft中引入了randomized election timeouts,尽量避免出现平票现象的产生)一旦选举完毕,leader节点会给所有其他节点发消息,避免其他节点触发新的选举
Log Replication 日志复制
Replicated state machine 复制状态机
复制状态机一般通过复制日志来实现,简单地描述一下:leader将写请求封装成一个个的log entry,然后将这些entries复制到follower,所有follower都按照这个这个顺序执行其中的command,那么所有server的状态一定是一致的。这就是raft的做法

复制过程
- 客户端的请求包含了被复制状态机执行的指令,并转发给
leader leader把指令作为新的日志,并发送给其他server,让他们复制- 假如日志被安全的复制(收到超过
majority的ack),leader会将日志添加到状态机中,并返回给客户端 - 如果
follower丢失,leader会不断重试,直到全部follower都最终存储了所有日志条目
当然,以上都是理想情况,如果出现崩溃、网络中断等情况,则可能出现日志不正常的现象,则需要考虑数据一致性和安全性问题
参考文章:
Raft算法详解
图解 Raft 共识算法:如何复制日志?















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









