








Hello,我是普通Gopher,00后男孩,极致的共享主义者,想要成为一个终身学习者。专注于做最通俗易懂的计算机基础知识类公众号。每天推送Golang技术干货,内容起于K8S而不止于K8S,涉及Docker、微服务、DevOps、数据库、虚拟化等云计算内容及SRE经验总结
=======================
初次见面,我为你准备了100G学习大礼包:
1、《百余本最新计算机电子图书》
2、《30G Golang学习视频》
3、《20G Java学习视频》
4、《90G Liunx高级学习视频》
5、《10G 算法(含蓝桥杯真题)学习视频》
6、《英语四级,周杰伦歌曲免费送!》
路过麻烦动动小手,点个关注,持续更新技术文章与资料!
目录:
GitHub项目地址:https://github.com/PlutoaCharon/Golang_logCollect⭐
Golang实战之海量日志收集系统(二)收集应用程序日志到Kafka中
Golang实战之海量日志收集系统(三)简单版本logAgent的实现
Golang实战之海量日志收集系统(四)etcd介绍与使用etcd获取配置信息
Golang实战之海量日志收集系统(五)根据etcd配置项创建多个tailTask
Golang实战之海量日志收集系统(六)监视etcd配置项的变更
Golang实战之海量日志收集系统(七)logTransfer之从kafka中获取日志信息
Golang实战之海量日志收集系统(八)logTransfer之将日志入库到Elasticsearch并通过Kibana进行展示
项目背景
项目架构图:
- 每个系统都有日志,当系统出现问题时,需要通过日志解决问题
- 当系统机器比较少时,登陆到服务器上查看即可满足
- 当系统机器规模巨大,登陆到机器上查看几乎不现实
每个业务系统都有自己的⽇志,当业务系统出现问题时,需要通过查找⽇志信息来定位和解决问题。 当业务系统服务器⽐较少时,登陆到服务器上查看即可满⾜。但当系统机器规模巨⼤,登陆到服务器上查看⼏乎不现实(分布式的系统,⼀个系统部署在⼗⼏甚至几十台服务器上)
平常我们在进行业务开发时常常不免遇到下面几个问题:
- 当系统出现问题后,如何根据日志迅速的定位问题出在一个应用层?
- 在平常的工作中如何根据日志分析出一个请求到系统主要在那个应用层耗时较大?
- 在平常的工作中如何获取一个请求到达系统后在各个层测日志汇总?
针对以上问题,我们想要实现的一个解决方案是:
- 把机器上的日志实时收集,统一的存储到中心系统
- 然后再对这些日志建立索引,通过搜索即可以找到对应日志
- 通过提供界面友好的web界面,通过web即可以完成日志搜索
关于实现这个系统时可能会面临的问题:
- 实时日志量非常大,每天几十亿条
- 日志准实时收集,延迟控制在分钟级别
- 能够水平可扩展
业界方案
有早期的ELK到现在的EFK。ELK在每台服务器上部署logstash,比较重量级,所以演化成客户端部署filebeat的EFK,由filebeat收集向logstash中写数据,最后落地到elasticsearch,通过kibana界面进行日志检索。
优缺点
优点:现成的解决方案,直接拿过来用,能够实现日志收集与检索。
缺点:
- 运维成本⾼,每增加⼀个⽇志收集项,都需要⼿动修改配置
- 监控缺失,⽆法准确获取logstash的状态。⽆法做到定制化开发与维护
- ⽆法做到定制化开发与维护
日志收集系统设计
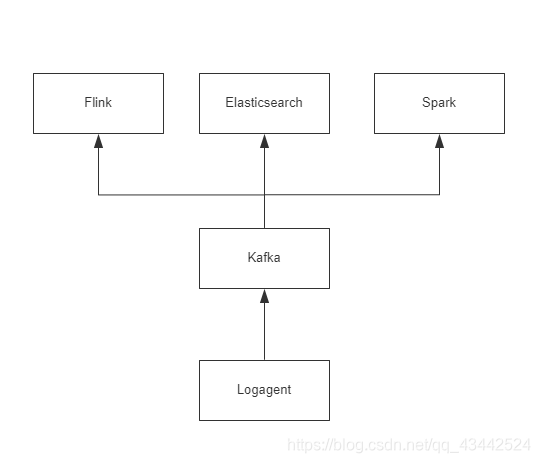
各个组件说明:
Log Agent,日志收集客户端,用来收集服务器上的日志
Kafka,高吞吐量的分布式队列
Elasticsearch,开源的搜索引擎,提供基于http restful的web接口
Flink,Spark,分布式计算框架,能够对大量数据进行分布式处理的平台
关于Kakfa的介绍
-
Kafka是一个分布式发布 - 订阅消息系统和一个强大的队列,可以处理大量的数据,并使您能够将消息从一个端点传递到另一个端点。 -
Kafka适合离线和在线消息消费。 -
Kafka消息保留在磁盘上,并在群集内复制以防止数据丢失。 -
Kafka构建在ZooKeeper同步服务之上。 它与Flink和Spark非常好的集成,用于实时流式数据分析。
Kafka中有几个基本的消息术语:
- Kafka将消息以topic为单位进行归纳。
- 将向Kafka topic发布消息的程序成为producers.
- 将预订topics并消费消息的程序成为consumer.
- Kafka以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个broker
Kafka的优点:
- 可靠性 - Kafka是分布式,分区,复制和容错的。
- 可扩展性 - Kafka消息传递系统轻松缩放,无需停机。
- 耐用性 - Kafka使用分布式提交日志,这意味着消息会尽可能快地保留在磁盘上,因此它是持久的。
- 性能 - Kafka对于发布和订阅消息都具有高吞吐量。 即使存储了许多TB的消息,它也保持稳定的性能。
- Kafka非常快,并保证零停机和零数据丢失。
Kafka的应用场景:
-
异步处理, 把非关键流程异步化,提高系统的响应时间和健壮性
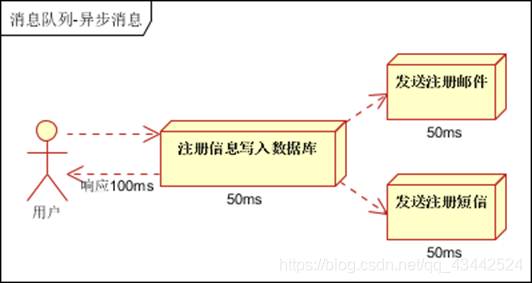
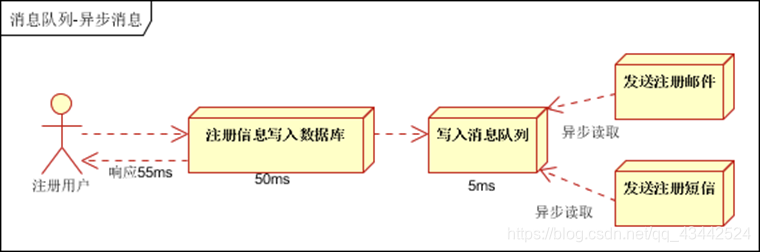
-
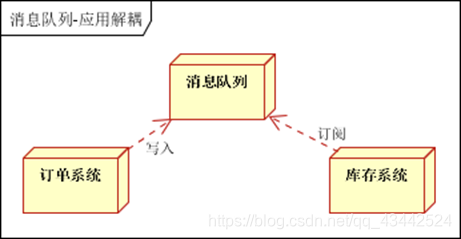
应用解耦,通过消息队列
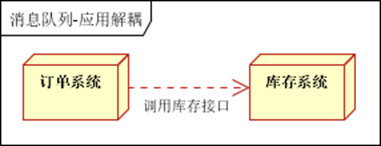
-
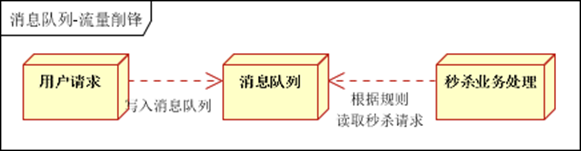
流量削峰
ZooKeeper介绍
ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
Apache ZooKeeper是由集群(节点组)使用的一种服务,用于在自身之间协调,并通过稳健的同步技术维护共享数据。ZooKeeper本身是一个分布式应用程序,为写入分布式应用程序提供服务。
ZooKeeper主要包含几下几个组件:
- Client(客户端):我们的分布式应用集群中的一个节点,从服务器访问信息。对于特定的时间间隔,每个客户端向服务器发送消息以使服务器知道客户端是活跃的。类似地,当客户端连接时,服务器发送确认码。如果连接的服务器没有响应,客户端会自动将消息重定向到另一个服务器。
- Server(服务器):服务器,我们的ZooKeeper总体中的一个节点,为客户端提供所有的服务。向客户端发送确认码以告知服务器是活跃的。
- Ensemble:ZooKeeper服务器组。形成ensemble所需的最小节点数为3。
- Leader: 服务器节点,如果任何连接的节点失败,则执行自动恢复。Leader在服务启动时被选举。
- Follower:跟随leader指令的服务器节点。
- ZooKeeper的应用场景:
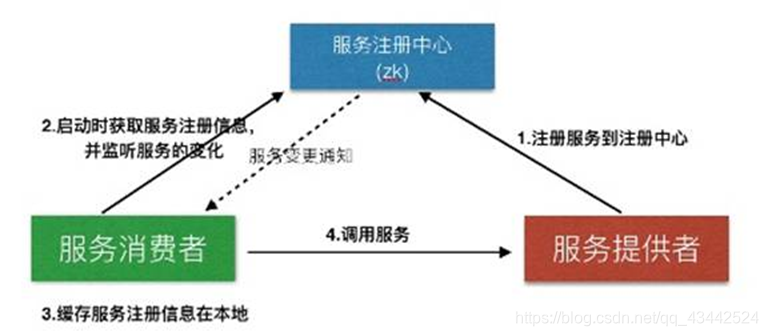
服务注册&服务发现
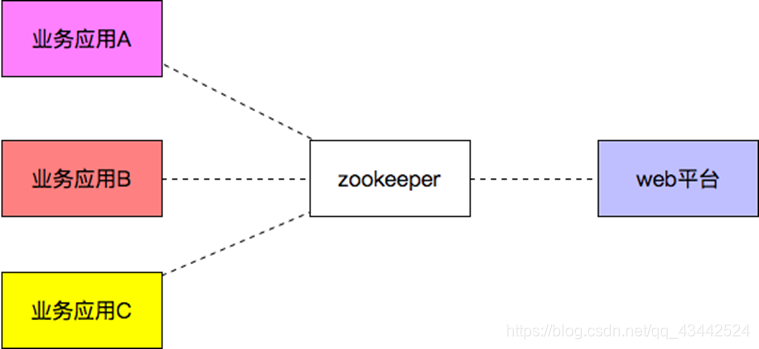
配置中心
- 分布式锁
Zookeeper是强一致的多个客户端同时在Zookeeper上创建相同znode,只有一个创建成功
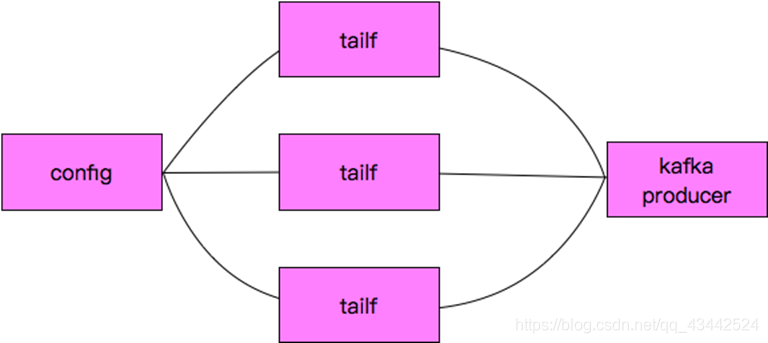
关于Log Agent
主要实现的功能是:
类似于我们在linux下通过tail的方法读日志文件,讲读取的内容发给Kafka
我们这里的tailf是可以动态变化的,当配置文件发生变化时,可以通知我们程序自动增加需要增加的配置文件
tailf去获取相应的日志并发给kafka producer
主要由一下几部目录组成:
Kafka
tailf
configlog
该项目中Zookeeper与Kafka可以安装在Liunx环境中使用远程连接,也可以在Windows本地安装连接使用
具体安装参考我的这篇博客: Windows10安装运行Kafka2.1.0与Zookeeper3.4.14
















 2015
2015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









