







文章目录
第7章 存储系统
7.3 降低Cache不命中率
总共介绍
8种降低不命中率的方法
7.3.1 三种类型的不命中
按照产生不命中的原因,可以把不命中分为三种类型
强制性不命中(Compulsory miss)
- 当第一次访问一个块时,该块不在Cache中,需从下一级存储器中调入Cache,这就是强制性不命中。 (冷启动不命中,首次访问不命中)
容量不命中(Capacity miss )
- 如果程序执行时所需的块不能全部调入Cache中,则发生容量缺失,随后再被调入。这种不命中称为容量不命中。
冲突不命中(Conflict miss)
- 在组相联或直接映象Cache中,若太多的块映象到同一组(块)中,则会出现该组中某个块被别的块替换(即使别的组或块有空闲位置),然后又被重新访问的情况。这就是发生了冲突不命中。
经过测试数据可以得出以下结论:
- 相联度越高,冲突不命中就越少;
- 强制性不命中和容量不命中不受相联度的影响;
- 强制性不命中不受Cache容量的影响,但容量不命中却随着容量的增加而减少。
减少三种不命中的方法
- 强制性不命中:增加块大小,预取(本身很少)
- 容量不命中:增加容量 (抖动现象)
- 冲突不命中:提高相联度(理想情况:全相联)
许多降低不命中率的方法会增加命中时间或不命中开销
7.3.2 增加Cache块大小
不命中率与块大小的关系
- 对于给定的Cache容量,当块大小增加时,不命中率开始是下降,后来反而上升了(先下降后上升)。
- Cache容量越大,使不命中率达到最低的块大小就越大。
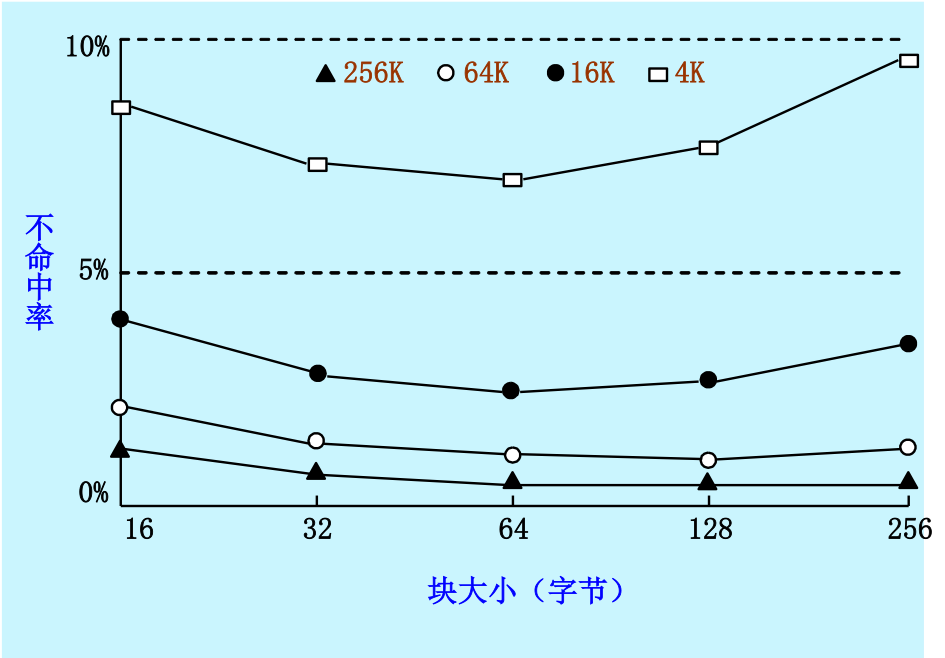
原因是增加块大小产生了双重作用:
- 增强了空间局部性,减少了强制性不命中
- 由于增加块大小会减少Cache中块的数目,所以有可能会增加冲突不命中
值得注意的是:增加块大小会
增加不命中开销。需要在其降低不命中率与增加不命中开销直接进行权衡。
7.3.3 增加Cache的容量
这是降低Cache不命中率
最直接的办法(这种方法在片外Cache中用得比较多 )
缺点:
- 增加成本
- 可能增加命中时间
7.3.4 提高相联度
采用相联度超过8的方案的实际意义不大。(8路组相联的作用已经与全相联相差不大)
2:1 Cache经验规则
- 容量为
N的直接映象Cache的不命中率和容量为N/2的两路组相联Cache的不命中率差不多相同。
注意:提高相联度是以增加命中时间为代价。
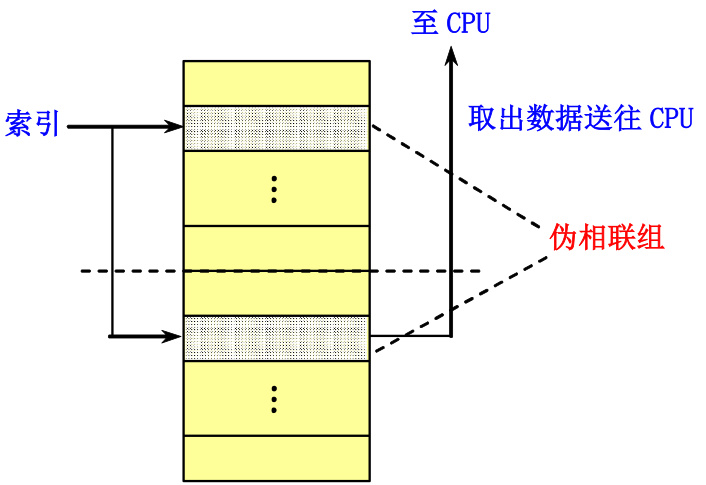
7.3.5 伪相联 Cache (列相联 Cache )
这一方法结合了多路组相联的低不命中率和直接映象的命中速度
| 优点 | 缺点 | |
|---|---|---|
| 直接映像 | 命中时间小 | 不命中率高 |
| 组相联映像 | 不命中率低 | 命中时间大 |
伪相联Cache的优点
- 命中时间小
- 不命中率低
基本思想及工作原理
- 在逻辑上把直接映象Cache的空间上下平分为两个区。对于任何一次访问,伪相联Cache先按直接映象Cache的方式去处理(快速命中)。
- 若命中,则其访问过程与直接映象Cache的情况一样。
- 若不命中,则再到另一区相应的位置去查找。若找到,则发生了伪命中,否则就只好访问下一级存储器。
存在的问题
-
如果直接映象Cache的许多快速命中,在伪相联Cache中变为慢速命中,则这种方法降低整体性能。需要指出哪一个块是快速的最重要。
-
解决方法:出现伪命中时把最近访问过的块发在第一位置(根据程序的局部性原理)。
缺点
- 多种命中时间,使得
流水线设计变复杂
7.3.6 硬件预取
指令和数据都可以在处理器提出访问请求之前预取
预取内容既可放入Cache,也可放在外缓冲器中(访问速度比主存快)。
指令预取通常由Cache之外的硬件完成
预取效果——Joppi的研究结果
-
指令预取 (4KB,直接映象Cache,块大小=16字节)
1个块的指令流缓冲器: 捕获15%~25%的不命中4个块的指令流缓冲器: 捕获50%16个块的指令流缓冲器:捕获72%
-
数据预取 (4KB,直接映象Cache)
1个数据流缓冲器:捕获25%的不命中- 还可以采用多个数据流缓冲器
结论:预取应利用存储器的空闲带宽,不能影响对正常不命中的处理,否则可能会降低性能。
7.3.7 编译器控制的预取
在编译时加入预取指令,在数据被用到之前发出预取请求。
指令和数据在被用到之前就取到寄存器或者Cache中
按照预取数据所放的位置,可把预取分为两种类型:
- 寄存器预取:把数据取到寄存器中。
- Cache预取:只将数据取到Cache中。
按照预取的处理方式不同,可把预取分为:
-
故障性预取:在预取时,若出现虚地址故障或违反保护权限,就会发生异常。
-
非故障性预取:在遇到这种情况时则不会发生异常,因为这时它会放弃预取,转变为空操作。
最有效的预取,既不会改变指令和数据之间的各种逻辑关系或存储单元的内容,也不会造成虚拟存储器故障。假定后面讨论的Cache预取都是非故障性的,也叫做非绑定预取。
⚠️在预取数据的同时,处理器应能继续执行,预取才有意义。
- 要求Cache在等待预取数据返回的同时,还能继续提供指令和数据,这种Cache称为非阻塞Cache
编译器控制预取的目的
- 使执行指令和读取数据能重叠执行。
循环是预取优化的主要对象
- 不命中开销小时:循环体展开
1~2次 - 不命中开销大时:循环体展开许多次
由于每次预取需要花费一条指令的开销
- 需要保证这种开销不超过预取所带来的收益
- 编译器可以通过把重点放在那些可能会导致不命中的访问上,使程序避免不必要的预取,从而较大程度地减少平均访存时间。
7.3.8 编译器优化
主要用在减少指令不命中和减少数据不命中两方面
基本思想:通过对软件进行优化来降低不命中率。
特色:无需对硬件做任何改动
编译优化技术
-
程序代码和数据重组
-
数组合并
将本来相互独立的多个数组合并成为一个复合数组,以提高访问它们的局部性。
-
内外循环交换
-
循环融合
将若干个独立的循环融合为单个的循环。这些循环访问同样的数组,对相同的数据作不同的运算。这样能使得读入Cache的数据在被替换出去之前,能得到反复的使用 。
-
分块
- 程序代码和数据重组
- 可以重新组织程序而不影响程序的正确性
- 例如,把一个程序中的过程重新排序,就可能会减少冲突不命中,从而降低指令不命中率。
- McFarling研究了如何使用配置文件(profile)来进行这种优化。
- 提高大Cache块的效率:把基本块对齐,使得程序的入口点与Cache块的起始位置对齐,就可以减少顺序代码执行时所发生的Cache不命中的可能性。
对分支指令的优化
如果编译器知道一个分支指令很可能会成功转移,那么它就可以通过以下两步来改善空间局部性:
- 将转移目标处的基本块和紧跟着该分支指令后的基本块进行对调;
- 把该分支指令换为操作语义相反的分支指令。
- 内外循环交换
有些程序的嵌套循环中,程序不是按照数据在存储器中存储的顺序进行访问的,简单的交换循环的嵌套关系,就能使程序按数据在存储器中存储的顺序进行访问
举例:
- 修改前 (大块)空间局部性较差
for ( j = 0 ; j < 100 ; j = j+1 )
for ( i = 0 ; i < 5000 ; i = i+1 )
x[i][j] = 2 * x[i][j];
- 修改后(可访问同一块中各个元素,在访问下一个块。)
for ( i = 0 ; i < 5000 ; i = i+1 )
for ( j = 0 ; j < 100 ; j = j+1 )
x[i][j] = 2 * x[i][j];
- 分块
通过提高时间局部性来减少不命中。
例如,把对数组的整行或整列访问改为按块进行。
举例
- 矩阵乘法(修改前)
- 计算过程(不命中次数: 2 N 3 + N 2 2N^{3}+N^{2} 2N3+N2)
for ( i = 0; i<N; i = i+1 ){
for ( j = 0; j < N; j = j+1 {
r = 0;
for ( k = 0; k < N; k = k+1){
r = r + y[ i ][ k ] * z[ k ][ j ];
}
x[ i ][ j ] = r;
}
}
- 矩阵乘法(修改后)
- 计算过程 (不命中次数: 2 N 3 / B + N 2 2N^{3} /B +N^{2} 2N3/B+N2)
for ( jj = 0; jj < N; jj = jj+B )
for ( kk = 0; kk < N; kk = kk+B )
for ( i = 0; i < N; i =i+1 )
for ( j = jj; j < min(jj+B-1, N); j = j+1 ) {
r = 0;
for ( k = kk; k < min(kk+B-1, N); k = k+1) {
r = r + y[i][k] * z[k][j];
}
x[i][j] = x[i][j] + r;
}
分块技术的优点:
- 有助于寄存器分配;
- 可以把load和store操作的次数变成最小。
7.3.9 “牺牲” Cache
一种能减少冲突不命中次数而又不影响时钟频率的方法。
容量小,采用命中率较高的全相联映像,而且仅在替换时发生作用
基本思想
- 在Cache和它从下一级存储器调数据的通路之间设置一个
全相联的小Cache,称为“牺牲”Cache(Victim Cache)。用于存放被替换出去的块(称为牺牲者),以备重用。
工作过程
- 每当发生不命中时,在访问下一级存储器之前,先检查“牺牲”Cache中是否有所需要的块。
- 如果有,就将该块与Cache中的某个块做交换,把所需的块从“牺牲”Cache调入Cache。
7.3.10 降低Cache不命中率技术总结
为了描述方便,引入以下记号:
“+”号:表示改进了相应指标。“-”号:表示它使该指标变差。空格栏:表示它对该指标无影响。复杂性:0表示最容易,3表示最
| 优化技术 | 不命中率 | 不命中开销 | 命中时间 | 硬件复杂度 | 说明 |
|---|---|---|---|---|---|
| 增加块大小 | + | - | 0 | 实现容易;Pentium 4 的第二级Cache采用了128字节的块 | |
| 增加Cache容量 | + | 1 | 被广泛采用,特别是第二级Cache | ||
| 提高相联度 | + | - | 1 | 被广泛采用 | |
| 伪相联Cache | + | 2 | MIPS R10000的第二级Cache采用 | ||
| 牺牲Cache | + | 2 | AMD Athlon采用了8个项的Victim Cache | ||
| 硬件预取指令和数据 | + | 2~3 | 许多机器预取指令,UltraSPARC Ⅲ预取数据 | ||
| 编译器控制的预取 | + | 3 | 需同时采用非阻塞Cache;有几种微处理器提供了对这种预取的支持 | ||
| 用编译技术减少Cache不命中次数 | + | 0 | 向软件提出了新要求;有些机器提供了编译器选项 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









