







哈喽,小伙伴们~
好久不见呀,今天我们来学习一下python中的正则表达式模块,正则表达式在其他语言同样可以使用,不过我们今天只看python中的正则表达式用法。
在使用之前,我们首先了解一下正则表达式。
正则表达式是一种非常高效的字符串匹配算法,其专门用于在复杂字符串中匹配特定字符。也许我们之前听过或没听过正则表达式,不过我认为如果想让你的工作效率提高,那么正则表达式是一定要掌握的!
正则表达式元字符
| 符号 | 含义 |
|---|---|
| * | 以前一个字符为依据,重复0次或多次 |
| . | 匹配任意字符,除了换行符 |
| ? | 以前一个字符为依据,出现0次或1次 |
| + | 以前一个字符为依据,出现1次或多次 |
| {m} | 匹配前面字符的m次 |
| {m,} | 匹配前面字符至少m次 |
| {m,n} | 匹配前面字符,至少m次,至多n次 |
| [] | 中括号内是一个字符集合,表示匹配集合内的任意一个符号 |
| 0-9a-zA-Z | 表示匹配0-9,a-z ,A-Z 的所有字符 |
| ^ | 如果不是在集合中,则必须在元素开头,表示匹配该符号后的那个元素开头的字符 |
| [^] | 在集合中,表示匹配除集合元素外的所有字符 |
| $ | 放在最后,表示匹配以其前一个字符结尾的字符串 |
正则表达式特殊字符
| 字符 | 含义 |
|---|---|
| \d | 表示匹配一个数字 |
| \d{5} | 表示匹配5个数字 |
| \w | 表示匹配一个字符:匹配a-z,A-Z,0-9,_(4部分) |
| \w{3} | 表示匹配3个字符 |
| \s | 表示匹配空格 |
| \D,\W,\S | 均表示匹配其小写字符含义的相反字符 |
| \D | 例如,该特殊字符表示匹配非数字的字符 |
知道了上面的一些信息,下面我们在python中进行实践练习。
注意:以上所有字符,基本上都可以组合使用,来匹配一些复杂的字符
在python应用正则表达式,我们需要导入re模块,来使用正则表达式
实践一:替换一串字符中的非法字符
在进行创建文件时,文件的名字不能出现以下字符【’\ /😗?",<>|’】,因此当我们从网上爬取到文章保存为文献时,就需要将这些非法字符替换掉,否则创建文件就会发生异常。
我们首先来看一下代码,依据代码进行分析讲解
import re
title = 'fgadfadsga;afd/adf\afds|ad||afd"dfad:asdf*?afd<fdsaf>fdsa,fa"'
# 过滤不合法的字符\ /:*?",<>|
def filter_illegal_character(title):
title = title.replace('"', '')
chararter = re.compile(r'[\/:*?,;<>|]', re.I)
chararter = chararter.findall(title)
for ch in chararter:
title = title.replace(ch, '-')
return title
title = filter_illegal_character(title)
print(title)
首先,代码的第一行导入了正则表达式re模块
接着第二行,是准备的一个字符串,将该字符串中的非法字符过滤掉
紧接着下面3-9行,就是过滤非法字符的函数
然后就是调用上面的函数,并用`title`来接收处理过的字符串返回值
最后一行就是打印该处理后的字符串
在进行处理非法字符时,我们可以自己规定想要将非法字符替换为何种合法字符,我这里是将引号替换为空,其余非法字符用‘-’代替。
观察初始时的title字符串,我们发现里面存在非法字符,下面我们通过正则表达式对非法字符进行替换。
正则表达式分析
由于一个"可以直接进行取代,所以不需要进行正则表达式编写了,我们看下其余的非法字符。
除了"外,其余的非法字符还有\ /:*?,<>|这几个,如果我们想把这几个字符替换掉,我们可以思考一下。对于正则表达式的集合[],他的含义为[]匹配集合内的任意一个元素,而非法字符只要出现在文件名中就不合法,因此我们可以很自然的写出正则表达式[\ /:*?,<>|],该正则表达式的含义就是匹配\ /:*?,<>|中的任意一个字符。
写完了正则表达式,我们看一下如何在python中使用。
要在python中使用,我们可以分为两步:
- 第一步就是编写处正则表达式,然后调用
re.compail函数来定义正则表达式 - 第二步就是依据第一步定义的规则去查找特定字符串,调用X.findall(title)
X表示第一步定义的正则表达式返回对象
之后就会将匹配到的字符返回为一个列表,上述代码执行匹配结果如下:
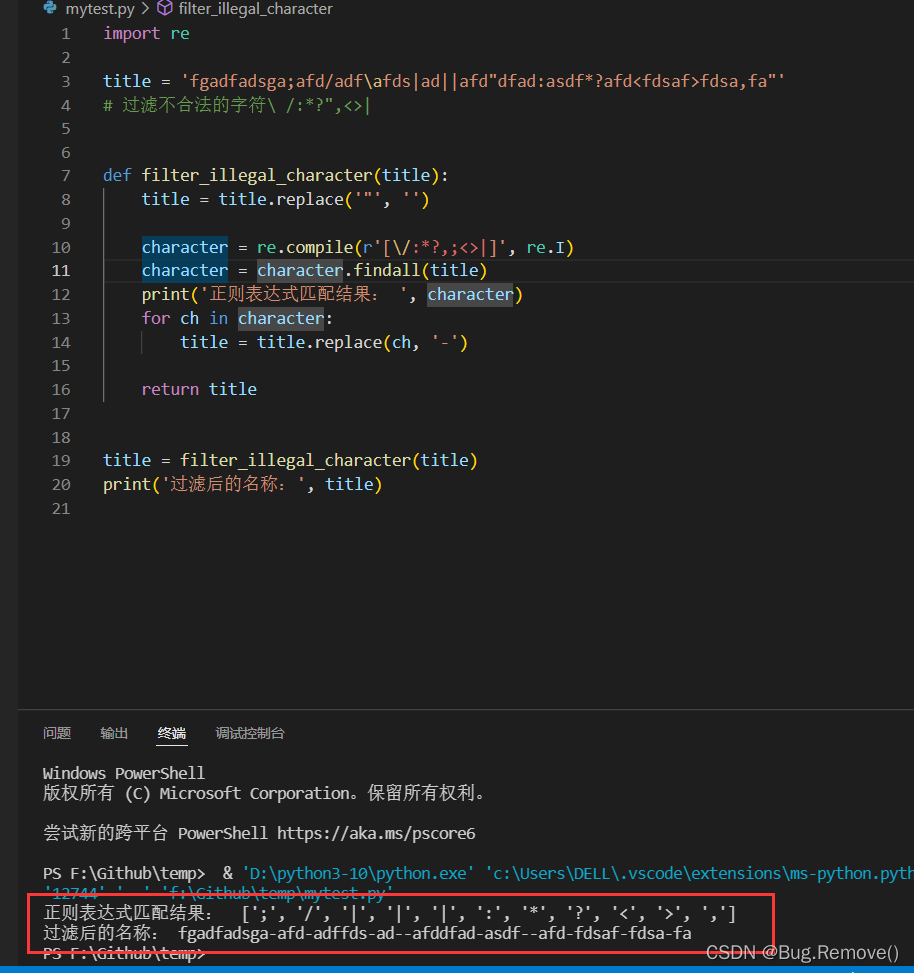
可见,如果正则表达式匹配成功会返回一个列表。
上面是一个非常简单的正则表达式用法,下面我们再看一个稍微复杂的正则表达式用法,该用法为从一串字符串中提取指定字符串
实践二:提取特定字符串
注:测试中准备的字符串为从pubmed上(一个论文下载网站)搜索的文献信息导出的csv文件中读取的一行,下面就将该行中的PMID,TITLE,YEAR,DOI分别提取出来
同样,我们先来看下代码
import re
def extracter_character(line):
line = line.replace('\n', '')
# 正则表达式匹配 PMID
PMID = re.compile('(\d{8}).*', re.I)
match_PMID = PMID.findall(line)
# 正则表达式匹配 TITLE
TITLE = re.compile('\d{8},(.*),\d{4},.*', re.I)
match_TITLE = TITLE.findall(line)
# 正则表达式匹配 YEAR
YEAR = re.compile('\d{8},.*,(\d{4}),{0,1}10\..*', re.I)
match_YEAR = YEAR.findall(line)
# 正则表达式匹配 DOI
DOI = re.compile('\d{8},.*,\d{4},(10\..*)', re.I)
match_DOI = DOI.findall(line)
print('PMID:', match_PMID)
print('TITLE:', match_TITLE)
print('YEAR:', match_YEAR)
print('DOI:', match_DOI)
if __name__ == '__main__':
line = '34520356,Applications of Capacitive Micromachined Ultrasonic Transducers: A Comprehensive Review,2022,10.1109/TUFFC.2021.3112917\n'
extracter_character(line)
对于使用一个正则表达式来提取特定字符串,那么我们肯定要观察字符串的信息,定义匹配规则,才能较好的匹配字符串。因为这里只列出了一个字符串进行测试,故看不出来什么规则,下面我把导出的csv文件截图一部分,一起观察一下规则:
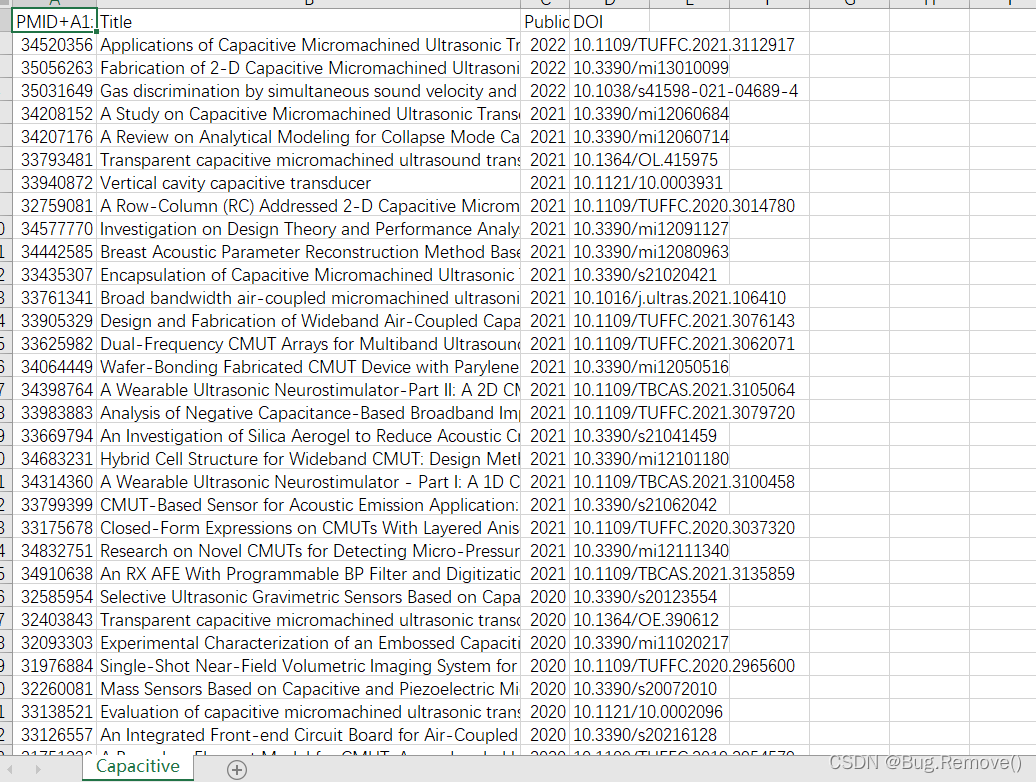 对比这些文献信息,我们应该就很容易看出一些规则:
对比这些文献信息,我们应该就很容易看出一些规则:
-
对于提取PMID
我们发现这里的PMID都是8位数字,然后其后面跟着的都是一些其他字符。
注意:这里有两个重要信息,一是前面几个都是数字,二是数字有八位。由于\d表示匹配一位数字,故\d{8}就表示匹配8位数字。由于前面的8位提取完成了,而后面还有标题,年份,DOI等信息,对于这些信息,我们此时不是太关心,故可以通过.来进行匹配。.表示任意字符(除换行符),而表示其前一个字符出现0次或多次。因此,可以将该字符匹配完全。 -
对于提取TITLE
提取TITLE稍微复杂点,首先,对于csv文件我们应该明确一点,csv各列是通过逗号(,)来分隔的 ,这里显示时隐藏了,故我们考虑匹配规则时需要把这个逗号(,)考虑进去。
我们观察提取TITLE,有这样几个信息:TITLE紧跟在PMID后面,并且TITLE的尾部紧跟的是年份,年份也是数字,并且是4位,故我们可以先这样写 \d{8}.*\d{4}.*,这样能表示匹配前面8位数字,中间任意字符,后面再跟4位数字,然后又是0次或多次的任意字符。然而这样还有点问题,就比如字符串:34520356,Applications of Capacitive Micromachined Ultrasonic Transducers: A Comprehensive Review,2022,10.1109/TUFFC.2021.3112917,此时中间的.*匹配出来的结果为(,Applications of Capacitive Micromachined Ultrasonic Transducers: A Comprehensive Review,2022,10.1109/TUFFC.2021.311),因为\d{4}.*意思为只要最后四位是数字就行了,此时即.*匹配了零个字符,因此我们需要调整一下,\d{8},.*\d{4},10.*这样便可匹配成功。注意每列是以逗号(,)隔开,因此匹配时别忘了加上逗号(,)。
- 对于提取YEAR
上面写完了,其实YEAR就写好了,就是上面的\d{4}, - 对于提取DOI
同样DOI也写完了,就是最后的10.*。不过在这里我们需要注意一下,由于DOI里有.这个字符,而.又是正则表达式的元字符,故我们需要转义为如下形式
10\..*
上面对于提取的各特定字符,多少有点小问题,不过基本上就是这样。下面我们可以直接看代码里的匹配了。对于代码中正则表达式:
匹配PMID时,如下
PMID = re.compile('(\d{8}).*', re.I)
match_PMID = PMID.findall(line)
我们可见,在\d{8}上,加了括号把该匹配的字符括了起来,加括号的意思就是我们在返回匹配的字符串时,只返回括号内匹配的字符串。而\d{8}就表示匹配的PMID,故提取PMID就需要把该部分括起来。后面同理,需要把以下几部分括起来:
匹配TITLE
TITLE = re.compile('\d{8},(.*),\d{4},.*', re.I)
match_TITLE = TITLE.findall(line)
匹配YEAR
YEAR = re.compile('\d{8},.*,(\d{4}),{0,1}10\..*', re.I)
match_YEAR = YEAR.findall(line)
匹配DOI
DOI = re.compile('\d{8},.*,\d{4},(10\..*)', re.I)
match_DOI = DOI.findall(line)
或许我们都发现了最后还有个参数re.I,这个参数可以先不管,这里无用,re.I意思为忽略字符的大小写,放这里只是让大家知道有这个参数。
下面我们看下匹配结果
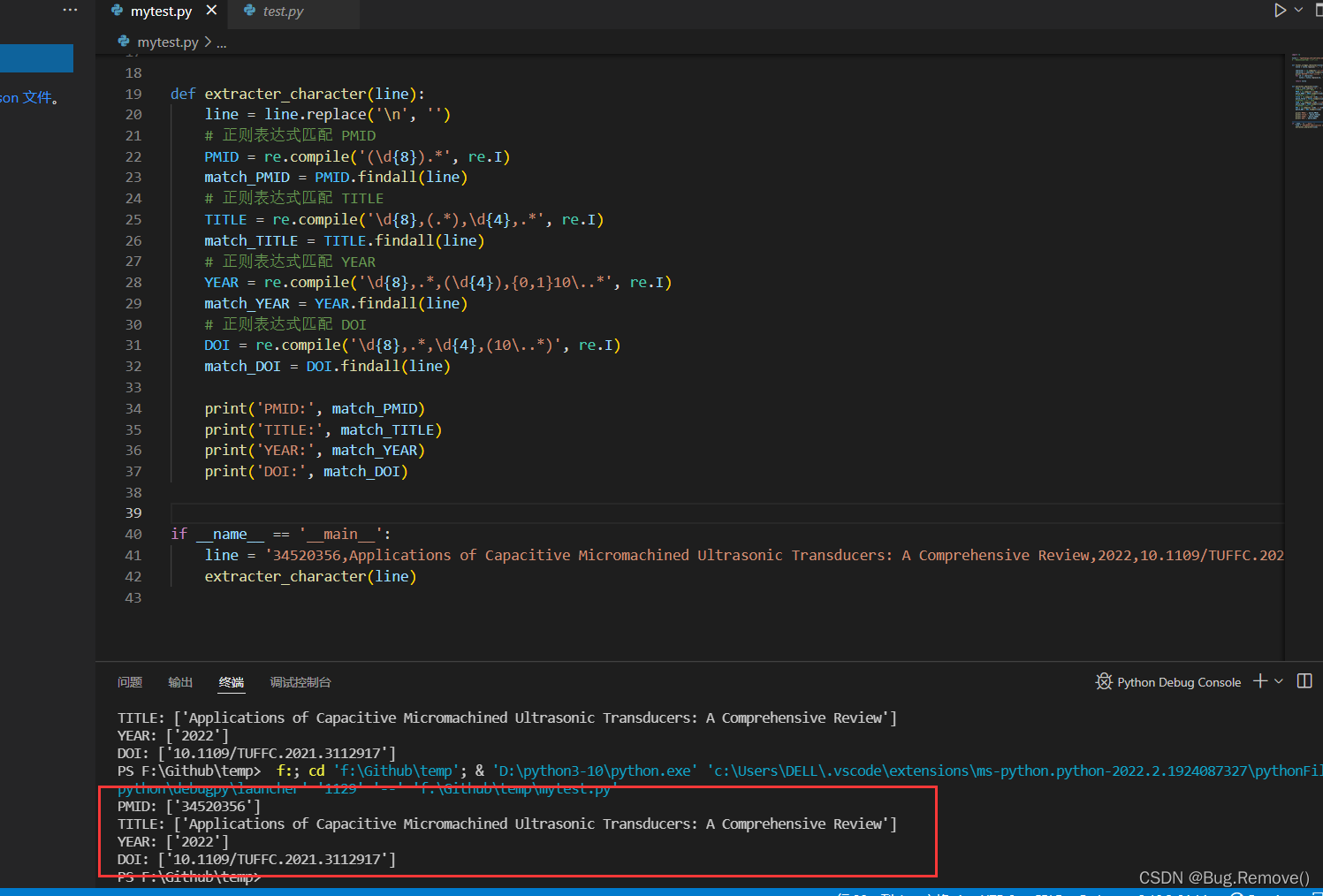
好啦,正则表达式就先写到这里,文章写的有些仓促,后面再继续完善,如果伙伴们决定有帮助,请三连支持呀~~~















 9743
9743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











