







目标网站
https://match.yuanrenxue.com/match/9
既然题目写明了是动态cookie,那我们直接用fiddler抓一下包看看
要注意一点,抓包前清除一下cookie
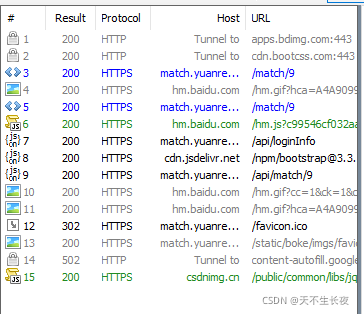
不出所料,两次请求,我们看看返回的什么

重返回数据中我们可以得到一下信息:
- cookie中设置了sessionid
- 有一大片js被混淆
- 首先加载了这个地址中的js (/static/match/safety/match9/udc.js),然后加载了后边一大片的js,
划到最后,又重新刷新了网页 location.reload()

在第二次请求中就看到了已经生成好的cookie了,那么就可以肯定,在第一次请求中设置了cookie
那就直接看第一次请求返回的js,复制到本地文本编辑器
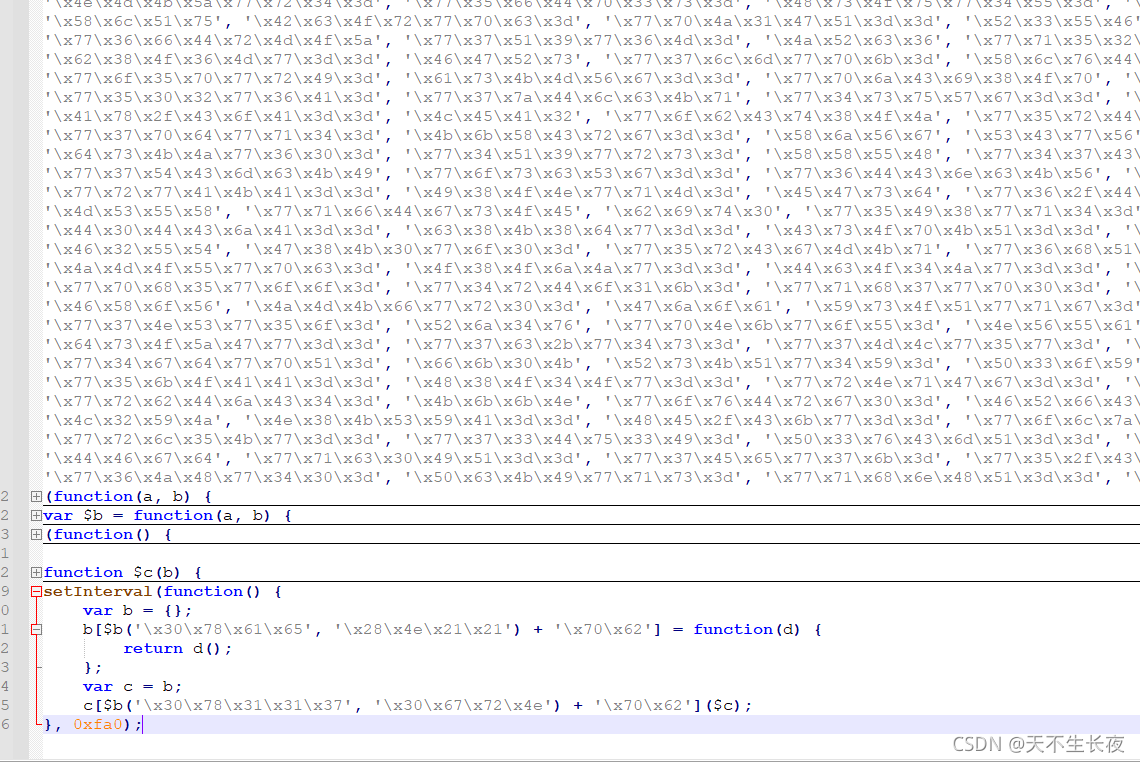
本来想用猿人学里的解混淆工具解一下,但是好像没用,所以就被迫学习了AST
这里先看一下反混淆后的结果吧
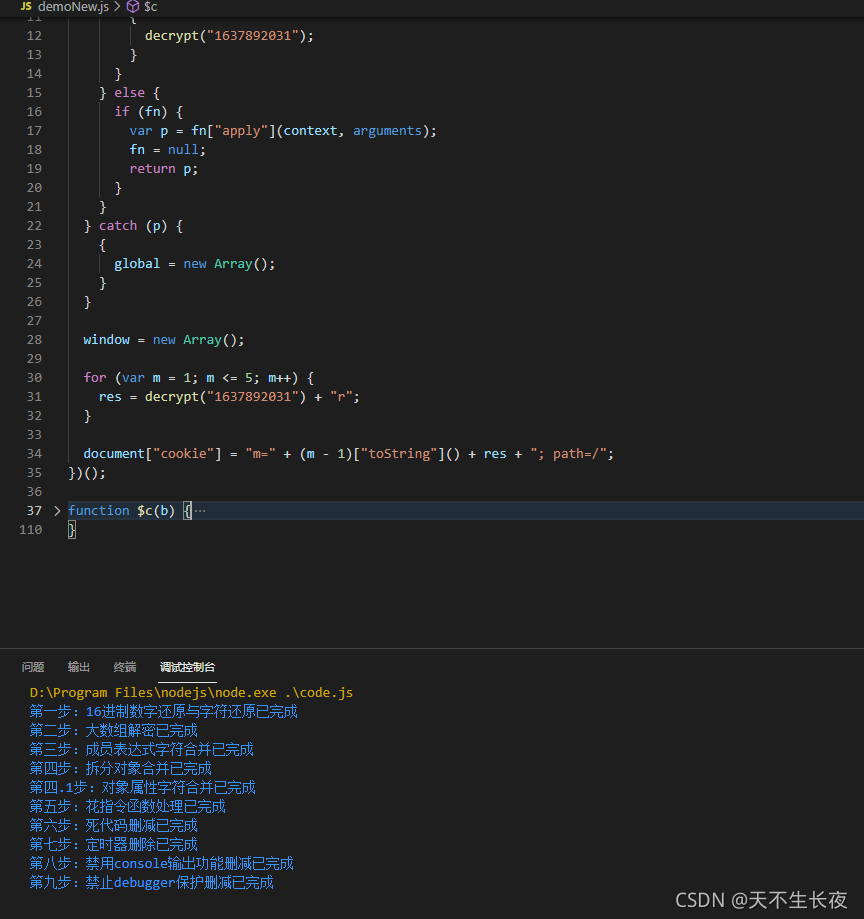
最开始的700多行混淆js,经过处理之后剩下100多行(其实有用的就几行),从上图一眼就可以看出来
是哪几行
for (var m = 1; m <= 5; m++) {
res = decrypt("1637892031") + "r";
}
document["cookie"] = "m=" + (m - 1)["toString"]() + res + "; path=/";
那么现在的问题就是这个 decrypt 是哪里来的,解决这个就算完成了
回想之前第一次请求返回混淆代码那里,还请求过一个js文件
‘/static/match/safety/match9/udc.js’ 看看它返回的什么
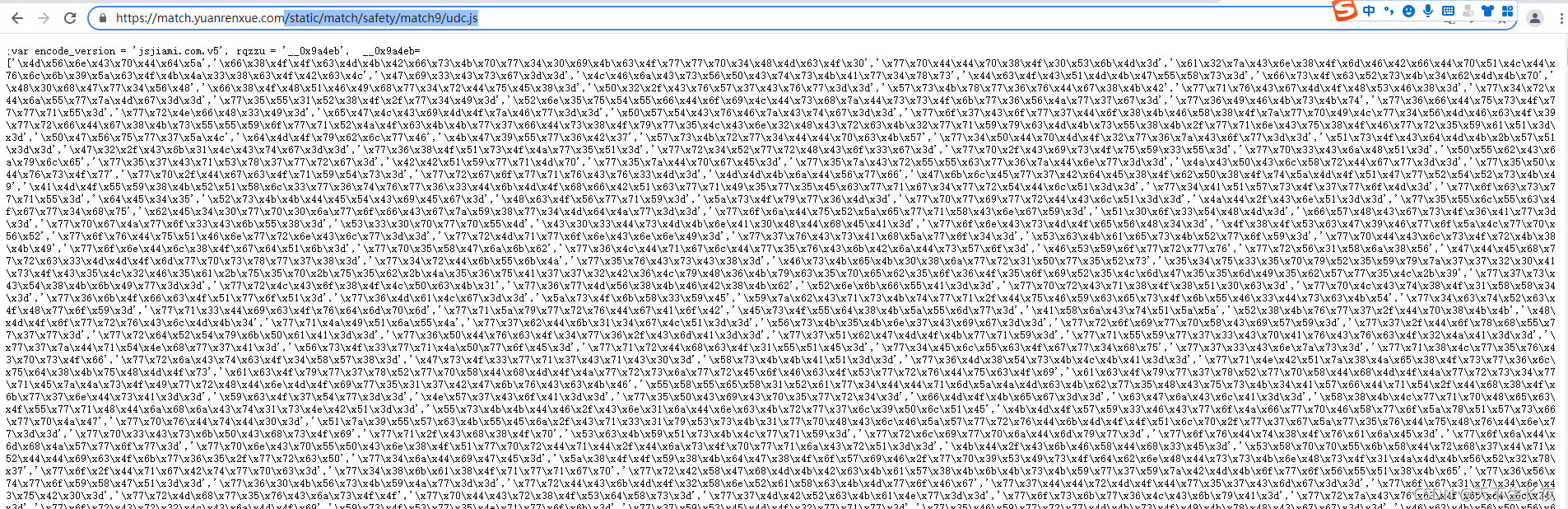
可以看到返回的还是混淆的代码,还是反混淆一下
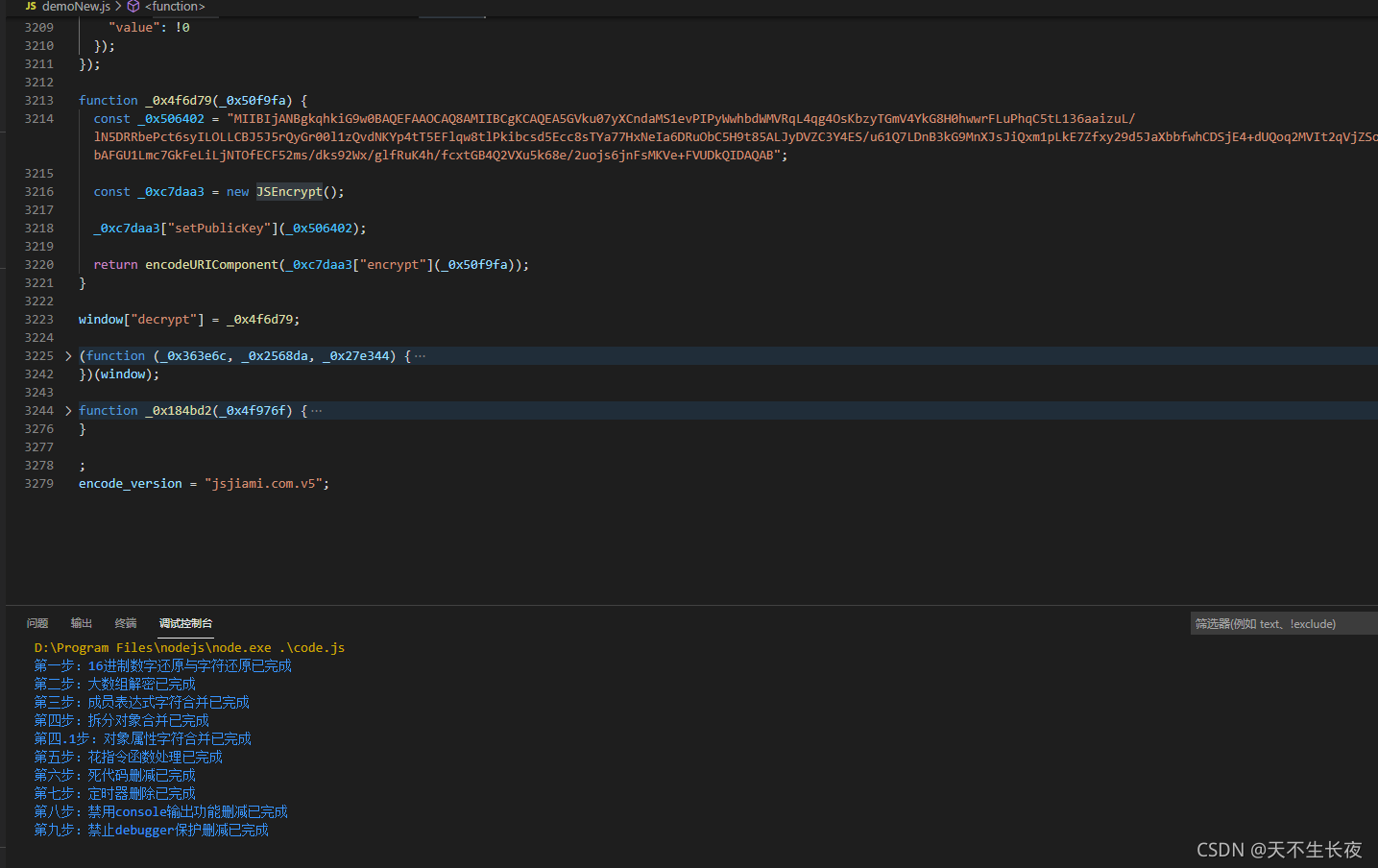
原来9000多行代码,反混淆后3000多行,差不多就是rsa的行数了
其实已经可以看到decrypt
我们在网页中执行一下看看
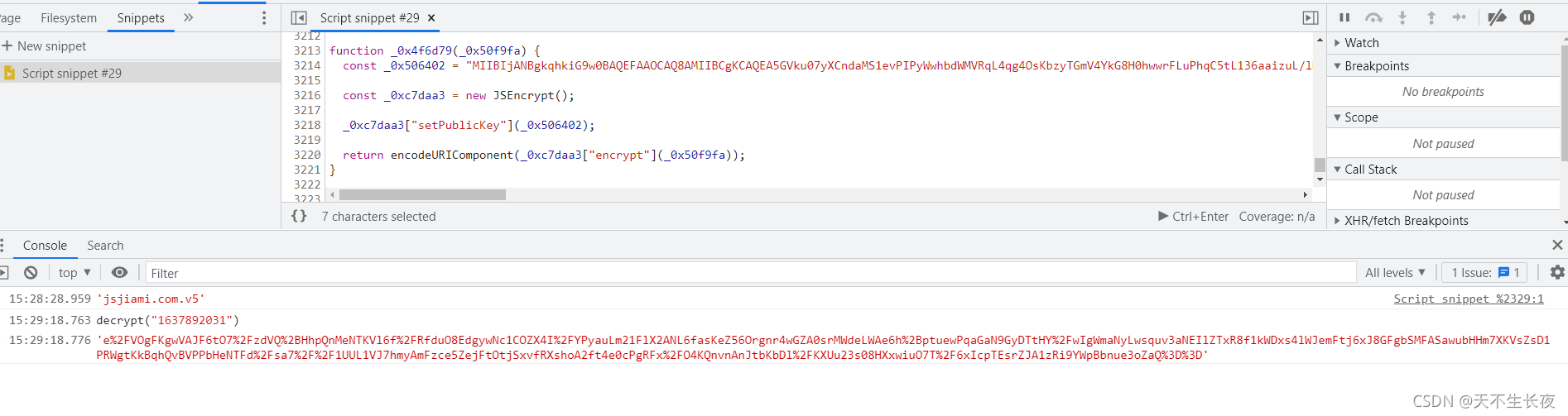
OK,然后模拟一下网页的请求顺序,用代码实现一下就好了。
最后还想说一下这个反混淆的问题
之前对混淆也是陌生的,后边在js逆向的过程中也遇到表较多的网站都有混淆
所以也就学习了一下,猿人学第九题也算是我第一个学习反混淆的成果了,感觉还不错
后边也会做AST的学习方法,分享一下学习心得

















 6221
6221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









