







文章目录
一.简介
逻辑回归(也称为罗吉思回归)被广泛用于估算一个实例属于某个特定类别的概率。它的工作原理和线性回归一样,逻辑回归模型也是计算输入特征的加权和(加上偏置项)但是不同于线性回归模型直接输出结果,它输出的是结果的数理逻辑,逻辑回归主要是解决的二分类问题。
二.逻辑函数公式
2.1 概率估算公式
p ^ = h θ ( X ) = σ ( θ T ⋅ X ) \hat p=h_{\theta}(X)=\sigma(\theta^T \cdot X) p^=hθ(X)=σ(θT⋅X)
这个概率计算的是一个实例属于正类的概率,在后面分类时以这个概率为依据,若概率大于0.5就判定为正类,否则就是负类。
2.2 逻辑函数
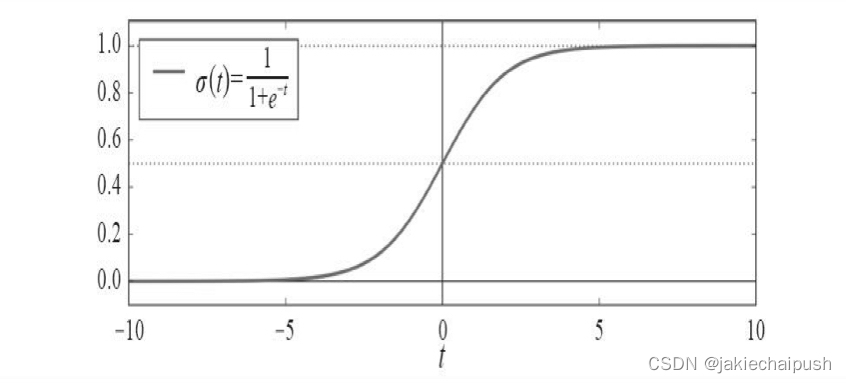
逻辑模型是一个sigmod函数,记做 σ \sigma σ,它的输出为一个0到1之间的数字。
σ ( t ) = 1 1 + e x p ( − t ) \sigma(t)=\frac 1 {1+exp(-t)} σ(t)=1+exp(−t)1
逻辑函数的函数图像如下:
2.3 逻辑回归模型预测函数
一旦逻辑回归通过概率估算公式计算出实例X属于正类的概率 p ^ = h θ ( x ) \hat p=h_\theta(x) p^=hθ(x)就能可以轻松做出预测 y ^ \hat y y^。当t<0时,由逻辑函数我们可以知道 σ ( t ) < 0.5 \sigma(t)<0.5 σ(t)<0.5;当 t ≥ 0 t\geq 0 t≥0时, σ ( t ) ≥ 0.5 \sigma(t)\geq 0.5 σ(t)≥0.5,所以如果 θ T X \theta^TX θTX是正类,逻辑回归模型预测结果就是1,如果是负类,则预测为0,逻辑回归预测函数如下
y ^ = { 0 ( p ^ < 0.5 ) 1 ( p ^ ≥ 0.5 ) \hat y=\begin{cases} 0 (\hat p <0.5)\\ 1(\hat p \geq 0.5) \\ \end{cases} y^={0(p^<0.5)1(p^≥0.5)
三 .训练和成本函数
3.1 简介
通过上面我们知道了逻辑回归模型是如何估算概率并做出预测的了,现在我们要把问题聚焦到如何去对模型去进行训练,训练的本质就是设置参数向量 θ \theta θ,使模型对正类实例做出高概率估算(y=1),对负类实例做出低概率估算(y=0),也就是求参数,使得模型的分类误差达到最小。
3.2 单个训练实例的成本
c ( θ ) = { − l o g ( p ^ ) ( y = 1 ) − l o g ( 1 − p ^ ) ( y = 0 ) c(\theta)=\begin{cases} -log(\hat p) (y=1)\\ -log(1-\hat p) (y=0) \\ \end{cases} c(θ)={−log(p^)(y=1)−log(1−p^)(y=0)
分析一下这个成本函数,假设样本本身是一个正例样本,但经过预测函数预测预测其为正例的函数概率很小(p<0.5判断为负类),这样根据 − l o g -log −log函数图像可以知道函数值会很大,这就导致误差很大。同理如果一个实例本身为负例,如果预测其为正例的概率却很大,则同意会误差很大。(这里要结合逻辑回归模型预测函数来进行工作的原理)
3.3 逻辑回归的成本函数
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( p ( i ) ) + ( 1 − y ( i ) ) l o g ( 1 − p ( i ) ) ] J(\theta)=-\frac 1 m \sum_{i=1}^m [ y^{(i)}log(p^{(i)})+(1-y^{(i)})log(1-p^{(i)})] J(θ)=−m1i=1∑m[y(i)log(p(i))+(1−y(i))log(1−p(i))]
前面介绍的损失函数是单个实例的损失函数,而整个训练集的成本函数即为所有训练实例的平均成本。可以看出一个实例如果是正例(真实值),就会算中括号的前一部分,相反就会算后一部分。
3.4 逻辑回归成本函数的偏导数
∂ J ( θ ) ∂ θ j = 1 m ∑ i = 1 m ( σ ( θ T ⋅ x ( i ) − y ( i ) ) x j ( i ) \frac {\partial{J(\theta)}} {\partial \theta_j}= \frac 1 m \sum_{i=1}^m(\sigma(\theta ^T \cdot x^{(i)}-y^{(i)})x_j^{(i)} ∂θj∂J(θ)=m1i=1∑m(σ(θT⋅x(i)−y(i))xj(i)
计算出每个实例的预测误差,并将其乘以第j个特征值,然后再对所有训练实例求平均值。有了成本函数的偏导数以后我们就可以使用梯度下降来求使预测函数误差最小的参数向量了
四 .鸢尾花案例分析
4.1 鸢尾花数据导入
from sklearn.datasets import load_iris
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
iris=load_iris()
iris=pd.DataFrame(data=iris.data,columns=iris.feature_names)
iris2["target"]=iris["target"]
结果:
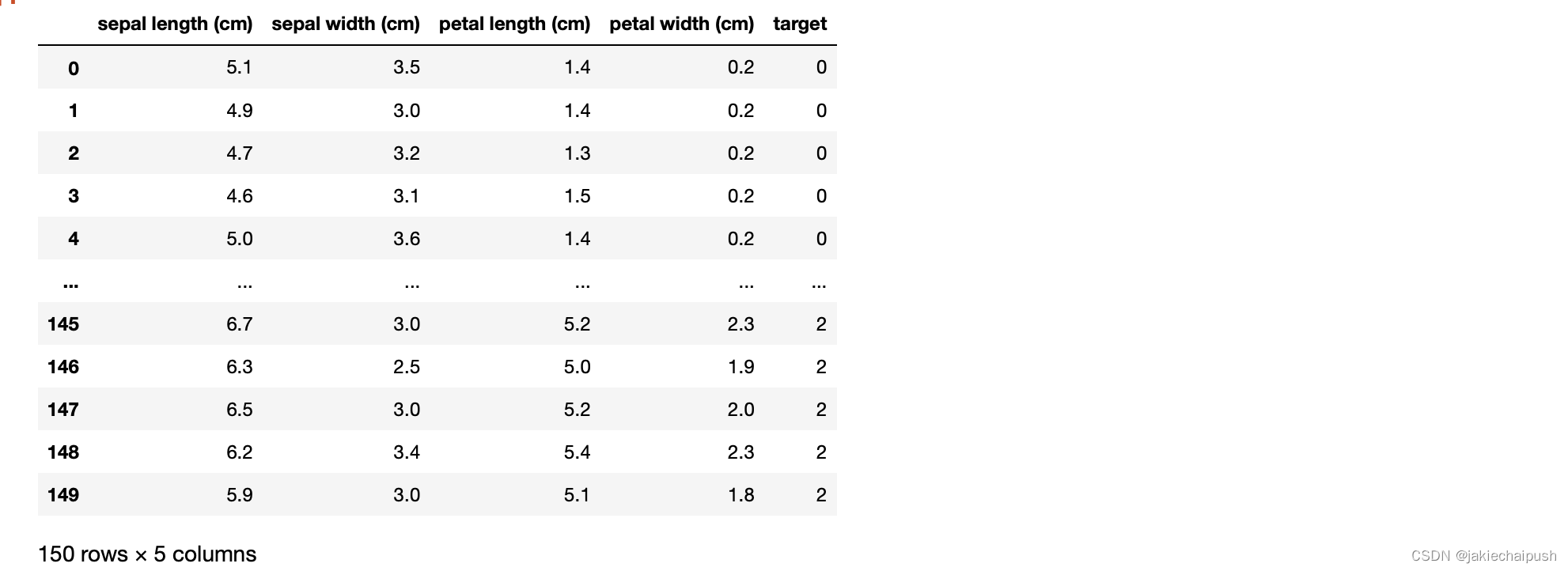
结果分析:
鸢尾花数据集是一个非常著名的数据集,数据的特征分别为花萼的长度和宽度以及花瓣的长度和宽度
4.2 模型训练
from sklearn.linear_model import LogisticRegression
log_reg=LogisticRegression()
log_reg.fit(iris.data[:,3:],(iris.target==2).astype(np.int)) #将taiget转换为只有0或1
X_new=np.linspace(0,3,1000).reshape(-1,1) #在0-3内生成1000个数字(以等差数列的形式)
y_proba=log_reg.predict_proba(X_new)#predict_proba返回返回的是一个n行k列的数组,第i行 第j列上的数值是模型预测第i个预测样本为某个标签的概率,并且每一行的概率和为1。
plt.plot(X_new,y_proba[:,1],"g-",label="Iris-Virginica")
plt.plot(X_new,y_proba[:,0],"b--",label="Not—Iris-virginica")
运行结果:
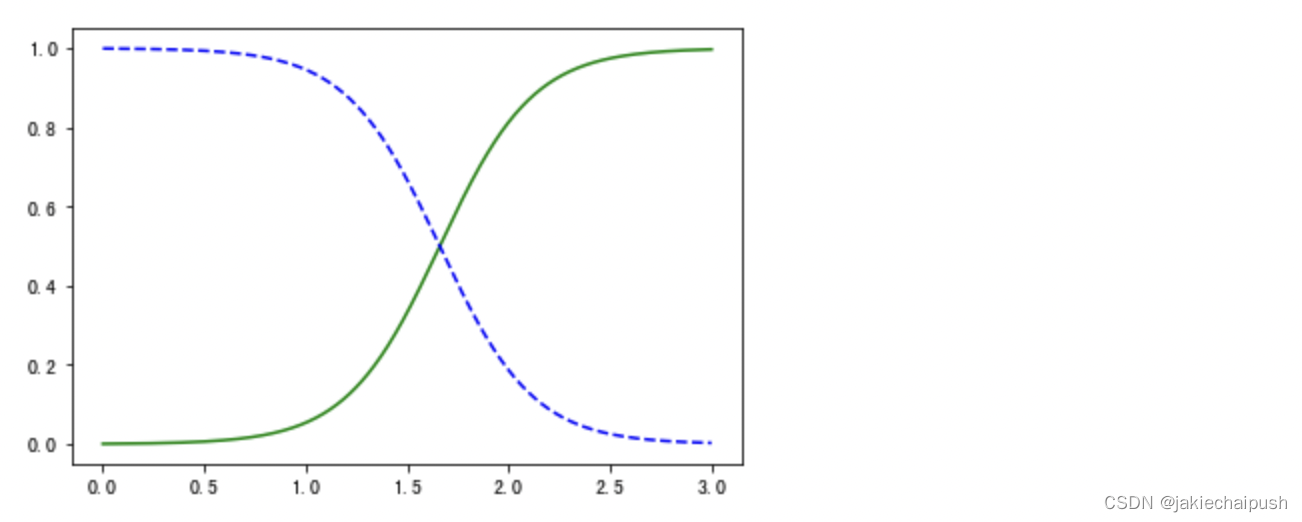
结果分析:
图片中的横轴为鸢尾花花瓣的宽度,纵轴为概率,蓝色的是不是鸢尾花的概率,绿色的表示是鸢尾花的概率。我们会发现两条线有个交点(大概在花瓣宽度1.7左右),这时是鸢尾花和不是鸢尾花的概率都是0.5,我们管1.7花瓣宽度为决策边界
五 .总结
和其它线性模型一样,逻辑回归模型可以使用L1或L2惩罚函数来正则化,默认使用的是L2正则化。















 1162
1162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









