







1. Redis底层hash编码格式
在redis6中hash的编码格式分别是ziplist(压缩列表)和hashtable,但在redis7中hash的编码格式变为了listpack(紧凑列表)和hashtable。
2. Redis 6源码分析
首先我们看一下redis6的默认配置
config get hash*

hash-max-ziplist-entries:使用压缩列表保存时哈希集合中最大元素个数
hash-max-ziplist-value:使用压缩列表保存时哈希集合中单个元素的最大长度
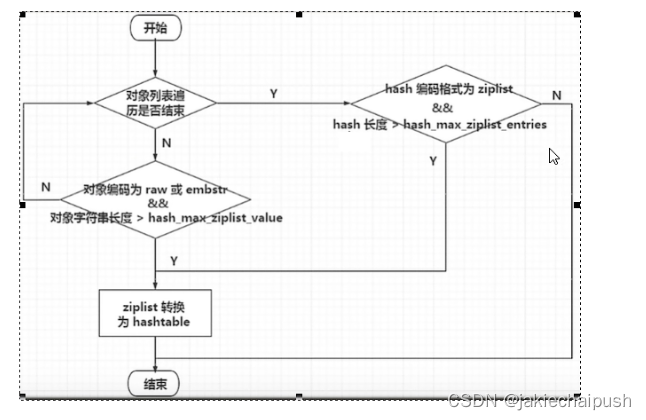
如果hash类型键的字段个数小于hash-max-ziplist-entries并且每个字段名和字段值的长度小于hash-max-ziplist-value,redis才会使用OBJ_ENCODING_ZIPLIST来存储该键,前面条件任意一个不满足的时候则会转化为OBJ_ENCODING_HT。

我们修改一下配置:
config set hash-max-ziplist-entries 3
config set hash-max-ziplist-value 8



从上面的案例我们可以看出上面两个配置的作用。下面我们看另一种情况:

我们可以看见不管我们怎么操作,只要有一个时间点不满足前面配置,底层编码都会转化
所以,在redis6中哈希对象报错的键值对个数要小于512,所有的键值对的键和值的字符串长度都小于64个字节时用ziplist否则用hashtable。
注意:ziplist可以升级为hashtable,但hashtable不能降级为ziplist,在节省内存空间方面哈希表是没有压缩列表高效的!
我们可以把上面的流程总结如下
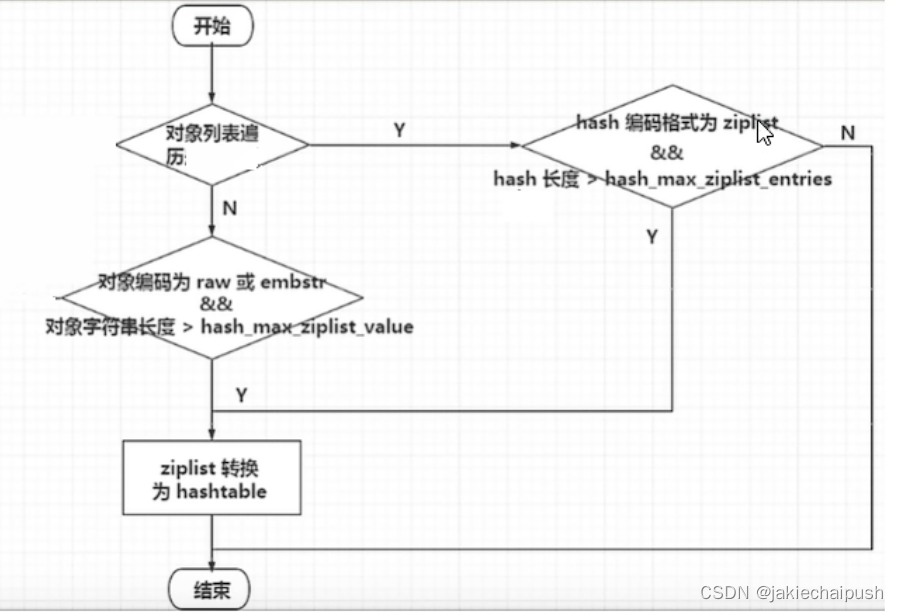
首先进入t_hash.c。首先在redis中,hashtable被称为字典,它是一个数组加链表的结构。OBJ_ENCODING_HT这种编码格式才是真正的hash表,或称为字典结构,其实现O(1)复杂度的读写操作,因此效率很高,再redis内部,从OBJ_ENCODING_HT类型到底层真正的散列表数据结构是一层一层嵌套下去的。

我们看dict.h
struct dict { //hash条目
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {//类型
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
int (*expandAllowed)(size_t moreMem, double usedRatio);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {//hash表
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict { //字典
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
int16_t pauserehash; /* If >0 rehashing is paused (<0 indicates coding error) */
} dict;
总的来说,每一个键值对都会对应一个dictEntry
下面解读一下hset这个命令,进入t_hash.c
void hsetCommand(client *c) {
int i, created = 0;
robj *o;
if ((c->argc % 2) == 1) {
addReplyErrorFormat(c,"wrong number of arguments for '%s' command",c->cmd->name);
return;
}
if ((o = hashTypeLookupWriteOrCreate(c,c->argv[1])) == NULL) return;
hashTypeTryConversion(o,c->argv,2,c->argc-1);
for (i = 2; i < c->argc; i += 2)
created += !hashTypeSet(o,c->argv[i]->ptr,c->argv[i+1]->ptr,HASH_SET_COPY);
/* HMSET (deprecated) and HSET return value is different. */
char *cmdname = c->argv[0]->ptr;
if (cmdname[1] == 's' || cmdname[1] == 'S') {
/* HSET */
addReplyLongLong(c, created);
} else {
/* HMSET */
addReply(c, shared.ok);
}
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_HASH,"hset",c->argv[1],c->db->id);
server.dirty += (c->argc - 2)/2;
}
hashTypeTryConversion这个函数就进行了编码类型的判断和转化
/* Check the length of a number of objects to see if we need to convert a
* ziplist to a real hash. Note that we only check string encoded objects
* as their string length can be queried in constant time. */
void hashTypeTryConversion(robj *o, robj **argv, int start, int end) {
int i;
size_t sum = 0;
if (o->encoding != OBJ_ENCODING_ZIPLIST) return;
for (i = start; i <= end; i++) {
if (!sdsEncodedObject(argv[i]))
continue;
size_t len = sdslen(argv[i]->ptr);
//如果长度大于hash_max_ziplist_value,则直接转化为hash表
if (len > server.hash_max_ziplist_value) {
hashTypeConvert(o, OBJ_ENCODING_HT);
return;
}
sum += len;
}
if (!ziplistSafeToAdd(o->ptr, sum))
hashTypeConvert(o, OBJ_ENCODING_HT);
}
上面就分析了编码类判断的底层源码,下面分析重点ziplist,我们进入ziplist.c。
ziplist压缩列表是一种紧凑编码格式,总体思想是多花时间来换取节约空间,即以部分读写性能为代价来换取极高的内存空间利用率,因此只会用于字段个数少,且字段值小的场景。压缩列表里利用率极高的原因与其连续内存的特性是分不开的。
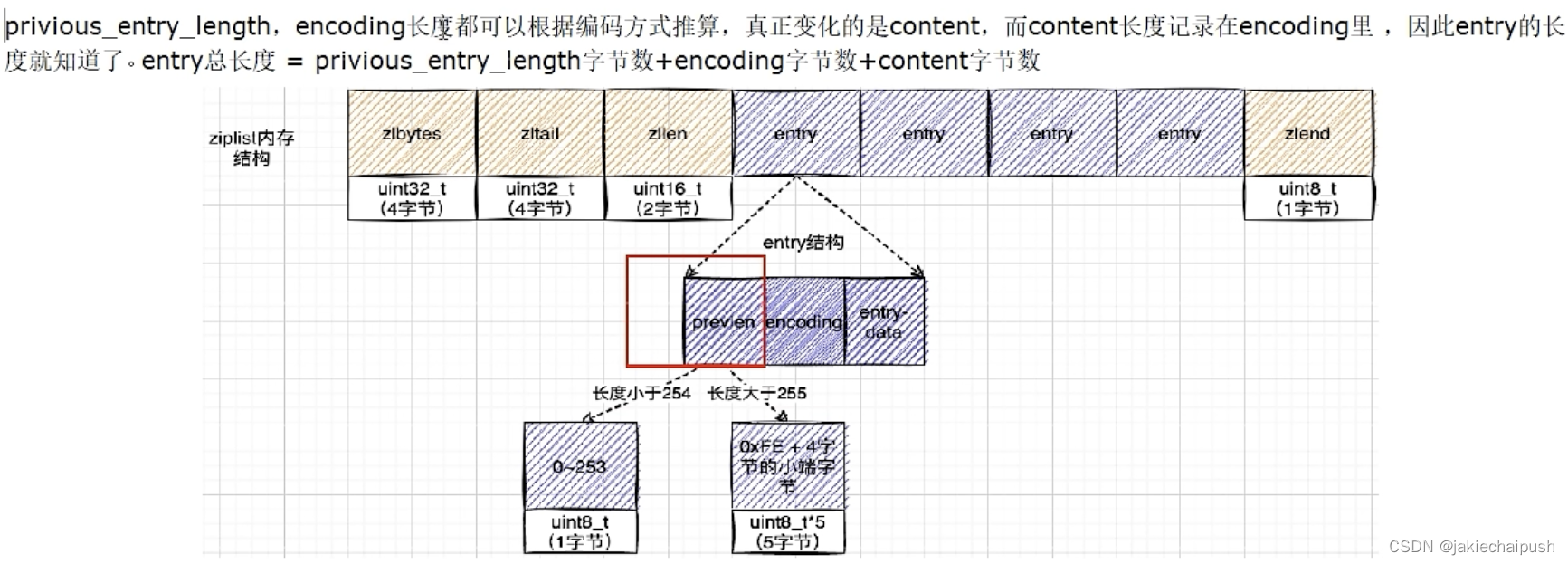
为了节约内存的开发,它是由连续内存块组成的顺序数据结构,有点类似于数组,ziplist是一个经过特殊编码的双向链表,它不存储指向前一个链表节点的prev和指向下一个链表节点的next而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能,来换取高效的内存空间利用率,节约内存是一种时间换空间的思想,只用在字段个数少,字段值小的场景里面。
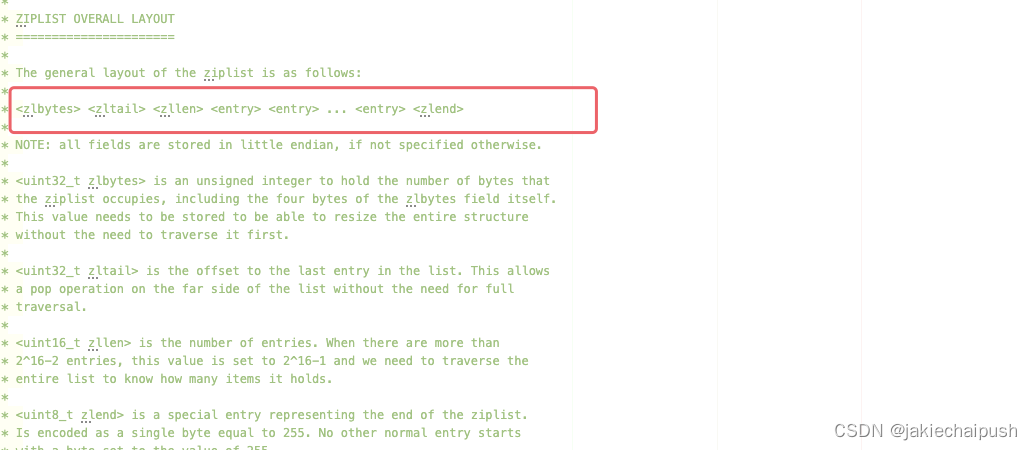
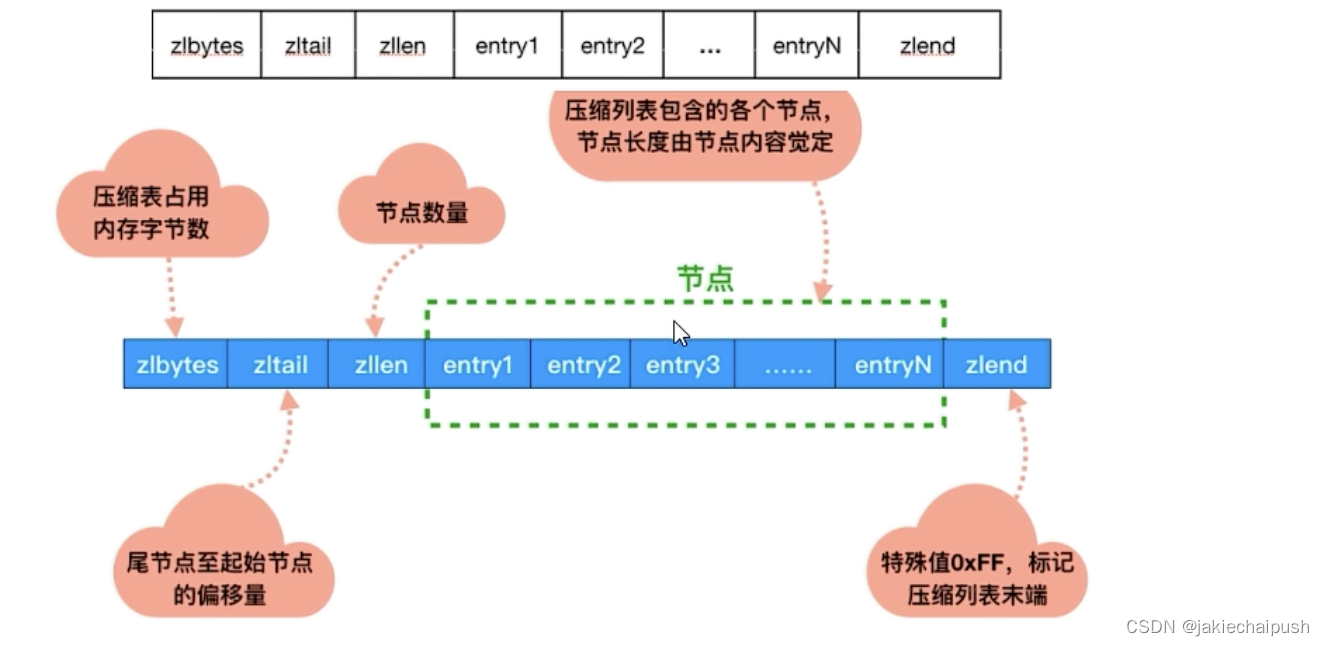

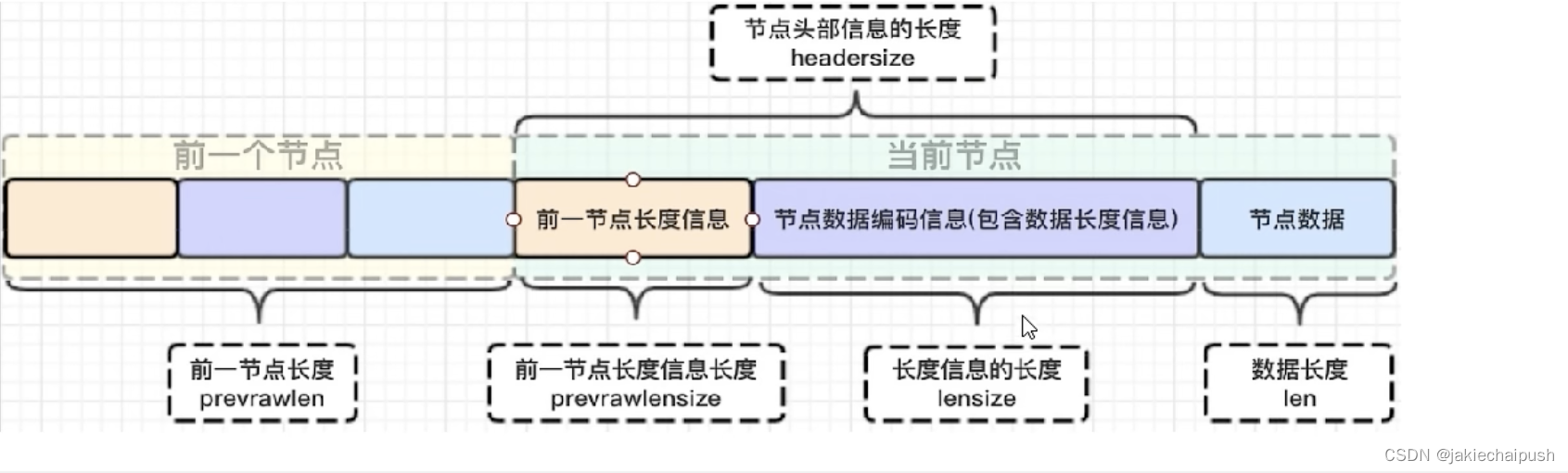
前面大致讲解了ziplist得大致结构,下面我们分析zlentry,即压缩列表的节点的构成:
typedef struct zlentry {
unsigned int prevrawlensize; /* Bytes used to encode the previous entry len*/
unsigned int prevrawlen; /* Previous entry len. */
unsigned int lensize; /* Bytes used to encode this entry type/len.
For example strings have a 1, 2 or 5 bytes
header. Integers always use a single byte.*/
unsigned int len; /* Bytes used to represent the actual entry.
For strings this is just the string length
while for integers it is 1, 2, 3, 4, 8 or
0 (for 4 bit immediate) depending on the
number range. */
unsigned int headersize; /* prevrawlensize + lensize. */
unsigned char encoding; /* Set to ZIP_STR_* or ZIP_INT_* depending on
the entry encoding. However for 4 bits
immediate integers this can assume a range
of values and must be range-checked. */
unsigned char *p; /* Pointer to the very start of the entry, that
is, this points to prev-entry-len field. */
} zlentry;
- prevrawlensize:上一个链表节点占用的长度所需要的字节数
- prevrawlen:存储上一个链表节点的长度值
- lensize:存储当前链表节点长度数值所需要的字节数
- len:当前链表节点占用的长度
- headersize:当前链表节点的头部大小(prevrawlensize+lensize),即非数据域的大小
- encoding:编码方式
- p:压缩链表以字符串的形式保存,该指针指向当前节点的起始位置
下面分析ziplist的存取情况,分析下面这条命令。
hset user01 name 1 age 2
上面这个底层的编码类型是ziplist,总共有两个kv对,分别为name-1和age-2,在ziplist存储时就会生成两个Entry
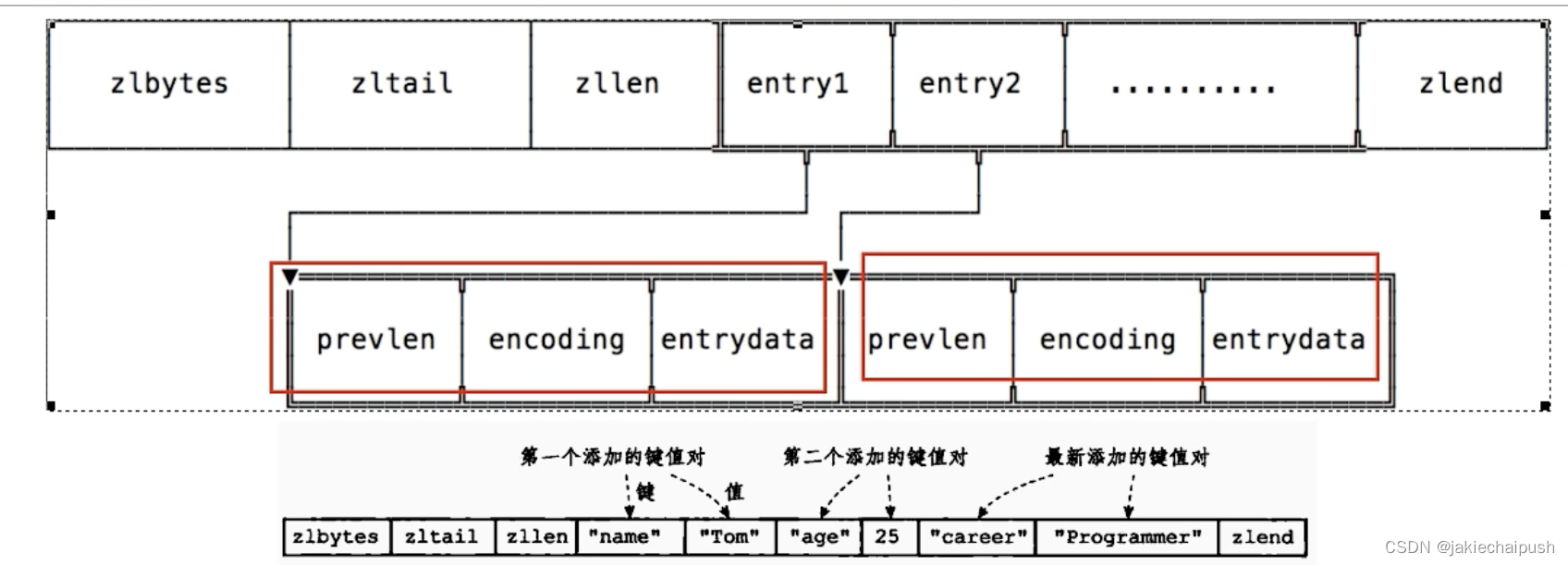

前节点:(前节点占用的内存字节数)表示前1个zlentry的长度,previous_entry_length有两种取值情况:1字节或5字节。取值1字节时,表示上一个entry节点的长度小于254字节,虽然1字节的值能表示0-255,但是压缩列表中zlend的取值默认为255,因此就默认用255表示整个压缩列表的结束,其他表示长度的地方就不能用255个值了,所以,当上一个entry长度小于254个字节的时候,prev_len取值就是1字节,否则就是5字节。记录长度的好处是:占用内存小,1或者5个字节。
encoding:记录节点的content保存数据的类型和长度
content:保存的实际数据内容
为什么记录前一个接待你的长度?
链表存储在内存中,一般是不连续的,遍历相对比较慢,而ziplist就可以解决这个问题,如果知道了当前的开始地址,因为entry是连续的,entry之后一定是另一个entry,想知道下一个entry的地址,只要将当前开始地址加上当前entry的长度即可,如果还想继续遍历,重复上面操作即可。
面试题:明明已经有链表了,为什么还要研究一个压缩链表:
- 普通的双向链表会有两个指针,在存储数据很小的情况下,我们存储的实际数据的大小可能还没有指针占用的内存大,得不偿失。ziplist是一个特殊的双向链表没有维护双向指针:previous next;而是存储上一个entry的长度和当前entry的长度,通过长度推算下一个元素在什么地方。牺牲读取的性能,获得高效的存储空间,因为(简短字符串的情况)存储指针比存储entry长度更费内存。这是典型的 “时间换空间”
- 链表在内存中一般是不连续的,遍历相对比较慢而ziplist可以很好的解决这个问题,普通数组的遍历是根据数组里存储的数据类型找到下一个元素的(例如int类型的数组访问下一个元素时每次只需要移动一个sizeof(int) 就行),但是ziplist的每个节点的长度是可以不一样的,而我们面对不同长度的节点又不可能直接sizeof(entry),所以ziplist只好将一些必要的偏移量信息记录在了每一个节点里,使之能跳到上一个节点或下一个节点。
备注:sizeof实际上是获取了数据在内存中所占用的存储空间,以字节为单位来计数。- 头节点里同时还有一个参数len,和string类型提到的SDS 类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到len值就可以了,这个时间复杂度是O(1)
- 总结
前面说到了ziplist为了节省内存空间,采用了紧凑的连续存储,ziplist是一个双向链表,可以在时间复杂度为O(1)下从头部,尾部进行POP或PUSH,但是它也有缺点,即新增元素可能会出现连锁更新现象(这也是它被listpack代替的原因),同时不能保存过多的元素,否则查询效率就会降低,数量小和内容小的情况下可以使用。
上面提到entry中的prevlen属性可能是1个字节也可能是5个字节,那么我们来设想这么一种场景:
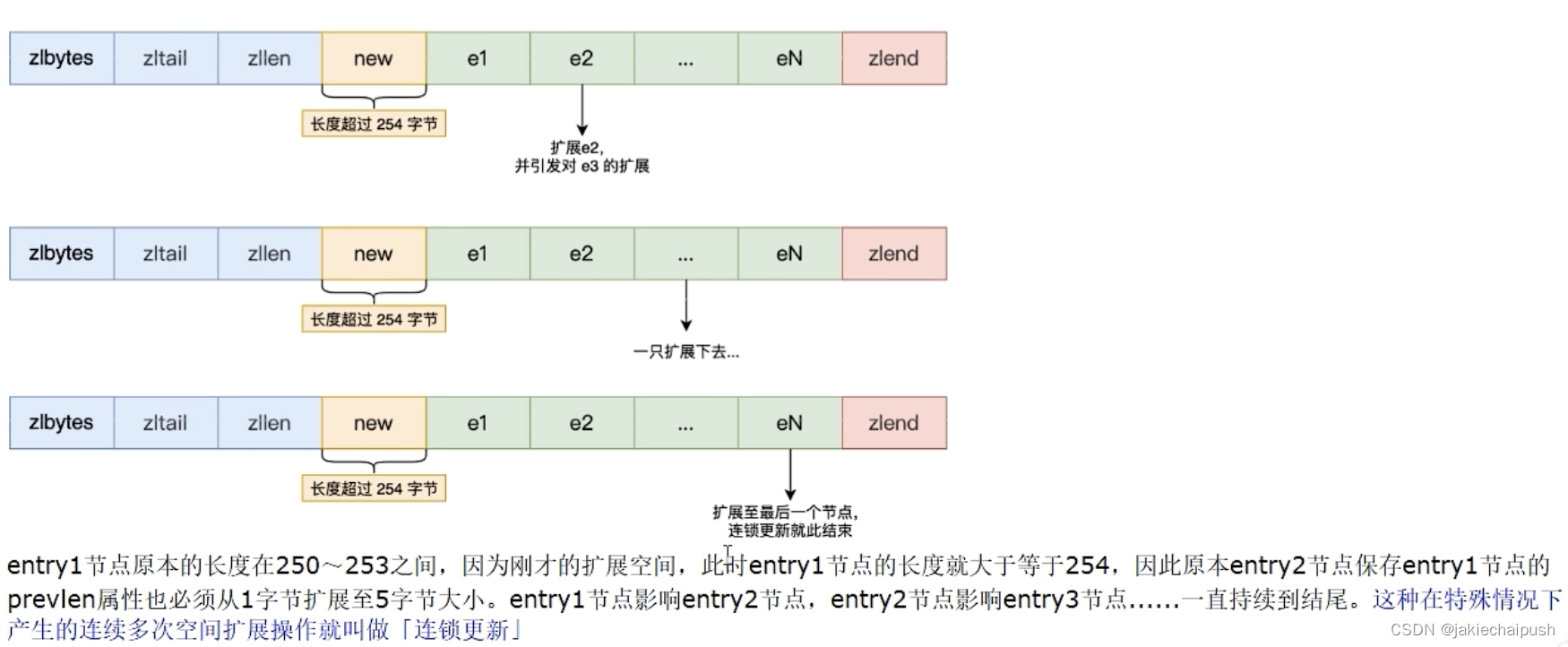
假设一个ziplist中,连续多个entry的长度都是一个接近但是又不到254的值(介于250~253之间),那么这时候ziplist中每个节点都只用了1个字节来存储上一个节点的长度,假如这时候添加了一个新节点,如entry1,其长度大于254个字节,此时entry1的下一个节点entry2的prelen属性就必须要由1个字节变为5个字节,也就是需要执行空间重分配,而此时entry2因为增加了4个字节,导致长度又大于254个字节了,那么它的下一个节点entry3的prelen属性也会被改变为5个字节。依此类推,这种产生连续多次空间重分配的现象就称之为连锁更新。同样的,不仅仅是新增节点,执行删除节点操作同样可能会发生连锁更新现象。虽然ziplist可能会出现这种连锁更新的场景,但是一般如果只是发生在少数几个节点之间,那么并不会严重影响性能,而且这种场景发生的概率也比较低,所以实际使用时不用过于担心。
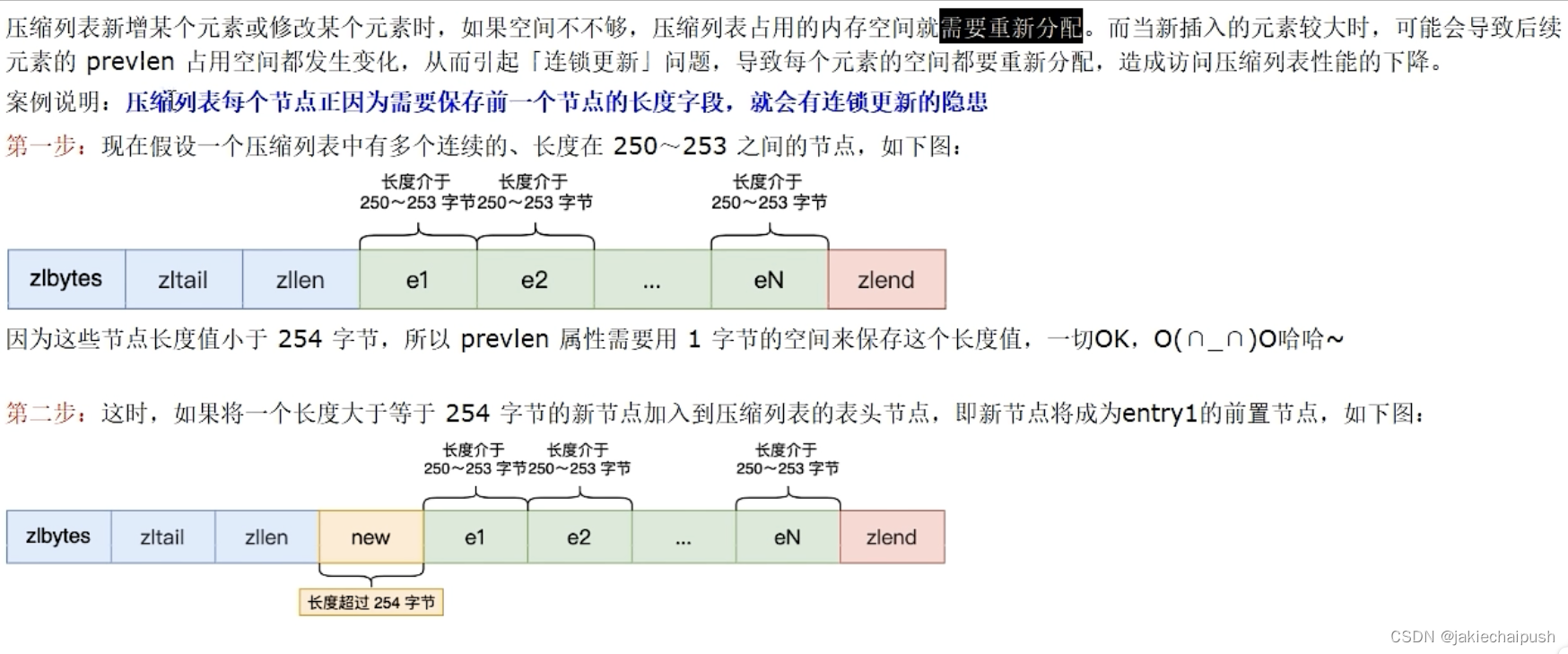
上图因为entry1节点的prevlen属性只有1个字节大小,无法保存新节点的长度,此时就需要对压缩列表的空间重分配操作并将entry1节点的prevlen属性从原理的1字节大小扩展到5字节大小。就出现了下面连锁更新现象:
3. Redis 7源码分析

hash-max-listpack-entries:使用压缩列表保存时hash集合中的最大元素个数
hash-max-listpack-value:使用压缩列表保存时hash集合中单个元素的最大长度
hash类型键的字段个数小于
hash-max-listpack-entries且每个字段名和字段值的长度小于hash-max-listpack-value时,Redis才会使用OBJ_ENCODING_LISTPACK来存储该键,前述条件任意一个不满足则会转化为OBJ_ENCODING_HT编码方式。
redis 7为了兼容和过度依旧保留了ziplist的使用,但是实际上真正起作用的是listpack。现在我们将上面两个有关listpack的配置修改一下。
config set hash-max-listpack-entries 3
config set hash-max-listpack-value 5

下面我们测试一下:

流程和ziplist一样,只是底层的数据结构从ziplist换成了listpack
下面我们开始看源码,首先看object.c:
robj *createHashObject(void) {
unsigned char *zl = lpNew(0);
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_LISTPACK;
return o;
}
上面代码首先调用lpNew创建了一个listpack数据结构,然后创建了一个redisObject对象,最后指定了编码为OBJ_ENCODING_LISTPACK,下面我们着重分析一下lpNew函数。
/* Create a new, empty listpack.
* On success the new listpack is returned, otherwise an error is returned.
* Pre-allocate at least `capacity` bytes of memory,
* over-allocated memory can be shrunk by `lpShrinkToFit`.
* */
unsigned char *lpNew(size_t capacity) {
unsigned char *lp = lp_malloc(capacity > LP_HDR_SIZE+1 ? capacity : LP_HDR_SIZE+1);
if (lp == NULL) return NULL;
lpSetTotalBytes(lp,LP_HDR_SIZE+1);
lpSetNumElements(lp,0);
lp[LP_HDR_SIZE] = LP_EOF;
return lp;
}
lpNew函数创建了一个空的listpack,一开始分配的大小为LP_HDR_SIZE加上1个字节,LP_HDR_SIZE宏定义是在listpack.c中,它默认是6个字节,其中4个字节记录listpack总字节树,2个字节是记录listpack的元素数量,此外listpack的最后一个字节是用来标识listpack的结束,器默认值是宏定义LP_EOF,和ziplist列表项的结束标记一样,LP_EOF的值也是255。lpNew函数将listpacack创建完后,回到createHashObject函数,接着会调用createObject来创建redisObject对象。
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;
//ptr指向前面创建的listpack数据结构
o->ptr = ptr;
o->refcount = 1;
o->lru = 0;
return o;
}
分析:明明有ziplist了,为什么出来一个listpack紧凑列表?
前面我们分析压缩列表时,我们知道每个entry都会记录一个prevlen,即前继节点的长度,如果前一个节点的长度小于254个字节,则prevlen用1个字节表示,否则prevlen就用5个字节表示。但这会存在一个连锁更新现象。紧凑列表就是redis设计用来取代掉ziplist的数据结构,它通过每个节点记录自己长度其放在自己节点的尾部,来彻底解决掉了ziplist存在的连锁更新现象。
- listpack结构
listpack主要由4部分组成,分别是total Bytes、Num Elem、Entry以及End。
| TotalBytes | 为整个listpack的空间大小,占用4个字节,每个listpack最多占用4294967295Bytes |
|---|---|
| num-element | 为listpack的元素个数,即Entry的个数占用2个字节 |
| element-1~element-n | 具体的元素 |
| listpack-end-byte | 为listpack的结束标志,内容为0xFF |
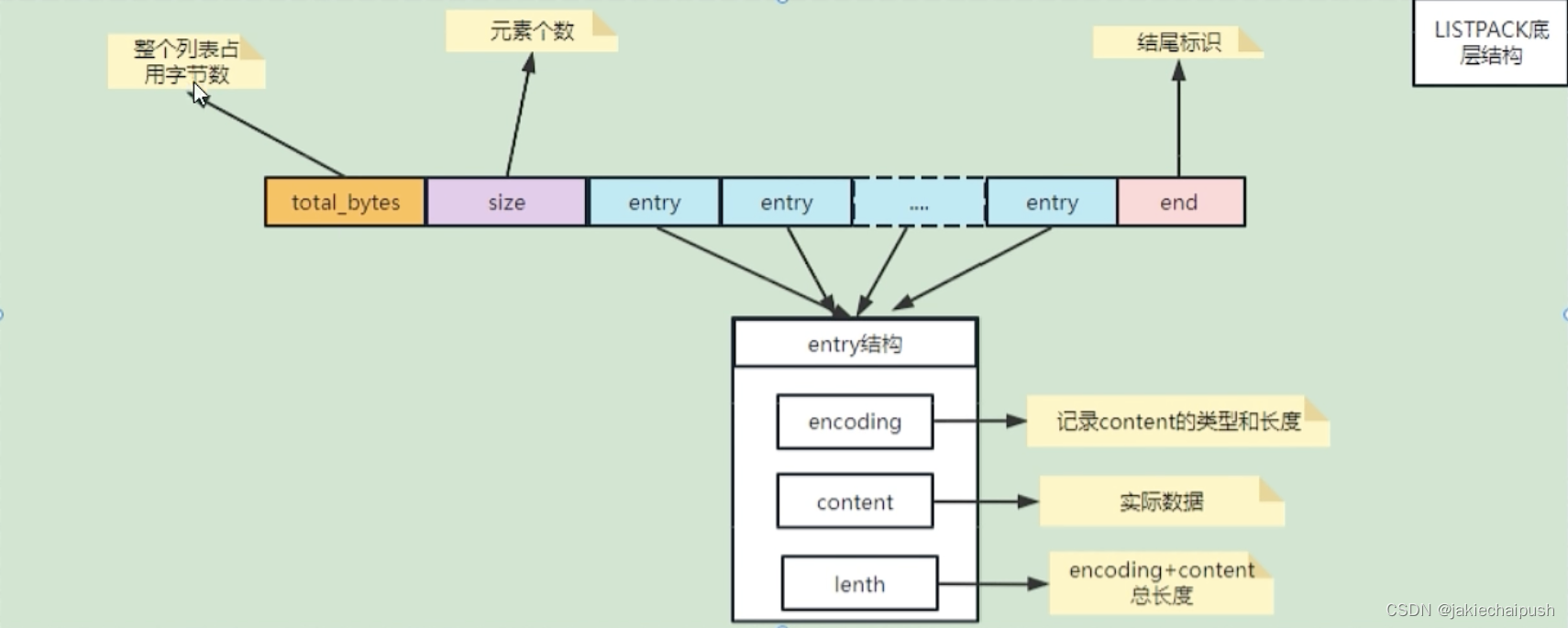
- entry的结构
entry从上图也可以看出大致结构,分别有下面几个部分:
- 当前元素的编码类型(entry-encoding)
- 元素数据(entry-data)
- 编码类型和元素数据这两部分的长度(entry-len)
//listpack.h
/* Each entry in the listpack is either a string or an integer. */
typedef struct {
/* When string is used, it is provided with the length (slen). */
unsigned char *sval;
uint32_t slen;
/* When integer is used, 'sval' is NULL, and lval holds the value. */
long long lval;
} listpackEntry;















 1500
1500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









