







文章目录
6.2 Track Score Function
字符含义汇总:
- D :数据
- DK表示第K次数据扫描的数据
- PT:真实目标的概率
- P0:是虚警目标的概率(并且PT+PT=1)
- H1 和 H0分别是概率为 PT 和 PF 的真实目标假设和虚警假设
- K表示数据扫描次数
- LR似然比
- △LU:更新时发生的增量,是运动学和信号相关项的总和。
- △LK:更新时运动学增量。
- △LS:更新时信号相关项增量。
- M:测量维度
- VC:测量体积元素,以便在每个元素内发生独立的真实目标检测和误报事件(例如,四维雷达体积元素可能由角度的波束宽度以及距离和距离速率仓宽定义。)
- S:测量残差协方差矩阵= HPH’+ R
- d2:根据测量残差向量 y ~和协方差矩阵 S 定义的测量的归一化统计距离。
- yS:总信号相关数据
- yA:信号幅度
- TH:检测阈值
- PD:检测的概率。
- PFA:虚警的概率。
- P0(H1):初始概率。
- βNT:新的目标密度。
- βFT:虚假目标密度。
- α= 错误轨迹确认概率
- β= 真实轨迹删除概率
- NFA:错误警报
- NFC:错误轨迹确认
- ND:[2]中的漏检
- THD:轨迹删除阈值
- PFD:预定允许概率
The evaluation of alternative track formation hypotheses requires a ptobabilistic expression that will include all aspects of the data association problem. define a likelihood ratio (LR) for a given combination of data (including a priori probability data) into a track to be
替代轨道形成假设的评估需要一个概率性的表达式,该表达式将包括数据关联问题的所有方面。为给定的数据组合(包括先验概率数据)定义一个似然比 (LR)
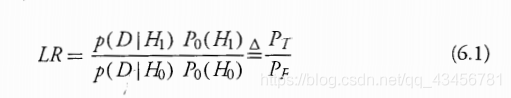
Hypotheses H1 and H0 are the true target and false alarm hypotheses with probabilities PT and PF, respectively and D is the data, so that
假设 H1 和 H0 分别是概率为 PT 和 PF 的真实目标假设和虚警假设,D 是数据,PT是真实目标的概率,P0是虚警目标的概率,(并且PT+PT=1),因此
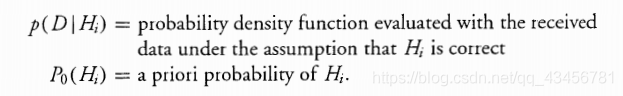
前者是在假设 Hi 正确的情况下用接收到的数据评估的概率密度函数,后者是Hi的先验概率。
A true target (H1) is most generally defined to be an object that will persist in the tracking volume for at least several scans. Thus, this definition includes objects, such as persistent clutter, that may not be of interest to the tracking system but that should be tracked in order to minimize their interference with tracks on targets of interest.
False alarms (H0) (or false targets) refer to erroneous detection events (such as those caused by random noise or clutter) that do not persist over several scans.
一个真正的目标(H1)通常被定义为一个对象,该对象将在跟踪体积中持续至少几次扫描。 因此,该定义包括跟踪系统可能不感兴趣但应该跟踪以最小化它们对感兴趣目标上的跟踪的干扰的对象,例如持续杂波。
错误警报(或错误目标)(H0)是指在多次扫描中不会持续存在的错误检测事件(例如由随机噪声或杂波引起的事件)。

LLR对数似然比,LLR 可以通过以上方式直接转换为真实目标的概率(PT)。
6.2.1 Likelihood Ratio Development

假设测量过程的精度与目标运动学无关,似然比 LR 可以划分为两项的乘积,LRK 和 LRS,分别代表运动学和信号相关的贡献。 此外,给定 K 次数据扫描,并假设测量误差的扫描间独立性,对于 K 次扫描中的每一次,LR 可以划分为项的乘积 LR(K)。 因此,定义 L0= P0(H1)/P0(H0),(这是6.1公式中的先验部分)
- K表示数据扫描次数,LR似然比
- **LRK**表示运动学的贡献
- **LRS**表示信号相关的贡献
- LR(K) :K次数据扫描中的任一次似然比

并且给定轨迹的对数似然比或分数 是 K 个运动学LRK 和 K 个信号相关项 LRS 的总和。因此,轨迹分数 (L) 定义为L(K):
- 已知:LLR=ln[LR]=ln[PT/PF]
- LR(K) :K次数据扫描中的任一次似然比
- L(K)=LLR(K)=ln(LR(K))


下面推导出这些项的形式
将在扫描 k 上接收到的数据视为运动数据 [DK(k)],例如位置测量,以及信号相关数据 [Ds(k)],例如测量的目标 SNR。 请注意,即使没有接收到其他信号相关数据,所报告的信号阈值交叉(检测)或未检测到的存在实际上也是信号相关数据。
首先,考虑运动学项,假设真实目标回报为高斯分布,而虚假回报假设为测量体积 VC上的均匀分布。 然后,得到LRK
- D表示数据,DK表示第K次数据扫描的数据
- H1真实目标假设,H0虚警目标假设
- M:测量维度
- VC:测量体积元素,以便在每个元素内发生独立的真实目标检测和误报事件(例如,四维雷达体积元素可能由角度的波束宽度以及距离和距离速率仓宽定义。)
- S:测量残差协方差矩阵= HPH’+ R
- d2:根据测量残差向量 y ~和协方差矩阵 S 定义的测量的归一化统计距离。

- yS:总信号相关数据
- yA:信号幅度
- TH:检测阈值
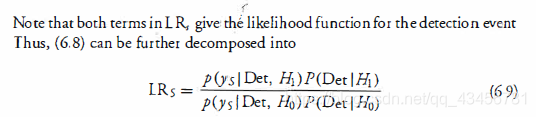
注意LRS中的两项都给出了检测事件的似然函数。因此,(6.8)可以进一步分解为 上式。
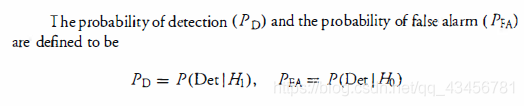
- PD:检测的概率。
- PFA:虚警的概率。
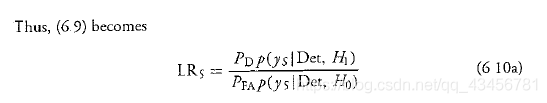
类似地,如果没有检测发生(即轨道没有更新)并且 PFA 很小:
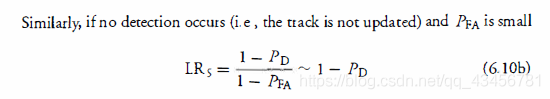
使用 (6.6) 和 (6.10) 给出了计算轨道分数的递归形式,由 (6 5) 定义:
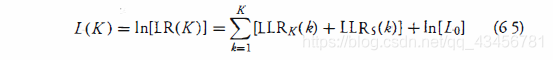
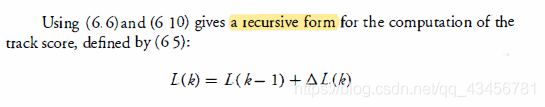
按照第K次数据扫描是否有轨道更新可以分成两种情况:

- △LU:更新时发生的增量,是运动学和信号相关项的总和。
- △LK:更新时运动学增量。
- △LS:更新时信号相关项增量。
6.2.2 Track Score Initation(跟踪分数启动)
初始轨迹分数完全基于轨迹中的第一次观察,因此,对初始轨迹分数没有运动学贡献。那么,轨迹开始时的 LR 为下面的式子(1就代表着似然比LR的初始情况):

参考之前的式子:
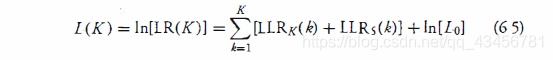
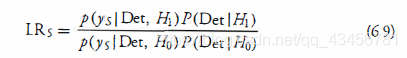
目标出现在 接收到检测的测量单元体积中 的初始概率由下式给出:
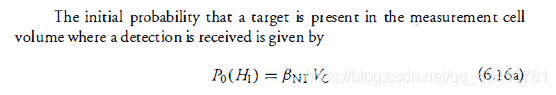
- P0(H1):初始概率。
- βNT:新的目标密度。
其中 βNT 是新的目标密度,它通常是测量空间中位置的函数。总是有机会发生误报,因此 :
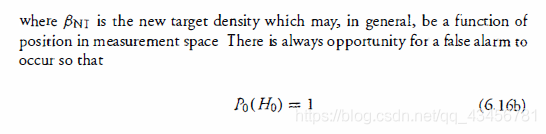
(6 16a) 和(6 16b) 之间的差异反映了这样一个事实,即目标必须在测量单元内才能发生真正的目标检测。 但是导致误报的现象(随机噪声、背景)总是存在于所有测量单元中。这些现象的重要性由PFA决定。 最后,结合 (6.15) 和 (616) 给出:
参考前面的式子:
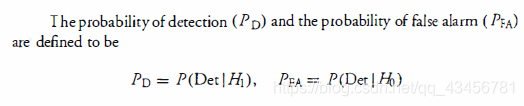
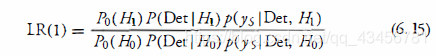
得出以下结论:

并且通过取LR(1)的对数得到初始轨迹分数,来得到 :
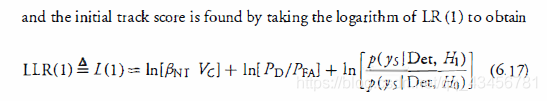
6.2.3 Special Cases of Signal-Related-Data
(1)仅检测数据
在唯一与信号相关的数据是检测(或未命中)发生的情况下,(6.14)中的第二项相同为零即△LS第一项为0,随后再将△LK和△LS代入△LU即可,并且轨道更新时的分数增量为:

其中(6.14)回顾:
按照第K次数据扫描是否有轨道更新可以分成两种情况:

- △LU:更新时发生的增量,是运动学和信号相关项的总和。
- △LK:更新时运动学增量。
- △LS:更新时信号相关项增量。
- βFT:虚假目标密度。
允许 (6. 18) 以与先前在 [2] 中提出的相同形式放置 :
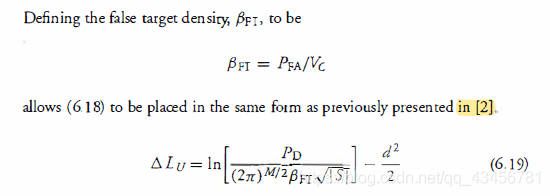
因此初始的跟踪分数可以变为:
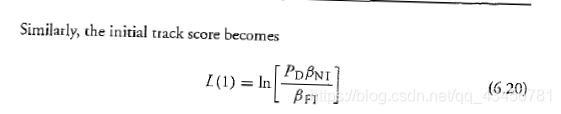
(2)测量信号幅度 (SNR)
在信号数据(yS) 只是测量的信号幅度(yA) 的情况下,(6.14) 中所需的概率分布函数被定义为仅在检测区域(y A > TH) 中非零。 在这个区域,他们被赋予:

因为只考虑检测区域,(6.21) 和 (6.22) 中给出的分布分别通过 PD 和 PFA 的划分进行归一化。 这些划分确保分布曲线下的面积是统一的。
结合(6.14)(6.21)(6.22)可以给出信号相关项分数增量部分的一般形式:

相似地,初始追踪分数为:
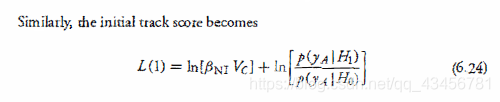
字符含义:
- PD:检测的概率。
- PFA:虚警的概率。
- △LS:更新时信号相关项增量。
- yS:总信号相关数据
- yA:信号幅度
- D:表示数据,DK表示第K次数据扫描的数据
- H1:真实目标假设
- H0:虚警目标假设
(3)基于分数的轨迹确认和删除
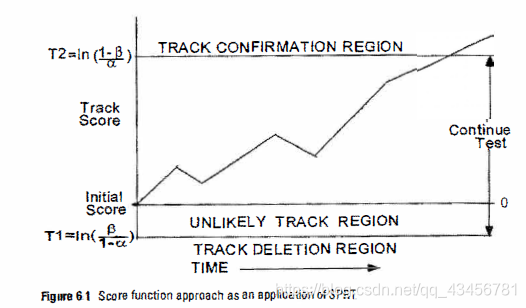
利用轨迹分数来确认和删除是经典的SPRT方法的应用,SPRT中将LLR当作轨迹分数。如图6-1,LLR(或者分数L),在跟阈值T1、T2相比较。
- 当L大于T2:宣布追踪确认
- 当L在T1、T2之间:继续测试
- 当L小于T1:删除轨迹

其中,为此应用程序定义了预先指定的错误判定概率,如下所示:
- α= 错误轨迹确认概率
- β= 真实轨迹删除概率
允许的错误轨迹确认概率 α 可以根据系统对错误轨迹启动的要求来定义。作为说明,假设系统每秒产生 NFA错误警报并且每小时允许 NFC 错误轨迹确认。 那么,α,这些虚警中的任何一个将产生虚轨的允许概率,是 :
- NFA:错误警报
- NFC:错误轨迹确认

举例子,给定NFA、 NFC,可以得出α(错误轨迹确认概率)。
β( 真实轨迹删除概率)对轨迹确认阈值的影响很小,并且数值也很小,能被用来计算T2。
然后,最好根据系统轨道维护能力确定低分轨道的删除规则。
最后,请注意,SPRT 阈值是在初始轨迹分数为零的假设下选择的。 因此,如果使用非零的初始分值,如(6.20)给出的,则应将此初始值添加到确认阈值(T2)


使用基于 SPRT 的轨道得分阈值取代了 [2] 中讨论的用于轨道确认的传统临时 M/N 规则。 类似地,如 [2] 中进一步讨论的,基于分数的轨迹删除也可以取代 ND 漏检的典型 ad hoc 规则。 [2] 中的推荐方法使用从最大轨迹分数(在Km次扫描)减少的分数(在K次扫描),就如定义:

当这个差距小于轨迹删除阈值THD时轨迹删除就出现了,也就是当满足下式时轨迹就被删除:
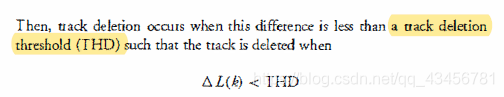
删除阈值(THD)的选择可以基于错误删除真实目标轨迹的预定允许概率(PFD)。 这个概率最好作为轨道状态的函数来选择,例如,删除完善的轨道比删除暂定轨道更困难。例如,对于MHT算法在此chaptet和Chaptet16后面描述的,证实轨道删除阈值典型地选择为PFD=10-3,使得THD公式如下:
这种删除阈值的选择近似对应于 ND = 5 的选择,假设满足门的概率接近统一,PD = 0.75,因为 (0.25)5 ~ 10-3。然而,使用分数递减进行删除比仅使用 ND漏检更普遍,因为更新差(大的d2)和偶尔更新(可能来自误报)中断的漏检串也会导致低质量轨道的删除 。
字符含义:
- THD:轨迹删除阈值
- PFD:预定允许概率
- PD:检测的概率
- ND:[2]中的漏检
















 534
534











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











