






pdf格式转换--gpu版
一级目录
二级目录
三级目录
pdf格式转换–开源项目marker的安装使用(附wsl环境配置cuda和开发环境)
在日常学习时由于习惯用md格式收集整理各种各样的笔记,在阅读pdf书籍资料时无法像md文件那样轻松编辑,遇到问题时也不易整理,之前接触到marker这个开源项目可以将pdf转换成几种格式的文件,这里做一下整理使用。
本文主要整理和记录的是在wsl环境下的cuda和开发环境配置,当这些前置步骤做好了使用marker等开源项目只要按照官方文档操作即可。
为什么选择wsl环境?
如果使用linux系统的话在安装nvida驱动时可能会遇到黑屏等问题解决起来比较耗时,在ubuntu系统下可自行搜索nvidia驱动安装(可能会遇到驱动安装后造成黑屏死机等问题,黑屏死机的解决方案见前文Ubuntu 安装 NVIDIA 驱动导致黑屏详细解决方案),windows系统是天然就支持nvida驱动的,但是使用windows系统本身的开发环境直接运行marker这种项目却会有各种各样的问题,wsl就能够像在linux上一样避免这些浪费时间的问题。
有关marker的介绍和调用方式详细可参考项目地址:https://github.com/VikParuchuri/marker
这里贴一下它的简要介绍:
Marker converts PDFs to markdown, JSON, and HTML quickly and accurately.
Supports a wide range of documents
Supports all languages
Removes headers/footers/other artifacts
Formats tables and code blocks
Extracts and saves images along with the markdown
Converts equations to latex
Easily extensible with your own formatting and logic
Works on GPU, CPU, or MPS
实测效果感觉虽不是很理想但比起一般的工具如pandoc等还是要强不少的。
下面首先整理一下wsl的常用或者说是必备操作吧
wsl安装
打开 PowerShell(以管理员身份运行),依次执行以下命令:
# 启用 WSL 功能
dism.exe /online /enable-feature /featurename:Microsoft-Windows-Subsystem-Linux /all /norestart
# 启用虚拟机平台
dism.exe /online /enable-feature /featurename:VirtualMachinePlatform /all /norestart
# 重启电脑后,设置 WSL2 为默认版本
wsl --set-default-version 2
# 安装 Ubuntu(推荐的 Linux 发行版)
wsl --install -d Ubuntu
备份 WSL 实例
-
导出 WSL 实例:
使用wsl.exe命令导出你的 WSL 实例。打开 PowerShell 或命令提示符,并运行以下命令:wsl --export <DistroName> <BackupFileName>.tar其中,
<DistroName>是你的 WSL 发行版的名称(例如Ubuntu-22.04),<BackupFileName>是你想要保存的备份文件名。示例:
wsl --export Ubuntu-22.04 C:\WSL_Backup\ubuntu_backup.tar -
确认备份文件:
确保备份文件成功创建在指定的目录中。
恢复 WSL 实例
如果未来需要恢复备份,可以使用以下步骤:
-
导入 WSL 实例:
使用wsl.exe导入之前的备份。打开 PowerShell 或命令提示符,并运行:wsl --import <NewDistroName> <InstallLocation> <BackupFileName>.tar --version 2<NewDistroName>是你想给新实例起的名称。<InstallLocation>是你希望安装此实例的目录。<BackupFileName>是你之前创建的备份文件名。
示例:
wsl --import Ubuntu-22.04-Restore C:\WSL\Ubuntu-Restore C:\WSL_Backup\ubuntu_backup.tar --version 2
version 2表示使用wsl2
导入后的默认以root用户登录,修复:
首先可以去/home下查看用户名,之后关闭wsl :wsl --shutdown 查看名称wsl -l -v
启动wsl -d Ubuntu
在wsl中配置wsl.conf: sudo vim /etc/wsl.conf:
添加:
[user]
default=lailai
[boot]
systemd=true
[automount]
enabled=true # 启用自动挂载 Windows 驱动器
options="metadata,umask=22,fmask=11" # 设置挂载选项
[network]
generateHosts=true
generateResolvConf=true
配置说明:
-
metadata: 允许在 Linux 文件系统中存储 Windows 文件的权限信息
-
umask=22: 设置默认权限掩码
- 文件默认权限为 644 (rw-r–r–)
- 目录默认权限为 755 (rwxr-xr-x)
-
fmask=11: 专门为文件设置权限掩码
- 确保文件不会被意外设置为可执行
-
generateHosts=true
- 自动更新 /etc/hosts 文件
- 确保 WSL 可以解析 Windows 主机名
- 添加必要的本地主机条目
-
generateResolvConf=true
- 自动生成 /etc/resolv.conf 文件
- 使用 Windows 的 DNS 设置
- 确保 WSL 可以正常解析域名
在 WSL (Windows Subsystem for Linux) 的 Ubuntu 中安装适用于 CUDA 的 PyTorch 版本,可以按照以下步骤进行。请确保已经安装了 WSL 2 并配置了 Ubuntu。具体步骤如下:
如何开启wsl内的代理
虽然通过配置镜像源的方式能解决大部分下载问题,但有时就是需要下载某些原生的软件或者访问请求等,这时就可以将windows主机内的代理同步到wsl中,如果使用clash,一种比较简单的方式是开启TUN模式,但有时会遇到失效的情况,也可以直接在wsl内通过设置代理地址的方式:
# 设置 windows_host 变量
export windows_host=$(ip route | grep default | awk '{print $3}')
# 设置代理
export http_proxy="http://$windows_host:7890"
export https_proxy="http://$windows_host:7890"
export all_proxy="socks5://$windows_host:7890"
# 测试代理是否生效
curl www.google.com
pytorch/cuda环境配置
接下来是环境的配置:
1. 更新系统
首先,打开 WSL 的终端,确保你的系统是最新的:
sudo apt update
sudo apt upgrade
更新失败时:
sudo apt dist-upgrade # 会处理依赖关系
sudo apt-get -f install # 也是修复依赖
2. 安装必要的依赖
在安装 PyTorch 之前,确保你的系统装有必要的依赖项:
sudo apt install python3 python3-pip python3-venv
3. 创建和激活虚拟环境(可选步骤)
为了保持项目的整洁,建议创建一个 Python 虚拟环境:
python3 -m venv marker_env
source marker_env/bin/activate
安装go :
wget https://golang.org/dl/go1.23.2.linux-amd64.tar.gz
sudo tar -C /usr/local -xzf go1.23.2.linux-amd64.tar.gz
vim ~/.bashrc —>`source ~/.bashrc
# 设置 Go 的安装路径
export PATH=$PATH:/usr/local/go/bin
export GOPATH=$HOME/go
export PATH=$PATH:$GOPATH/bin
验证:go version
4. 安装 NVIDIA 驱动和 CUDA Toolkit
确保你的 Windows 系统中安装了 NVIDIA 图形驱动,并且支持 CUDA。然后,可以在 WSL 中安装 CUDA Toolkit。
-
安装 NVIDIA 驱动:
- 确保你的 Windows 系统安装了最新版本的 NVIDIA 驱动,这些驱动支持 CUDA。
-
安装 CUDA Toolkit:
- WSL 2 中可以直接使用 CUDA。确保你的系统已经安装了 CUDA Toolkit。可以访问 NVIDIA 的 CUDA Toolkit 页面 来获取安装说明。
windows使用nvidia-smi查看cuda-version–>CUDA Toolkit 12.6 Update 2 Downloads | NVIDIA Developer选择ubuntu版本:
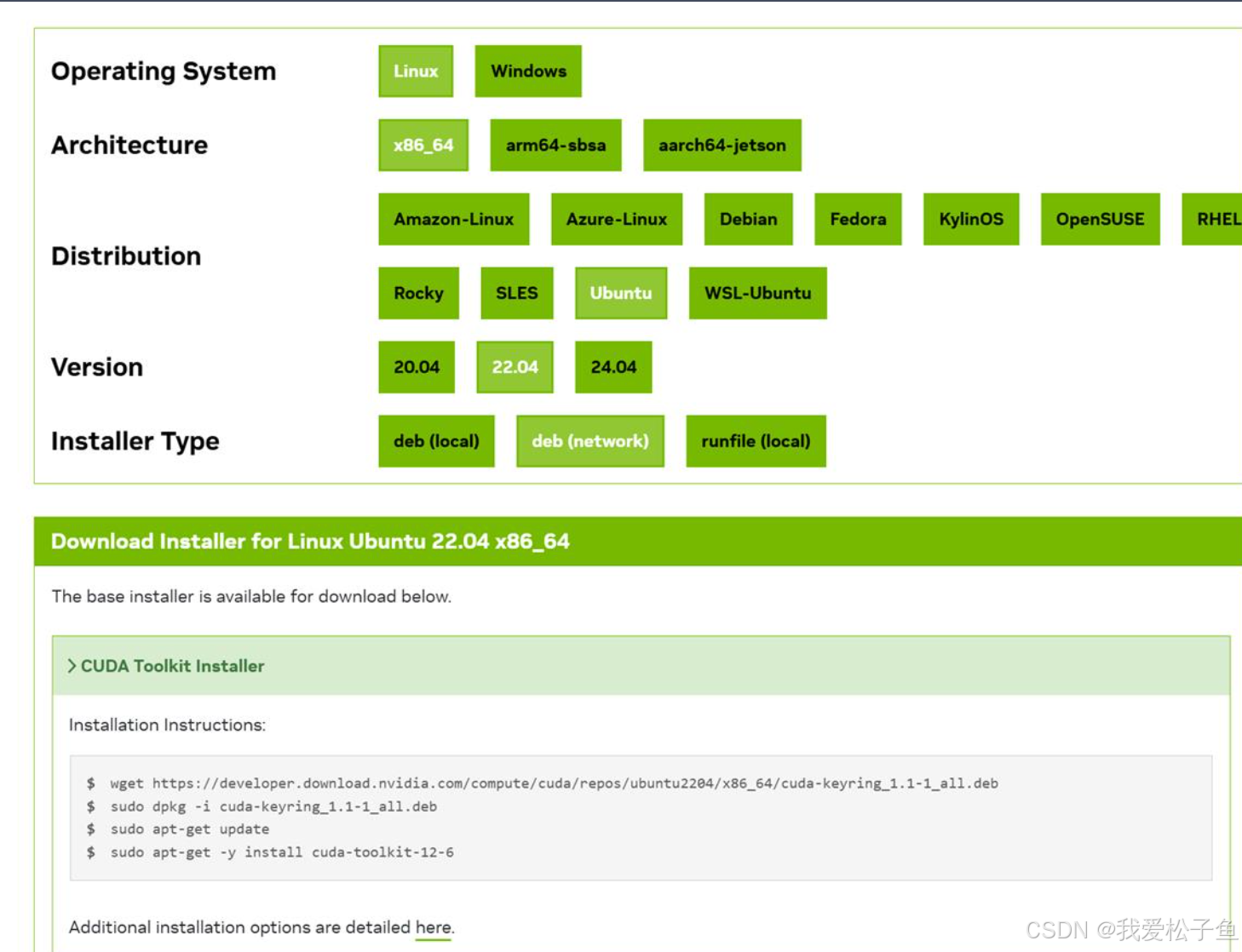
执行下面的命令,之后添加到环境变量:~/.bashrc
- WSL 2 中可以直接使用 CUDA。确保你的系统已经安装了 CUDA Toolkit。可以访问 NVIDIA 的 CUDA Toolkit 页面 来获取安装说明。
# 添加以下内容到文件末尾
export PATH=/usr/local/cuda-12.6/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
–>source ~/.bashrc,查看安装nvcc -V
5. 安装 PyTorch
根据你的 CUDA 版本,选择合适的 PyTorch 安装命令。可以在 PyTorch 官方网站 找到具体的安装命令。通常,你可以使用以下命令安装 PyTorch:
例如,如果你安装了 CUDA 11.7,使用以下命令:
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu117
6. 验证安装
安装完成后,运行 Python 并验证 PyTorch 是否成功安装:
python3
然后输入以下 Python 代码:
import torch
print(torch.__version__)
print(torch.cuda.is_available())
- 如果 PyTorch 安装正确,会输出版本号。
torch.cuda.is_available()如果返回True,则说明 CUDA 可以正常使用。
marker安装使用
前置:gpu加速,nvidia显卡驱动,cuda,pytorch
安装marker-pdf:pip install marker-pdf
安装ocr:
# 1. 安装ocrmypdf
sudo apt-get install ocrmypdf
# 2. 安装ghostscript(使用提供的脚本)
bash scripts/install/ghostscript_install.sh
# 3. 安装Python包
pip install ocrmypdf
# 4. 安装tesseract语言包(根据需要选择语言)
sudo apt-get install tesseract-ocr-eng
# 5. 查找tessdata路径
find / -name tessdata
# 6. 创建环境变量文件
# 将找到的tessdata路径填入下面的命令
echo "TESSDATA_PREFIX=/你找到的/tessdata/路径" > local.env
中文简体:tesseract-ocr-chi-sim,繁体:tesseract-ocr-chi-tra
安装完成后,可以运行以下命令来检查安装的语言包
tesseract --list-langs
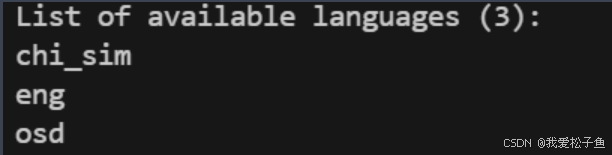
Tesseract单独使用ocr示例:
tesseract image.png output -l chi_sim
image.png是您要识别的图像文件。output是输出文件的前缀,Tesseract 会生成output.txt。-l chi_sim指定使用简体中文语言包进行识别。
使用find / -name tessdata或sudo find / -name tessdata时:
sudo find / -name tessdata
/usr/share/tesseract-ocr/4.00/tessdata
find: File system loop detected; ‘/mnt/wslg/distro’ is part of the same file system loop as ‘/’.
find: ‘/mnt/c/Program Files/Windows Defender Advanced Threat Protection/Classification/Configuration’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows/CapabilityAccessManager’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows/SystemData’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows Defender Advanced Threat Protection/Cache’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows Defender Advanced Threat Protection/Cyber’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows Defender Advanced Threat Protection/DataCollection’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows Defender Advanced Threat Protection/DLP’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows Defender Advanced Threat Protection/Downloads’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows Defender Advanced Threat Protection/Platform’: Permission denied
find: ‘/mnt/c/ProgramData/Microsoft/Windows Defender Advanced Threat Protection/SenseCM’: Permission denied
。。。
这种情况是因为你在WSL (Windows Subsystem for Linux)环境下运行命令,而这些Permission denied错误是完全正常的:
- 即使你使用sudo,也无法访问某些Windows系统保护的目录
- 这些目录通常是Windows系统目录或特殊服务目录
- 这里已经找到了需要的tessdata目录
/usr/share/tesseract-ocr/4.00/tessdata
marker_single转换pdf
我们可以使用marker_single命令来转换单个PDF文件。
首先创建一个输出目录来保存markdown和图片:
# 创建输出目录
mkdir -p /mnt/e/.../output
然后使用marker_single命令转换PDF:
marker_single "/mnt/e/.../xxx.pdf" "/mnt/e/.../output"
说明:
-
默认情况下会:
- 自动提取和保存图片(
EXTRACT_IMAGES=True) - 图片会保存在输出目录下的
images文件夹中 - 生成markdown文件和一个metadata.json文件
- 自动提取和保存图片(
-
如果文档较大,你可以添加一些参数来控制转换:
marker_single "/mnt/e/.../xxx.pdf" "/mnt/e/.../output" \
--batch_multiplier 2 \ # 如果你有足够的显存,可以提高处理速度
--max_pages 50 # 如果你想先测试部分页面
- 如果转换效果不理想,可以尝试强制使用OCR:
# 设置环境变量强制OCR
export OCR_ALL_PAGES=true
# 然后运行转换命令
marker_single "/mnt/e/.../xxx.pdf" "/mnt/e/.../output"
转换完成后,在output目录下你会看到:
- 一个
.md文件(转换后的markdown文档) - 一个
metadata.json文件(包含转换的统计信息) - 一个
images文件夹(包含所有提取的图片)
GPU显存设置
参数:--batch_multiplier用来控制GPU显存使用的,而不是系统内存(RAM)
-
Marker默认设置:
- 默认使用约3-4GB显存
- –batch_multiplier 1是默认值
- –batch_multiplier 2会使用约6-8GB显存
- –batch_multiplier 3会使用约9-12GB显存
-
如何设置这个参数:
-
首先查看你的显卡显存大小:
nvidia-smi
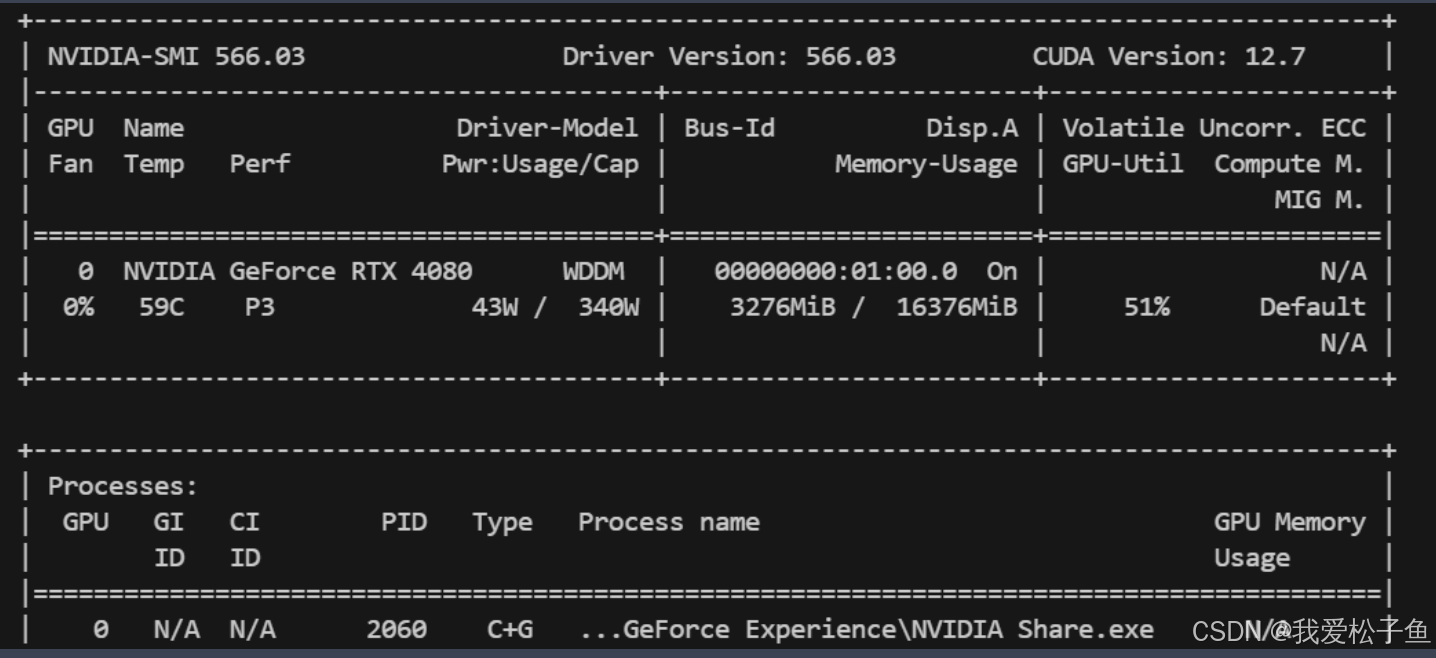
根据你的显卡显存大小来设置:
- 如果显存 4GB:使用默认值 --batch_multiplier 1
-
- 如果显存 8GB:可以使用 --batch_multiplier 2
-
- 如果显存 12GB或以上:可以使用 --batch_multiplier 3或更高
-
- 实际使用建议:bash# 如果你有8GB显存的显卡marker_single “你的PDF路径” “输出目录” --batch_multiplier 2# 如果你有12GB或以上显存的显卡marker_single “你的PDF路径” “输出目录” --batch_multiplier 3
-
- 如果你没有独立显卡: - Marker会自动使用CPU模式 - 这种情况下–batch_multiplier参数影响不大 - 建议保持默认值或设置为1。如果你不确定,可以运行:bashnvidia-smi来查看显卡信息。
运行命令过程中会从huggingface下载模型,需要开启代理下载加速,参考前文。
或尝试使用镜像export HF_ENDPOINT=https://hf-mirror.com然后重新运行marker_single xxx命令


















 1957
1957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











