






纯属无聊的小爬虫,技术含量不高勿喷…
一.爬取思路:
1.找到王者荣耀官网的英雄资料列表页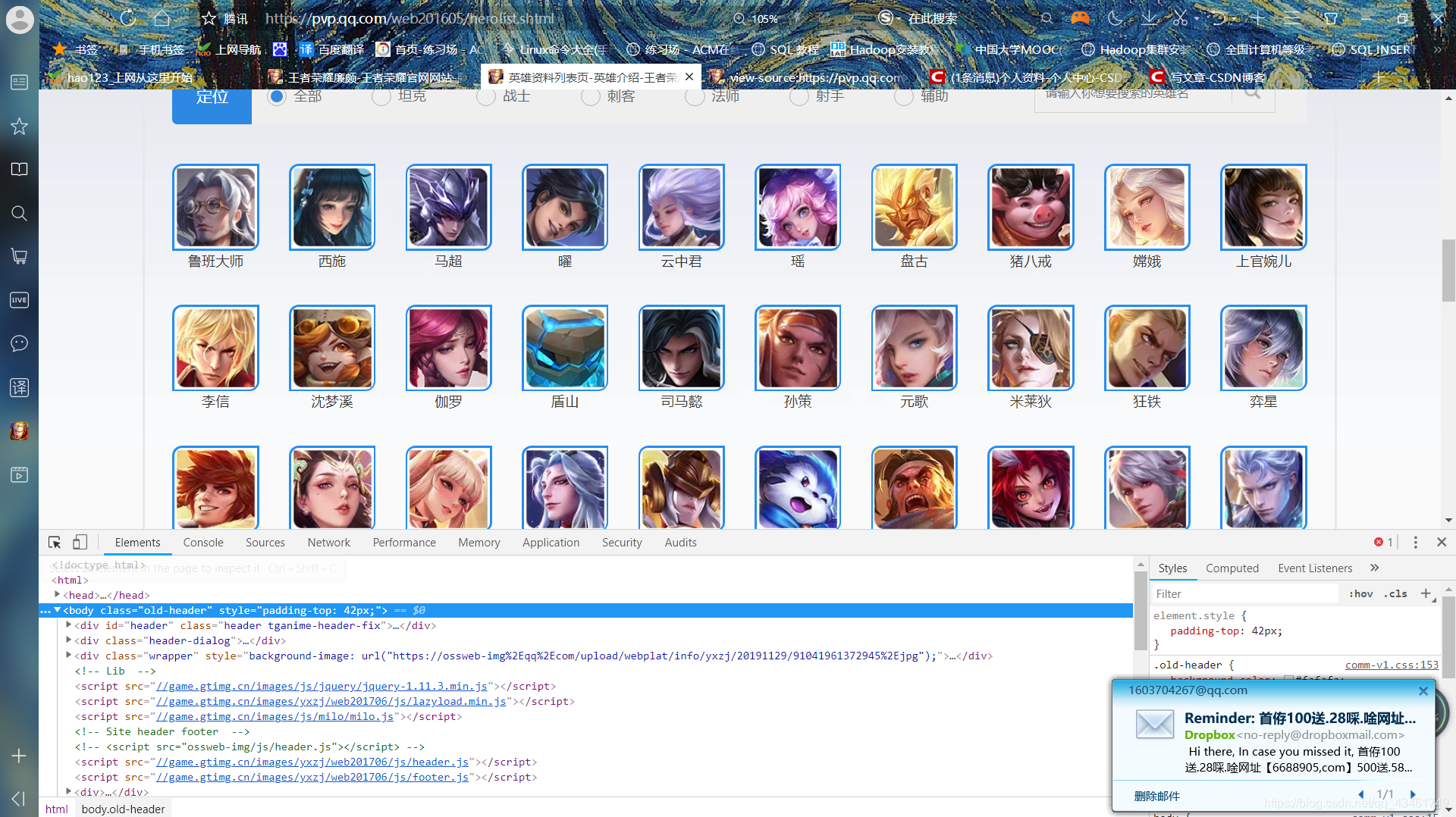
2.按F12查找英雄链接所在的标签,再按ctrl+shift+c移动鼠标移到不同英雄头像处,发现英雄列表都在一个ul下的li下,链接和信息都在a标签下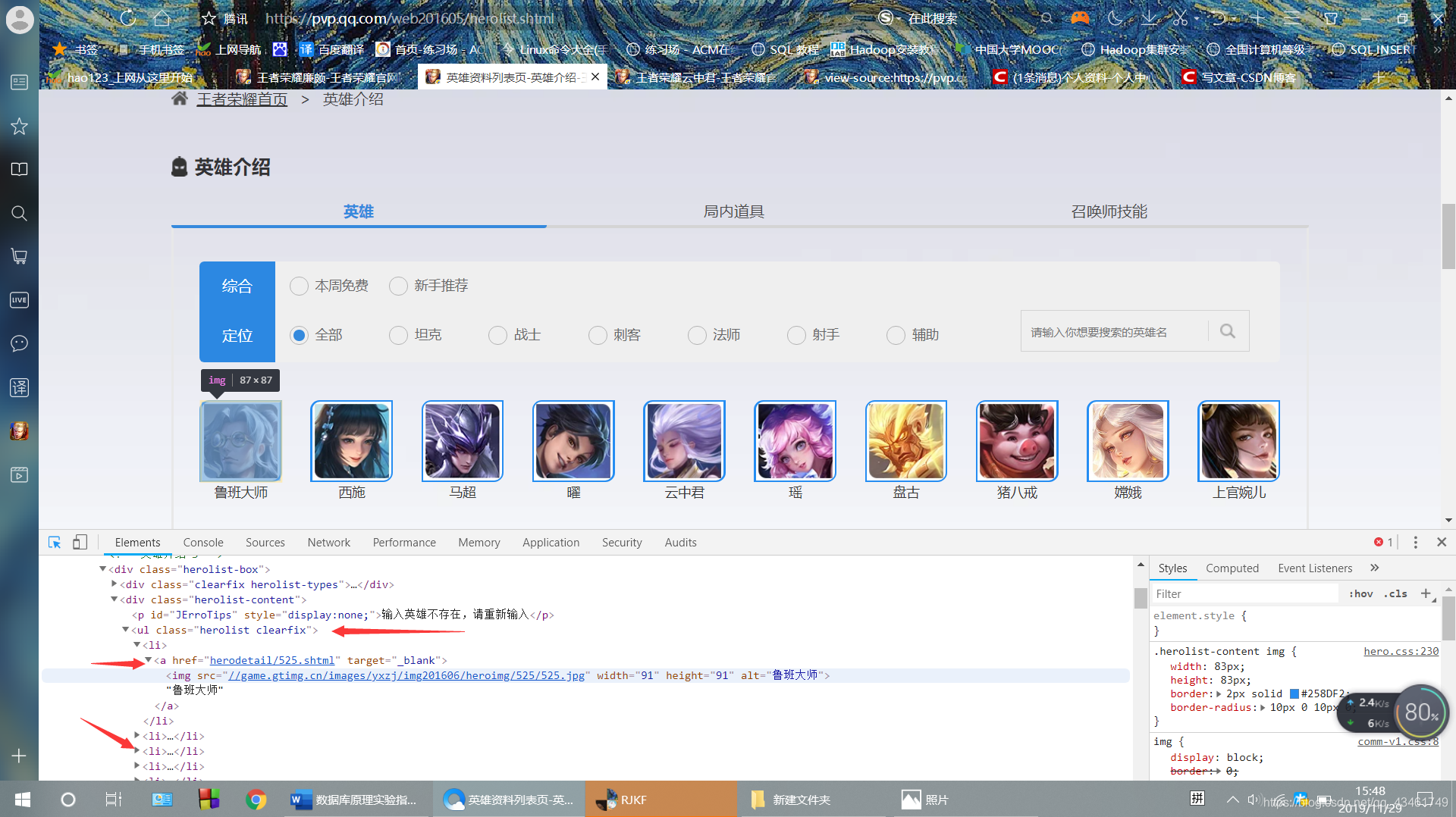
3.编写正则表达式获取英雄链接列表,以及相关信息(部分代码)
def getLink(html):
soup=BeautifulSoup(html,'html.parser')
heroList=soup.find_all('a',href=re.compile('herodetail/\d{3}.shtml'))#正则查找图片链接
for each in heroList:
link=each.get('href')#获取英雄所在链接
name=each.select('img')[0].get('alt')#获取英雄名字
_id=link[11:14]#获得英雄序号
- 注意:为什么获取英雄名字和英雄序号?
英雄名字方便之后创建文件保存,我们不难发现不同英雄的链接最后三位数不同,故推测这是区分不同英雄的关键,但是发现这些序号是乱序,不过不慌,之后获取皮肤链接会用到
4.进入英雄所在链接页面,继续按F12,ctrl+shift+c,鼠标移到背景图,查找皮肤链接所在的标签,如图:
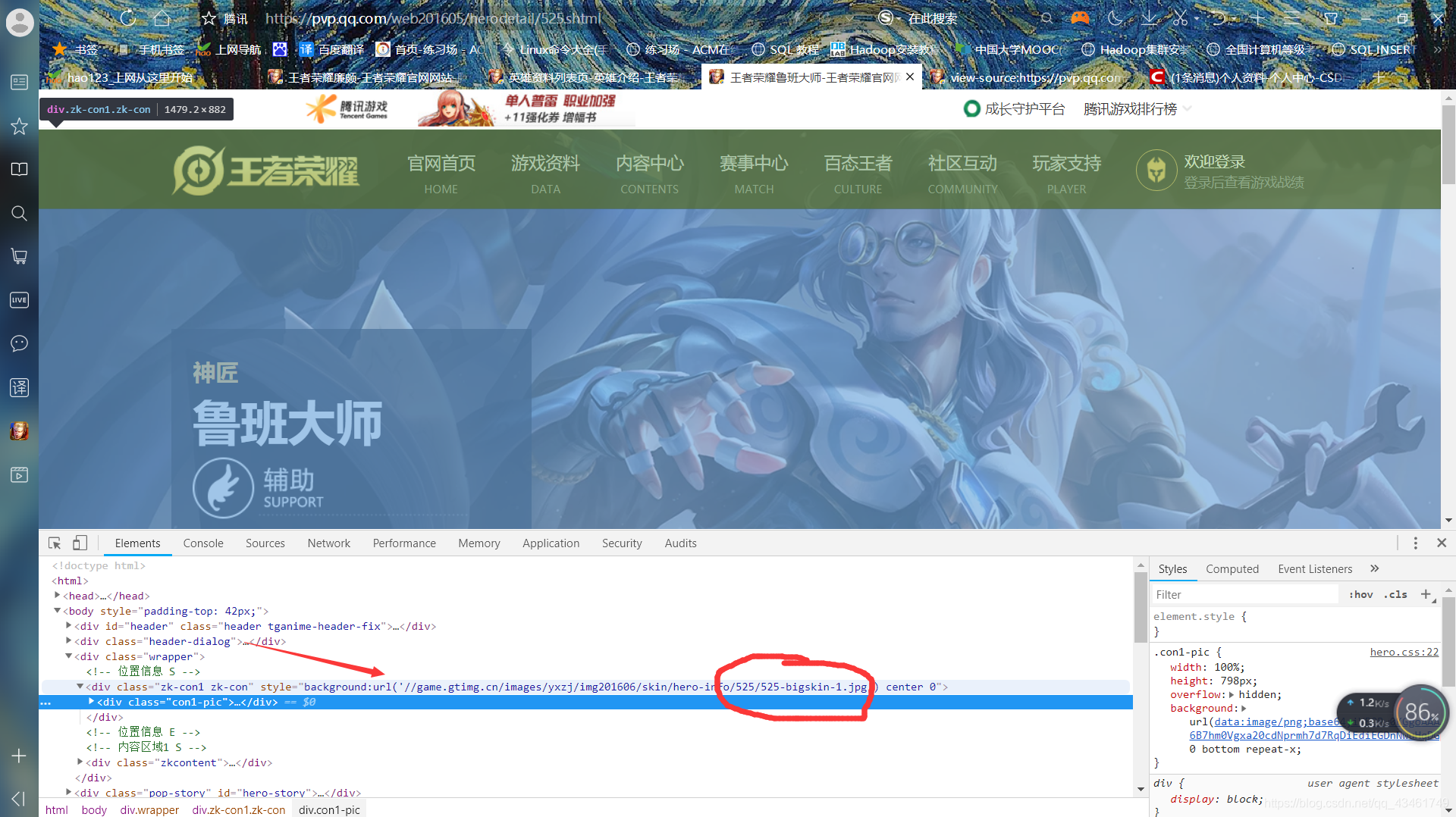
- 注意:我们不难发现此处的皮肤链接后的编号和前面的一样(都含有525),继续移动鼠标查看另一皮肤的链接,发现后面的bigskin-前面的内容没有发生改变,只是后面序号1变成了2,我们推想其他的也一样(查看后发现其他英雄的皮肤链接都是如此组成)
- 我们虽然找到了皮肤链接的组成,也得到了英雄序号,但是不同的英雄皮肤数量不尽相同,怎么确定不同英雄的皮肤数量呢?
5.继续通过观察英雄网页源代码,我发现有一个字符串记录了不同皮肤的名称,如图:
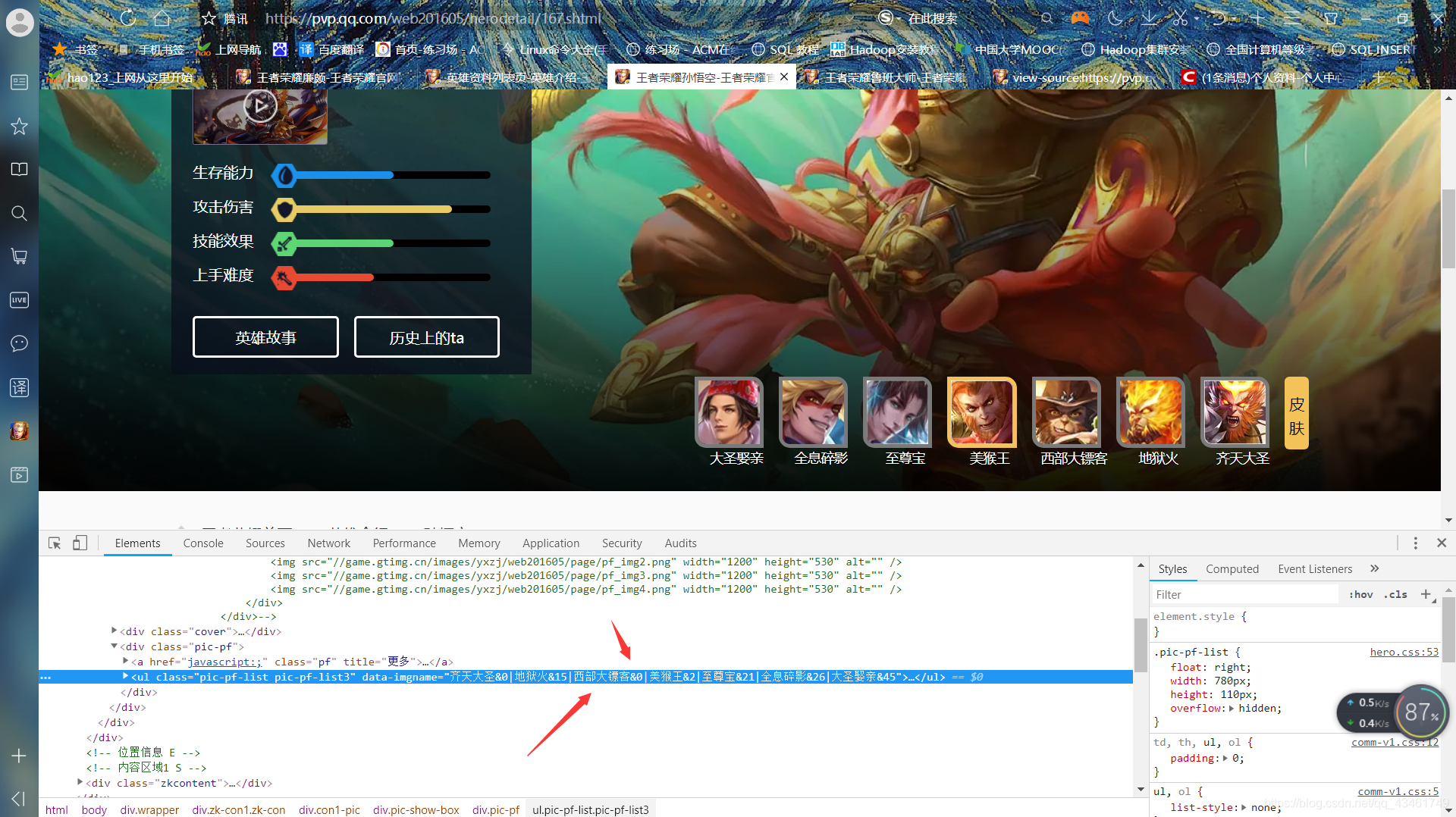
6.于是我拿这串字符串做文章,先找到它(这里用到了BeautifulSoup中的select),找到后怎么提取出有用的信息并形成皮肤列表呢?不慌,python自带的字符串方法带来了极大的便利,我们利用count方法获取字符串中&的数量来得到皮肤数量,然后用replace方法去数字,最后用split方法通过字符’|'分隔字符串形成皮肤名称列表,简直不要太顺利!
def savePic(link,name,id):#上面代码中返回的链接,名字和英雄序号
url='https://pvp.qq.com/web201605/'+link
html=getHtml(url)
soup = BeautifulSoup(html, 'html.parser')
cloName=soup.select('.pic-pf ul')[0].attrs['data-imgname']#寻找皮肤字符串
count=cloName.count('&')#找到皮肤数量
cloName=cloName.replace('&','')#去&
for i in range(10):#去数字
cloName=cloName.replace(str(i),'')
cloList=cloName.split('|')#得到皮肤名字列表
样例效果如图:

7.好了,万事俱备,我们有了英雄序号和皮肤数量,就可以组成每个英雄的皮肤链接了,再将上面得到的皮肤名称列表一一对应起来保存到本地
localPath='..\\爬王者荣耀全英雄全皮肤\\'+name+'\\'#创建每个英雄的文件夹
if not os.path.exists(localPath): # 新建文件夹,判断是否存在
os.mkdir(localPath)
basepic_link='https://game.gtimg.cn/images/yxzj/img201606/heroimg/'#皮肤链接的前缀
for i in range(1,count+1):
pic = str(id) + '/' + str(id) + '-mobileskin-' + str(i) + '.jpg'#皮肤链接的后缀
pic_url=basepic_link+pic#得到最终的完整皮肤链接
try:
pic_re = requests.get(pic_url, timeout=10)
open(localPath + cloList[i-1] + '.jpg', 'wb').write(pic_re.content)#名字皮肤一一对应保存到本地
except requests.exceptions.ConnectionError:
print('数据异常或错误!当前图片无法下载')
二.成果
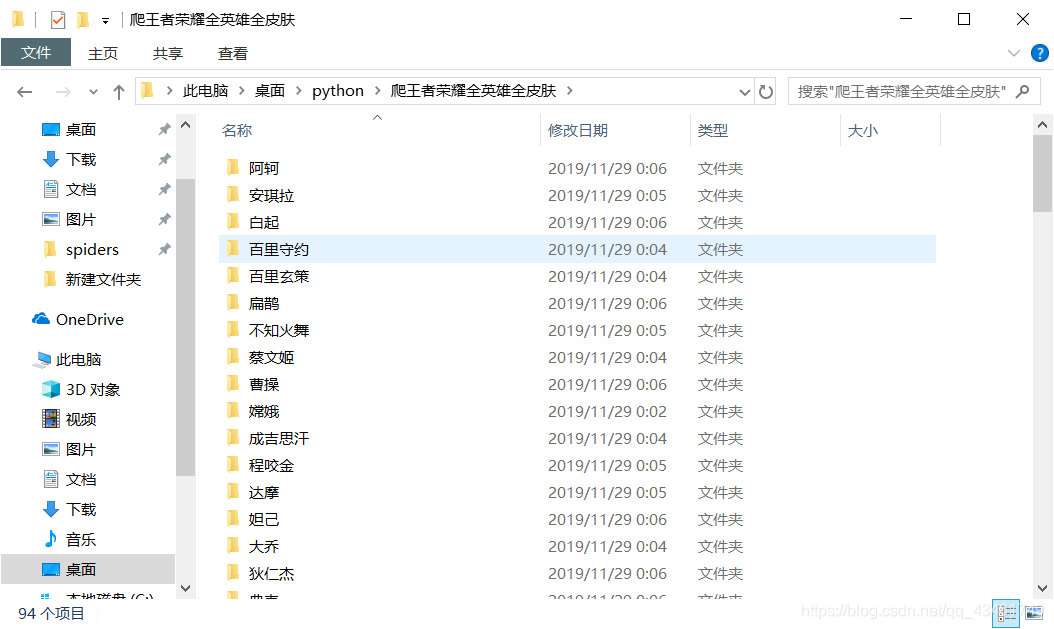
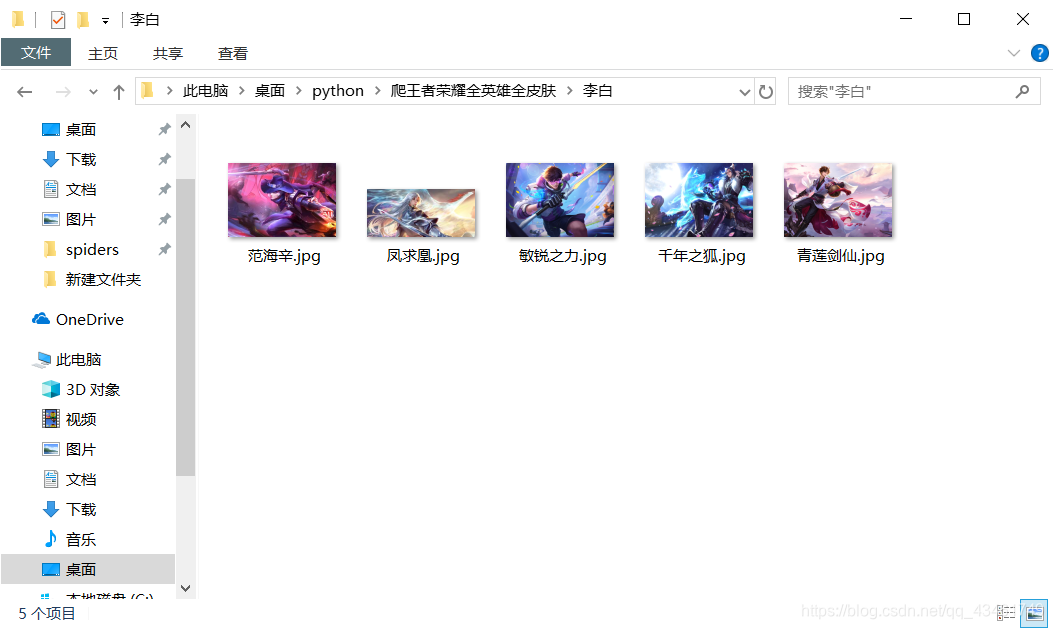
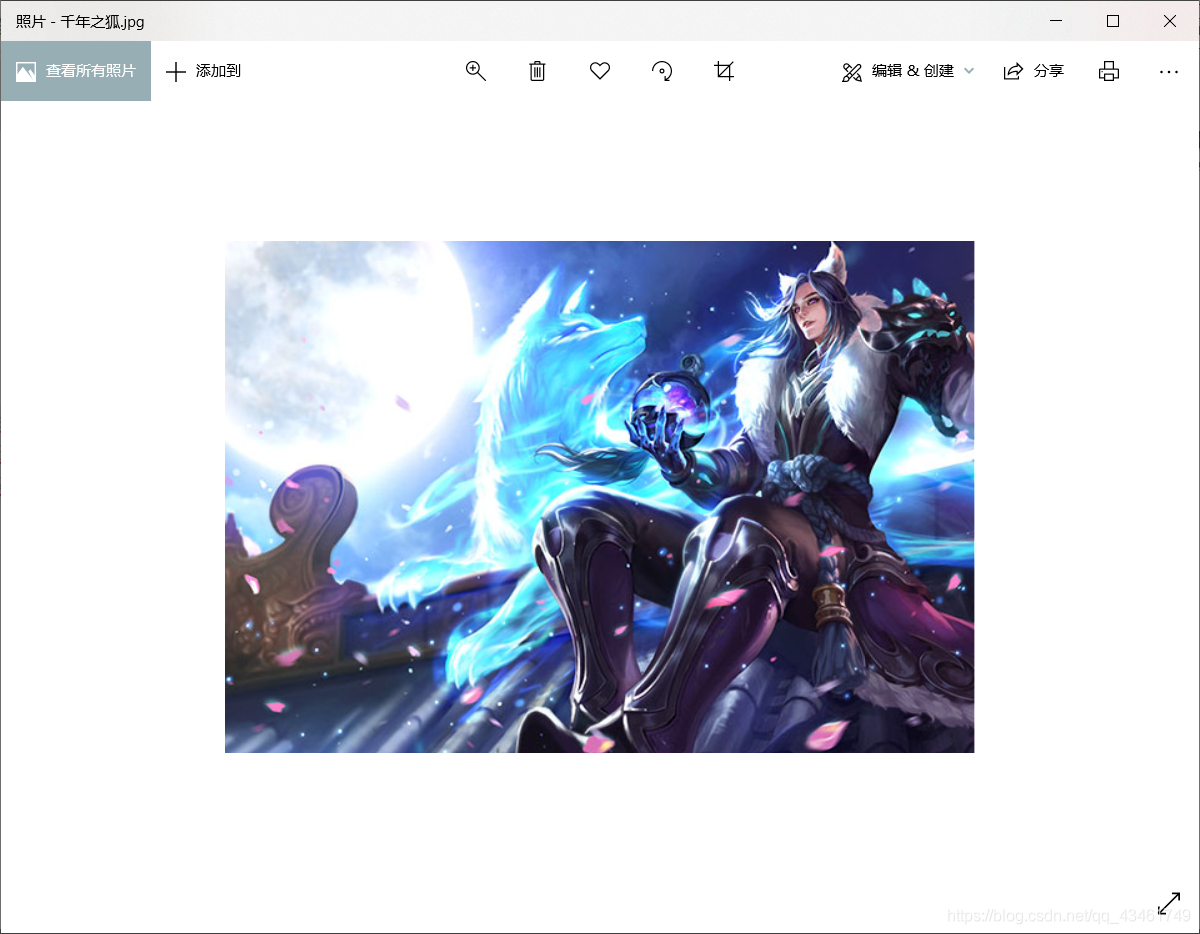
三.最终代码:
import re
import os
import requests
from bs4 import BeautifulSoup
def getHtml(url):
r=requests.get(url,timeout=10)
r.raise_for_status()
r.encoding=r.apparent_encoding#防止乱码
return r.text
def savePic(link,name,id):
url='https://pvp.qq.com/web201605/'+link
html=getHtml(url)
soup = BeautifulSoup(html, 'html.parser')
print("正在获取{}的所有皮肤链接......".format(name),end='')
cloName=soup.select('.pic-pf ul')[0].attrs['data-imgname']#寻找皮肤字符串
count=cloName.count('&')#找到皮肤数量
cloName=cloName.replace('&','')#去&
for i in range(10):#去数字
cloName=cloName.replace(str(i),'')
cloList=cloName.split('|')#得到皮肤名字列表
print("--->成功!")
localPath='..\\爬王者荣耀全英雄全皮肤\\'+name+'\\'#创建每个英雄的文件夹
if not os.path.exists(localPath): # 新建文件夹,判断是否存在
os.mkdir(localPath)
basepic_link='https://game.gtimg.cn/images/yxzj/img201606/heroimg/'
for i in range(1,count+1):
pic = str(id) + '/' + str(id) + '-mobileskin-' + str(i) + '.jpg'
pic_url=basepic_link+pic#得到最终的皮肤图片
try:
pic_re = requests.get(pic_url, timeout=10)
print("正在下载{}-{}".format(name,cloList[i-1]),end='')
open(localPath + cloList[i-1] + '.jpg', 'wb').write(pic_re.content) # 名字皮肤一一对应保存到本地
print("--->成功!")
except requests.exceptions.ConnectionError:
print('数据异常或错误!当前图片无法下载')
print("\r所有{0}的英雄皮肤下载完成!".format(name))
def getLink(html):
print("正在查找所有英雄链接......")
soup=BeautifulSoup(html,'html.parser')
heroList=soup.find_all('a',href=re.compile('herodetail/\d{3}.shtml'))#正则查找图片链接
print("获取英雄链接成功!")
for each in heroList:
link=each.get('href')#获取英雄所在链接
name=each.select('img')[0].get('alt')#获取英雄名字
_id=link[11:14]#获得英雄序号
savePic(link,name,_id)
print("所有英雄的皮肤下载完成!")
def main():
url='https://pvp.qq.com/web201605/herolist.shtml'#主页面
html = getHtml(url)
getLink(html)
print("下载完成!")
main()

















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









