









 本文通过实例演示了如何使用SVM处理数据不平衡问题,对比了不同参数设置下SVM的表现,尤其是在线性核和高斯核函数下的效果差异。
本文通过实例演示了如何使用SVM处理数据不平衡问题,对比了不同参数设置下SVM的表现,尤其是在线性核和高斯核函数下的效果差异。
前面讲到随机森林和逻辑回归对较为均衡的数据的处理效果都很不错,那么对于不均衡的数据,比如某一个特征占绝大多数,而另一个特征仅仅只有很少一点。对于这种数据,用SVM去处理是较为方便的。
下面直接通过代码来介绍
1.首先导入包
import numpy as np
from sklearn import svm
import matplotlib.colors
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, fbeta_score
import warnings
2.生成测试数据
warnings.filterwarnings("ignore") # UndefinedMetricWarning
np.random.seed(0) # 保持每次生成的数据相同
c1 = 990
c2 = 10
N = c1 + c2
x_c1 = 3*np.random.randn(c1, 2)
x_c2 = 0.5*np.random.randn(c2, 2) + (4, 4)
x = np.vstack((x_c1, x_c2))
y = np.ones(N)
y[:c1] = -1
# 显示大小
s = np.ones(N) * 30
s[:c1] = 10
可以先看看生成的数据
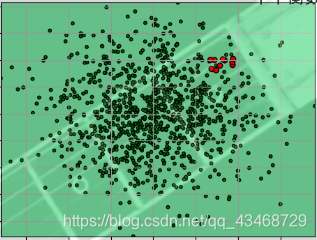
可以看到一小部分的红点,这些点如果用随机森林和回归是比较难处理的,下面我们用SVM来处理一下。首先定义种类型的SVM
clfs = [svm.SVC(C=1, kernel='linear'),
svm.SVC(C=1, kernel='linear', class_weight={-1: 1, 1: 50}),
svm.SVC(C=0.8, kernel='rbf', gamma=0.5, class_weight={-1: 1, 1: 2}),
svm.SVC(C=0.8, kernel='rbf', gamma=0.5, class_weight={-1: 1, 1: 10})]
titles = 'Linear', 'Linear, Weight=50', 'RBF, Weight=2', 'RBF, Weight=10'
打印出每种分类器的准确率、精度、召回率
cm_light = matplotlib.colors.ListedColormap(['#77E0A0', '#FF8080'])
cm_dark = matplotlib.colors.ListedColormap(['g', 'r'])
matplotlib.rcParams['font.sans-serif'] = [u'SimHei']
matplotlib.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 8), facecolor='w')
for i, clf in enumerate(clfs):
clf.fit(x, y)
y_hat = clf.predict(x)
print (i+1, '次:')
print ('正确率:\t', accuracy_score(y, y_hat))
print( ' 精度 :\t', precision_score(y, y_hat, pos_label=1))
print( '召回率:\t', recall_score(y, y_hat, pos_label=1))
print( 'F1Score:\t', f1_score(y, y_hat, pos_label=1))
开始画图
plt.subplot(2, 2, i+1)
grid_hat = clf.predict(grid_test) # 预测分类值
grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同
plt.pcolormesh(x1, x2, grid_hat, cmap=cm_light, alpha=0.8)
plt.scatter(x[:, 0], x[:, 1], c=y.ravel(), edgecolors='k', s=s, cmap=cm_dark) # 样本的显示
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(titles[i])
plt.grid()
plt.suptitle(u'不平衡数据的处理', fontsize=18)
plt.tight_layout(1.5)
plt.subplots_adjust(top=0.92)
plt.show()
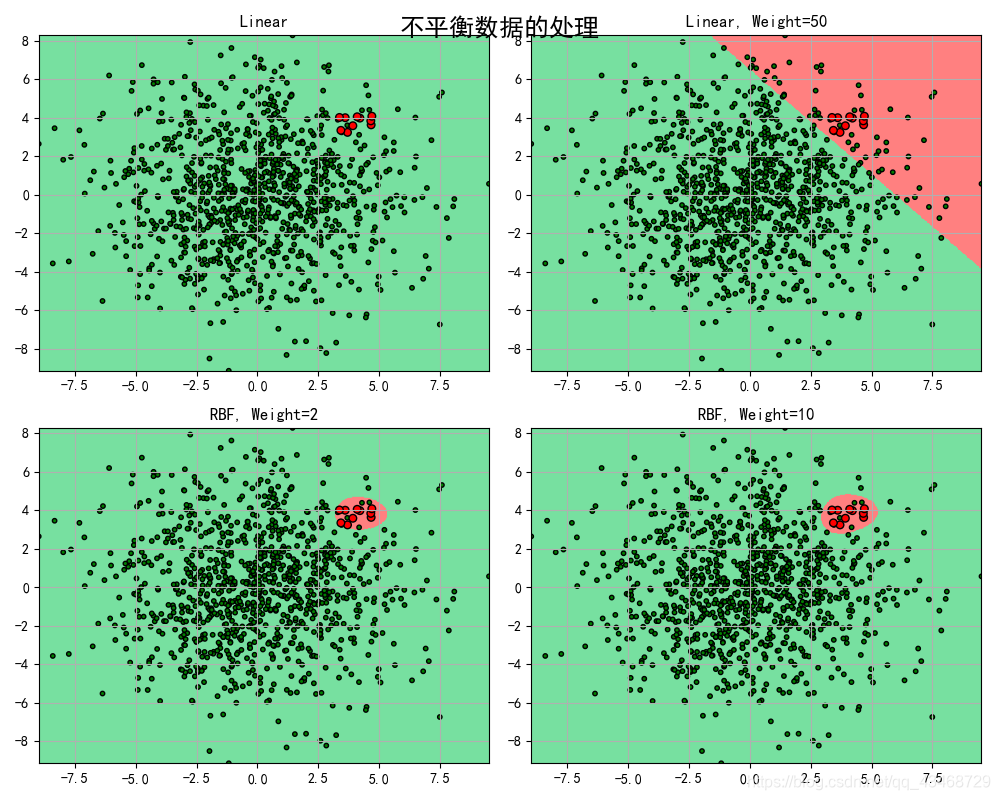
结果如下
1 次:
正确率: 0.99
精度 : 0.0
召回率: 0.0
F1Score: 0.0
2 次:
正确率: 0.94
精度 : 0.14285714285714285
召回率: 1.0
F1Score: 0.25
3 次:
正确率: 0.994
精度 : 0.625
召回率: 1.0
F1Score: 0.7692307692307693
4 次:
正确率: 0.994
精度 : 0.625
召回率: 1.0
F1Score: 0.7692307692307693
可以看到虽然第一次的正确率非常高,这是因为线性的这种SVM将所有类别都划分成了多数类 由于多数类基数过大而导致正确率过高,由此可见仅仅由正确率来判断分类器的好坏是不准确的。而在提高了权值之后,虽然能进行分类,但由于是线性一刀切,误差较大
相比之下用高斯核函数rbf的效果就要好很多。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









