







文章目录
- RegExp :正则表达对象
- 1. 常用匹配
- 2. 字面量创建正则 / /
- 3. 正则对象 new RegExp
- 4. 选择符 |
- 5. 原子表[]和原子组()
- 6. 转义 \
- 7. 字符的边界^ $
- 8. 数字\d元字符 和 空白\s元字符
- 9. \w匹配一个单字字符(字母、数字或者下划线) 囊括\d
- 10. . 点字符(小数点)匹配除换行符之外的任何单个字符
- 11. 精确匹配所有字符
- 12. i与g模式修正符
- 13. m多行搜索匹配符
- 14. 字符属性
- 15. lastIndex属性
- 16. y模式
- 17. s模式 允许 . 匹配换行符
- 18. 批量使用正则every
- 19. matchAll 全局匹配
- 20. match和search的区别
- 21. split()使用正则
- 22. $ `、$ '、$&
- 23.断言匹配
RegExp :正则表达对象
- 正则表达式 : 定义字符串的组成规则。
1. 常用匹配
1.单个字符:[]
如: [a] [ab] [a-ZA-Z0-9_]
特殊符号代表特殊含义的单个字符:
\d:单个数字字符[0-9]
\w: 单个单词字符[a-ZA-Z0-9_]
2.量词符号:
? :表示出现0次或1次
* :表示出现0次或多次
+ :出现1次或多次
{m,n}:表示m<=数量<=n
m如果缺省: {,n}:最多n次
n如果缺省: {m,}最少m次
3.开始结束符号
^ 开始
$ 结尾
1.创建
1.var reg = new RegExp("正则表达式");
2.var reg = /正则表达式/;
2.方法
test():验证指定的字符串是否符合正则定义的规范
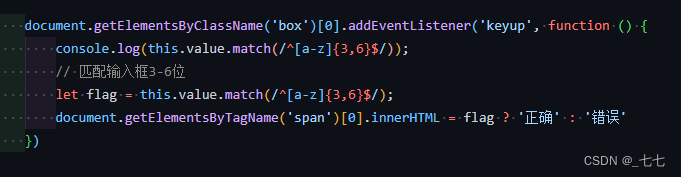
案例1:JS 正则表达式 获取小括号 中括号 花括号内的内容(包含括号)
var str = "12【开始】3{xxxx}456[我的]789123[你的]456(1389090)78【结束】9";
var regex1 = /\((.+?)\)/g; // () 小括号
var regex2 = /\[(.+?)\]/g; // [] 中括号
var regex3 = /\{(.+?)\}/g; // {} 花括号,大括号
var regex4 = /\【(.+?)\】/g; // {} 中文大括号
// 输出是一个数组
console.log(str.match(regex1)); // ["(1389090)"]
console.log(str.match(regex2)); // ["[我的]", "[你的]"]
console.log(str.match(regex3)); // ["{xxxx}"]
console.log(str.match(regex4)); // ["【开始】", "【结束】"]
案例2:正则表达式匹配括号中的字符,不包括括号
(?<=exp)是以exp开头的字符串, 但不包含本身.
(?=exp)就匹配为exp结尾的字符串, 但不包含本身.
var str = "12【开始】3{xxxx}456[我的]789123[你的]456(1389090)78【结束】9";
var regex1 = /(?<=\()(.+?)(?=\))/g; // () 小括号
var regex2 = /(?<=\[)(.+?)(?=\])/g; // [] 中括号
var regex3 = /(?<=\{)(.+?)(?=\})/g; // {} 花括号,大括号
var regex4 = /((?<=\【)(.+?)(?=\】))/g; // {} 中文大括号
// 输出是一个数组
console.log(str.match(regex1)); // ["1389090"]
console.log(str.match(regex2)); // ["我的", "你的"]
console.log(str.match(regex3)); // ["xxxx"]
console.log(str.match(regex4)); // ["开始", "结束"]

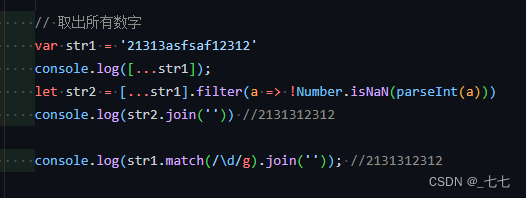
2. 字面量创建正则 / /
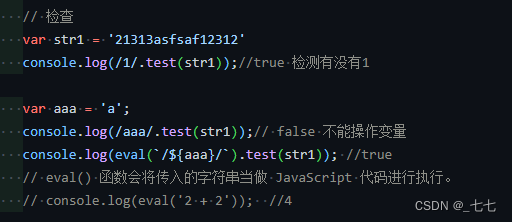
3. 正则对象 new RegExp
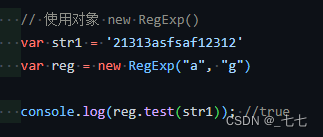
使用变量
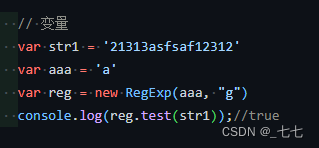
高亮替换对象

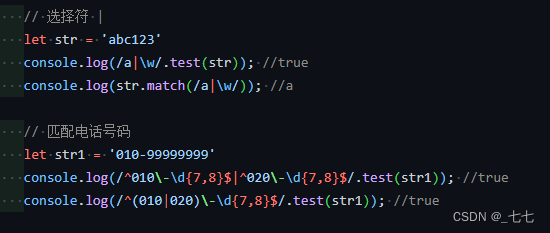
4. 选择符 |
5. 原子表[]和原子组()
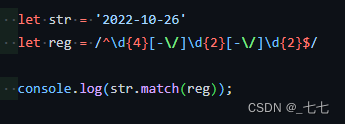
原子表 []
出现啥要啥
比如[,-.21] 出现 ,-.21 都需要
区间匹配/[0-9]/ /[a-z]/
排除匹配 /^123/ 排除匹配字符123
匹配所有字符 /[\s\S]/ /[\d\D]/
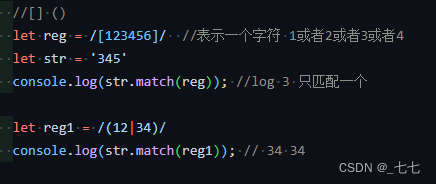
原子组()
正则表达式中的小括号"()"。是代表分组的意思。
如果再其后面出现\1,则是代表与第一个小括号中要匹配的内容相同。
生成组编号,\2就是顺序第二个。
注意:\1必须与小括号配合使用
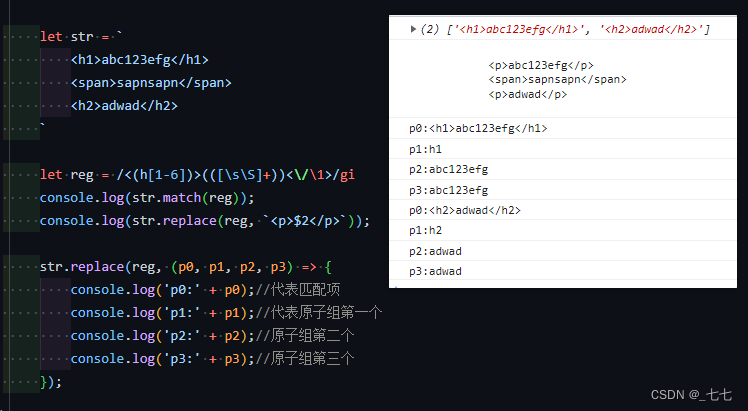
原子组匹配,[0]为正则匹配内容,[1]为原子组匹配内容
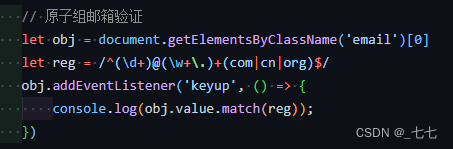
使用原子组匹配邮箱
原子组引用$完成替换
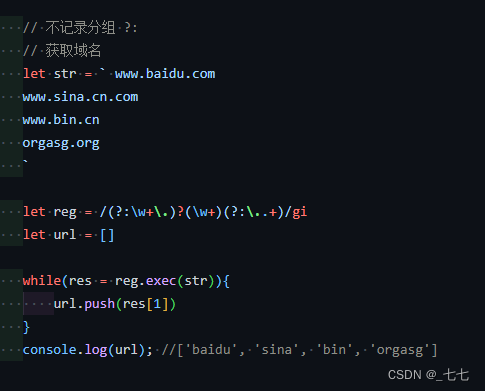
不记录分组 ?:
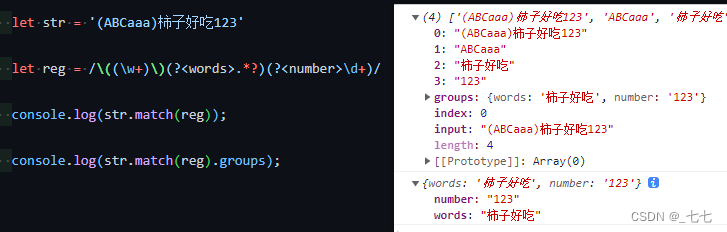
原子组别名 ?<>
6. 转义 \

7. 字符的边界^ $
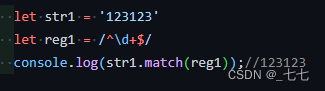
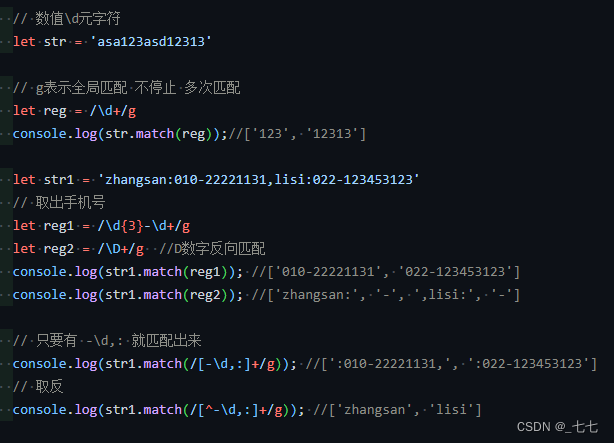
8. 数字\d元字符 和 空白\s元字符
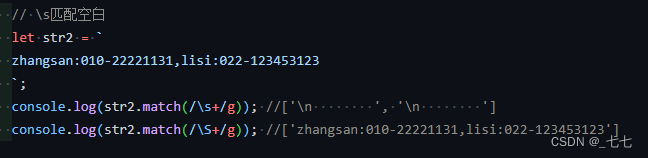
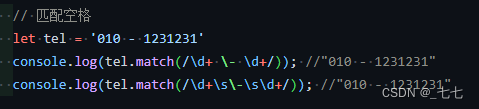
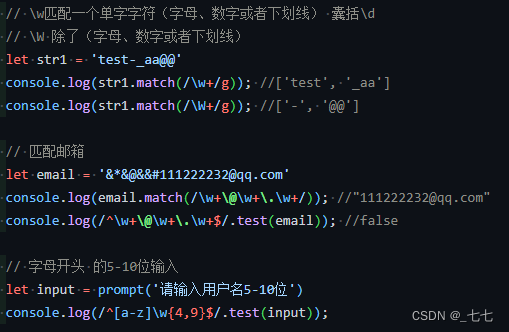
9. \w匹配一个单字字符(字母、数字或者下划线) 囊括\d
10. . 点字符(小数点)匹配除换行符之外的任何单个字符
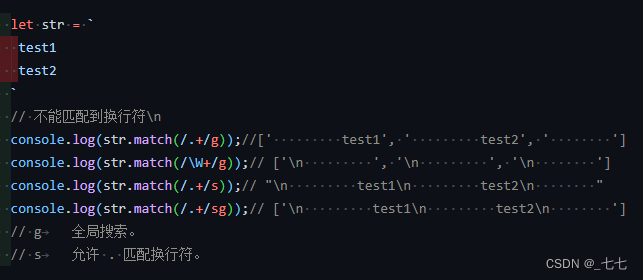
11. 精确匹配所有字符

12. i与g模式修正符

13. m多行搜索匹配符
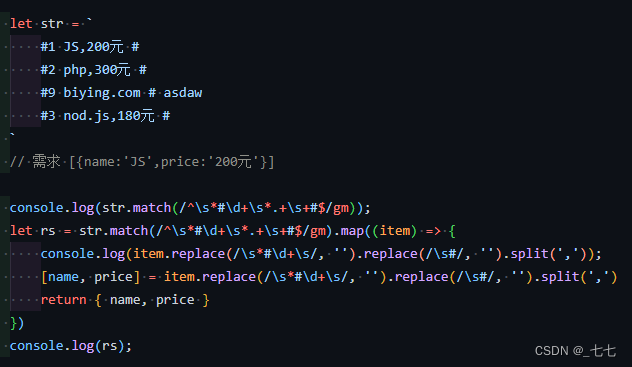
14. 字符属性
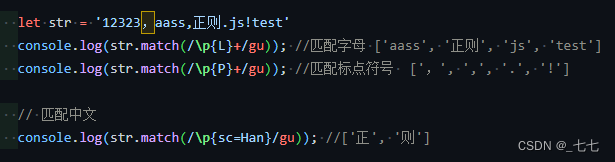
当使用不确定字符集的时候 也是用u
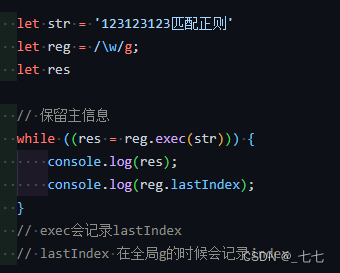
15. lastIndex属性
lastIndex 属性用于规定下次匹配的起始位置。
上次匹配的结果是由方法RegExp.exec() 和 RegExp.test() 找到的,它们都以 lastIndex 属性所指的位置作为下次检索的起始点。这样,就可以通过反复调用这两个方法来遍历一个字符串中的所有匹配文本。
重要事项:不具有标志 g 和不表示全局模式的 RegExp 对象不能使用 lastIndex 属性。
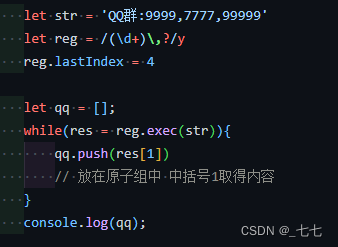
16. y模式
y 执行“粘性 (sticky)”搜索,匹配从目标字符串的当前位置开始。
17. s模式 允许 . 匹配换行符
18. 批量使用正则every
批量使用正则对密码校验 使用every

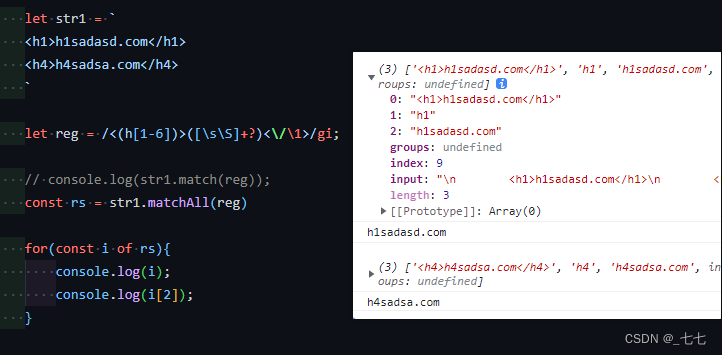
19. matchAll 全局匹配
matchAll 返回一个iterator
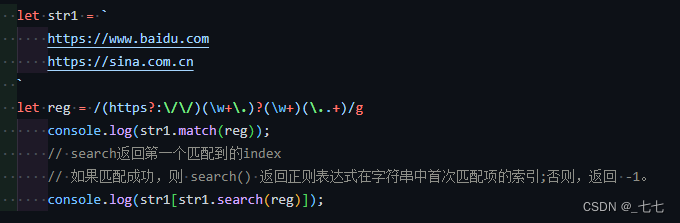
20. match和search的区别
match():方法检索返回一个字符串匹配正则表达式的结果。
search():如果匹配成功,则 search() 返回正则表达式在字符串中首次匹配项的索引;否则,返回 -1。

21. split()使用正则

22. $ `、$ '、$&

23.断言匹配
?= 先行断言,以什么结尾
?<=后行断言,以什么开始
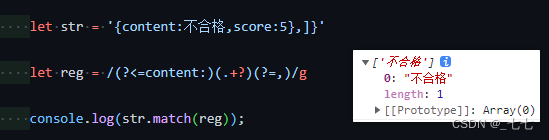
?! 先行否定断言 判断后面不是什么
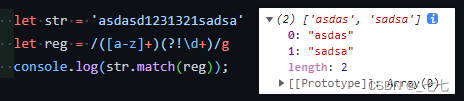
?<!后行否定断言 前面不是什么

小结
比如,只匹配百分号之前的数字,要写成 /\d+(?=%)/
/\d+(?=%)/.exec('100% of US presidents have been male') // ["100"]
只匹配不在百分号之前的数字,要写成 /\d+(?!%)/
/\d+(?!%)/.exec('that’s all 44 of them') // ["44"]
只匹配美元符号之后的数字,要写成 /(?<=\$)\d+/
/(?<=\$)\d+/.exec('Benjamin Franklin is on the $100 bill') // ["100"]
只匹配不在美元符号后面的数字
/(?<!\$)\d+/.exec('it’s is worth about €90') // ["90"]














 1420
1420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









