







文章目录
- 0. 理论
- 1. JMeter 常用命令
- 2. 配置环境变量
- 3. 配置内存
- 4. shell常用命令
- 5. 跳板机-压力机
- 6. 配置示例
- 7. 元件执行顺序
- 8. 线程组
- 9. Jmeter的HTTP请求
- 10. Jmeter断言
- 11. Jmeter关联(同一线程组关联)
- 12. Jmeter参数化(重点)
- 13. Jmeter属性(跨线程组关联)
- 14. Jmeter自动录制脚本
- 15. Jmeter直连数据库
- 16. JMeter逻辑控制器
- 17. JMeter定时器
- 18. JMeter分布式
- 19. JMeter测试报告
- 20. 性能测试时TPS计算
- 21. Jmeter下载第三方插件
- 22. 性能测试常用图表及组件
- 23.Concurrency Thread Group 和stepping thread group的区别
- 24. PerfMon组件监控服务器资源
- 25. 性能分析和调优
0. 理论
一、什么是性能测试以及性能测试的价值和目的
性能测试就是通过性能压测工具(jmeter,loadrunner),通过特定方式,对系统施加一定的压力:正常、异常负载以及峰值来对系统实施压力,得到各项性能指标。保证系统的性能需求。
价值和目的:
1.评估系统的能力
2.识别系统的弱点:瓶颈,弱点
3.检查系统的隐藏的问题
4.检验系统的稳定性和可靠性
二、性能测试指标理解透彻以及测算
- 【虚拟用户数】:线程=用户
- 【并发数】:指在某一时间,一定数量的虚拟用户同时对系统的某个功能进行交互。一般通过集合点实现。
- 【事务】:一个接口可以是事务,多个接口也可以是事务,一个流程可以是事务,事务代表一个完整的功能。由测试人员决定的。
- 【场景】:性能测试的用例
- 【响应时间】:Response Time
平均响应时间:
中位数:从小到大排序,选择第50个。
90%:从小到大排序,选择第90个。(具有参考价值)
95%:从小到大排序,选择第95个。
99%:从小到大排序,选择第99个。
基准测试:1个用户请求接口。200-500MS
压力测试:N个用户并发请求接口,2秒 - 【TPS】
TPS是系统的重要性能指标,用于衡量系统在一定时间内能够处理的事务数(交易数)。Transactions per sencond
计算公式:总的事务数/总的运行时间- 比如:某一系统1分钟处理1000个事务,那么TPS=1000/60=16.7
- 比如:按去年的经营数据,2022年最高的一天有10万笔交易。预测2023年TPS需要多少合格?
总事务数=10万,时间=24*60*60=86,400秒
理论上TPS = 100000/86400=1.2- (1)没有更详细的数据:根据二八定律(80%的事务在20%的时间完成)计算:
TPS = 100000 * 0.8 / 86400 * 0.2 = 80000/17280 = 4.6- (2)如果有更详细的数据:5万比交易是晚上的8-9点完成的。
TPS=50000/3600=13.9 - (3)考虑业务的增长:30%
TPS=(50000+50000*0.3)/3600=18
- 【QPS】每一秒的查询率。
说明:QPS(Query Per Second)每秒查询数
TPS,QPS,RPS HPS(每一秒的点击率) - 【吞吐量】
衡量网络成功传输的数量量,单位Byte/S - 【资源利用率】
服务器:CPU,内存,磁盘,网络。提示:通常,没有特殊需求的话
1). 建议CPU不高于80%(±5)
2). 内存不高于80%
3). 磁盘不高于90%
4). 网络不高于80%
卡的比较严错误率不超过0.1%
最大响应时间不能有超过2S
三、性能测试流程
1.需求分析以及需求确定(指标值,场景,环境,人员)
考虑合理
客户:OA,1万员工,并发一万。
产品经理:单台阿里云服务器。支撑1万并发。
项目组领导:3年之后需要达到什么样的性能。
2.性能测试计划和方案制定
-
基准测试:
- 狭义上讲:也是单用户测试,测试环境确定以后,对业务模型中的重要业务做单独的测试,获取单用户运行时的各项性能指标。(进行基础的数据采集)
- 广义上讲:是一种测量和评估软件性能指标的活动。你可以在某个时刻通过基准测试建立一个已知的性能水平(称为基准线),当系统的软硬件环境发生变化之后再进行一次基准测试以确定那些变化对性能的影响。
-
基准测试数据的用途:
1. 为多用户并发测试和综合场景测试等性能分析提供参考依据
2. 识别系统或环境的配置变更对性能响应带来的影响
3. 为系统优化前后的性能提升/下降提供参考指标 -
负载测试:
- 说明:通过逐步增加系统负载,测试系统性能的变化,并最终确定在满足系统的性能指标情况下,系统所能够承受的最大负载量的测试。
- 负载:指向服务器发送的请求数量,请求越多,负载越高
- 注意:负载测试关注的重点是逐步增加压力
-
压力测试:
- 压力测试是在强负载(大数据量、大量并发用户等)下的测试,查看应用系统在峰值使用情况下操作行为,从而
有效地发现系统的某项功能隐患、系统是否具有良好的容错能力和可恢复能力。压力测试分为高负载下的长时间(如24小时以上)的稳定性压力测试和极限负载情况下导致系统崩溃的破坏性压力测试。
- 压力测试是在强负载(大数据量、大量并发用户等)下的测试,查看应用系统在峰值使用情况下操作行为,从而
-
稳定性测试:
- 稳定性测试是指,在服务器稳定运行(用户正常的业务负载下)的情况下进行长时间测试,并最终保证服务器能满足线上业务需求。时长一般为1天、一周等。
-
其他:配置测试,极限测试,浪涌测试
3.性能测试准备阶段
- 性能测试用例
- 测试脚本编写/录制
- 建立测试环境
人力,硬件,软件,环境折算。
测试时干净的环境。
4.测试执行阶段
- 执行测试脚本
- 性能测试监控
性能监控就是监控服务器的各项性能指标。例如:监控CPU、内存、网络、TPS、磁盘IO等 - 性能分析和调优
性能测试分析人员经过对结果的分析以后,有可能提出系统存在性能瓶颈。-
调优人员(开发人员、数据库管理员、系统管理员、网络管理员、性能测试分析人员)相关人员对系统进行调整;
-
验证-性能测试人员继续进行第二轮、第三轮……的测试,与以前的测试结果进行对比,从而确定经过调整以后系统的性能是否有提升。
系统调优由易到难的先后顺序如下:
- 硬件问题
- 网络问题
- 应用服务器、数据库等配置问题
- 源代码、数据库脚本问题
- 系统构架问题
-
5.测试报告和总结
1. JMeter 常用命令
1.1 启动命令
启动jemeter的脚本 生成日志和结果的命令
jmeter -n -t /home/test.jmx -l /home/amt/1500.jtl -e -o /home/amt/rs
example:
//绝对路径
/tmp/apache-jmeter-5.4.1/bin/jmeter -n -t /tmp/test_1008.jmx -l /tmp/lyh/1.jtl -e -o /tmp/lyh/rs
/home/test/apache-jmeter-5.4/bin/jmeter -n -t /home/test/rs/text.jmx -l /home/test/1000.jtl -e -o /home/test/rs
//结果打包
tar -zcf lyh.tar.gz /tmp/lyh/*
//解包
-zxf
1.2 设置中文
- 在 *\bin 的目录下找到 jmeter.properties,将“#language=en” 改成“language=zh_CN”
2. 配置环境变量
前提条件:安装JDK
2.1 windows
JAVA_HOME=C:\Program Files\Java\jdk1.8.0_151
path:
%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin
JMETER_HOME=F:\Jmeter\apache-jmeter-5.1.1
path:
%JMETER_HOME%\bin
%JMETER_HOME%\lib\ext\ApacheJMeter_core.jar;%JMETER_HOME%\lib\jorphan.jar;%JMETER_HOME%\lib\logkit-2.0.jar;
2.1.1 启动
JMeter启动有多种方式
- 进入JMeter安装目录下的bin目录,双击 jmeter.bat
- 双击 ApacheJMeter.jar 选择使用java程序打开
- 命令行输入:
java -jar ApacheJMeter.jar
2.1.2 JMeter文件目录
bin目录
jmeter.bat: windows的启动文件
jmeter.log: 日志文件
jmeter.sh: linux的启动文件
jmeter.properties: 系统配置文件
jmeter-server.bat: windows分布式测试要用到的服务器配置
jmeter-serve: linux分布式测试要用到的服务器配置
docs目录
- docs:是JMeter的api文档,可打开api/index.html页面来查看
printable_docs目录
- printable_docs的usermanual子目录下的内容是JMeter的用户手册文档
- usermanual下component_reference.html是最常用到的核心元件帮助文档。
提示:printable_docs的demos子目录下有一些常用的JMeter脚本案例,可以作为参考
lib目录
- 该目录用来存放JMeter依赖的jar包和用户扩展所依赖的jar包
2.2 linux
vi /etc/profile --在文件内容末尾追加
两种方式并没有太大差异,因为JAVA_HOME的值没有包含特殊字符或空格。但是在更复杂的情况下,使用${}的方式可能会更安全,因为它可以帮助区分变量名和其他文本,避免歧义。
方式一:
export JAVA_HOME=/lyh/java/jdk1.8.0_221 --(自定义jdk安装目录)
export PATH=$JAVA_HOME/bin:$PATH
exportCLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JMETER_HOME=/jmeter/jmeter-3.2
export CLASSPATH=$JMETER_HOME/lib/ext/ApacheJMeter_core.jar:$JMETER_HOME/lib/jorphan.jar:$CLASSPATH
export PATH=$JMETER_HOME/bin:$PATH
方式二:使用${}的方式更加规范和安全
export JAVA_HOME=/home/lyh/jre1.8.0_301
export JRE_HOME=${JAVA_HOME}/jre
export PATH=${JAVA_HOME}/bin:$PATH
export CLASSPATH=.:{JAVA_HOME}/lib:${JRE_HOME}/lib
export JMETER_HOME=/jmeter/jmeter-3.2
export CLASSPATH=$JMETER_HOME/lib/ext/ApacheJMeter_core.jar:$JMETER_HOME/lib/jorphan.jar:$CLASSPATH
export PATH=$JMETER_HOME/bin:$PATH
最后一步:启用配置
source /etc/profile
3. 配置内存
修改jmeter.sh
在大并发的测试中,我们需要的大量的内存来执行压力测试,而JMeter在默认情况下的内存分配非常低,我们需要自己把该项配置的最大堆修改成合适的值
根据负载机的内存来决定该项的值为多少。在前面我们查询了内存为1.6GB,所以我们设置成1GB。一般建议设置为内存的80%。例如一台8GB的负载机,我们可以设置为6GB。
3.1 jmeter启动脚本配置内存
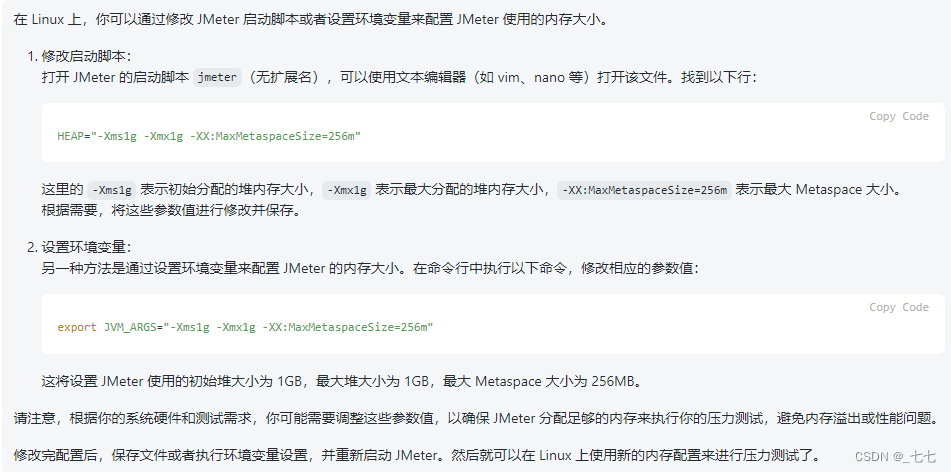
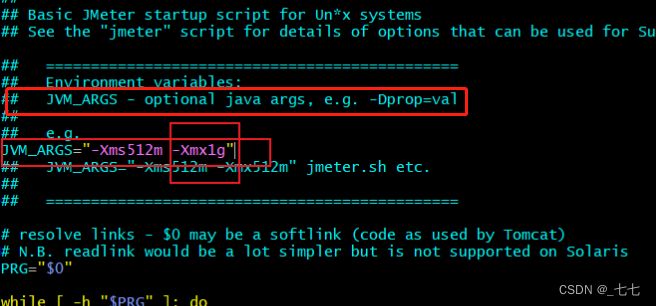
3.2 jmeter.sh修改内存
vim jmeter.sh
找到JVM-ARGS,复制该行,去除注释,将512m修改为合适的大小
4. shell常用命令
chmod 777 target_file -- 赋予权限
tar xzvf target_file -- 解压
unzip apache-jmeter-5.4.1.zip --解压
tar -zcf 1.tar.gz /tmp/lyh/* --压缩打包
source /etc/profile -- 使配置文件生效
java -version -- 检查java版本
jmeter --version -- 检查jmeter环境
free -h -- 查看Linux内存
uname -a -- Linux系统架构
yum install -y ibus-libpinyin --安装拼音
rz -be target_file -- 上传文件夹
mkdir -- 创建文件夹
sz --下载命令
zip -r -q 目标名称 被打包目录/文件 --打包压缩
mv test1-njzj\(1\).jmx test1-njzj.jmx --修改名字
mv test1-njzj.jmx /web/jmeter/ --移动目录
chown root:root test1-njzj.jmx --修改权限
chmod a+x test1-njzj.jmx --修改权限
5. 跳板机-压力机
跳板机 创建好了 直接在跳板机中 ssh ip 直接跳转到压力机
登录脚本 跳板机自动登录账号密码
$ ssh 113.xxx.200.90
password: xxxc
跳板机-压力机文件传输方式
5.1 跳板机到压力机后,如何本地直接访问压力机传文件(XSHELL与XFTP)
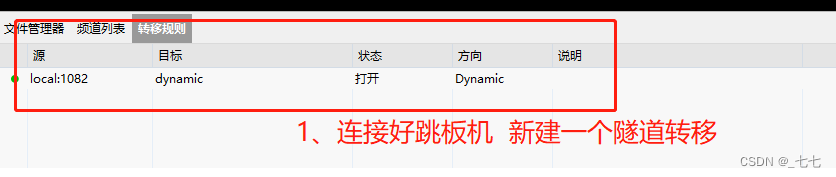
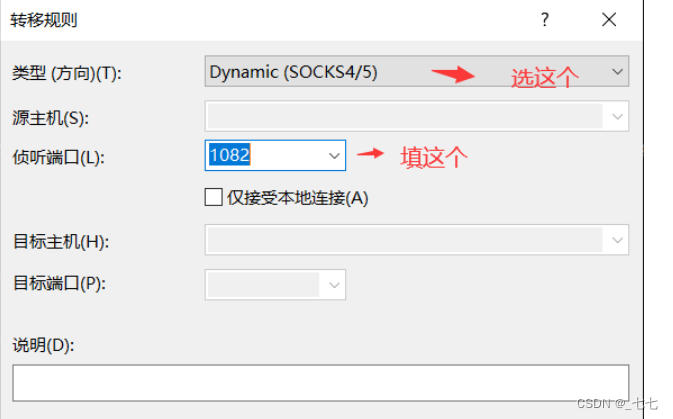
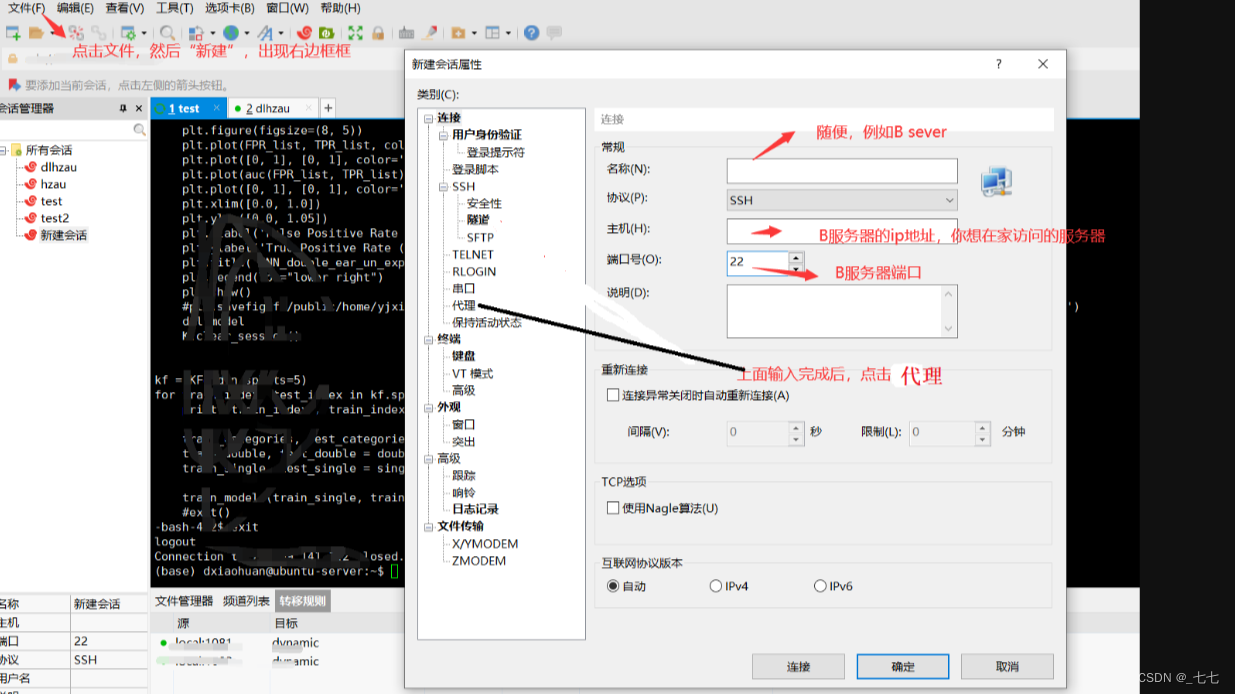
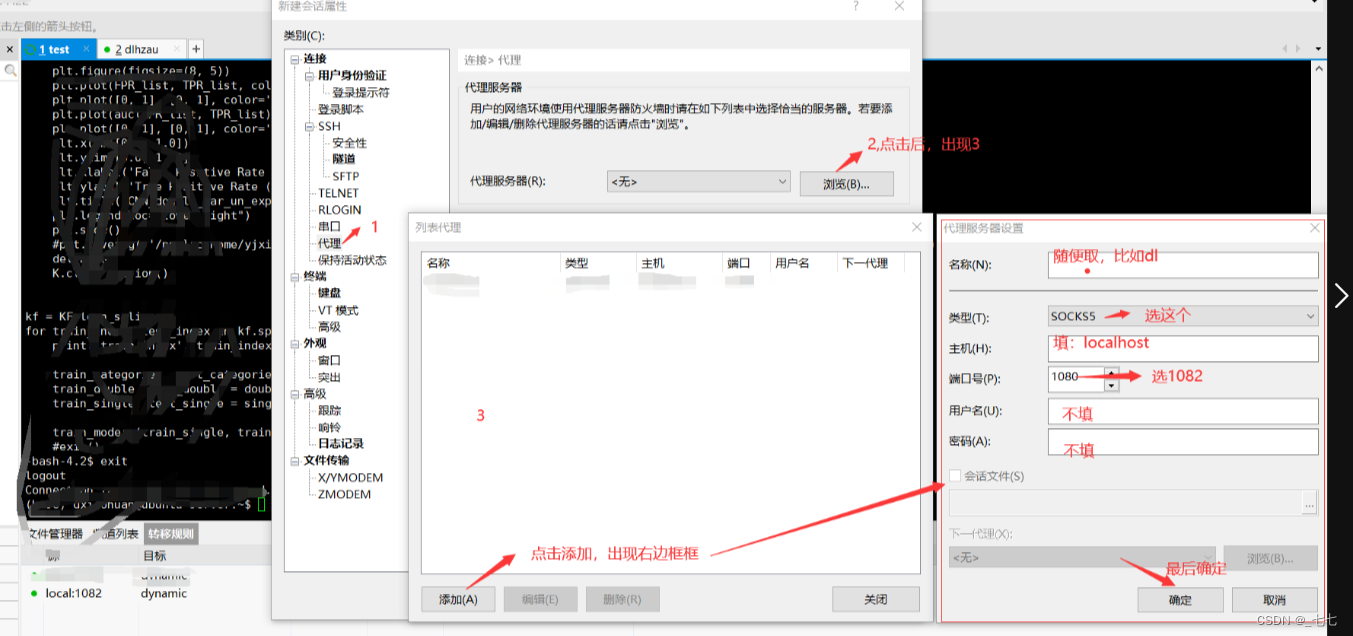
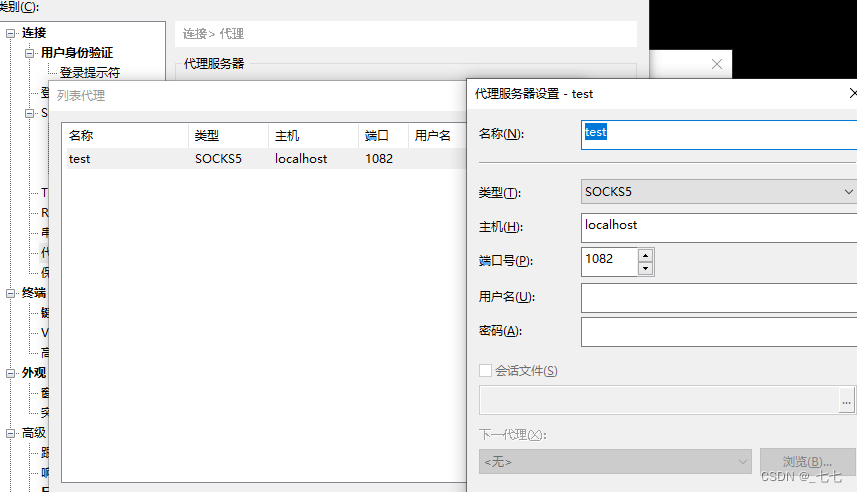
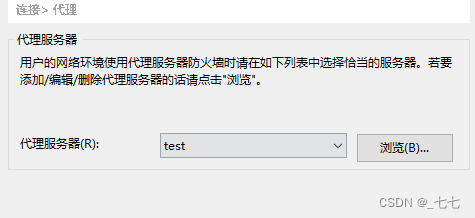
5.2 rz -be
压力机使用 rz -be,将本机文件上传到压力机上
rz -be 是一个Linux命令,用于从本地计算机上传文件到远程服务器。
这些命令通常在基于终端的SSH会话中使用,用于文件传输。
- -b 参数表示二进制模式传输文件。这意味着文件将以原始二进制格式进行传输,而不会进行字符编码转换。
- -e 参数表示使用Escape序列来控制文件传输。这个选项在某些终端程序中可能需要设置,以确保正确的文件传输。
5.3 scp [参数] [来源文件] [目标位置]
-
scp 文件 user@压力机ip:压力机目录
-
[参数] 可以是一些选项,比如 -r 表示递归复制整个目录。
-
[来源文件] 是指要传输的文件或目录。
-
[目标位置] 是指文件或目录将要保存到的位置。
-
scp "C:\Users\Administrator\Desktop\1.jmx" user@172.17.8.8:/home/user/lyh/
5.4 ftp命令
ftp 命令是用于在计算机网络中进行文件传输的标准网络协议。它允许用户在客户端和服务器之间传输文件。
ftp [选项] [主机名]
一旦连接到 FTP 服务器,你可以在 FTP 命令提示符下输入各种命令来执行文件传输操作。以下是一些常用的 ftp 命令:
- open 主机名:打开与指定主机的 FTP 连接。
- user 用户名 密码:使用指定的用户名和密码进行身份验证。
- get 文件名:从服务器下载指定的文件到本地计算机。
- put 文件名:将本地计算机上的文件上传到服务器。
- cd 目录:更改服务器上的当前目录。
- ls:列出当前服务器目录中的文件和子目录。
- mkdir 目录名:在服务器上创建一个新的目录。
- delete 文件名:删除服务器上的指定文件。
- quit 或 bye:断开与服务器的连接并退出 ftp 会话。
这只是 ftp 命令的一些基本用法示例。实际上,ftp 命令提供了更多的选项和功能,如设置传输模式(二进制或文本)、被动模式、重命名文件等。你可以通过在 ftp 命令提示符下输入 help 或 ? 来获取更多帮助信息,了解所有可用的命令和选项。
需要注意的是,由于 ftp 是明文传输协议,不提供数据加密,因此在安全性要求较高的情况下推荐使用更加安全的协议,如 sftp(基于 SSH)或 ftps(基于 SSL/TLS)来进行文件传输。
6. 配置示例
阶梯压测
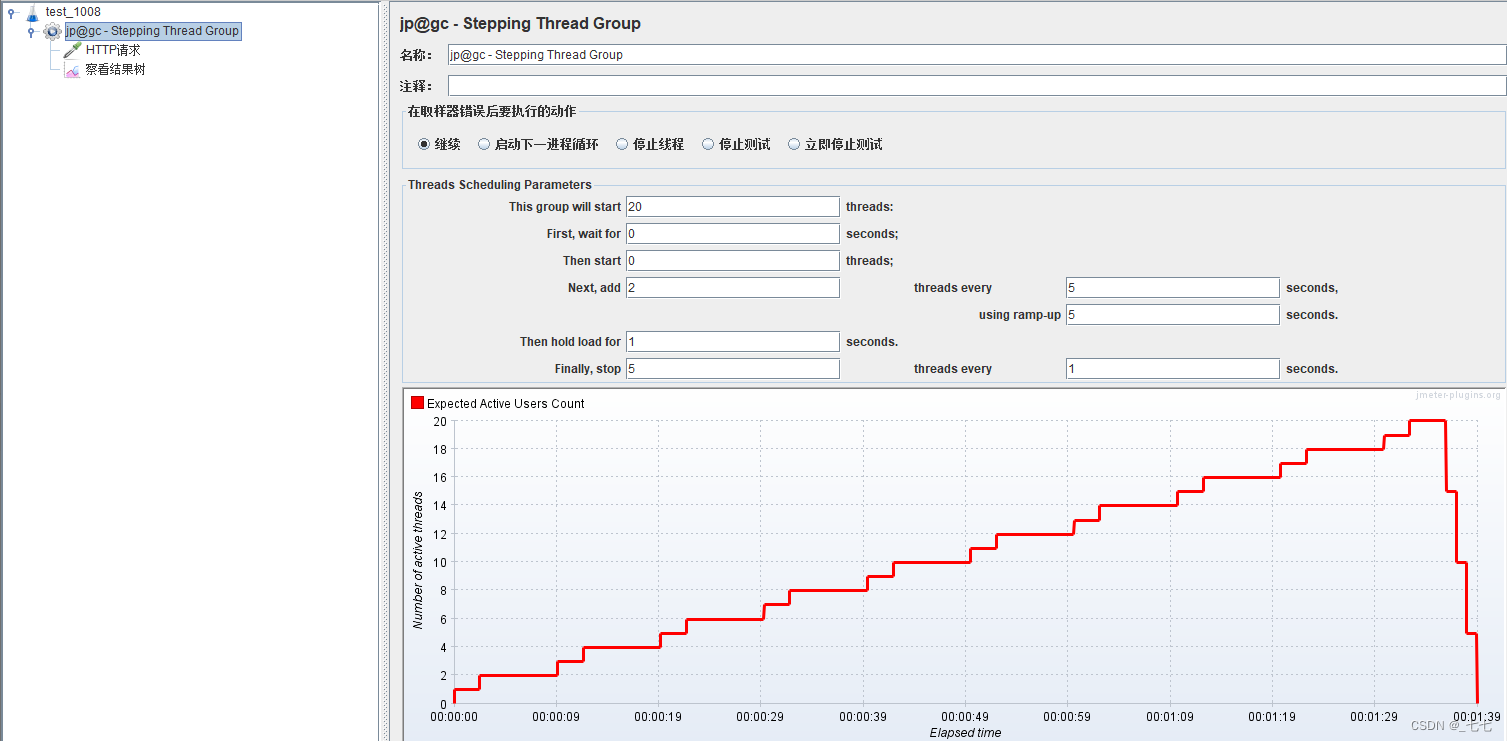
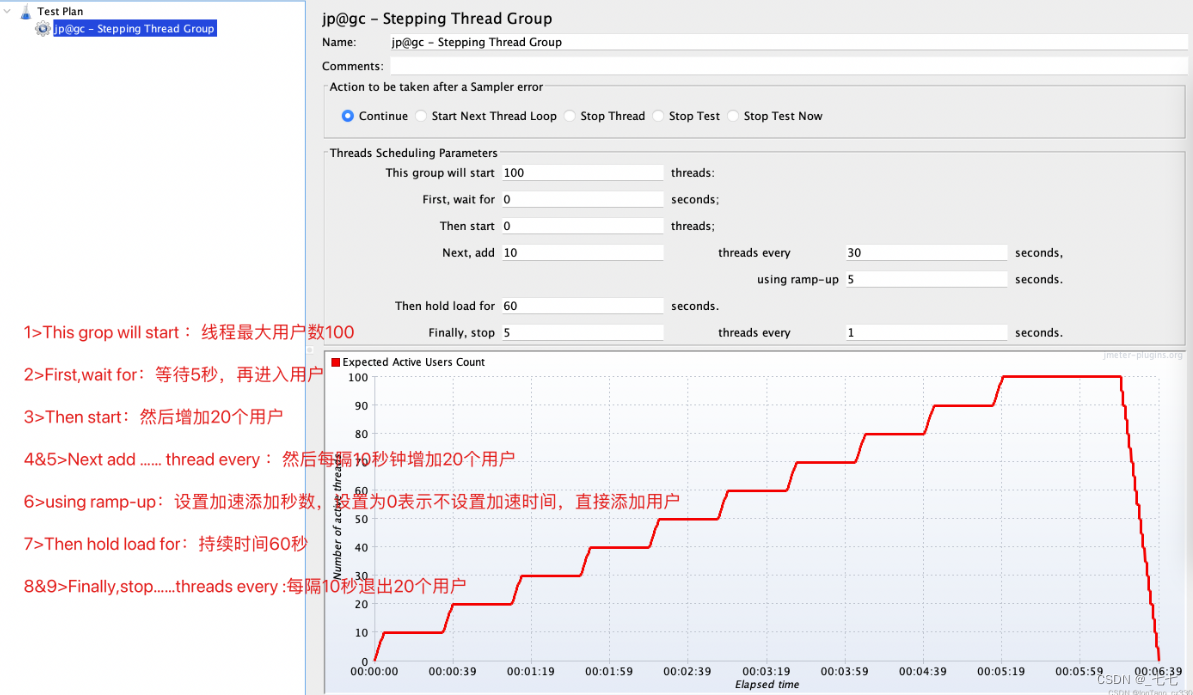
1000线程并发持续5分钟
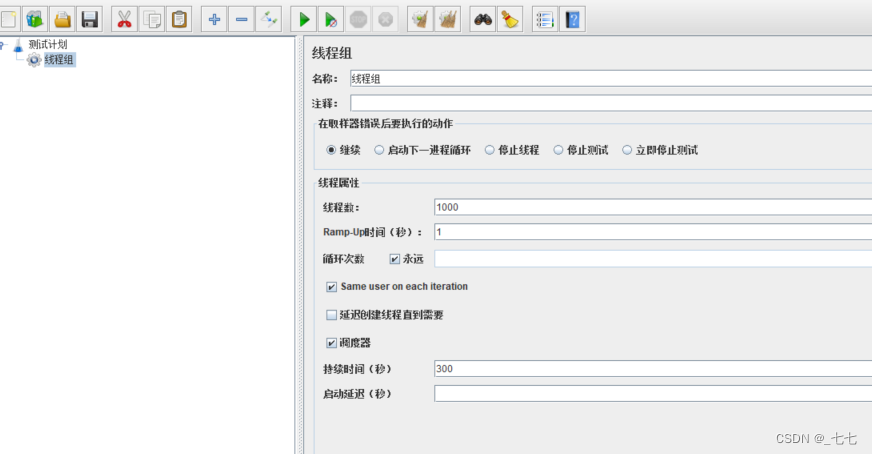
1000用户登录,使用不同金额访问接口
某支付系统,需要用1000个不同的用户登录,并使用添加不同的测试金额数据访问支付接口?
添加线程组
添加配置元件 - CSV数据文件设置,读取CSV文件数据中的用户名密码
添加HTTP请求 - 登录,引用CSV数据文件设置中的变量
添加HTTP请求 - 支付,使用counter函数传入不同金额的测试数据
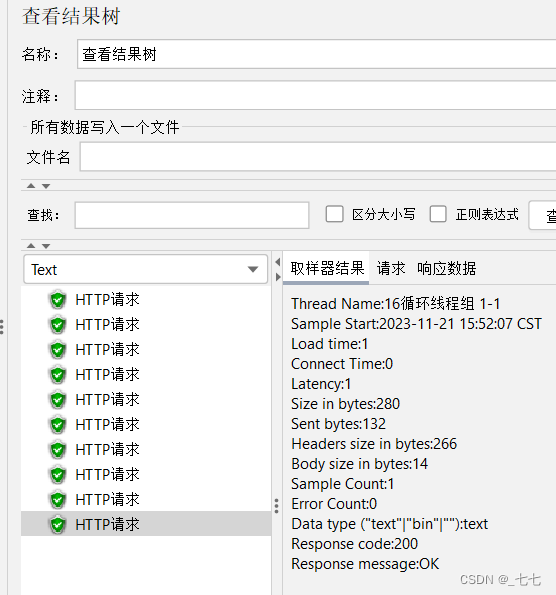
添加查看结果树
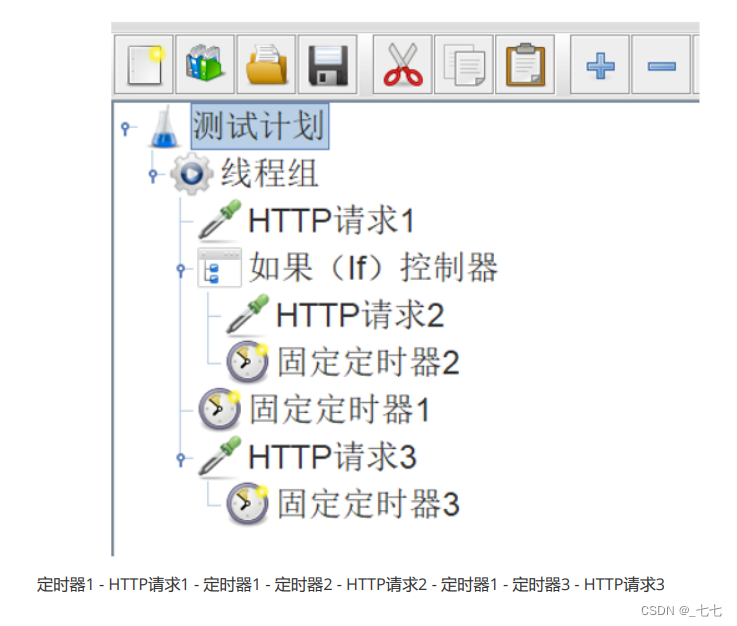
7. 元件执行顺序
- 配置元件(config elements)
- 前置处理程序(Per-processors)
- 定时器(timers)
- 取样器(Sampler)
- 后置处理程序(Post-processors)
- 断言(Assertions)
- 监听器(Listeners)
提示:
- 前置处理器、后置处理器、断言等元件功能对取样器起作用(如果在它们的作用域内没有任何取样器,则不会被执行)
- 如果在同一作用域范围内有多个同一类型的元件,则这些元件按照它们在测试计划中的上下顺序依次执行
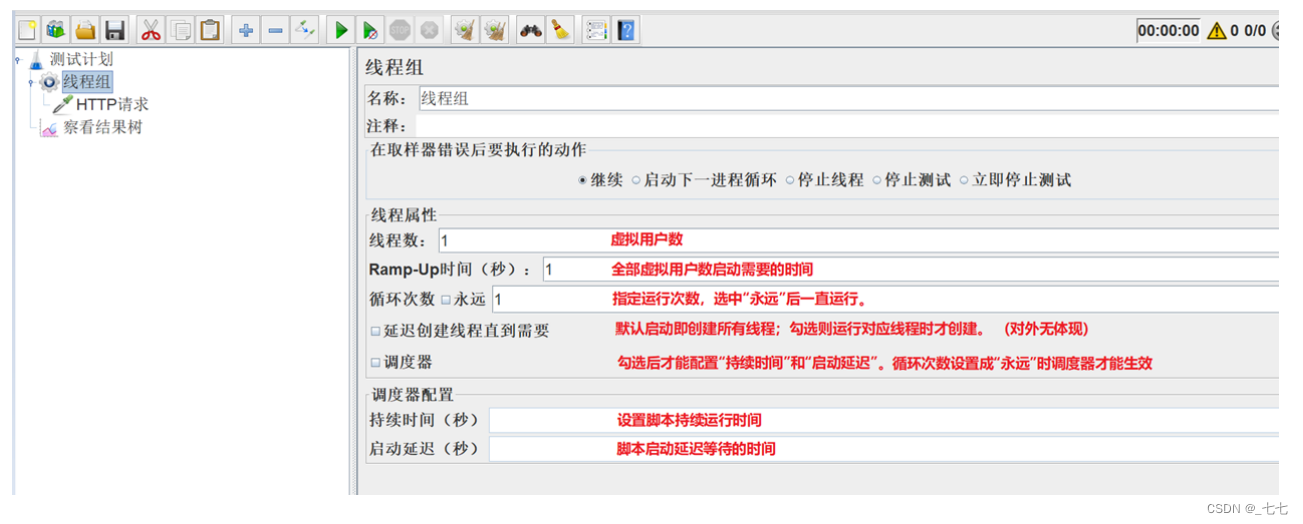
8. 线程组
1. 线程组
- 说明:线程组是控制JMeter将用于执行测试的线程数,也可以把一个线程理解为一个测试用户。
- 线程组的特点
模拟多人操作
线程组可以添加多个,多个线程组可以并行或串行
取样器(请求)和逻辑控制器必须依赖线程组才能使用
线程组下可以添加其他元件下组件
2. 线程组的分类
- setup线程组:前置处理,初始化
- 普通线程组:编写脚本
- teardown线程组:后置处理,环境恢复等
3. 参数介绍
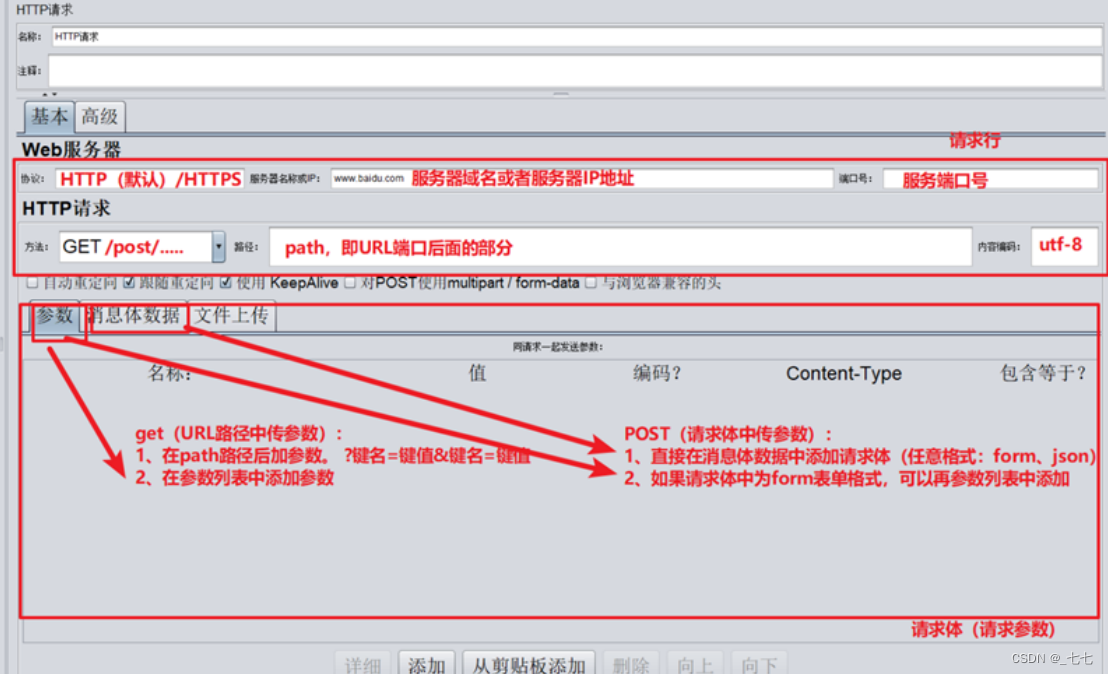
9. Jmeter的HTTP请求
参数介绍:
作用:向服务器发送http及https请求
查看结果树
第一个HTTP请求中,URL错误,导致服务器产生了重定向,提供了新的URL路径
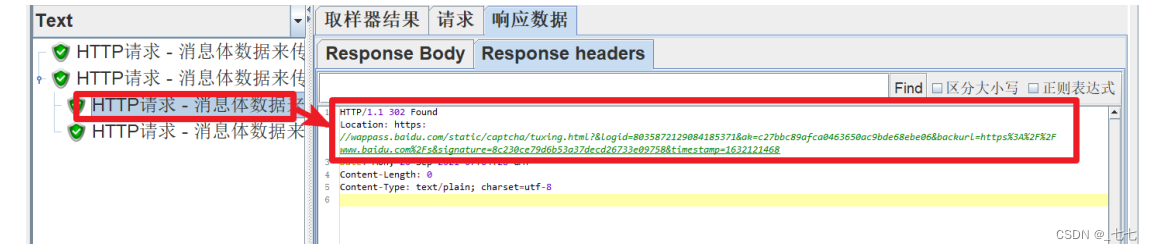
JMeter会自动发送第二个HTTP请求(使用第一个HTTP请求中返回的URL路径)
点击最外层HTTP请求时,显示的内容与最后一个HTTP请求的请求和响应数据一致
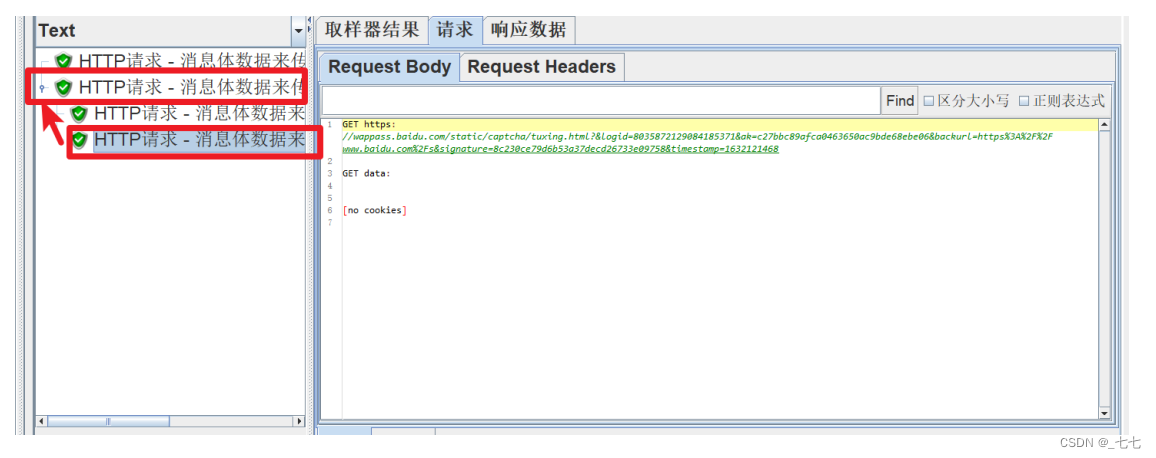
HTTP响应数据中存在乱码
要修改取样器结果的编码格式

10. Jmeter断言
断言:让程序自动判断预期结果和实际结果是否一致。
- JMeter在请求的返回层面有个自动判断机制(响应状态码)
- 自动校验机制:Jmeter会自动判断响应状态码(2xx:成功,4xx/5xx:失败)
- 但是请求成功了,并不代表结果一定正确,因此需要检测机制提高测试准确性。
JMeter中常用断言
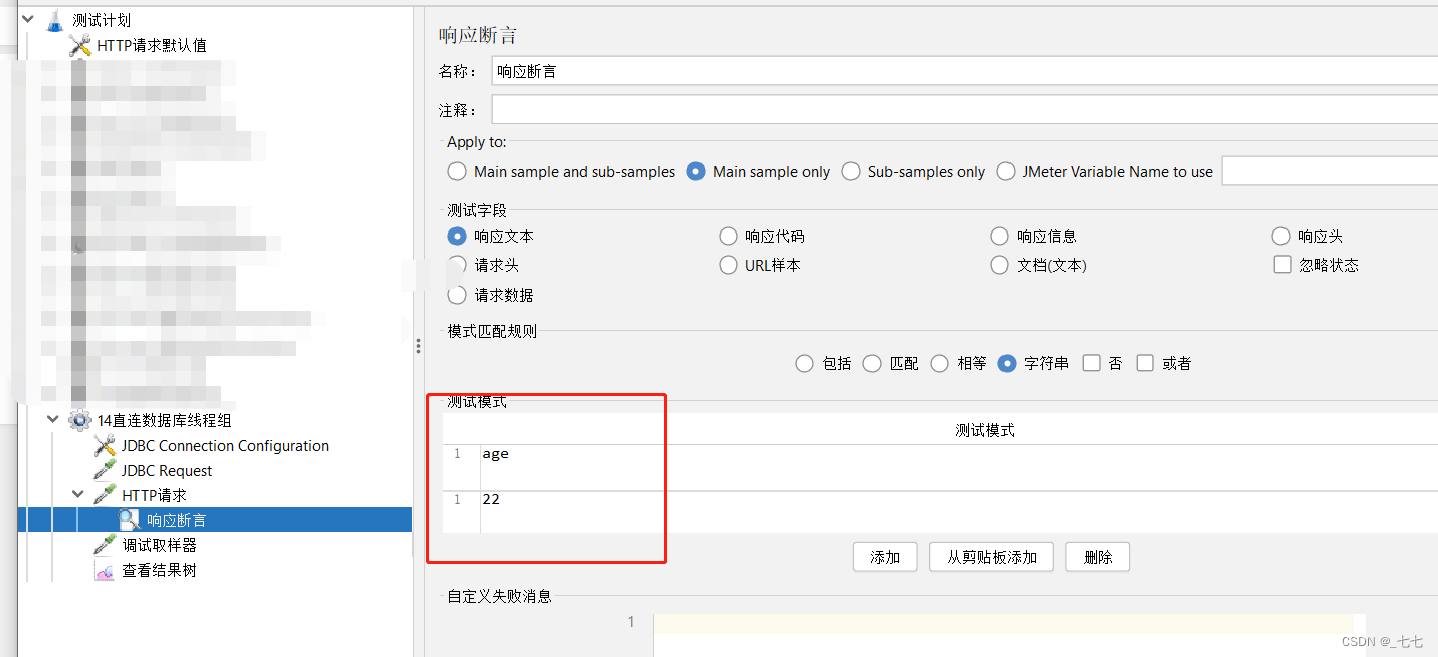
- 响应断言
- 场景:可以针对任意格式的响应数据进行断言
- JSON断言
- 场景:当响应数据为JSON格式时,优先使用JSON断言
- 持续时间断言(Duration Assertion)
- 场景:检查HTTP请求的响应时间是否满足要求时,使用断言持续时间
1.响应断言
(1)什么时候可以使用响应断言?
- 任意HTTP请求的响应结果,都可以使用响应断言
(2)使用“响应断言”的操作步骤?
- 添加线程组
- 添加HTTP请求
- 添加响应断言
• 测试字段:要检查的项(实际结果)
• 模式匹配规则:比较方式
• 测试模式:预期结果 - 添加查看结果树
添加方式:测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> 响应断言
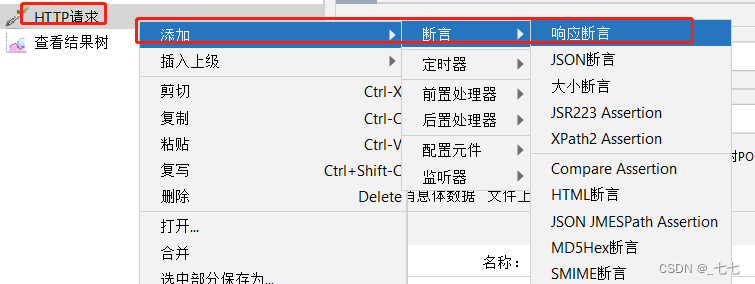
场景:
请求:https://www.baidu.com
检查:让程序检查响应数据中是否包含“百度一下,你就知道”
操作步骤:
1.添加线程组
2.添加HTTP请求
3.添加响应断言
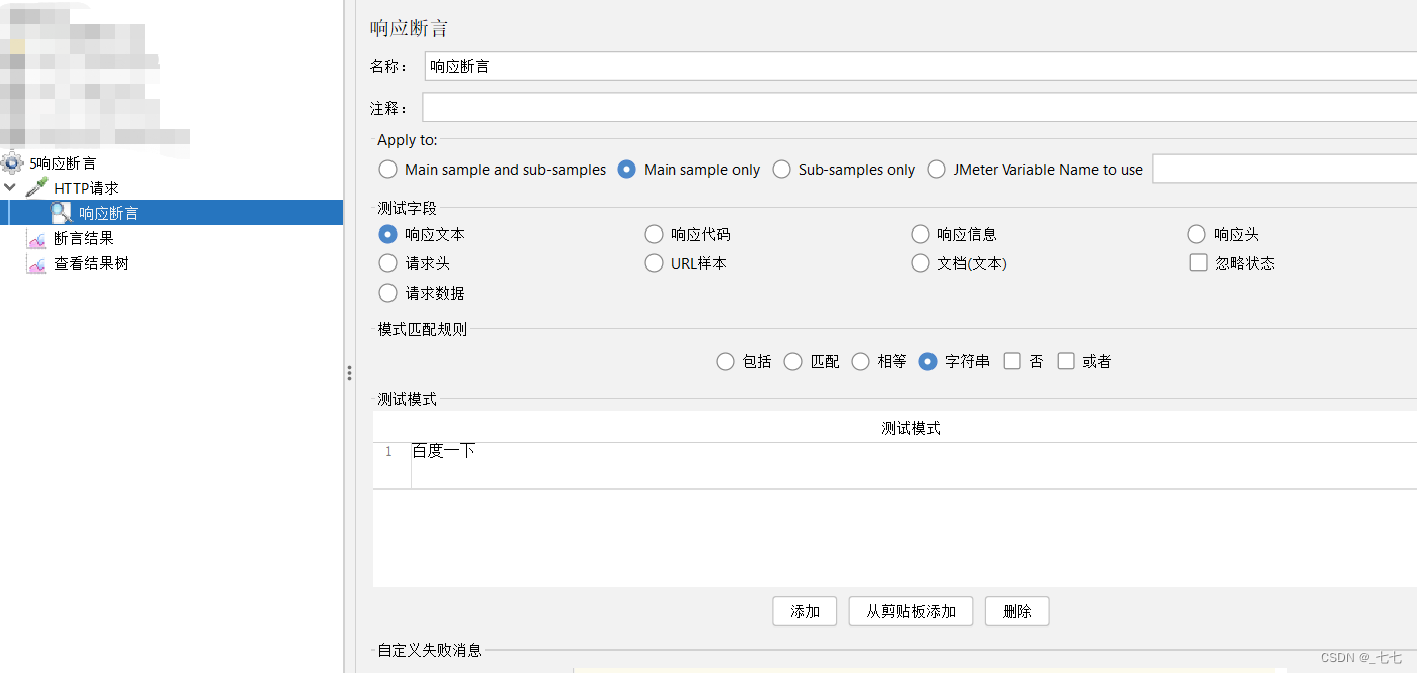
4.添加断言结果
5.添加查看结果树
失败场景:
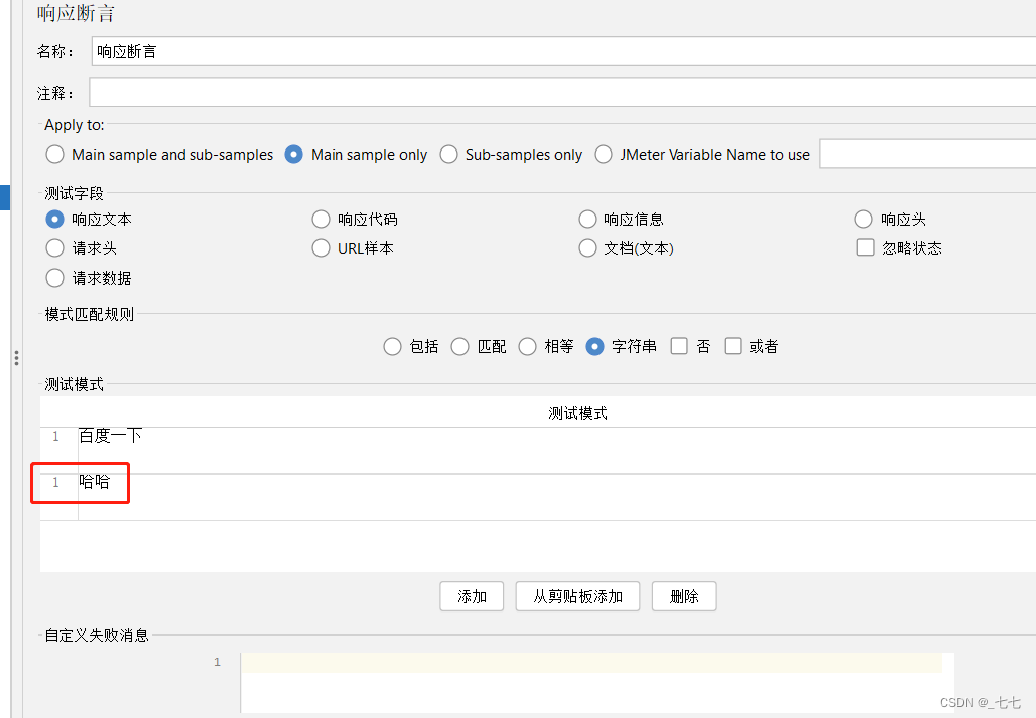
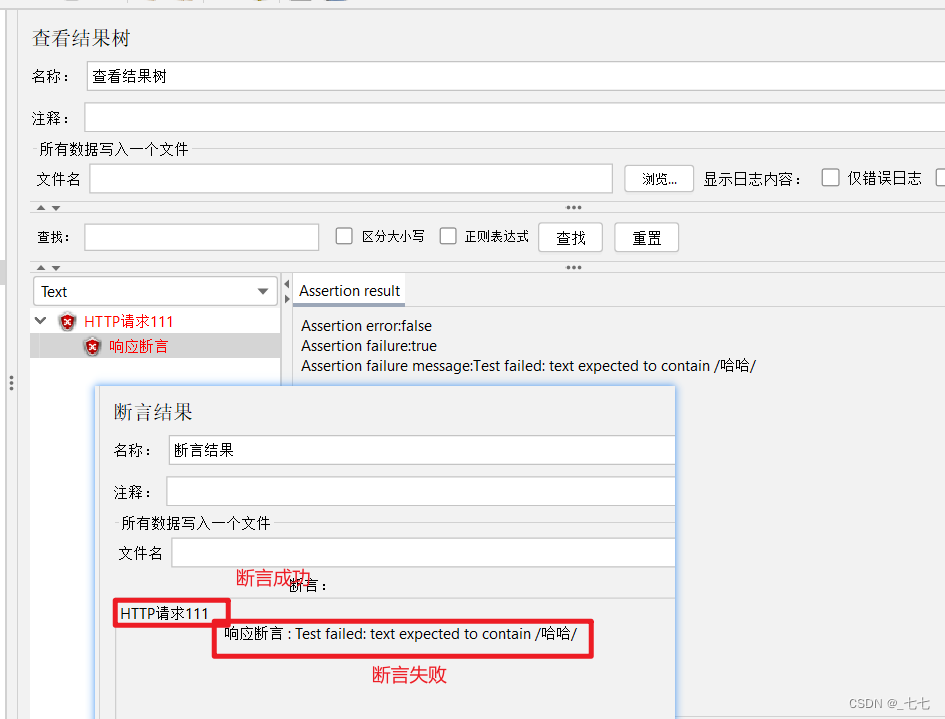
参数详解
Apply to:适用范围
- Main sample and sub-samples: 作用于父节点取样器及对应子节点取样器;
- Main sample only: 仅作用于父节点取样器;
- Sub-samples only: 仅作用于子节点取样器;
- JMeter Variable: 作用于jmeter变量(输入框内可输入jmeter的变量名称);
测试字段:要检查的项
- 响应文本: 来自服务器的响应文本,即主体,不包括任何HTTP头
- 响应代码: 响应的状态码,例如:200
- 响应信息: 响应的信息,例如:OK
- Response Headers: 响应头部
- Request Headers: 请求头部
- Request Data: 请求数据
- URL样本: 响应的URL
- Document(text): 响应的整个文档
- 忽略状态:忽略返回的响应状态码
模式匹配规则
- 包括:文本包含指定的正则表达式
- 匹配:整个文本匹配指定的正则表达式
- Equals:整个返回结果的文本等于指定的字符串(区分大小写)
- Substring:返回结果的文本包含指定字符串(区分大小写)
- 否:取反
- 或者:如果存在多个测试模式,勾选代表逻辑或(只要有一个模式匹配,则断言就是OK),不勾选代表逻辑与(所有都必须匹配,断言才是OK)
注意:Equals和Substring模式是普通字符串,而不是正则表达式
测试模式
即填写你指定的结果(可填写多个),按钮【添加】、【删除】是进行指定内容的管理
2. JSON断言
(1)什么时候可以使用JSON断言?
- 对HTTP请求的响应结果为JSON格式时,可以使用JSON断言
(2)使用“JSON断言”的操作步骤?
- 添加线程组
- 添加HTTP请求
- 添加JSON断言
• 填写Assert JSON Path exists(实际结果-json路径)
• 勾选Additionally assert value
• 填写Expected Value(期望结果) - 添加查看结果树
作用:对HTTP请求的JSON格式的响应结果进行断言
添加方式:测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> JSON断言
场景
检查:让程序检查响应的JSON数据中,city对应的内容是否为“北京”
操作步骤
1.添加线程组
2.添加HTTP请求
3.添加JSON断言
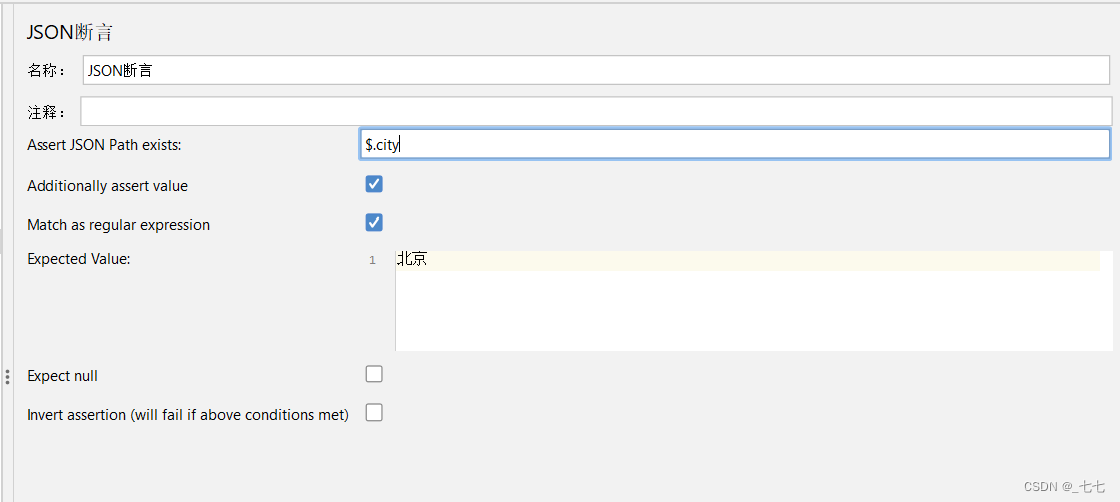
参数介绍
- Assert JSON Path exists:用于断言的JSON元素的路径(实际结果)
- Additionally assert value:如果您想要用某个值生成断言,请选择复选框
- Match as regular expression:使用正则表达式断言
- Expected Value:期望值(期望结果)
- Expect null:如果希望为空,请选择复选框
- Invert assertion (will fail if above conditions met):反转断言(如果满足以上条件则失败)
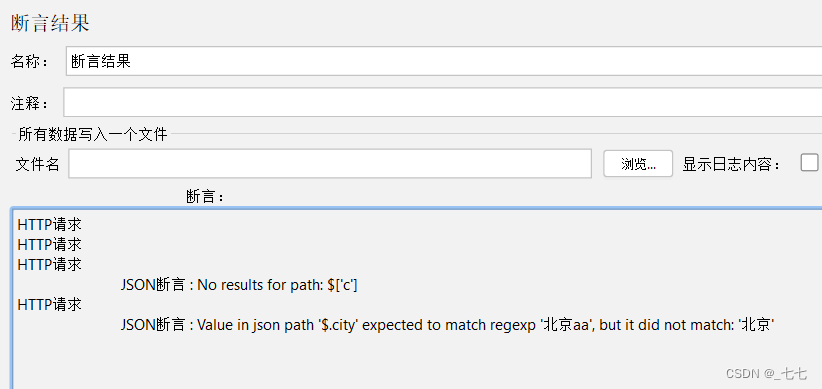
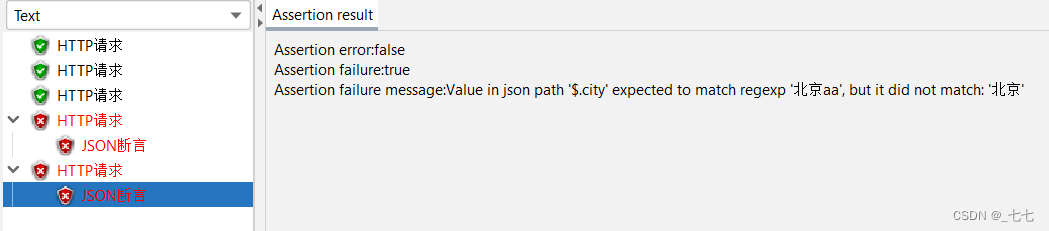
4.添加断言结果
5.添加查看结果树
断言失败场景:
JsonPath语法介绍
JsonPath 是一种用于查询和提取 JSON 数据中特定元素的语法。它类似于 XPath,但适用于 JSON 格式的数据。
以下是 JsonPath 的一些常见语法:
1. `$`:表示根节点。使用 `$` 可以指向整个 JSON 结构。
2. `.`:表示当前节点。可以使用 `.key` 或 `.['key']` 来指向当前节点下的某个属性。
3. `..`:表示递归下降。可以使用 `..key` 来匹配深层嵌套结构中的某个属性。
4. `*`:表示通配符。可以使用 `*` 来匹配任意节点。
5. `[]`:表示筛选器。可以使用 `[expression]` 来筛选符合条件的节点。例如,`[0]` 表示选择数组的第一个元素,`[key='value']` 表示选择具有指定键值对的节点。
6. `[,]`:表示多个筛选器。可以使用逗号分隔多个筛选器,表示并集操作。例如,`[0,1]` 表示选择数组的前两个元素。
7. `[:start:end:step]`:表示切片操作。可以使用冒号分隔起始索引、结束索引和步长来选择数组的子集。例如,`[1:3]` 表示选择数组的第二个和第三个元素。
这些只是 JsonPath 语法的一部分,更多复杂的语法和功能可以根据具体需求进行学习和使用。
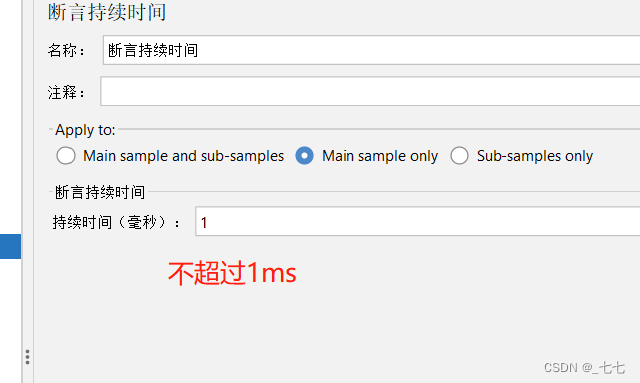
3. 断言持续时间
(1)什么时候可以使用断言持续时间?
- 测试HTTP请求的响应时间是否满足要求时,可以使用断言持续时
(2)使用“断言持续时间”的操作步骤?
- 添加线程组
- 添加HTTP请求
- 添加断言持续时间
- 填写持续时间(允许的最大响应时间,单位:ms)
- 添加查看结果树
添加方式:测试计划 --> 线程组–> HTTP请求 --> (右键添加) 断言 --> 断言持续时间
操作步骤
1.添加线程组
2.添加HTTP请求
3.添加断言持续时间
4.添加断言结果
5.添加查看结果树
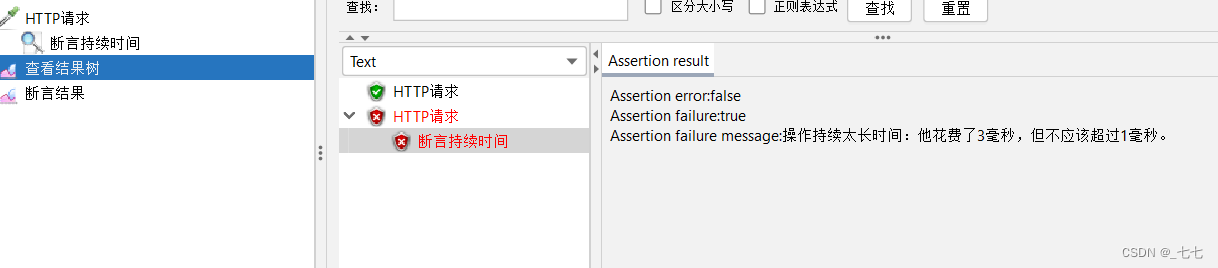
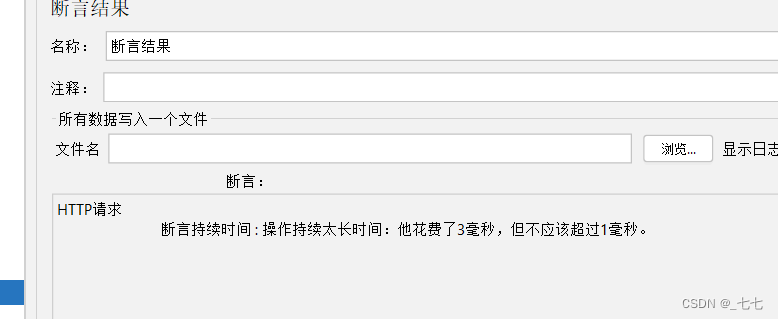
场景
检查:让程序检查响应时间是否大于500毫秒
参数详解
持续时间(毫秒):在将每个响应标记为失败之前允许的最大毫秒数
11. Jmeter关联(同一线程组关联)
关联:
当请求之间有依赖关系,比如一个请求的入参是另一个请求返回的数据,这时候就需要用到关联处理。 JMeter可以通过“后置处理器”中的一些组件来处理关联。
常用的关联方法
- 正则表达式提取器
- XPath提取器
- JSON提取器
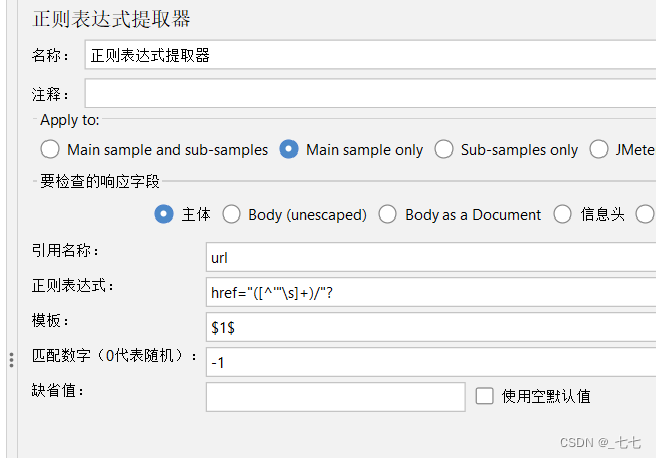
11.1 正则表达式提取器
(1)什么时候可以使用正则表达式提取器?
- 任意格式的响应数据,都可以使用正则表达式提取器进行提取
添加方式:
测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> 正则表达式提取器
场景
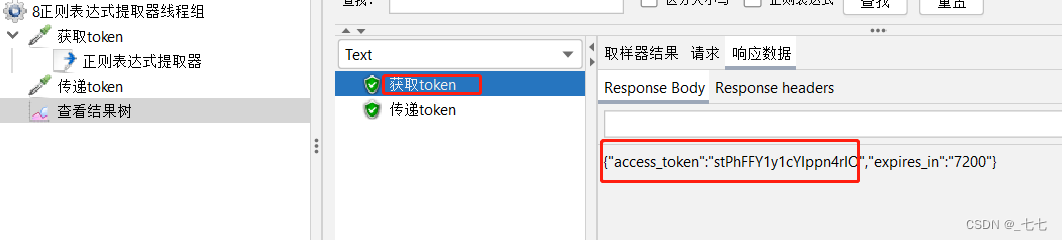
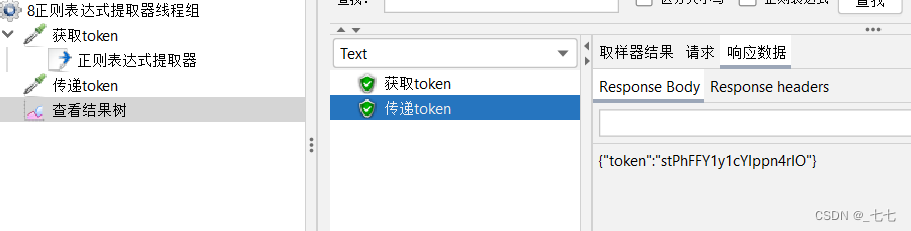
请求:网址1 ,获取token值
请求:网址2,把获取到的token作为请求参数
操作步骤
1.添加线程组
2.添加HTTP请求-网址1
3.添加正则表达式提取器

4.添加HTTP请求-网址2
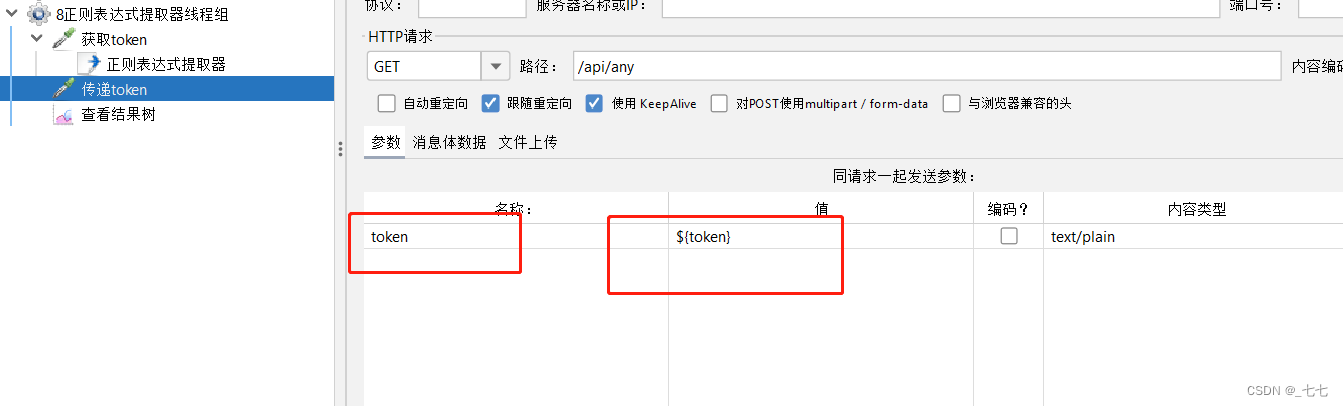
5.添加查看结果树
参数设置(正则表达式提取器)
- Apply to:
指定正则表达式提取器应用的范围,可以选择“Main sample and sub-samples”(主样本和子样本)或者“Main sample only”(仅主样本)。
- Field to check:
指定在响应的哪个部分应用正则表达式。可以选择“Body”(响应正文)、“Body (unescaped)”(未转义的响应正文)、“URL”(URL)、“Response headers”(响应头部)等。
- 引用名称 Name of created variable:
用于指定提取的内容将被保存到的变量名。
下一个请求要引用的参数名称,如填写title,则可用${title}引用它
- 正则表达式
():括起来的部分就是要提取的。
.:匹配任何字符串。
+:一次或多次。
?:不要太贪婪,在找到第一个匹配项后停止。
比如,如果您想要提取 HTML 中的链接内容,可以使用类似<a href="(.*?)">的正则表达式。
- 模板:
用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。
如:$1$表示解析到的第1个值
$1$、$2$ 等来表示对应捕获组的内容
- 匹配数字:
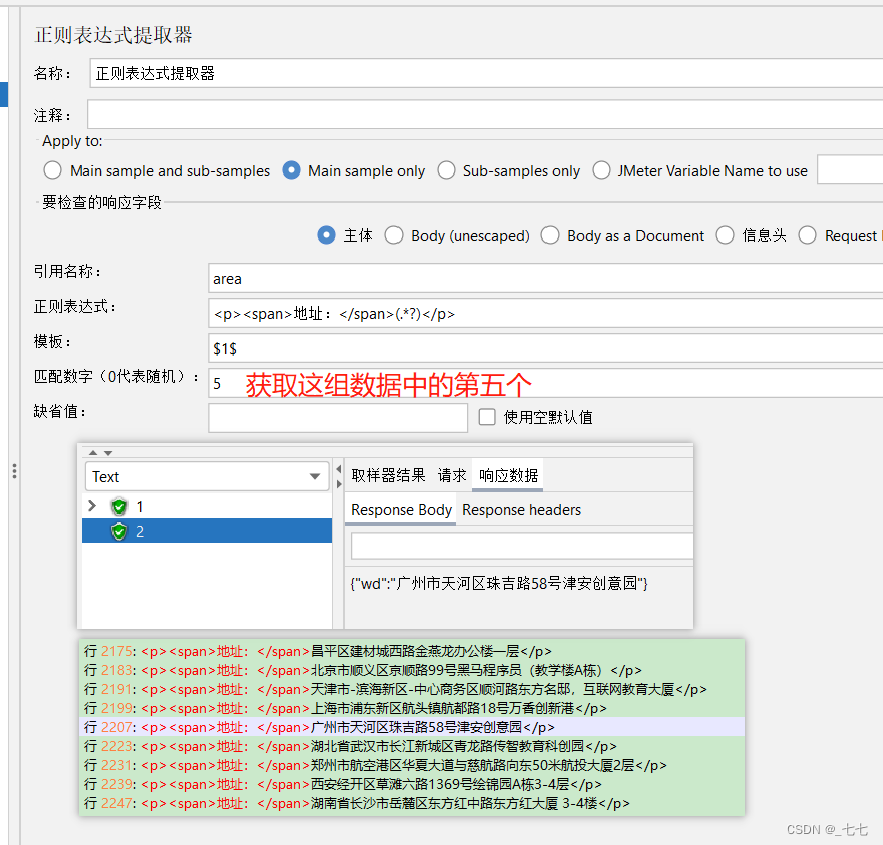
指定当有多个匹配时,提取哪一个。
可以使用 0 表示随机选择一个匹配,也可以指定具体的匹配序号。
0代表随机取值,-1代表全部取值,1代表取第一个值
- 缺省值:
如果参数没有取得到值,那默认给一个值让它取。
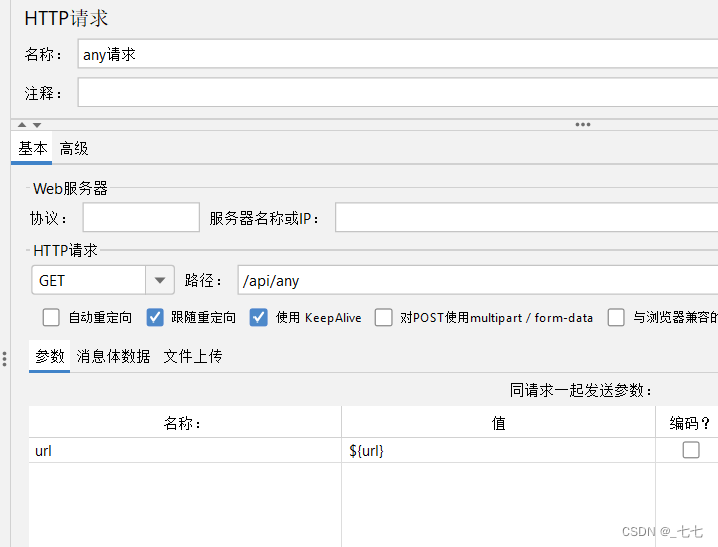
案例1:获取匹配返回的第五个数据
方法1:添加正则表达式 —— 获取第5个地址
方法2:
-
添加正则表达式 —— 获取所有匹配的地址数据

-
添加Debug Sample
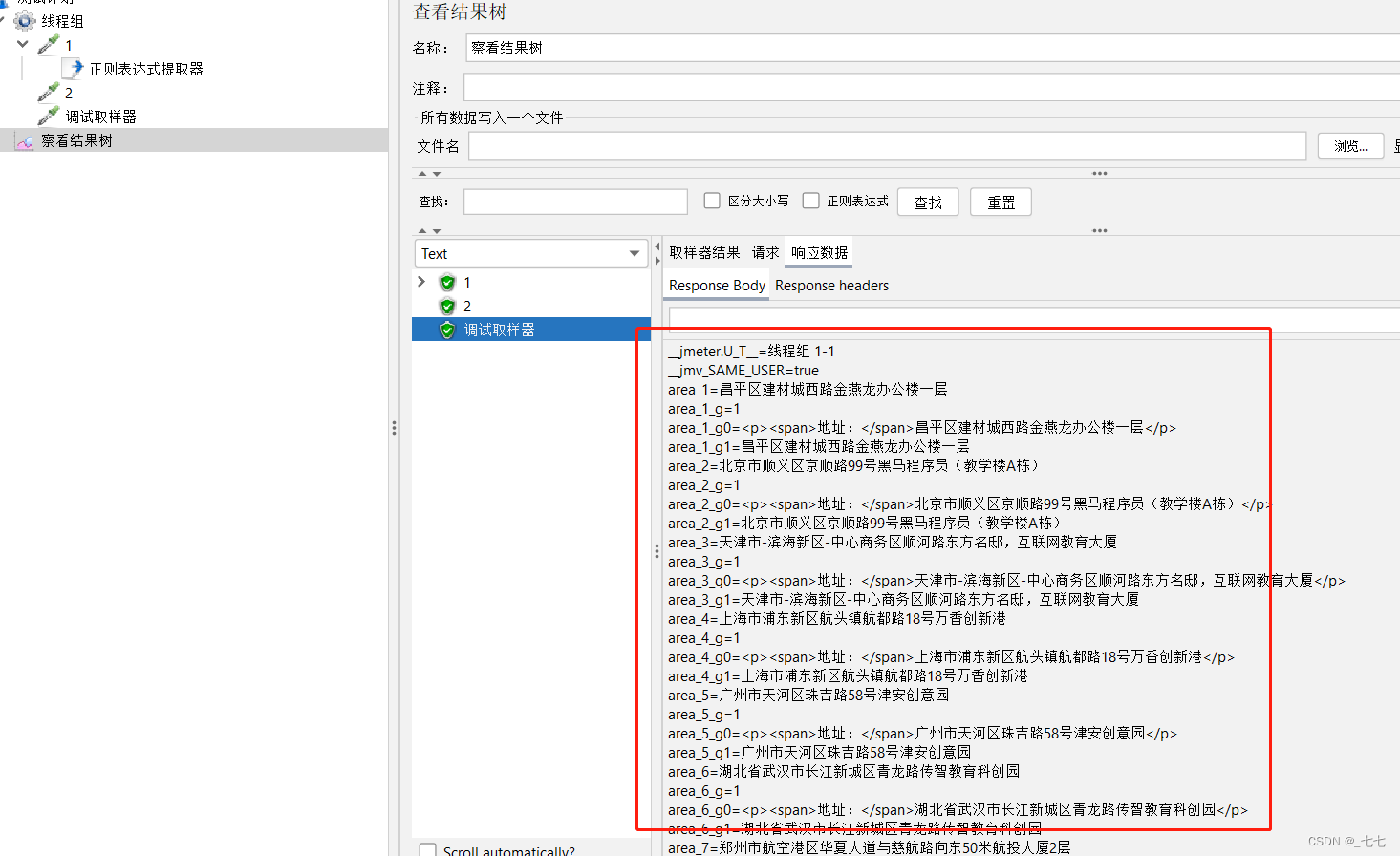
-
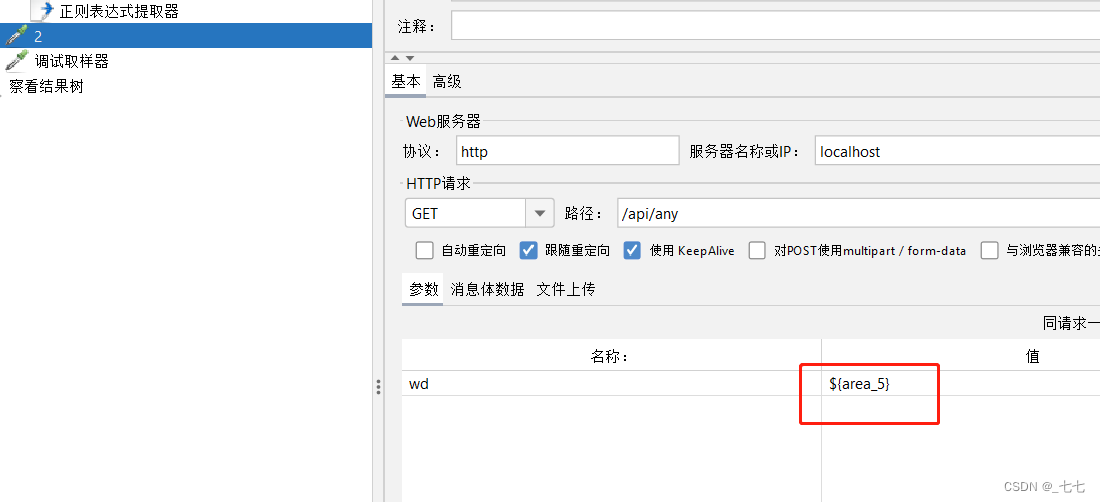
添加HTTP请求 - 百度,引用第5个地址信息,格式:
${变量名_索引},索引从1开始
11.2 XPath提取器
添加方式:测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> XPath提取器
场景
请求:网址1 ,获取title值
请求:网址2,把获取到的title作为请求参数
操作步骤
1.添加线程组
2.添加HTTP请求-网址1
3.添加XPath提取器
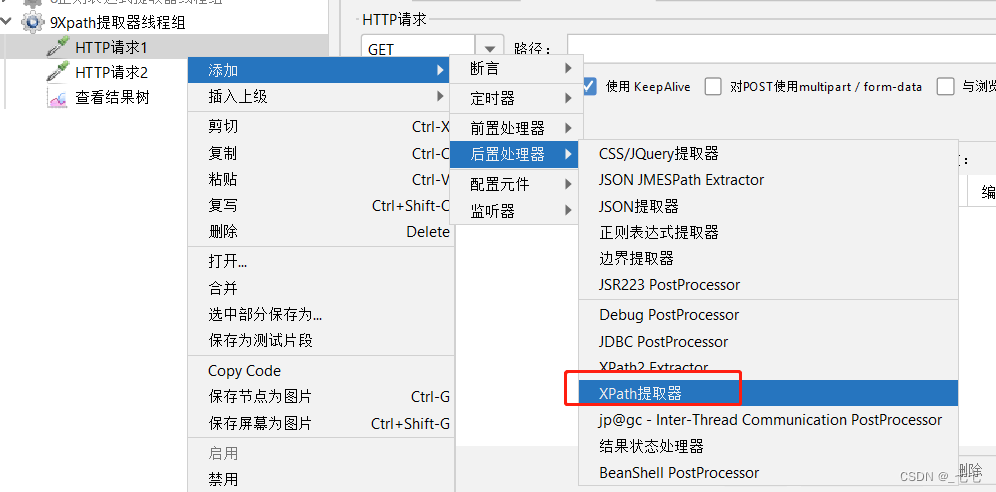

案例:
//a : 找出所有的a标签
//a[@id='kw']: 在HTML页面中,找出a标签(有一个属性为id,且id的值为kw)
//b[@name='kw']: 在HTML页面中,找出b标签(有一个属性为name,且name的值为kw)
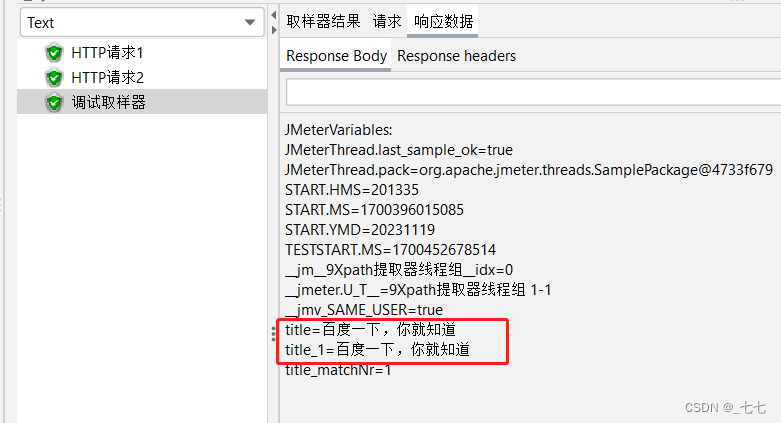
案例2:获取网页中的title标签,
使用://title
4.添加HTTP请求-网址2
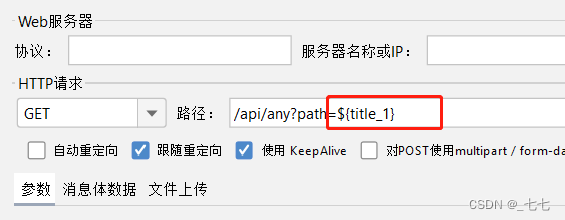
5.添加查看结果树
参数设置(XPath提取器)
- Use Tidy (tolerant parser):如果勾选此项,则使用Tidy将HTML响应解析为XHTML。
- 当需要处理的页面是HTML格式时,必须选中该选项
- 当需要处理的页面是XML或XHTML格式(例如,RSS返回)时,取消选中该选项。
- 引用名称:存放提取出的值的参数
- XPath Query:用于提取值的XPath表达式
- 匹配数字:如果XPath路径查询导致许多结果,则可以选择提取哪个作为
- 变量:
0:表示随机
-1:表示提取所有结果(默认值),它们将被命名为<变量名>_N(其中N从1到结果的个数)
X:表示提取第X个结果。如果这个x大于匹配项的数量,则不返回任何内容。将使用默认值 - 缺省值:参数的默认值
11.3 JSON提取器
(1)什么时候可以使用JSON提取器?
- 针对JSON格式的响应数据,可以使用JSON提取器进行提取
添加方式:
- 测试计划 --> 线程组–> HTTP请求 --> (右键添加) 后置处理器 --> JSON提取器
场景
- 请求获取天气的接口,http://www.weather.com.cn/data/sk/101010100.html
- 获取返回结果中的城市名称
- 请求:把获取到的城市名称作为请求参数
操作步骤
1.添加线程组
2.添加HTTP请求-天气
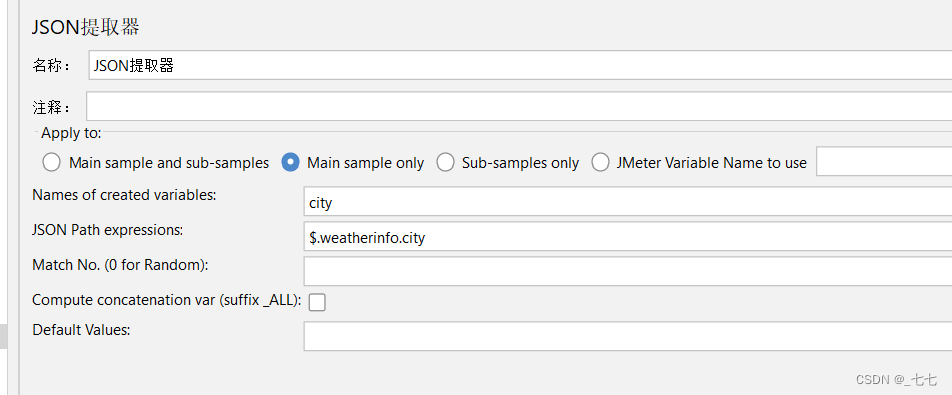
3.添加JSON提取器
4.添加HTTP请求
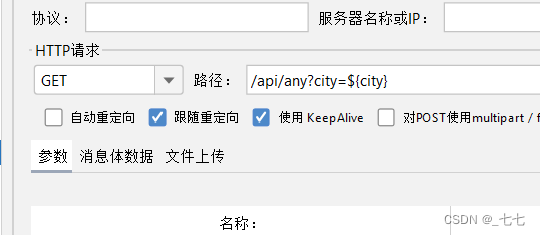
5.添加查看结果树
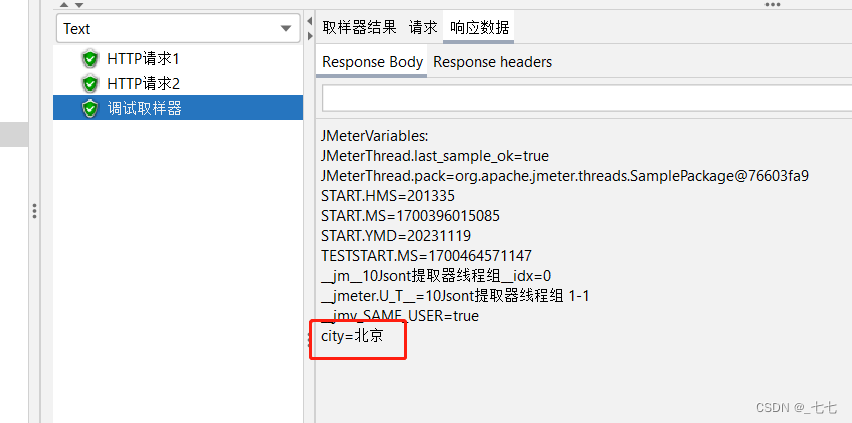
参数设置
Names of created variables:存放提取出的值的参数
JSON Path Expressions:JSON路径表达式
12. Jmeter参数化(重点)
(1)什么是参数化?
把测试数据组织起来,用不同的测试数据调用相同的测试方法。
(2)4种参数化方式有何不同?如何选择适当的方式?
- 用户定义的变量:
作用:定义全局变量
局限性:每次取值(无论是否相同的用户)都是固定值 - 用户参数:
作用:保证不同的用户针对同一组参数,可以取到不同的值
局限性:同一个用户在多次循环时,取到相同的值 - CSV数据文件设置:
作用:保证不同的用户及同一用户多次循环时,都可以取到不同的值
局限性:需要手动进行测试数据的设置 - 函数:
作用:保证不同的用户及多次循环时,都可以取到不同的值,不需要提前设置
局限性:输入数据有特定的业务要求时无法使用(如:登录时的用户名密码)
实现方式
- 用户定义的变量
- 用户参数
- CSV Data Set Config文件定义的方式(所有测试数据都是固定的情况下)
- 函数的方式(灵活,业务测试常用)
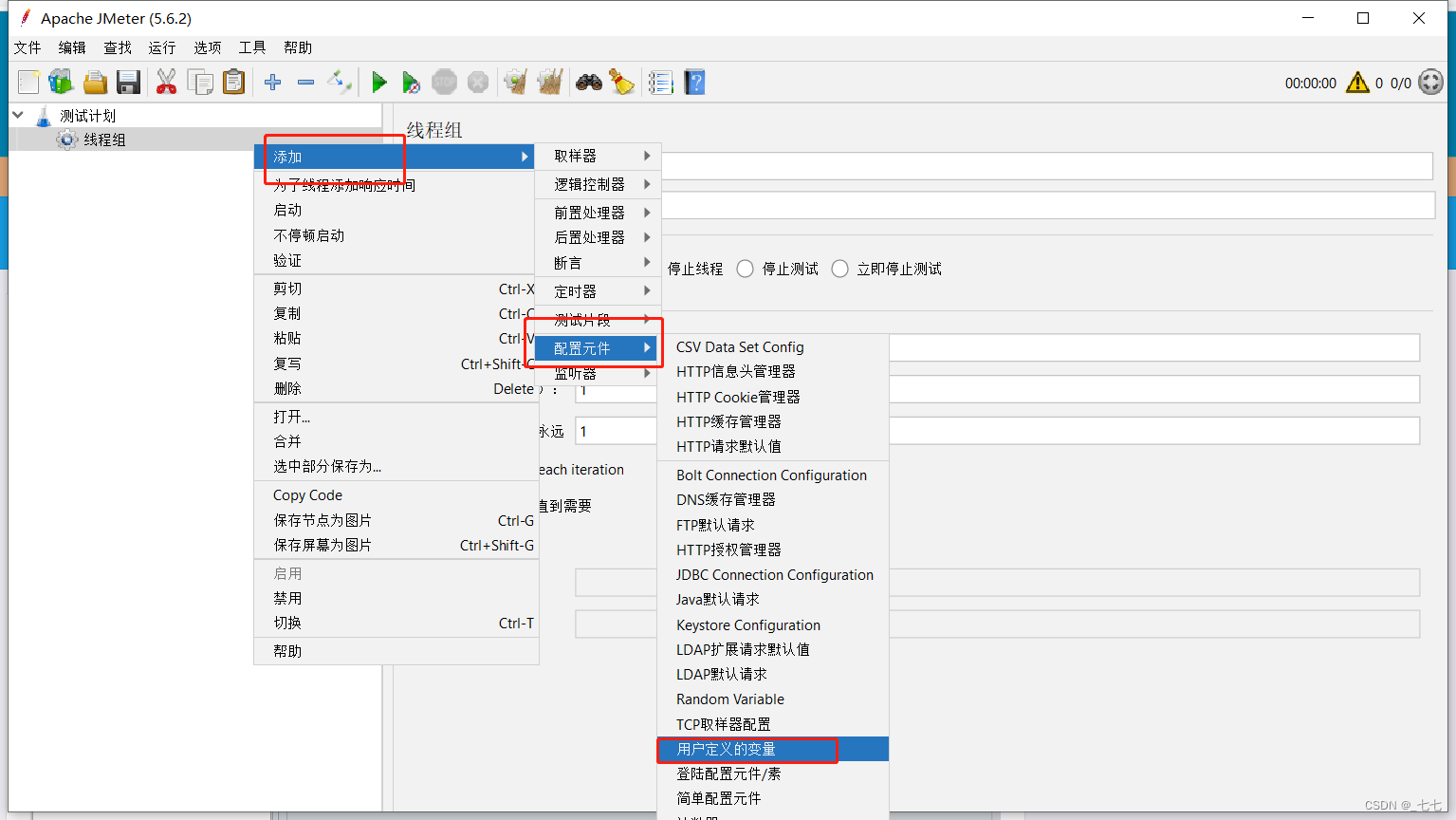
12.1. 用户定义的变量使用
-
添加路径:线程组>配置元件>用户自定义变量
-
添加用户自定义变量
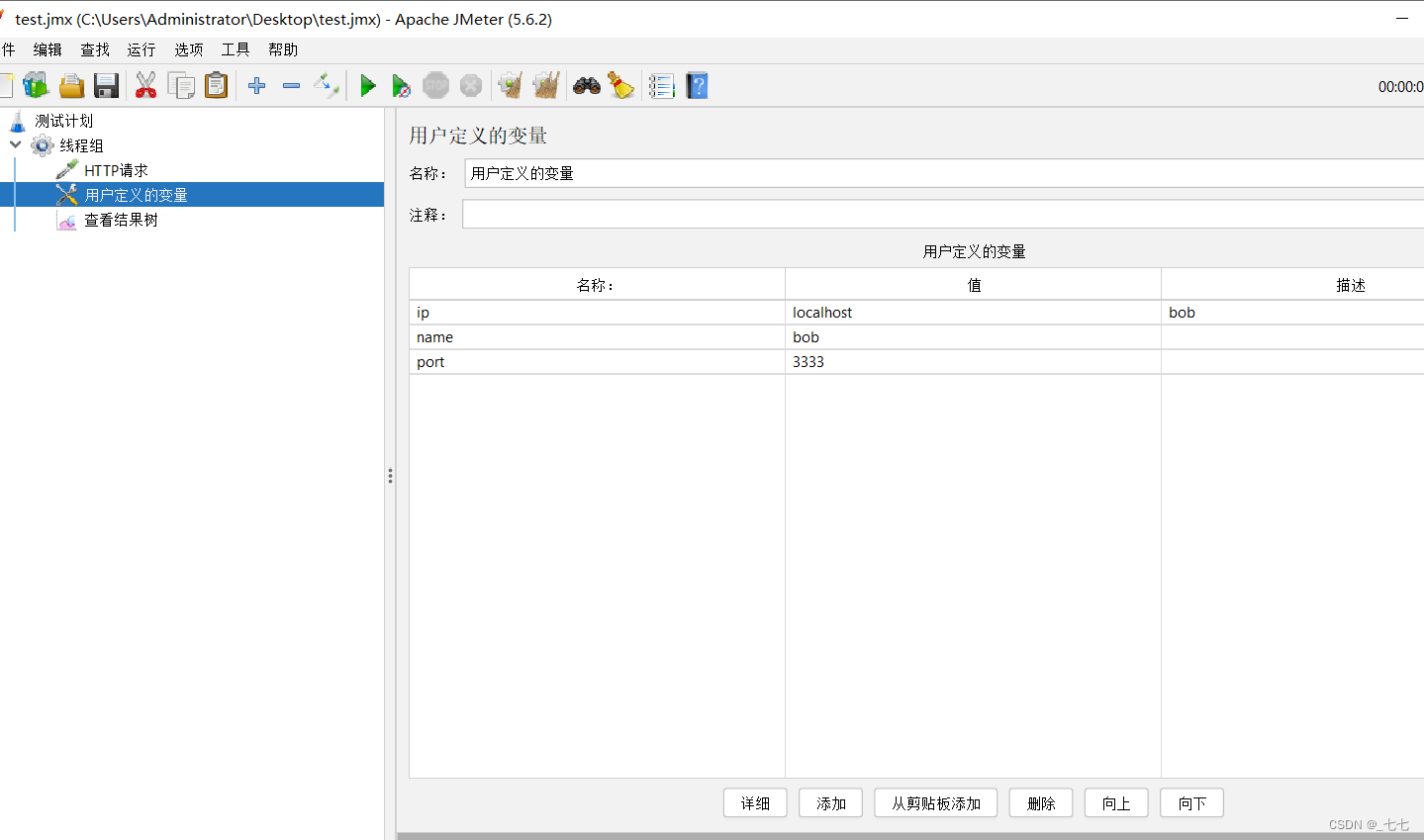
-
http请求应用变量名
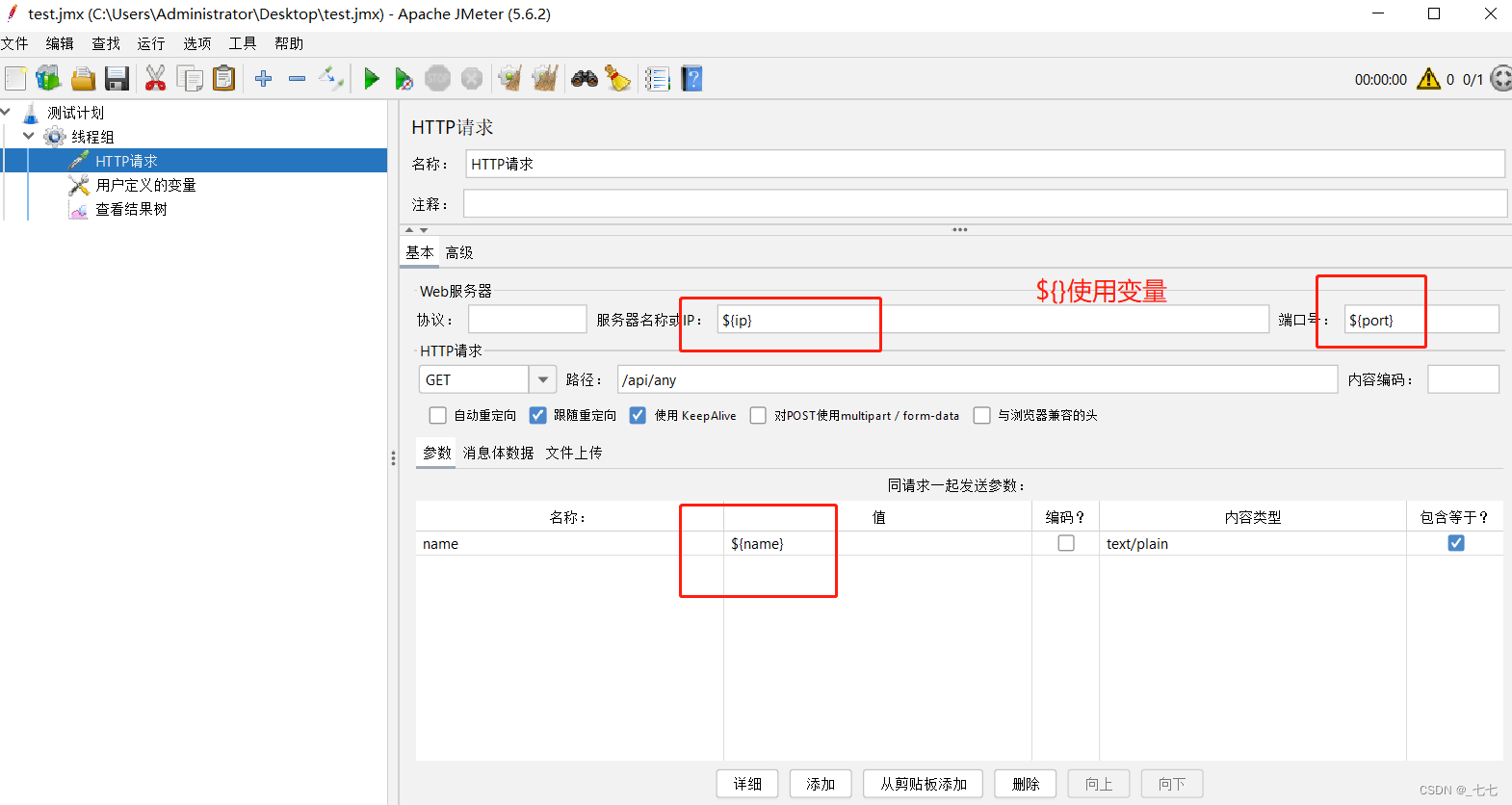
12.2. 用户参数
添加方式:测试计划 --> 线程组–> 前置处理器 --> 用户参数
场景
- 请求:https://www.baidu.com
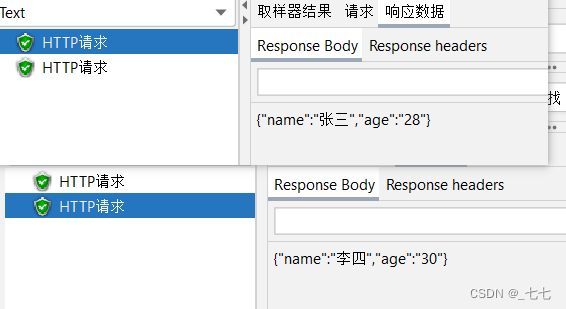
- 要求:第一次请求附带参数:name=“张三”&age=28;第二次请求附带参数:name=“李四”&age=30
操作步骤
1.添加线程组
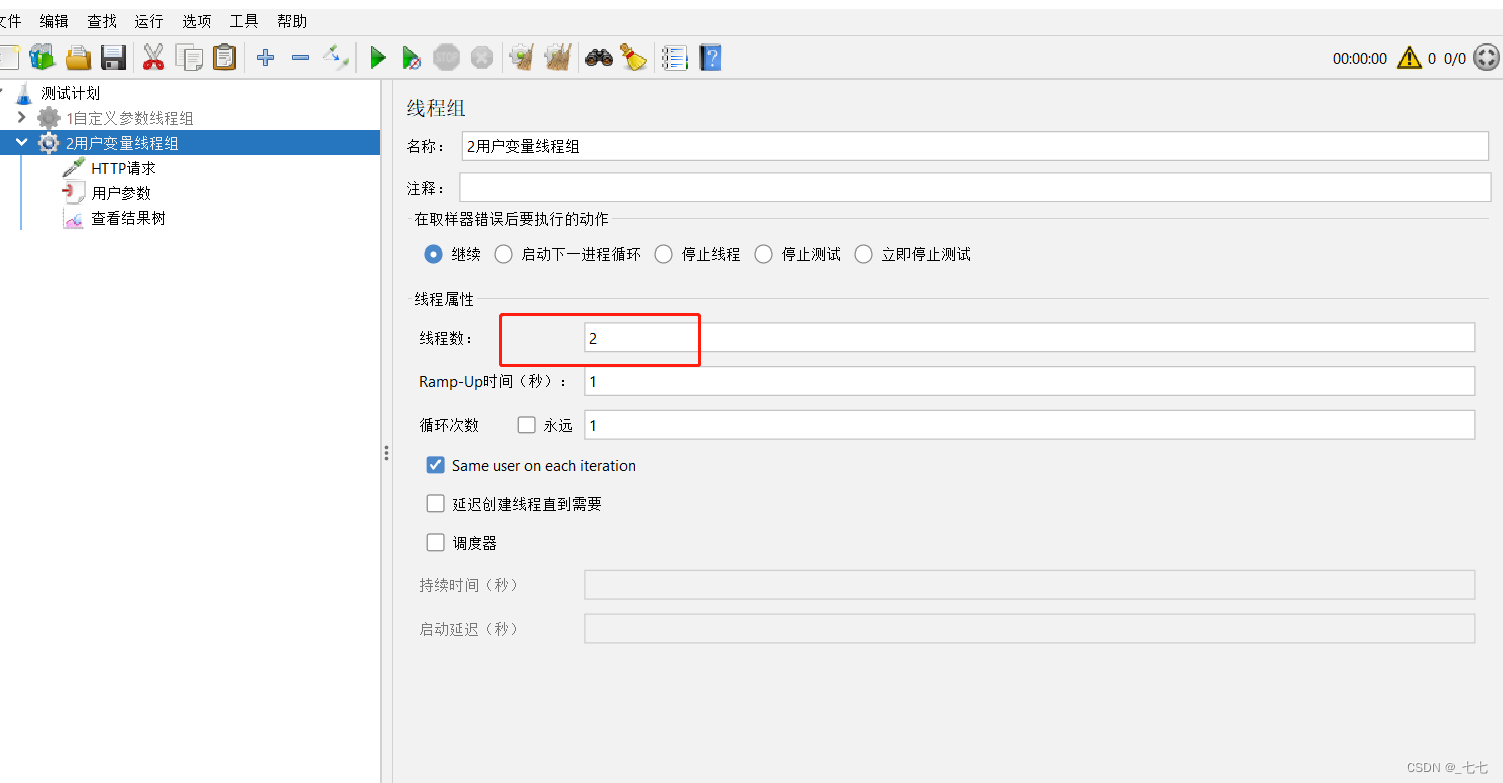
2.添加用户参数
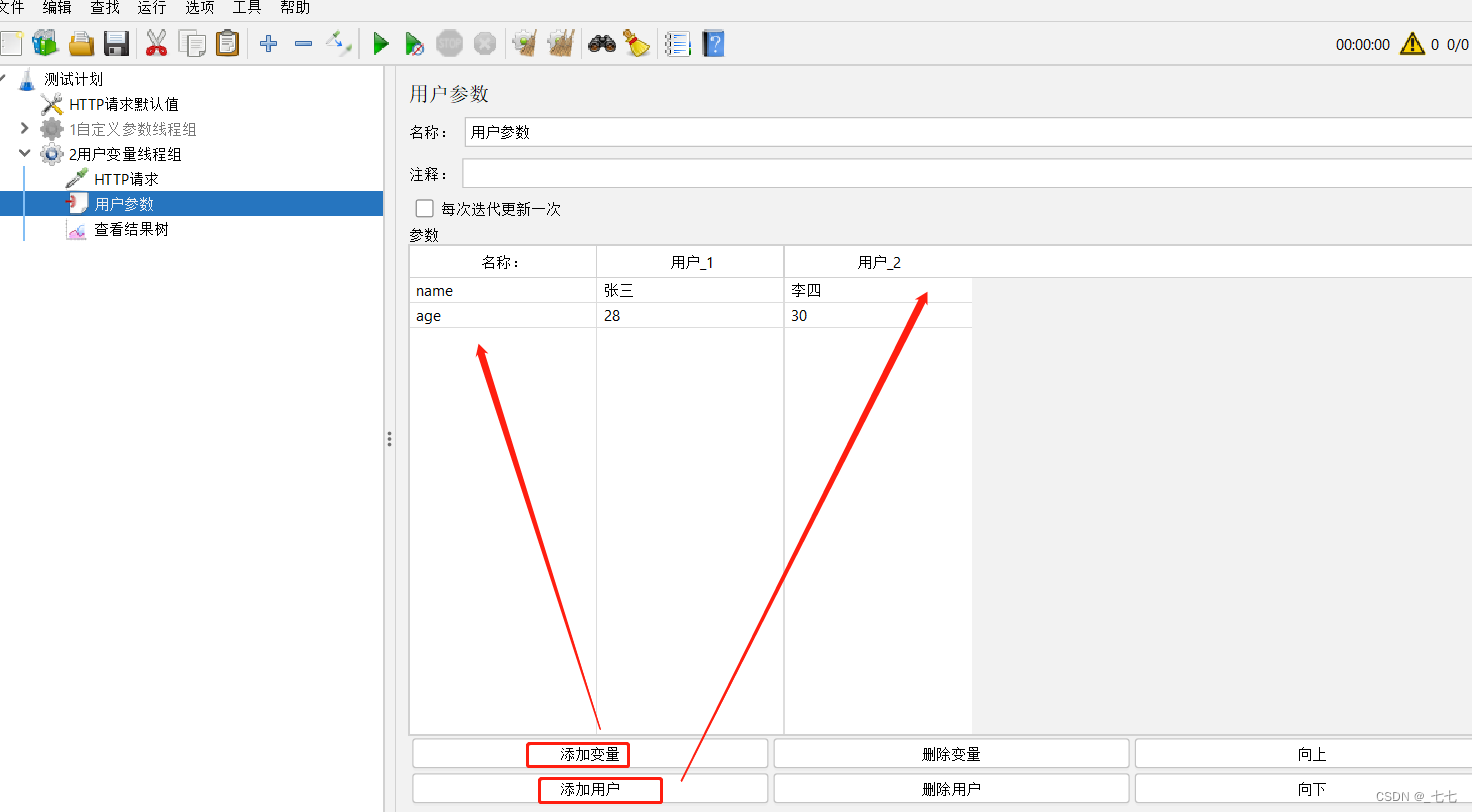
3.添加HTTP请求

4.添加查看结果树
12.3 CSV 数据文件设置
添加方式:测试计划 --> 线程组–> 配置元件 --> CSV 数据文件设置
场景
请求:https://www.baidu.com
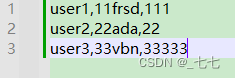
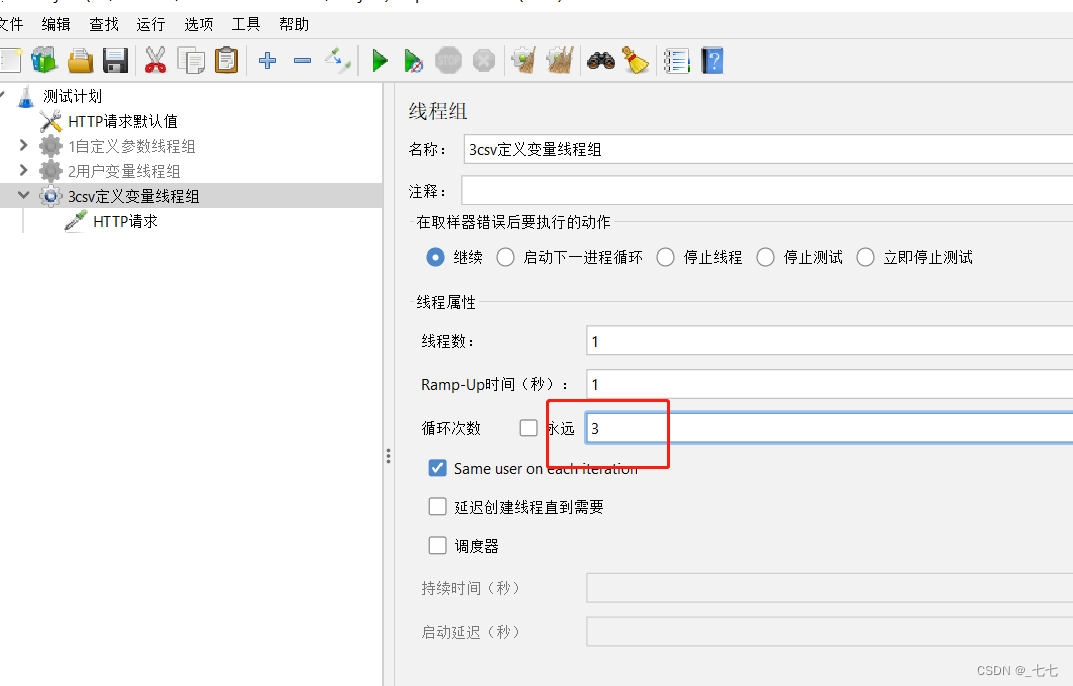
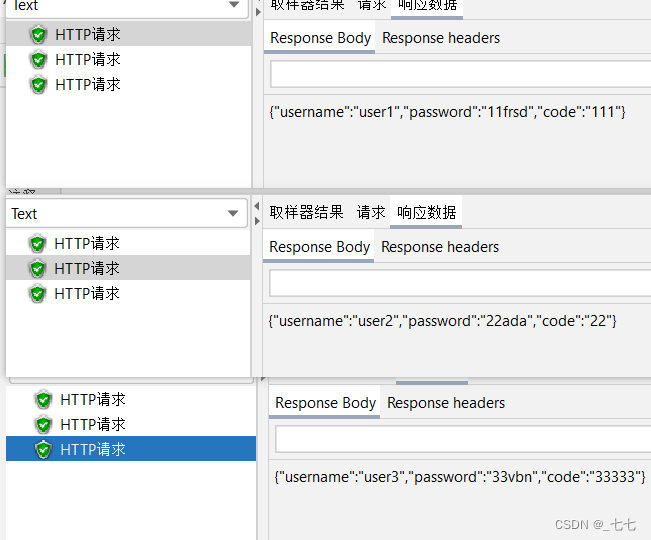
要求:循环3次,每次请求时附带参数username,password,code的值不相同
操作步骤
1.定义CSV数据文件
2.添加线程组
3.添加CSV 数据文件设置
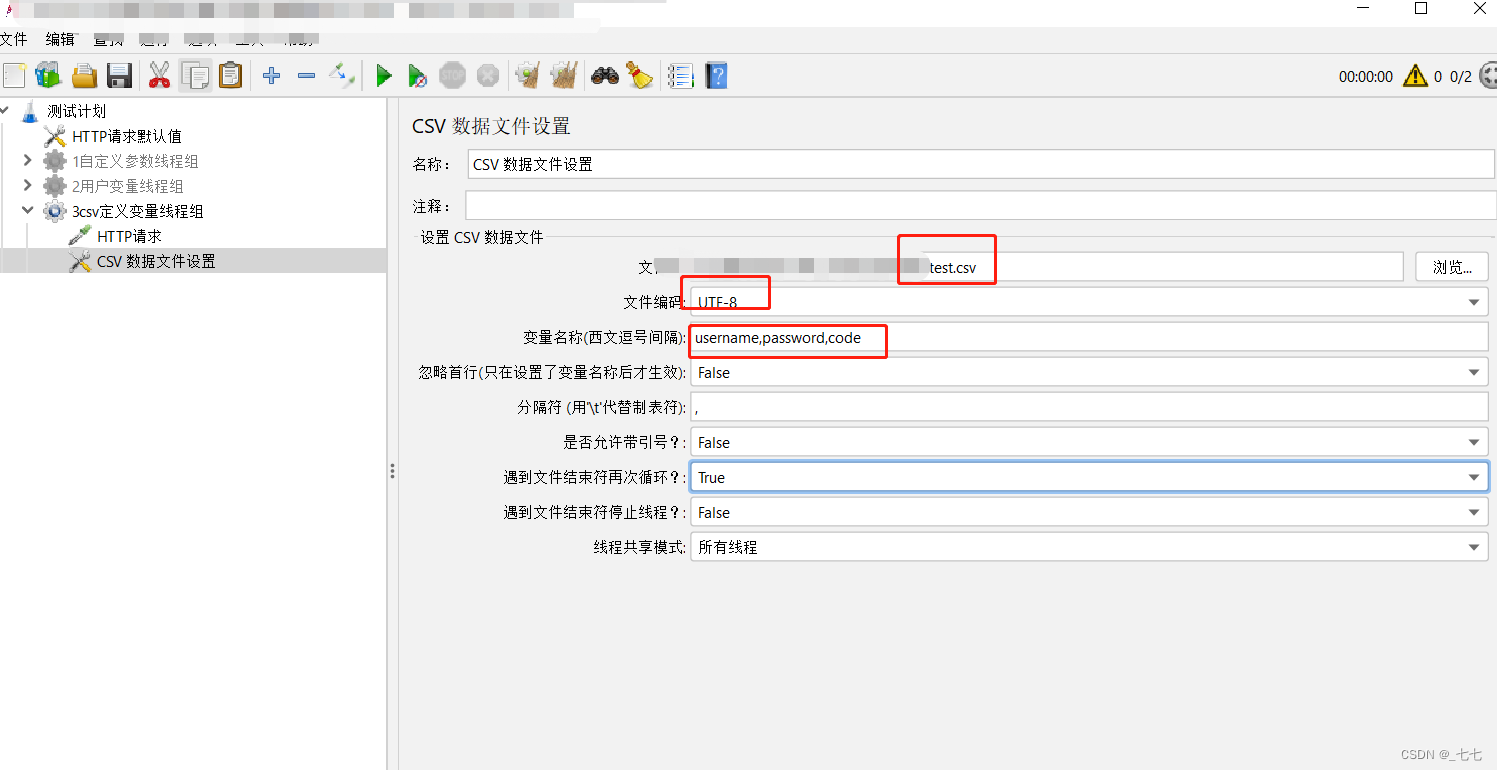
参数详解(CSV 数据文件设置)
- 文件名:CSV文件路径
- 文件编码:文件编译字符编码,一般设置UTF-8
- 变量名称:多个变量时,使用英文逗号分隔
- 忽略首行:True为忽略,False为不忽略,默认值:False
- 分隔符:如文件中使用的是逗号分隔,则填写逗号;如使用的是制表符,则填写\t;
- 是否允许带引号: CSV文件中的内容是否允许带引号
- 遇到文件结束符再次循环:当读取文件到结尾时,是否再从头读取文件,False=当读取文件到结尾时,停止读取文件
- 遇到文件结束符停止线程:当“遇到文件结束符再次循环”一项为False时起效;True:当读取文件到结尾时,停止进程
- 线程共享模式:共享模式一般默认即可
- 所有线程:该文件在所有线程之间共享,所有线程循环取值,线程一取第一行,线程二取下一行
- 当前线程组:各个线程组分别循环取值
- 当前线程:每个文件分别为每个线程打开
4.添加HTTP请求
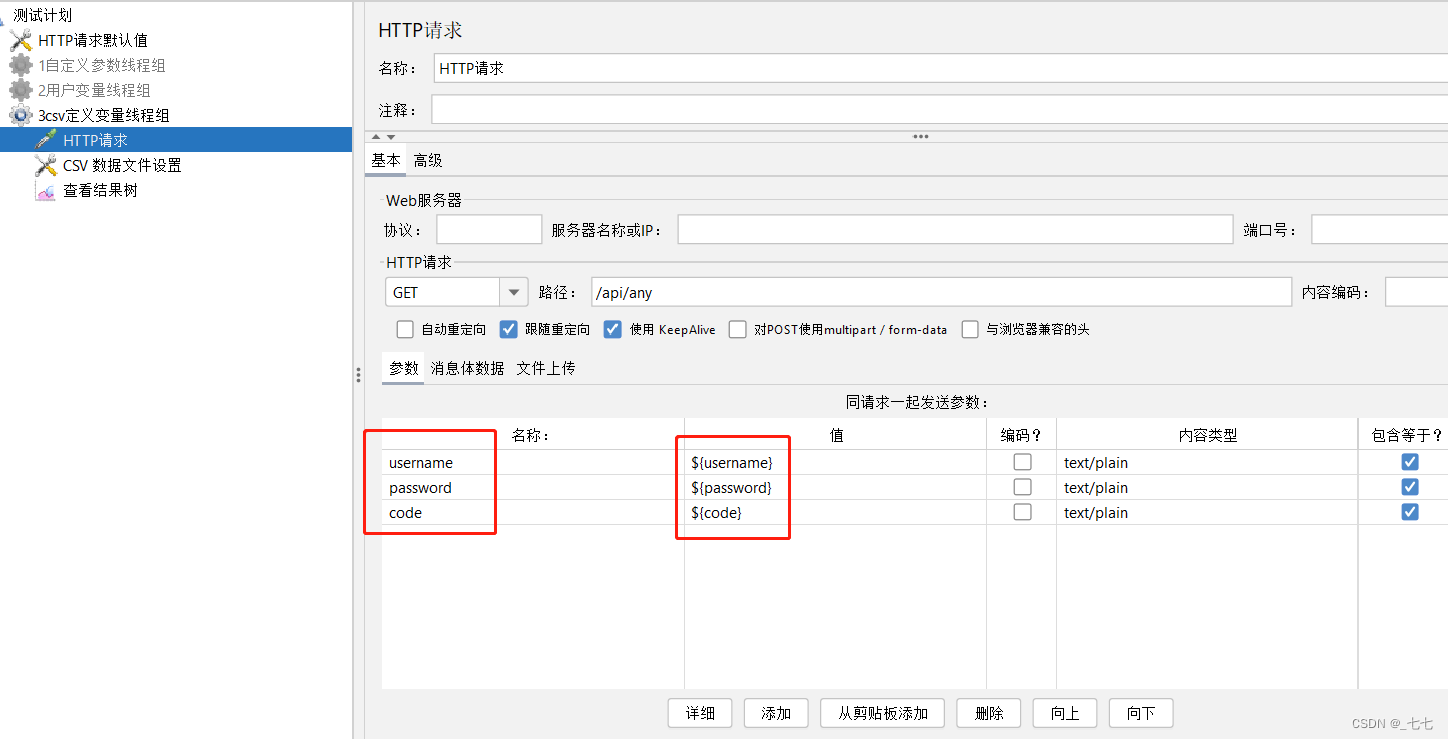
5.添加查看结果树
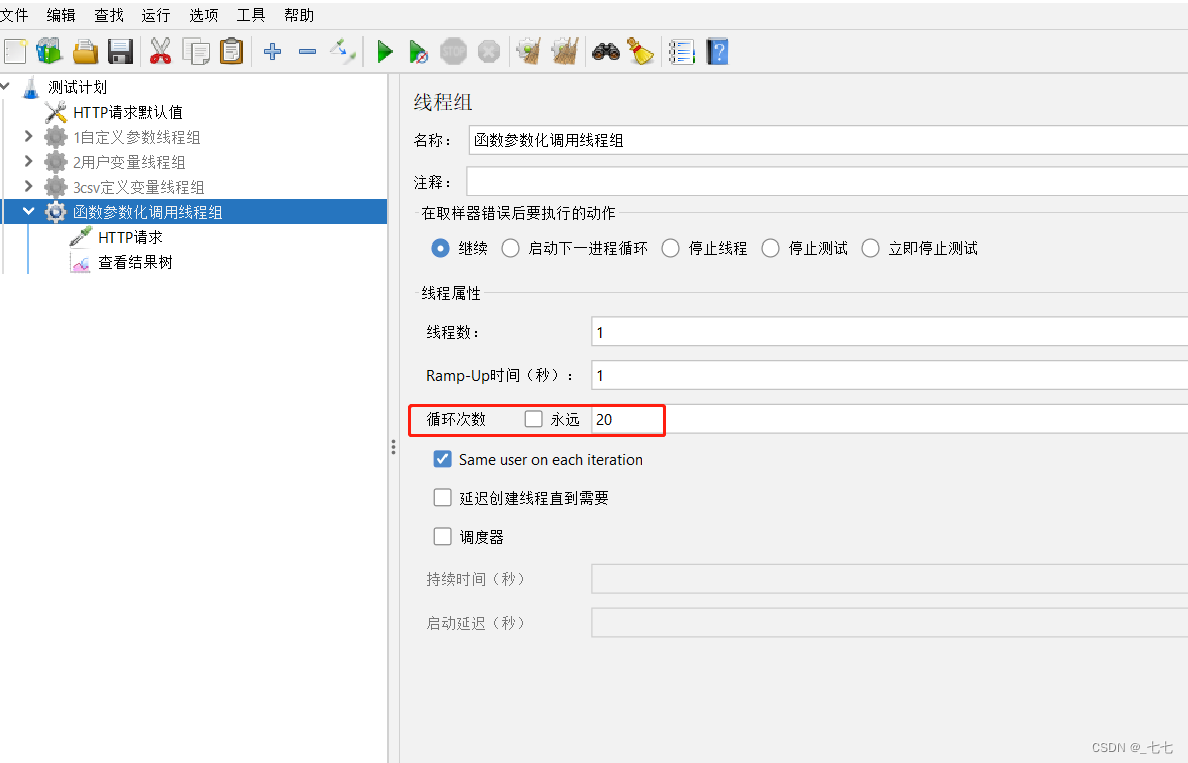
12.4 函数(counter)
计数函数,一般做执行次数统计使用;
位置:在菜单中选择–> 工具 --> 函数助手对话框
- 什么时候使用counter函数?
自动生成不重复的数据,让每个用户每次循环都能取到不同的数据,且不需要提前定义
函数助手
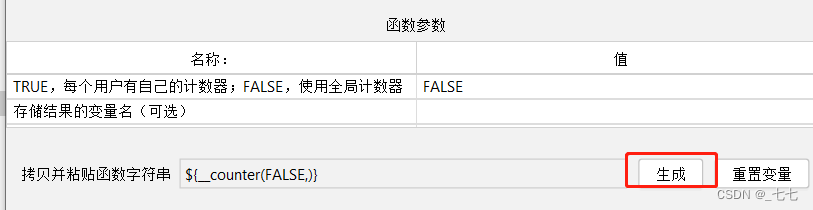
- 设置:
• TRUE,每个用户有自己的计数器;FALSE,使用全局计数器
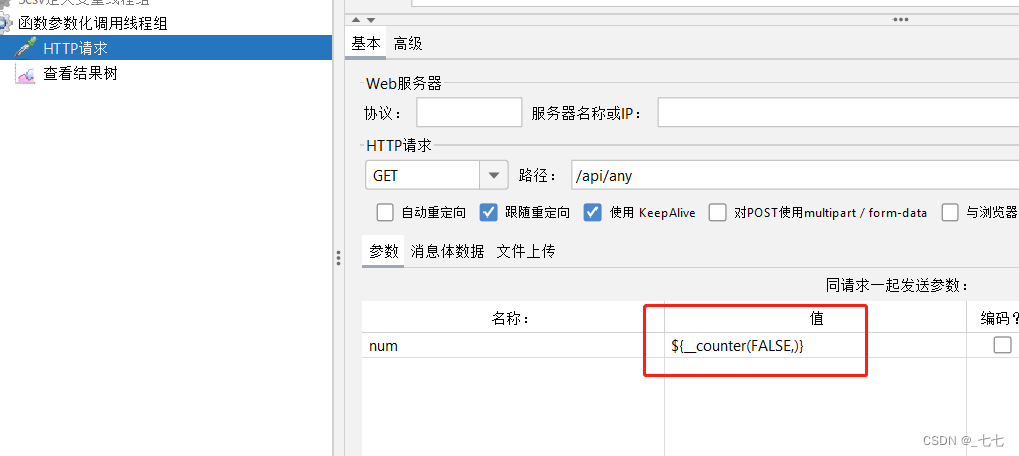
• Name of variable in which to store the result (optional):用于存储结果的变量名(可选) - 使用:生成-复制
${__counter(FALSE,)}
参数化调用
查看结果

13. Jmeter属性(跨线程组关联)
- 当有关联关系的两个请求在同一个线程组中时,可以使用三种提取器的变量来实现数据传递。
- 当有关联关系的两个请求在不同线程组中时,如何进行数据传递呢?答:JMeter属性
当有依赖关系的两个请求(一个请求的入参是另一个请求返回的数据),放入到不同的线程组中时,就不能使用提取器保存的变量来传递参数值,而是要使用Jmeter属性来传递。
(1)什么时候需要使用JMeter属性?
- 需要实现跨线程组的数据传递时,可以使用JMeter属性
Jmeter属性的配置方法
函数实现:
1. __setProperty函数:将值保存成jmeter属性
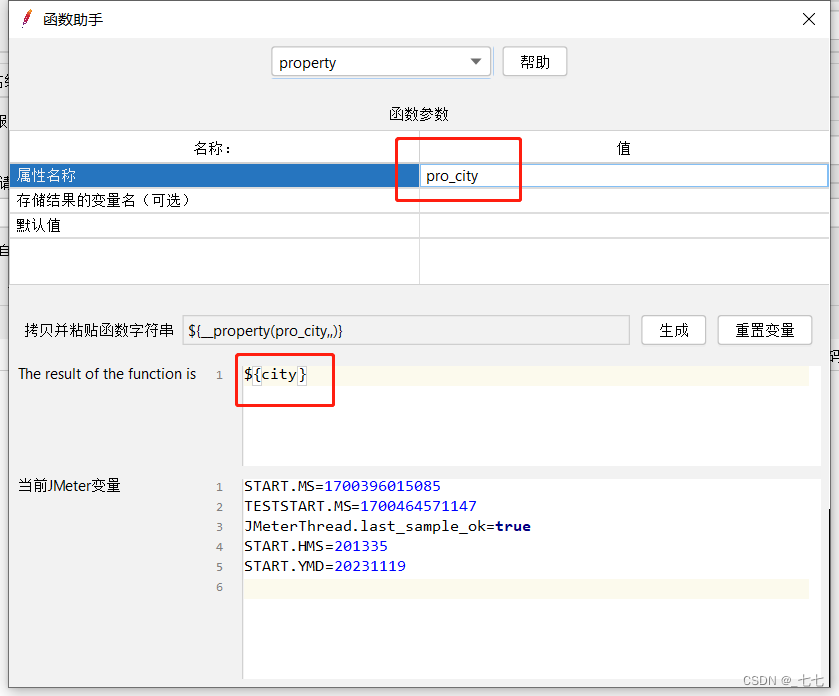
2. __property函数:在其他线程组中使用property函数读取属性
备注:setProperty函数需要通过BeanShell取样器来执行(BeanShell取样器作用:执行函数和java脚本)
1、__setProperty函数:将值保存成JMeter属性
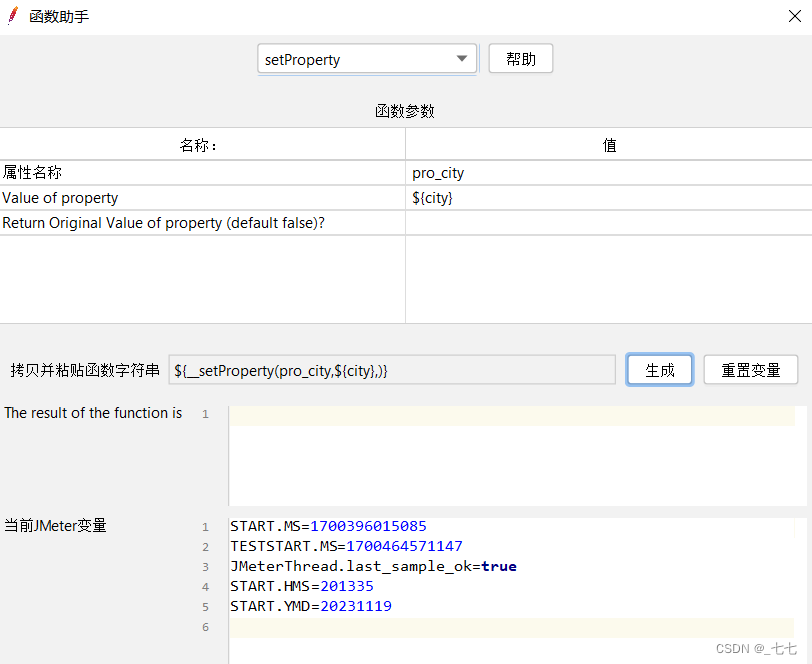
2、__property函数:在其他线程组中使用property函数读取属性
读取pro_city
场景
- 线程组1:请求获取天气的接口,http://www.weather.com.cn/data/sk/101010100.html
- 获取返回结果中的城市名称
- 线程组2:请求:把获取到的城市名称作为请求参数
操作步骤
1.添加线程组1
2.添加HTTP请求-天气
3.添加JSON提取器
4.添加BeanShell取样器(将JSON提取器提取的值保存为Jmeter属性)
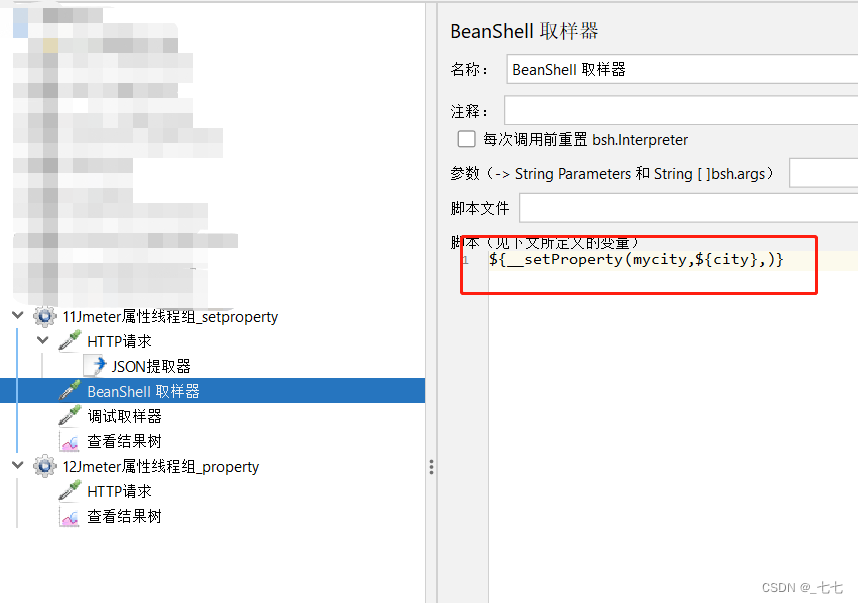
5.添加HTTP请求(读取Jmeter属性)
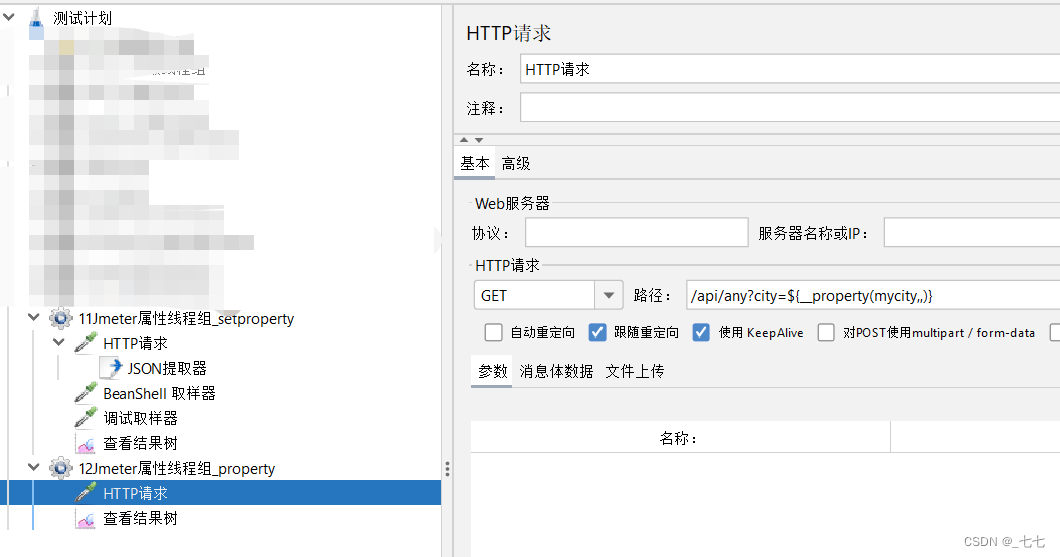
6.添加查看结果树
14. Jmeter自动录制脚本
为什么要录制脚本?
- 有API文档时,可以根据API文档的定义来编写HTTP接口测试脚本。
那如果没有API文档时,该如何来编写HTTP接口测试脚本呢 ?
应用场景:
在没有接口文档的旧项目当中,快速录制web页面产生的http接口请求,帮助编写接口测试脚本
JMeter录制脚本的操作步骤
-
开启windows操作系统的浏览器代理

开启后,windows操作系统中所有的http请求都会发送给设置的代理服务器。 -
在jmeter当中添加非测试元件HTTP代理服务器,并进行配置
-
加HTTP代理服务器:测试计划(右键)->非测试元件->HTTP代理服务器
-
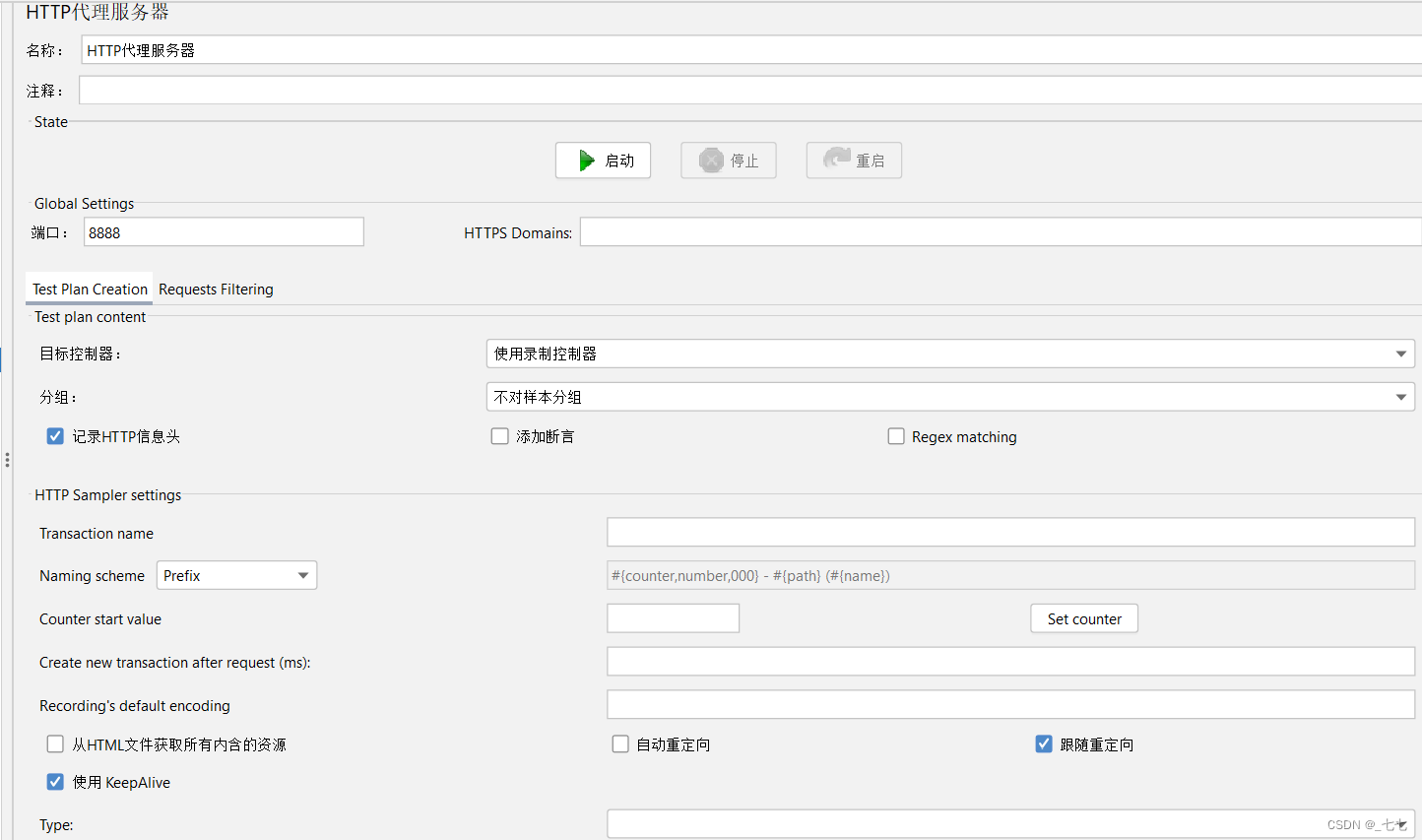
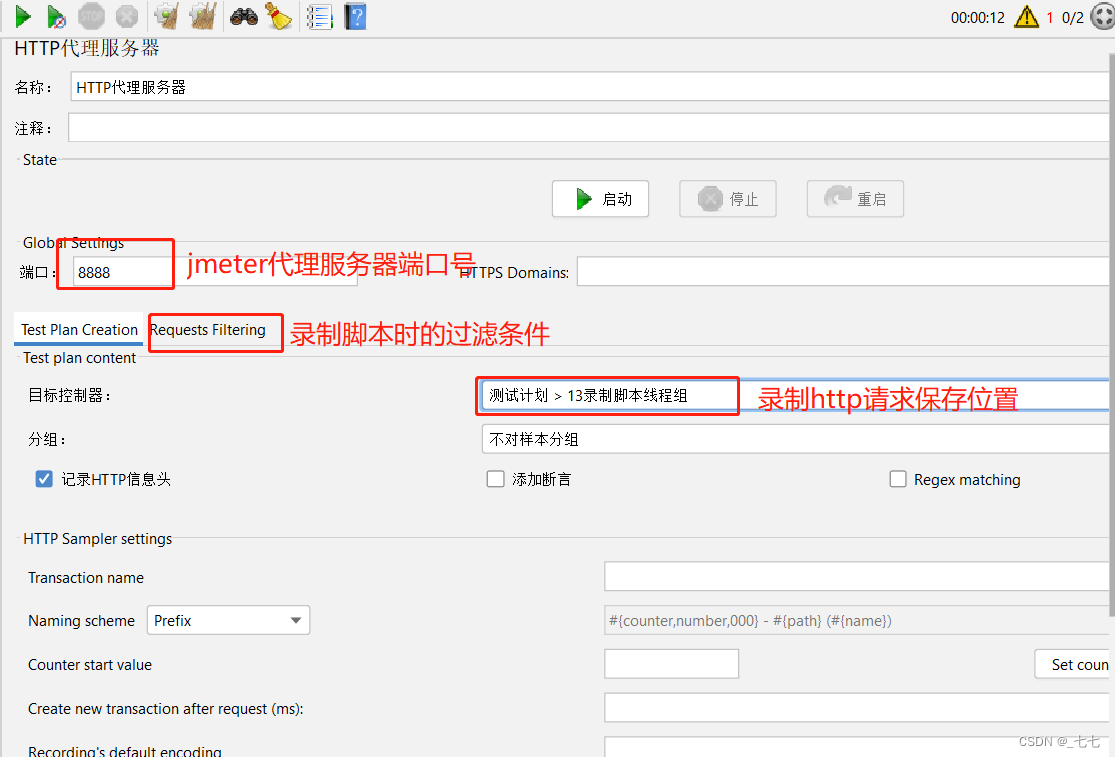
配置代理服务器的参数
参数解析:
-
State:
1. 设置端口:代理服务程序端口程序
2. 启动按钮
Test Plan Creation:
1. 目标控制器:录制的脚本放到那个容器
2. 分组:
1). 不对样本分组:对所有录制的取样器不分组。
2). 在组间添加分组:在取样器分组之间添加以名为 "---"的控制器。
3). 每个组放入一个新的控制器:每个分组放到一个新的简单控制器下。
4). 只存入每个组的第一个样本:只要每个分组的第一个请求会被录制。
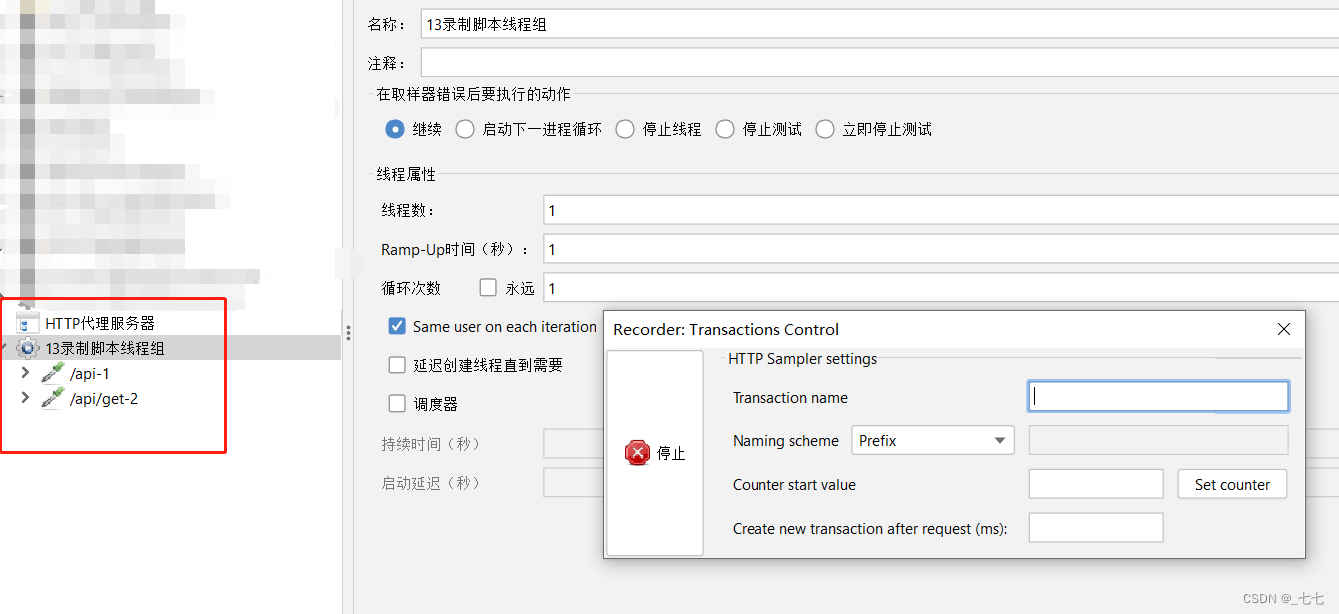
5). Put each group in a new transaction controller:
(每个分组创建一个事务控制器,那个分组的所有取样器都保存在控制器下。)
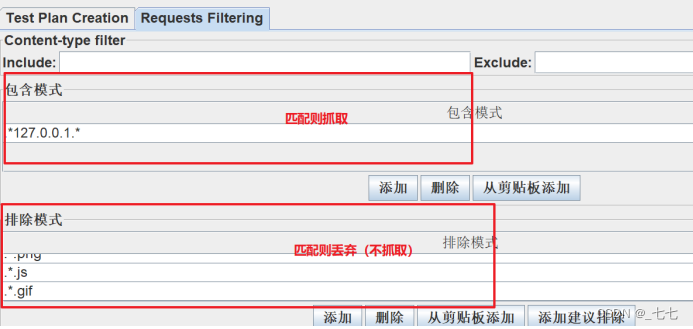
Requests Filtering:
包含模式:url匹配正则表达式,包含此项 如:.*localhost.*
排除模式:url匹配正则表达式,不包含此项 如:.*.css .*.jpg .*.jpeg .*.png .*.js
- 启动代理服务器,开始录制
先点击启动
等待一段时间后,会弹出一个证书确认窗口,这个证书用于抓取https接口请求。
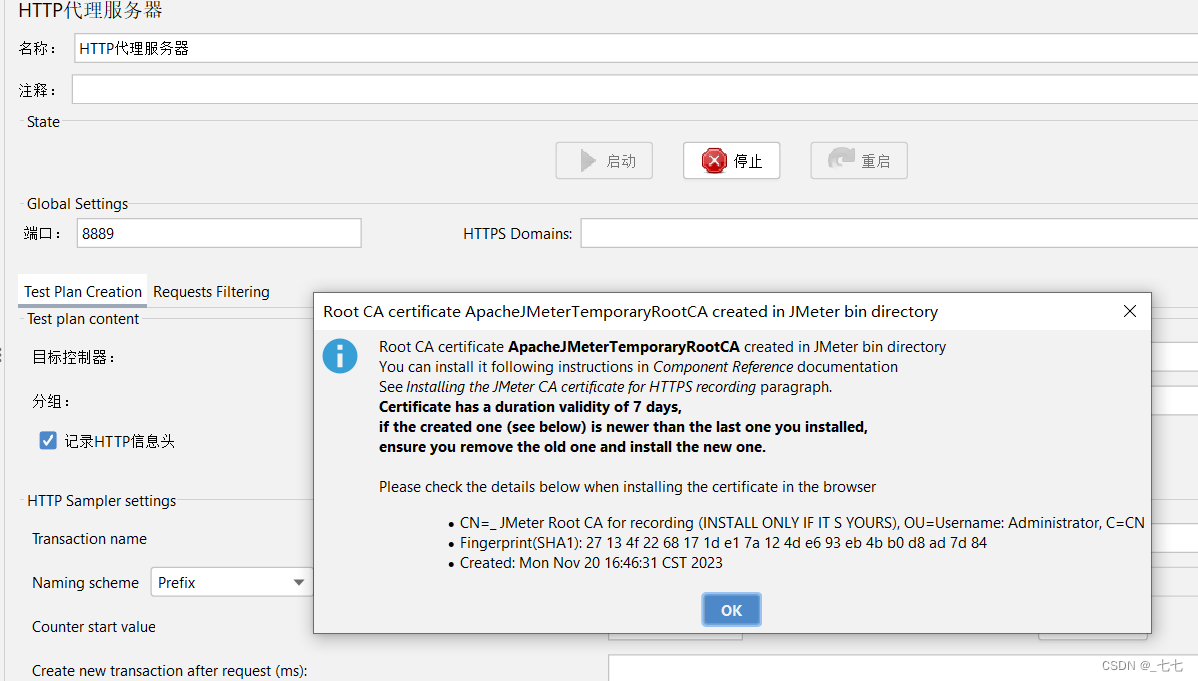
在浏览器页面中进行操作,成功后,就能在jmeter当中看到抓取到的接口请求了。
15. Jmeter直连数据库
直连数据库的使用场景
-
用作请求的参数化
例如:登录时需要的用户名,可以从数据库中查询获取 -
清理垃圾数据
例如:添加商品(商品名/编号等不能重复),再执行该脚本不能成功,需要在下次执行前删除该商品数据 -
准备测试数据
例如:通过数据库来准备大量(几十万条)的性能测试数据。 -
用作结果的断言
例如:添加购物车下订单,检查接口返回的订单号,是否与数据库中生成的订单号一致
1、直连数据库的关键配置
- 添加MySQL驱动jar包
- https://dev.mysql.com/downloads/connector/j/
- 方式一:在测试计划面板点击“浏览…“按钮,将你的JDBC驱动添加进来
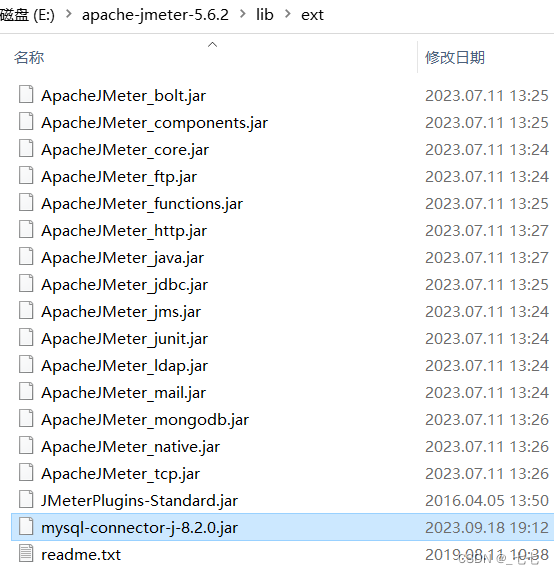
- 方式二:将MySQL驱动jar包放入到lib/ext目录下,重启JMeter
2、配置数据库连接信息
- 添加方式:测试计划 --> 线程组–> (右键添加) 配置元件 --> JDBC Connection Configuration
主要参数:
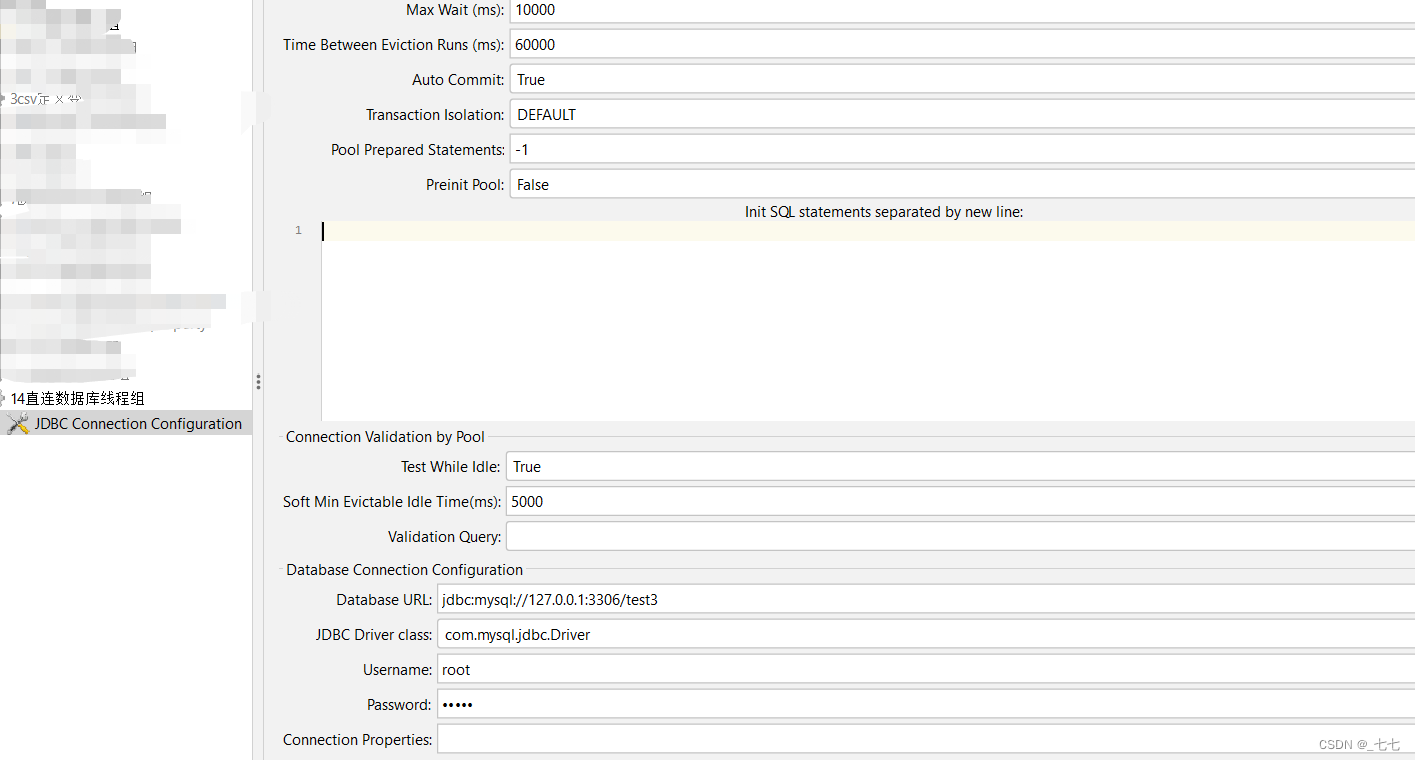
Variable Name: mysql数据库连接池名称(JDBC请求时要引用)
Database URL: jdbc:mysql://localhost:3306/books
jdbc:mysql:(MySQL固定格式)
//127.0.0.1:(数据库ip地址)
3306:(MySQL默认端口,如改变,请如实填写)
books:要连接的数据库名称
JDBC DRIVER class: com.mysql.jdbc.Driver(MySQL驱动包位置固定格式)
Username: root(连接数据库用户名,如实填写)
Password:(MySQL数据库密码,如实填写,如果密码为空不写)
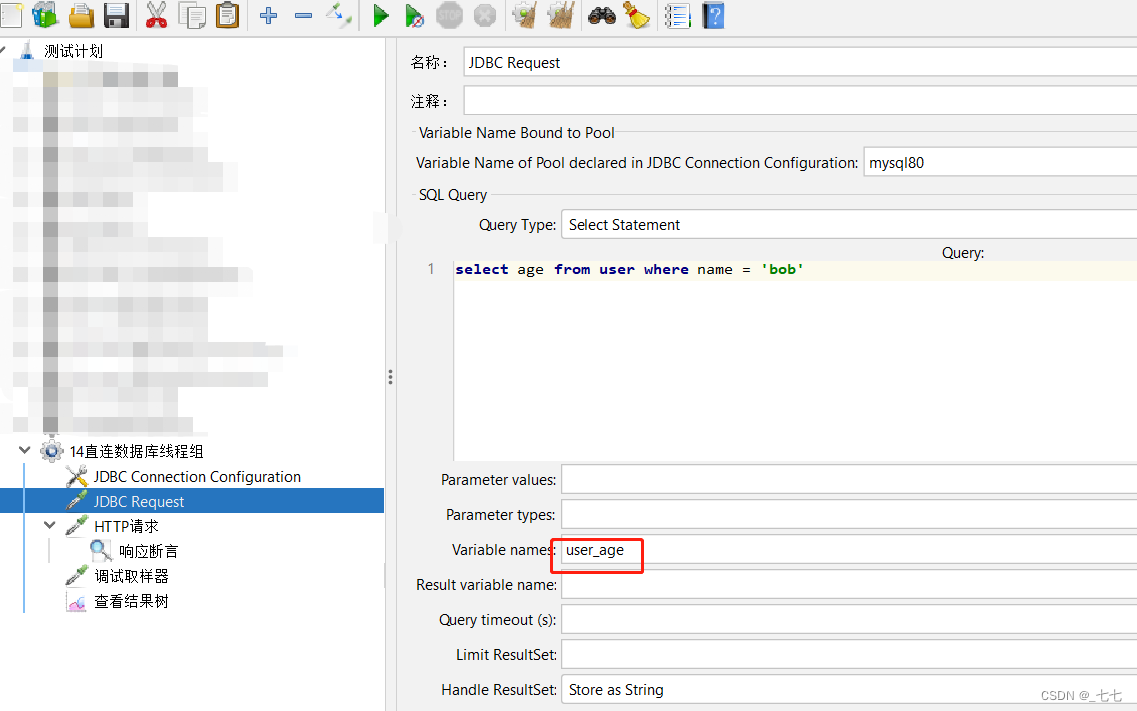
3、添加 JDBC request
主要参数:
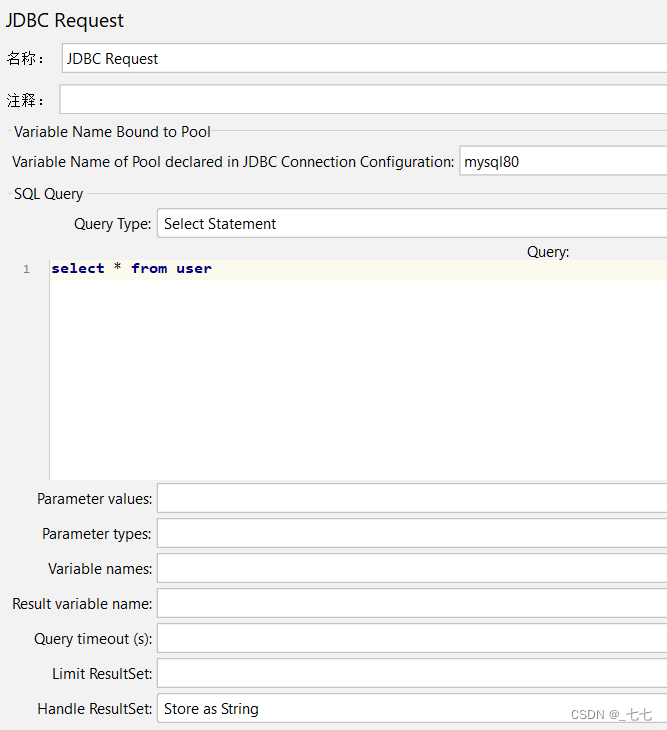
Variable Name:数据库连接池的名字,需要与JDBC Connection Configuration的Variable Name Bound Pool名字保持一致
Query:填写的sql语句未尾不要加“;”
Parameter values:参数值
Parameter types:参数类型
Variable names:保存sql语句返回结果的变量名
Result variable name:创建一个对象变量,保存所有返回的结果
Query timeout:查询超时时间
Handle result set:定义如何处理由callable statements语句返回的结果
4、添加查看结果树
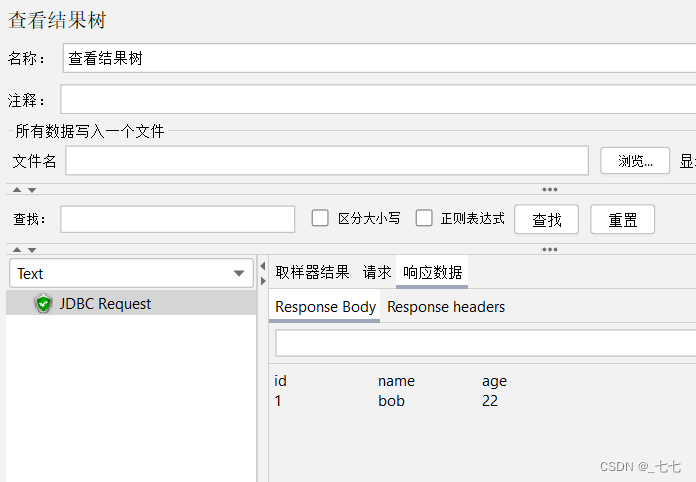
5、报错
Cannot create PoolableConnectionFactory (Access denied for user ‘root’@‘localhost’ (using password: YES))

解决:用户名密码不正确
6、案例
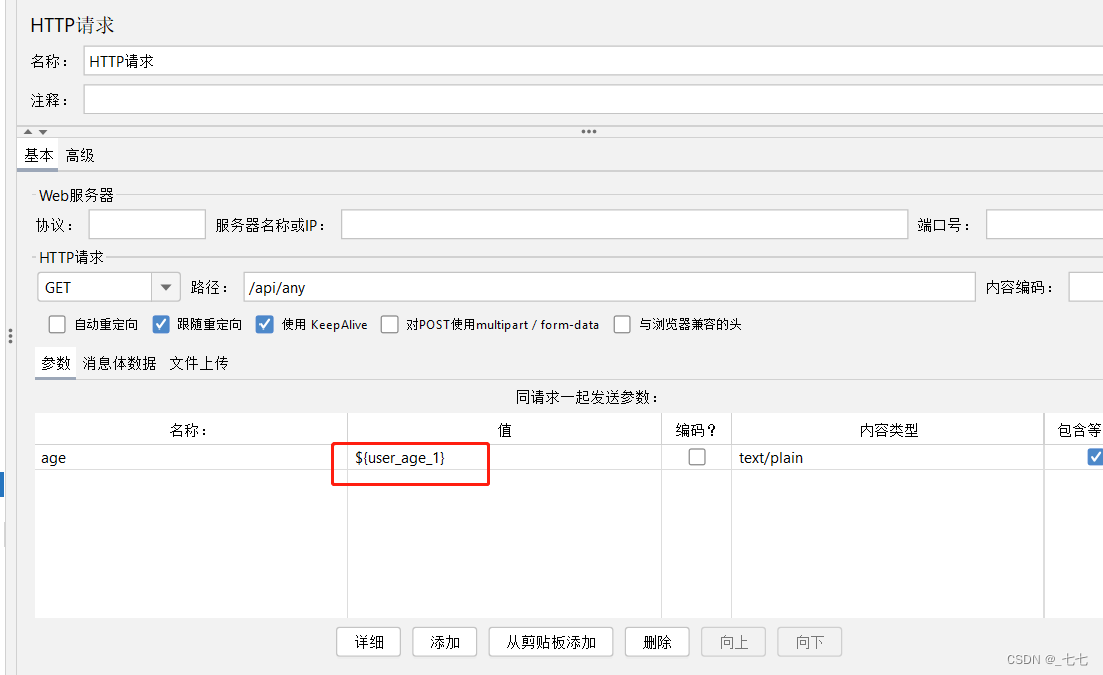
使用查询出的数据库变量,发出接口请求
16. JMeter逻辑控制器
逻辑控制器: 可以按照设定的逻辑控制取样器的执行顺序
常用的逻辑控制器
- 如果(If)控制器
- 循环控制器
- ForEach控制器
1、If控制器
If控制器用来控制它下面的测试元素是否运行
添加方式:测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> 如果(If)控制器
需求
- 使用‘用户定义的变量’定义一个变量name,name的值可以是‘jack’或‘bob’
- 根据name的变量值实现对应网站的访问
操作步骤
-
添加线程组
-
用户定义的变量
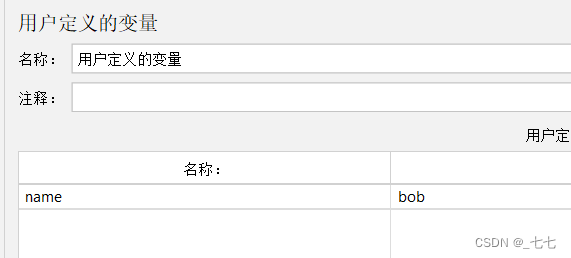
-
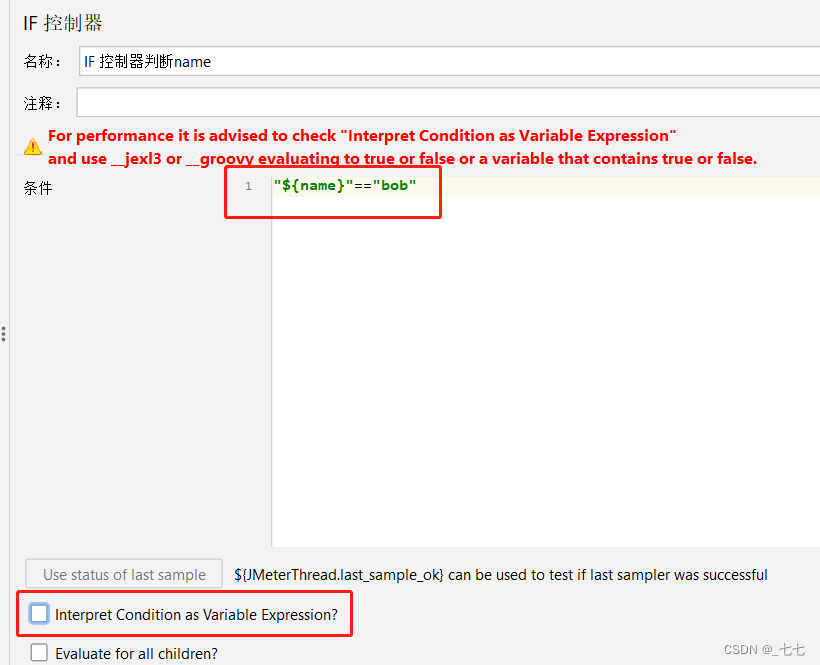
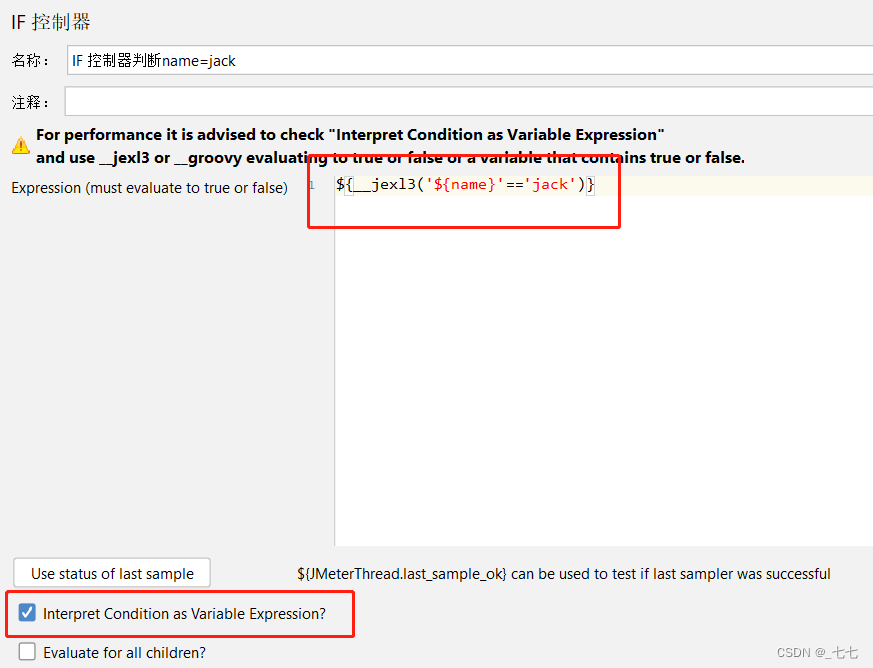
添加If控制器,判断name是否等于bob,判断name是否等于jack
JS语法形式:
函数形式:
-
添加HTTP请求,用来访问
-
添加查看结果树
2、循环控制器
作用:通过设置循环次数,来实现循环发送请求
位置:测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> 循环控制器

循环10次
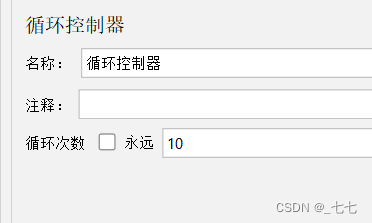
思考:线程组属性可以控制循环次数,那么循环控制器有什么用?
-
控制的作用域不同:线程组控制是线程组下的所有请求,循环控制器控制逻辑控制器下的所有请求;
-
线程组属性控制组内所有取样器的执行次数,而循环控制器可以控制组内部分取样器的循环次数,后者控制精度更高
-
如果线程组循环次数为M,循环控制器循环次数为N:
循环控制器下的HTTP请求运行:M*N次
线程组下的其他HTTP请求运行:M次
3、ForEach控制器
-
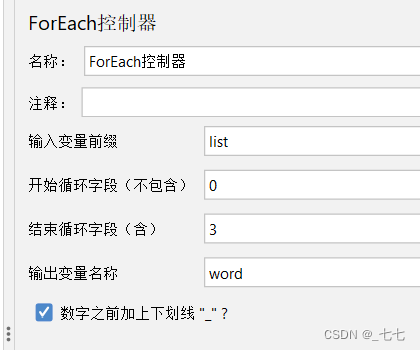
作用:
一般和用户自定义变量或者正则表达式提取器一起使用,读取返回结果中一系列相关的变量值。该控制器下的取样器都会被执行一次或多次,每次读取不同的变量值。 -
位置:测试计划 --> 线程组–> (右键添加) 逻辑控制器 --> ForEach控制器
需求
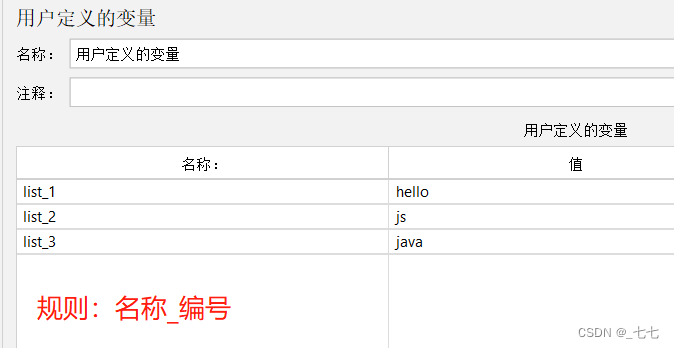
- 有一组关键字 [hello,python,测试],使用用户定义的变量存储
- 要依次取出关键字,并在百度搜索,例如:https://www.baidu.com/s?wd=hello
操作步骤
-
添加线程组
-
用户定义的变量
-
添加ForEach控制器
-
添加HTTP请求
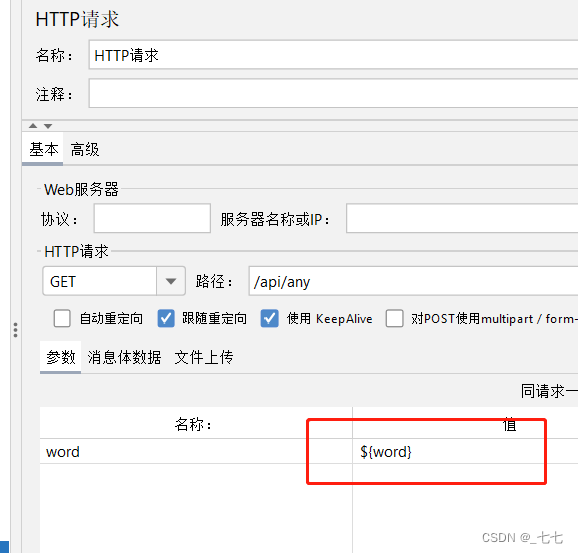
-
添加查看结果树
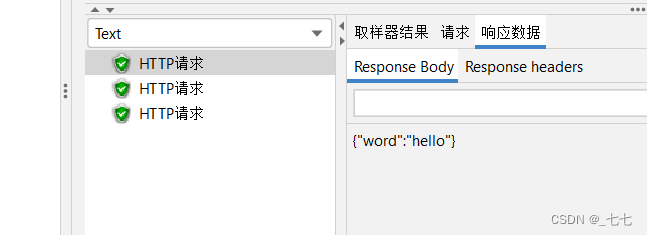
案例:
- 访问 123.sogou.com 获取首页中的地址信息,并全部保存下来
- 要依次取出关键字,并传递使用


17. JMeter定时器
1. 同步定时器(Synchronizing Timer)[集合点]
为什么要使用同步定时器?
- 如何模拟1w人同时使用电商网站?
- 如何模拟1w人同时进行电商网站中的抢购活动/秒杀活动?
- 如何模拟1000人同时抢红包?
(1)什么时候需要使用同步定时器?
- 测试抢购、秒杀或者抢红包等高并发的场景时使用
同步定时器:
-
阻塞线程(累积一定的请求),当在规定的时间内达到一定的线程数量,这些线程会在同一个时间点一起释放,瞬间产生很大的压力。
-
提示:在JMeter中叫做同步定时器,在Loadrunner中又叫集合点
-
SyncTimer的目的是阻塞线程,直到阻塞了n个线程,然后立即释放它们。
-
同步定时器相当于一个储蓄池,累积一定的请求,当在规定的时间内达到一定的线程数量,这些线程会在同一个时间点一起并发,所以可以用来做大数据量的并发请求
位置:测试计划 --> 线程组–> HTTP请求 --> (右键添加) 定时器 --> Synchronizing Timer
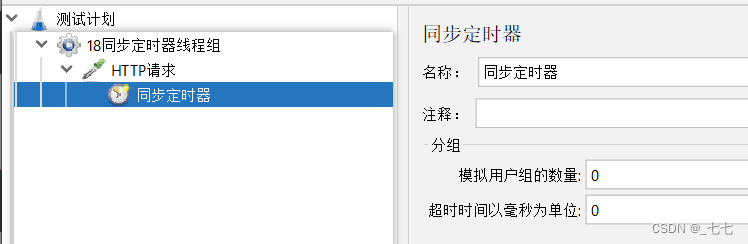
参数介绍:
- Number of Simulated Users to Group by:模拟用户的数量,即指定同时释放的线程数数量。
- 若设置为0,等于设置为线程组中的线程数量
- Timeout in milliseconds:超时时间,即超时多少毫秒后同时释放指定的线程数;
- 如果设置为0,该定时器将会等待线程数达到了设置的线程数才释放,若没有达到设置的线程数会一直死等。
- 如果大于0,那么如果超过Timeout in milliseconds中设置的最大等待时间后还没达到设置的线程数,Timer将不再等待,释放已到达的线程。默认为0
案例:
模拟1000个用户同时访问百度首页,统计高并发情况下运行情况
操作步骤
-
添加线程组,设置线程数=1000
ramp-up时间应该设置多少?需要确保 1000 个用户在设定的时间点(比如电商秒杀活动开始时)同时发起请求。因此,你可以将 Ramp-Up 时间设置为 0,这样所有的用户线程将会立即启动。
由于我们希望所有的用户都在同一时刻发出请求,所以不需要考虑逐渐增加用户的启动时间。将 Ramp-Up 时间设置为 0 将使得所有的用户线程立即启动,并且在同步定时器的作用下,在指定的时间点同时发起请求。 -
添加HTTP请求
-
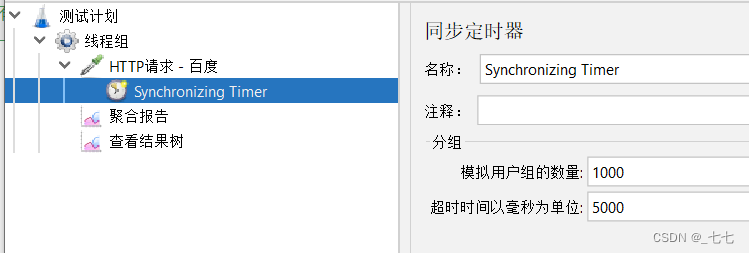
添加同步定时器,并发数线程数为 1000,表示等待所有 1000 个线程都到达同步点
- 设置并发线程数:同时发送请求的虚拟用户数
- 设置超时时间:
Ø建议设置:不设置的话,若没有达到设置的线程数会一直死等
Ø不能设置太小:等待时间后还没达到设置的线程数,会释放已到达的线程
-
添加查看结果树
-
添加监听器-聚合报告
2. 常数吞吐定时器(Constant Throughput Timer)、
介绍:
- 常数吞吐量定时器可以让JMeter以指定数字的吞吐量(以每分钟的样本数为单位,而不是每秒)执行。
- 吞吐量计算的范围可以为指定为当前线程、当前线程组、所有线程组。
为什么要使用常数吞吐量定时器?
- 稳定性测试时,要求模拟用户真实的业务场景。
- 如果用户真实业务场景的QPS为20如何精确模拟?
(1)什么时候需要使用常数吞吐量定时器?
- 需要按指定的吞吐量发送请求时,可以使用常数吞吐量定时器
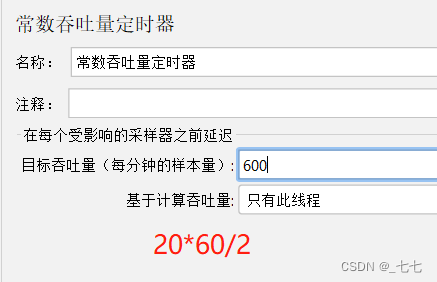
添加方式:测试计划 --> 线程组–> HTTP请求 --> (右键添加) 定时器 --> Constant Throughput Timer
场景
一个用户以 20QPS (20 次/s) 的频率访问百度首页,持续一段时间,统计运行情况
-
添加线程组,循环次数设置成永远
-
添加HTTP请求
-
添加常数吞吐定时器
-
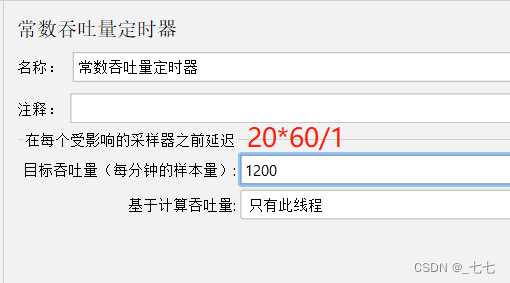
设置目标吞吐量:每个用户每分钟发送的请求数
-
计算方法:目标吞吐量= 要求QPS * 60 / 线程数
-
(1)一个用户以 20QPS (20 次/s) 的频率访问百度首页,持续一段时间,统计运行情况
-
(2)2个用户针对 (服务器的QPS要求:20QPS (20 次/s)) 的频率访问百度首页,持续一段时间,统计运行情况
-
-
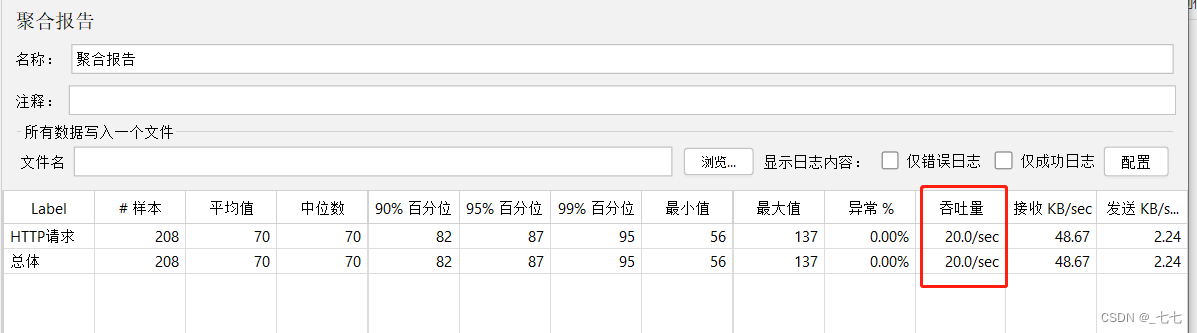
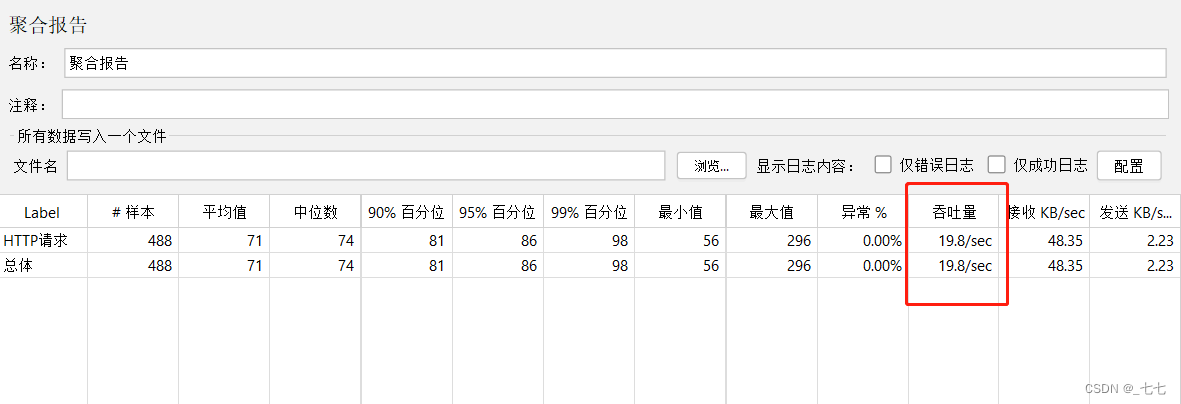
添加查看结果树
-
添加监听器-聚合报告
- 查看聚合报告的 Throughput 字段,实际值围绕设置的QPS值上下波动
3. 固定定时器
案例:
(1)系统登录错误3次后,锁定1分钟,等待1分钟后重新输入正确的用户名密码登录成功
- 步骤:
添加线程组
添加HTTP请求1 - 错误1次
添加HTTP请求2 - 错误2次
添加HTTP请求3 - 错误3次
添加HTTP请求4 - 正确用户名密码
在HTTP请求4下,添加固定定时器
添加查看结果树
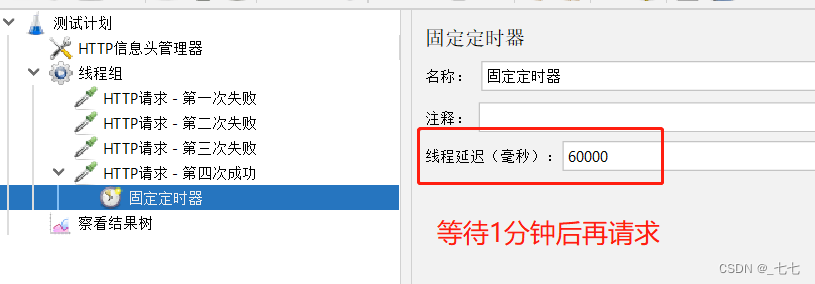
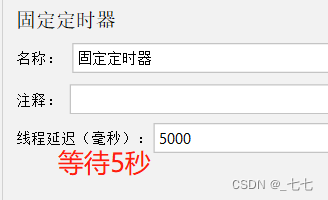
- 固定定时器,必须添加在需要等待的HTTP请求的子节点下
- 在HTTP信息头管理器中,修改HTTP请求的头域
18. JMeter分布式
为什么要使用分布式?
- 在使用JMeter进行性能测试时,如果并发数比较大(比如项目需要支持10000并发),单台电脑的(CPU和内存)可能无法支持,这时可以使用JMeter提供的分布式测试的功能。
应用场景
- 当单个测试机无法模拟用户要求的业务场景时,可以使用多台测试机进行模拟,就是Jmeter的分布式测试
JMeter分布式执行原理
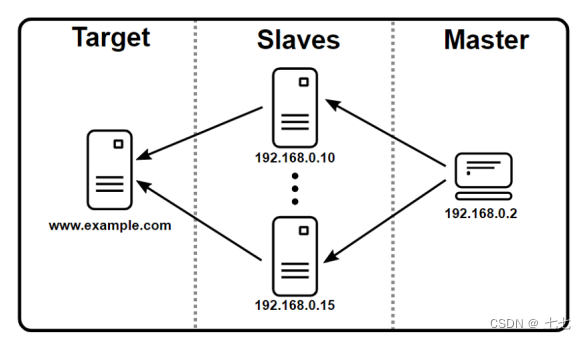
JMeter分布式测试时,选择其中一台作为控制机(Controller),其它机器做为代理机(Agent)。
- 执行时,控制机会把脚本发送到每台代理机上
- 代理机拿到脚本后就开始执行,代理机执行时不需要启动JMeter界面,可以理解它是通过命令行模式执行的。
- 执行完成后,代理机会把结果回传给控制机,控制机会收集所有代理机的信息并汇总。
代理机(Agent)配置
- Agent机上需要安装JMeter
- 修改服务端口
- 注意:非必须。如果是在同一台机器上演示需要使用不同的端口,多台机器可以不修改
- 打开bin/jmeter.properties文件,修改
server_port,比如:server_port=2001
- 将RMI SSL设置为禁用
- 打开bin/jmeter.properties文件,修改为:
server.rmi.ssl.disable=true
- 代理机(命令行方式启动):
- 运行Agent上的jmeter-server.bat文件,启动JMeter
控制机(Controller)配置
- 配置代理机远程地址:
- 修改JMeter的bin目录下jmeter.properties配置文件,修改
remote_hosts - 示例:
remote_hosts=192.168.182.100:1099,192.168.182.101:1099 - 配置每个代理机的IP+port,多个代理机之间用
,连接 - IP和Port是Agent机的IP以及自定义的端口,多台Agent之间用
,隔开
- 修改JMeter的bin目录下jmeter.properties配置文件,修改
- 将RMI SSL设置为禁用
- 打开bin/jmeter.properties文件,修改为:
server.rmi.ssl.disable=true
- 打开bin/jmeter.properties文件,修改为:
- 启动JMeter
- 控制机:
- 方式1、选择菜单:运行–>远程启动/远程全部启动
- 方式2、进入bin目录,运行jmeter.bat文件,启动JMete
案例
1、请求:https://www.baidu.com
2、一台控制机和两台执行机,做分布式;要求控制机启动,两台执行机执行,反馈结果操作步骤:
- 配置代理机一,并启动
- 配置代理机二,并启动
- 配置控制机,并启动
- 添加线程组
- 添加HTTP请求 – 百度
- 添加查看结果树
分布式相关注意事项
-
- 关闭防火墙
-
- 所有的控制机、代理机、服务器都在同一个网络上
-
- 所有机器的Jmeter和JAVA版本必须一致
-
- 关闭RMI SSL开关
-
- 修改完端口要重启JMeter
-
- 控制机和代理机最好分开,由于控制机需要发送信息给代理机并且会接受代理机回传的测试数据,所以控制机自身会有消耗
-
- 参数文件:如果使用csv进行参数化,那么需要把参数文件在每台slave上拷一份且路径需要设置成一样的;
-
- 每台机器上安装的JMeter版本和插件最好都一致,否则会出一些意外的问题;
总结
(1)什么时候需要使用分布式?
- 单台测试机无法满足用户要求的负载量时,使用多台机器来模拟
(2)JMeter分布式测试的原理?
- 执行时,控制机会把脚本发送到每台代理机上
- 代理机拿到脚本后就开始执行,接收服务器返回的响应
- 执行完成后,代理机会把结果回传给控制机
(3)JMeter分布式的配置和使用?
- 配置
- 代理机:修改服务端口server_port,禁用RMI SSL开关
- 控制机:配置代理机远程地址remote_hosts,禁用RMI SSL开关
- 使用:
- 代理机:命令行方式启动,运行jmeter-server.bat文件
- 控制机:运行jmeter.bat文件,启动JMeter,运行–>远程启动/远程全部启动
19. JMeter测试报告
为什么需要测试报告?
- 作用:收集性能测试结束后,系统的各项性能指标。如:响应时间、并发数、吞吐量、错误率等
1. 聚合报告
位置: 测试计划->右键->监听器->聚合报告

- Label:每个请求的名称(勾选:在标签中包含组名称,显示线程组名-取样器名)
- #样本:各请求发出的数量
- 平均值:平均响应时间(单位:毫秒)。默认是单个Request的平均响应时间
- 中位数:中位数,50% <= 时间
- 90%百分比:90% <= 时间
- 95%百分比:95% <= 时间
- 99%百分比:99% <= 时间
- 最小值:最小响应时间
- 最大值:最大响应时间
- 异常%:请求的错误率 = 错误请求的数量/请求的总数
- 吞吐量:吞吐量。默认情况下表示每秒完成的请求数,一般认为它为TPS。
- 接收 KB/sec:每秒从服务器端接收到的千字节数
- 发送 KB/sec:每秒向服务器发送的千字节数
2. html测试报告
JMeter支持生成HTML测试报告,以便从测试计划中获得图表和统计信息。
命令
- jmeter -n -t [jmx file] -l [result file] -e -o [html report folder]
- jmeter -n -t hello.jmx -l result.jtl -e -o ./report
参数描述:
-n:非GUI模式执行JMeter
-t [jmx file]:测试计划保存的路径及.jmx文件名,路径可以是相对路径也可以是绝对路径
-l [result file]:保存生成测试结果的文件,jtl文件格式
-e:测试结束后,生成测试报告
-o [html report folder]:存放生成测试报告的路径,路径可以是相对路径也可以是绝对路径
注意:result.jtl和report会自动生成,如果在执行命令时result.jtl和report已存在,必须用先删除,否则在运行命令时就会报错
查看测试报告
打开index.html
APDEX (应用性能指标)

- APDEX:计算每笔交易APDEX的容忍和满足阈值基于可配置的值,满意度,范围在 0-1 之间,1表示达到所有用户均满意;
- T(Toleration threshold):容忍或满意阈值
- F(Frustration threshold):失败阈值
Requests Summary(请求总结)
- 成功与失败的请求占比,KO指失败率,OK指成功率
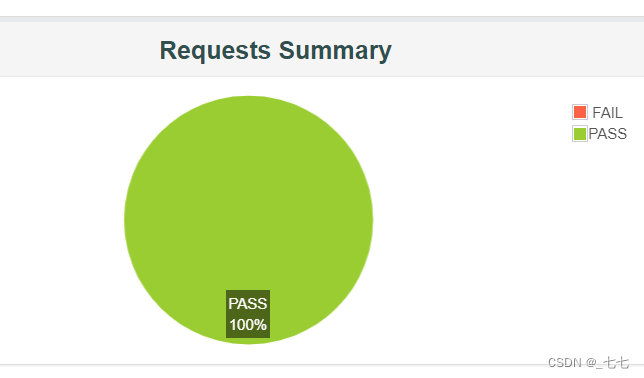
Chart(图表)
它包括Over Time(时间变化) 、Throughput(吞吐量) 、Response Times(响应时间)
20. 性能测试时TPS计算
为什么需要计算性能测试TPS?
- 稳定性测试时需要模拟用户真实负载量,真实负载量是多少 ?
- 压力测试时需要模拟高负载验证系统的容错能力,高负载有多高 ?
案例:
根据数据统计,在2019年第32周,日均PV为4.13万,需要计算TPS
1. 普通计算方法
-
计算公式:
- TPS= 总请求数 / 总时间
- 只能满足最基本的要求,但是不能很好覆盖系统正常的使用情况
-
数据分析:
- 根据数据统计,在2019年第32周,日均PV为4.13万,可以估算为1天有4.13万请求(1次浏览都至少对应1个请求)总请求数 = 4.13 万请求数 = 41300
总时间 = 1天 =1 * 24 小时=24 * 3600 秒
- 根据数据统计,在2019年第32周,日均PV为4.13万,可以估算为1天有4.13万请求(1次浏览都至少对应1个请求)总请求数 = 4.13 万请求数 = 41300
-
套入公式:
- TPS = 41300请求数/24*3600秒 = 0.48请求数/秒
-
结论:
- 按照普通计算方法,理论上每秒能够处理0.48请求,就可以满足线上的需要
2. 二八原则计算方法
二八原则就是指80%的请求业务在20%的时间内完成
- 计算公式 :
- TPS = 总请求数 80% / (总时间20%)
- 满足系统绝大多数情况下的应用场景的需要
- TPS = 41300 * 0.8请求数 / 2436000.2秒 = 1.91 请求数/秒
- 结论:按照二八原则计算,在测试环境我们的TPS只要能达到1.91请求数每秒就能满足线上需要。二八原则的估算结果会比平均值的计算方法更能满足用户需求。
3. 根据业务运营数据的统计计算(通常用来做稳定性测试)
并发TPS = 有效请求数 * 80% / 有效时间 * 20%
当运营数据统计越精确时,计算出的并发TPS与实际的越接近

数据分析:
根据这些数据统计图,可以得出结论:
- 大部分订单在8点-24点之间,因此系统的有效工作时长为16个小时
- 从订单数量统计,8-24点之间的订单占一天总订单的98%左右(40474个)
结合二八原则计算公式 : TPS = 总请求数 * 80% / (总时间*20%) :
- 需要在测试环境模拟用户正常业务操作(稳定性测试)的并发量为:
TPS = 40474 * 0.8请求数 / 1636000.2秒 = 2.81 请求数/秒
4. 根据用户峰值业务操作来计算(通常用来做压力测试)
并发TPS = 峰值请求数 / 峰值时间 * 系数
专门用于满足极端的用户业务场景下的性能需求
-
满足峰值请求时间段内的负载量,系数取决于项目组对于未来业务量的评估,相当于冗余量
-
比如订单最高峰在在21点-22点之间,一小时的订单总数大约为8853个
计算压力测试的并发数:TPS = 峰值请求数/峰值时间 * 系数 -
需要在测试环境模拟用户峰值业务操作(压力测试)的并发量为:
TPS = 8853 请求数 / 3600秒 * 3(系数) = 7.38 请求数/秒
案例
某购物商城,经过运营统计,正常一天成交额为100亿,客单价平均为300元,交易时间主要为10:00-14:00,17:00-24:00,其中19:00—20:00的成交量最大,大约成交20亿。
现升级系统,需要进行性能测试,保证软件在上线后能稳定运行。
请计算出系统稳定性测试时的并发(负载)量,及保证系统峰值业务时的并发(负载)量
-
稳定性并发量:
并发TPS = 有效请求数 * 80% / 有效时间 * 20%
并发TPS = (100E/300 * 80%) / (3600 * 11 * 20%) -
压力并发量:
并发TPS = 峰值请求数 / 峰值时间 * 系数
压力TPS = (20E/300) / (3600 * 1) * 系数
21. Jmeter下载第三方插件
说明:先下载JMeter插件管理工具包,再用此包下载JMeter插件
- 下载包管理工具jar包
- 将包管理工具jar包添加到jmeter中
提示:存放到jmeter安装目录 lib\ext\目录下 - 下载性能测试常用组件
下载: https://jmeter-plugins.org/install/Install/
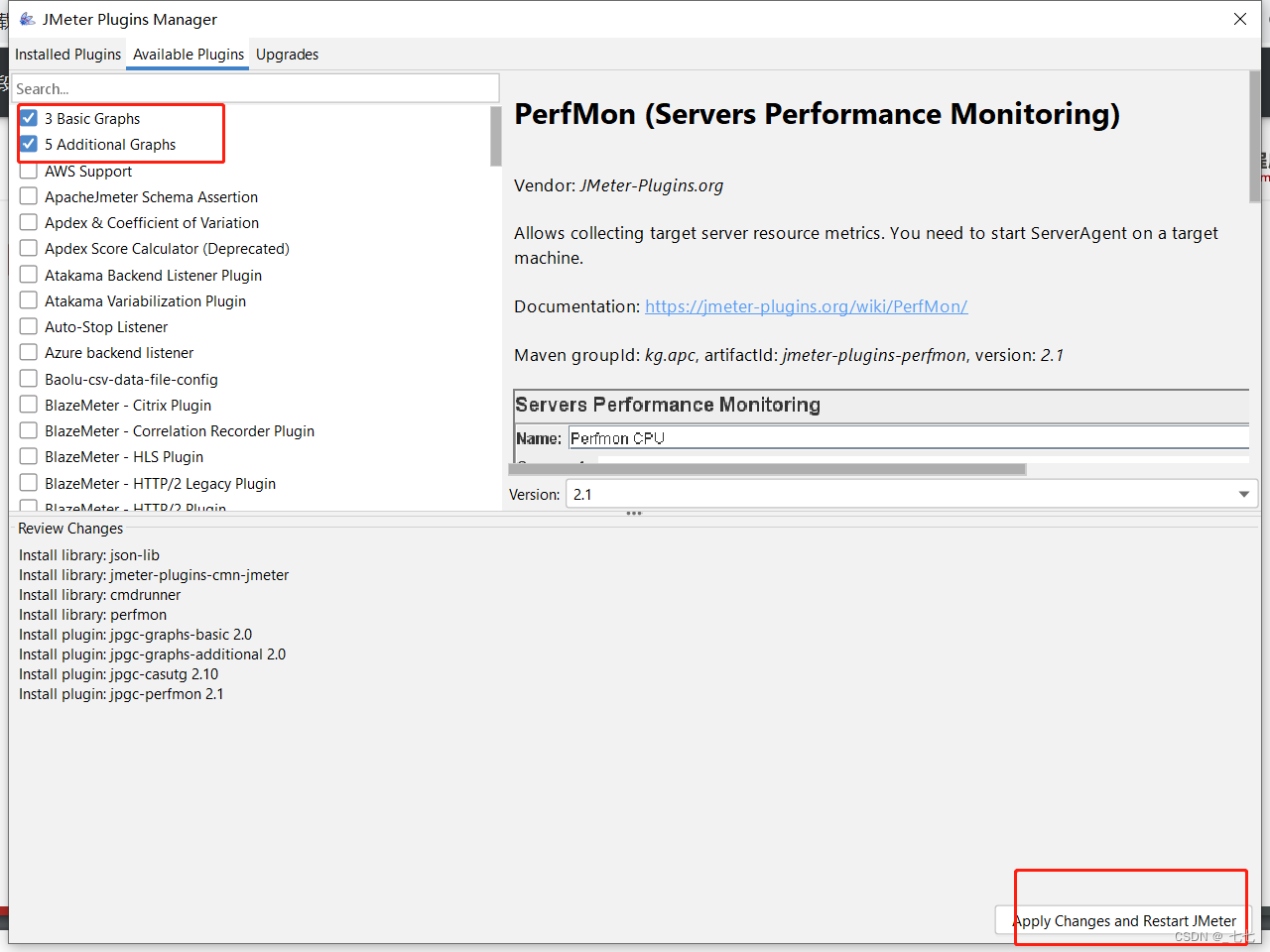
安装如下指定的插件
- 3 Basic Graphs
- 5 Additionally Graphs
- Custom Thread Groups
- PerfMon
22. 性能测试常用图表及组件
- Concurrency Thread Group 线程组
- Transactions per Second 每秒事务数
- Bytes Throughput Over Time 吞吐量
- PerfMon Metrics Collector 性能指标收集器
1. Concurrency Thread Group 线程组
说明:阶梯线程组
作用:
- 线程数阶梯上升
- 图形化的展示
添加方式:测试计划 --> 线程(用户)–> Concurrency Thread Group
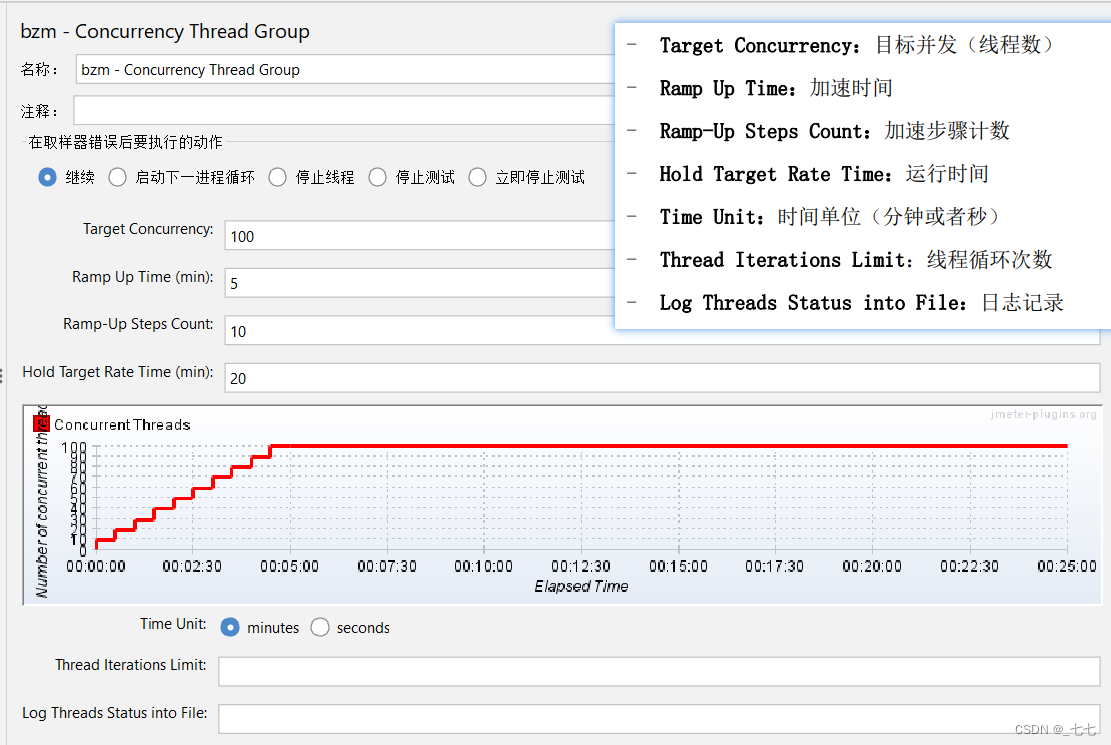
参数:
重点:
Target Concurrency:目标并发(线程数)
Ramp Up Time:加速时间
Ramp-Up Steps Count:加速步骤计数
Hold Target Rate Time:运行时间
Time Unit:时间单位(分钟或者秒)
了解:
Thread Iterations Limit:线程迭代次数限制(循环次数)
Log Threads Status into File:将线程状态记录到文件中(将线程启动和线程停止事件保存为日志文件)
2. 每秒性能指标统计
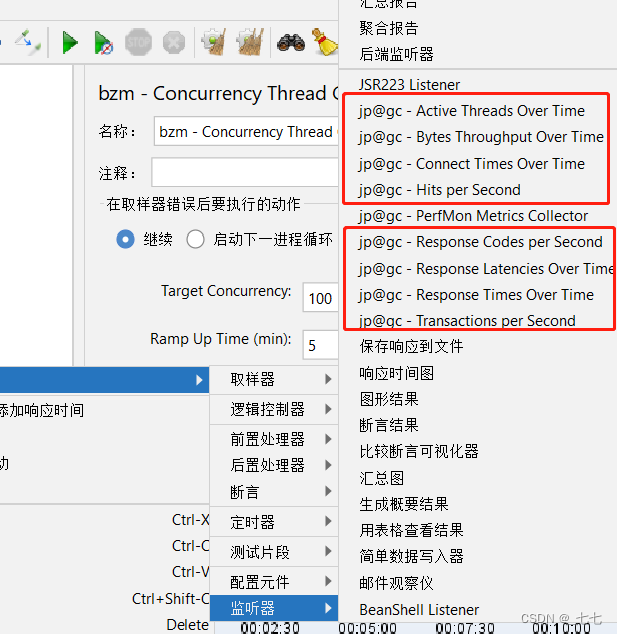
Transactions per Second
每秒完成事务数:作用是统计各个事务每秒钟成功的事务个数
添加方式:测试计划 --> 线程组–> 监听器–>Transactions per Second
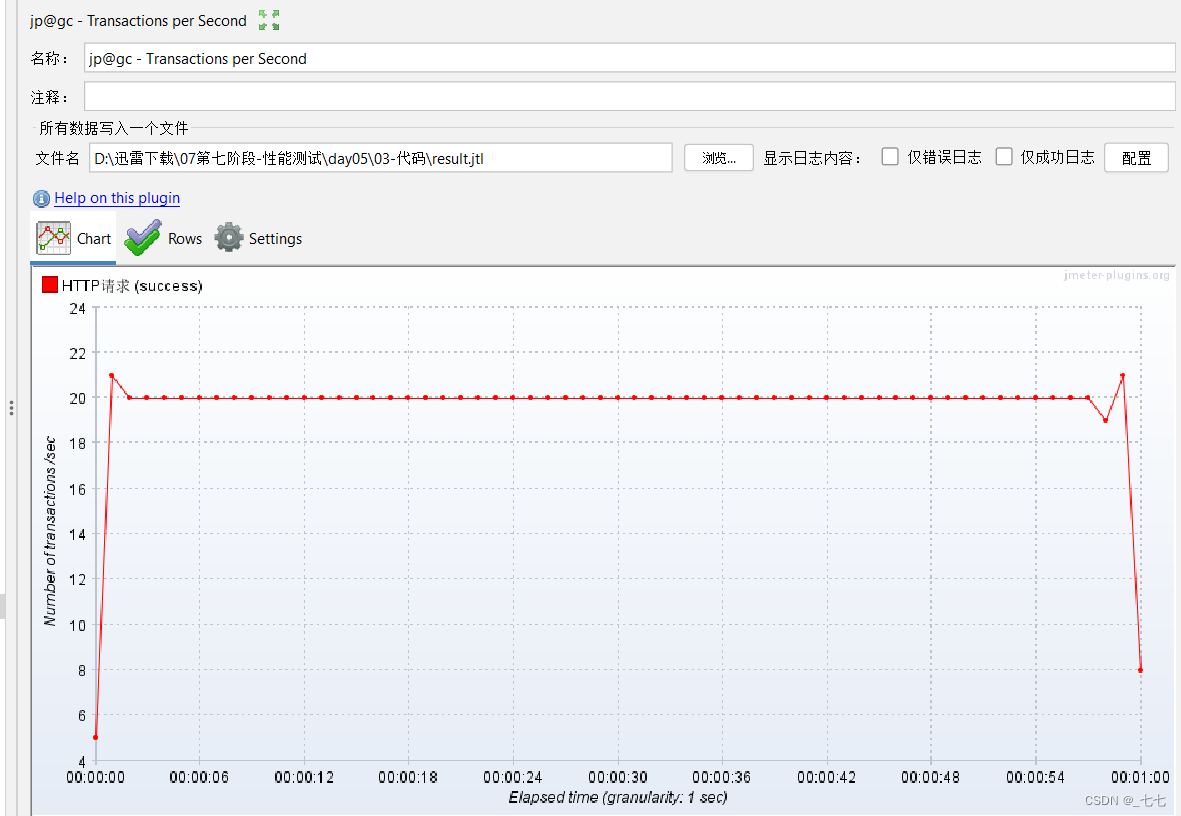
Bytes Throughput per Second
每秒字节吞吐量:作用是查看服务器吞吐流量(单位/字节)
添加方式:测试计划 --> 线程组–> 监听器–>Bytes Throughput Over Time
- Transactions per Second和聚合报告中的TPS在性能测试时的作用有何不同,以哪个为准?
- 性能测试的结果统计,以聚合报告的结果为准
- 每秒性能指标的作用是:查看系统长时间运行过程中是否有异常出现,有则进一步分析
23.Concurrency Thread Group 和stepping thread group的区别

JMeter 中的 Concurrency Thread Group 和 Stepping Thread Group 是两种不同的线程组,它们在功能和使用方式上有所区别。
-
Concurrency Thread Group(并发线程组):
- Concurrency Thread Group 是 JMeter 5.0 版本引入的新特性。
- 它允许你以一种更直观和简单的方式定义并发用户数量。
- 可以设置线程数的起始值、目标值和持续时间,JMeter 会根据设定的参数自动进行线程数的增减来维持并发用户数量。
- 适合模拟用户数量的动态变化,比如在某个时间段内逐渐增加或减少并发用户数。
-
Stepping Thread Group(步进线程组):
- Stepping Thread Group 是 JMeter 较早版本就存在的线程组。
- 它允许你设置线程数的起始值、增加步长、持续时间和步长间隔。
- Stepping Thread Group 会根据设定的参数逐步增加线程数,并在达到最大线程数后持续运行一段时间,然后再逐步减少线程数。
- 适合模拟用户数量逐步增加或减少的场景,比如逐渐增加负载并观察系统的性能。
总结:
- Concurrency Thread Group 更加灵活,可以根据设定的参数自动调整线程数,模拟并发用户数量的动态变化。
- Stepping Thread Group 则是通过逐步增加或减少线程数来模拟负载的变化,更适合于逐步增强或减弱压力的场景。
选择使用哪种线程组取决于你需要模拟的测试场景和需求。如果你需要灵活地控制并发用户数量,并且用户数量可能会动态变化,则可以选择 Concurrency Thread Group。如果你需要逐步增加或减少负载,并观察系统在不同负载下的性能表现,则可以选择 Stepping Thread Group。
24. PerfMon组件监控服务器资源
作用:
用来监控服务端的性能资源指标的工具,包括cpu、内存、磁盘、网络等性能数据添加
方法:
线程组->监听器->jp@gc - PerfMon Metrics Collector
注意:
使用之前需要在服务器端安装监听服务程序并启动
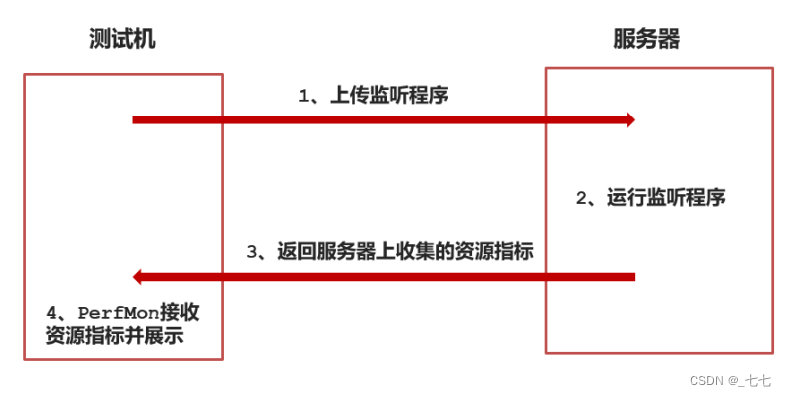
- 下载安装包ServerAgent-2.2.3.zip,链接地址:https://github.com/undera/perfmon-agent
- 解压ServerAgent-2.2.3.zip
- 启动,如果是windows运行startAgent.bat,如果是linux运行startAgent.sh
- 启动这个工具后,jmeter的插件jp@gc - PerfMon Metrics Collector就可以收集服务端的资源使用率,并在jmeter中查看了
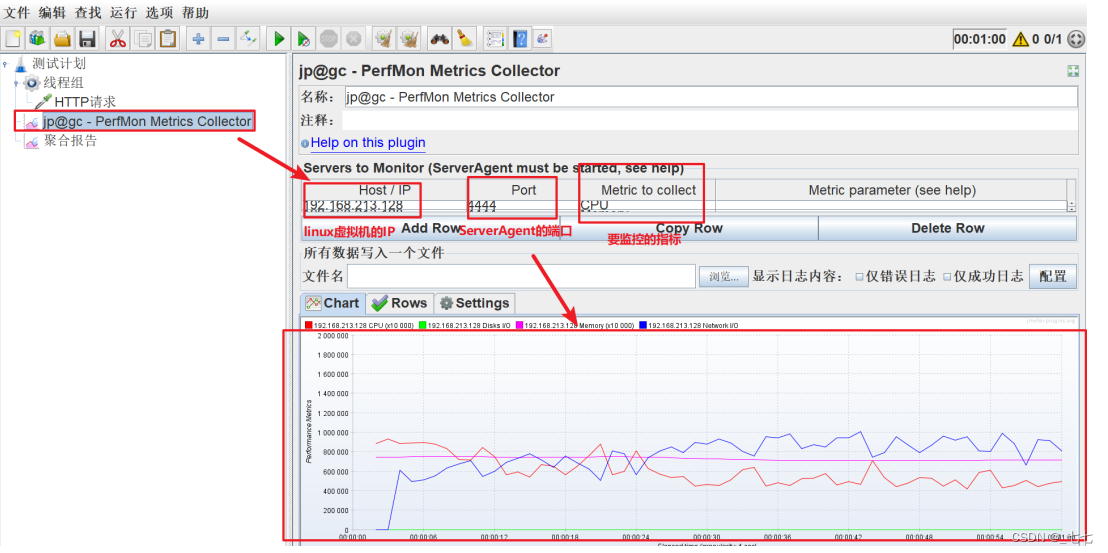
监控性能指标的步骤(linux服务器)
(1)解压缩: unzip ServerAgent2.2.3.zip
(2)进入ServerAgent目录,赋权限:
cd ServerAgent-2.2.3
chmod -R 777 *
(3)启动ServerAgent程序
./startAgent.sh
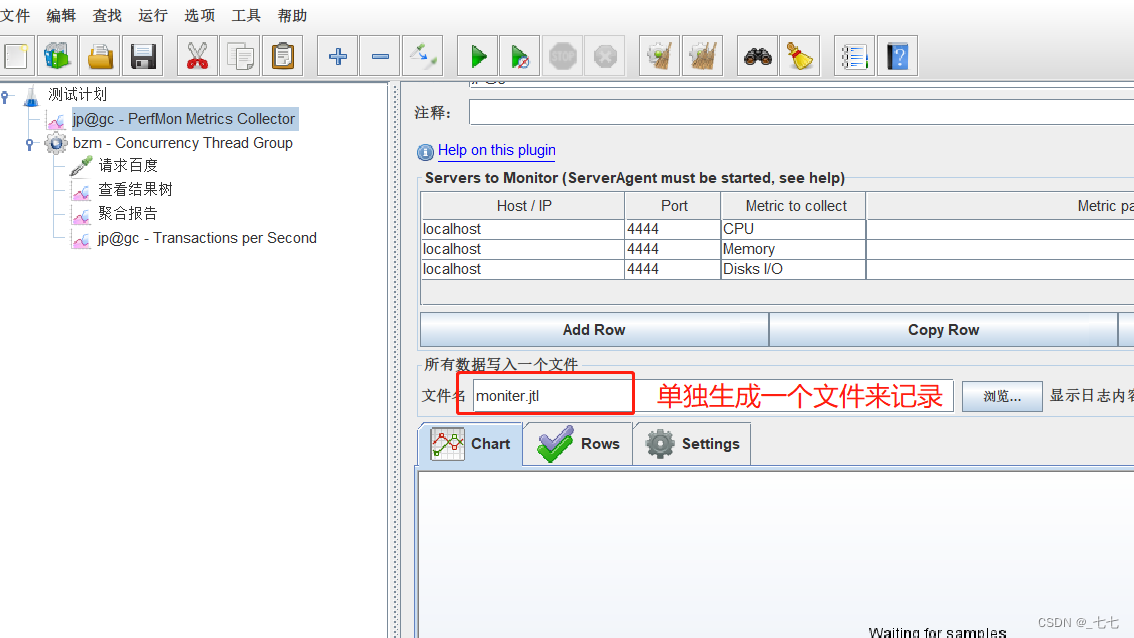
启动监控后:

jtl结果写入查看
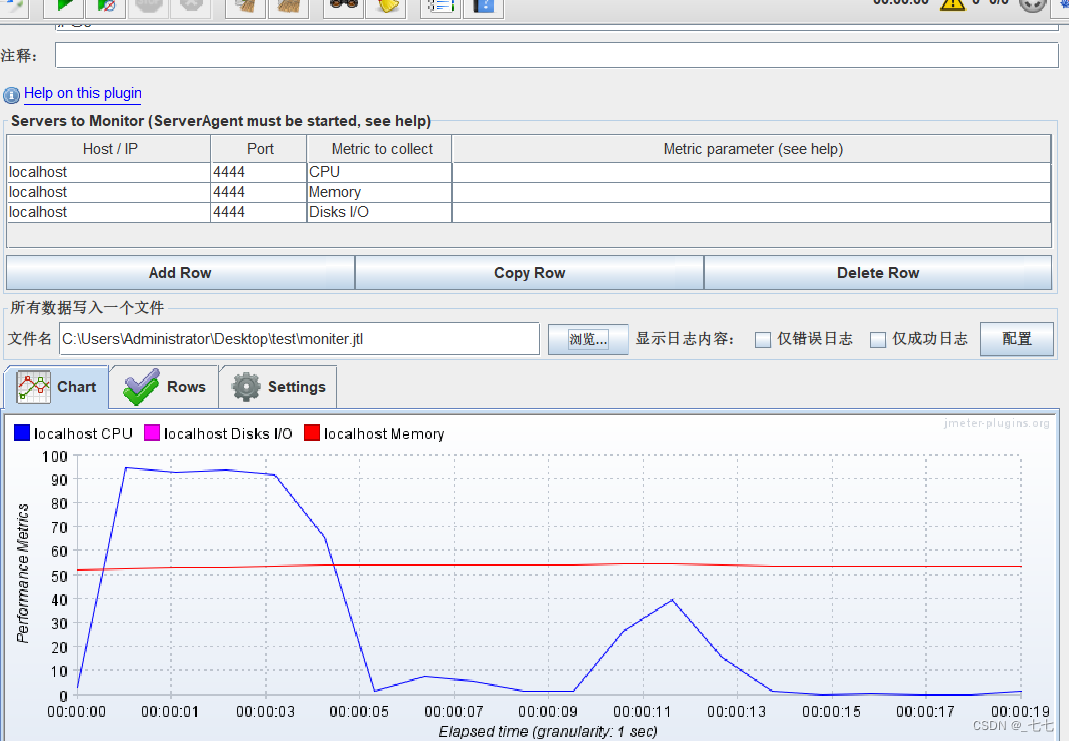
ServerAgent的端口号
ServerAgent 是一款用于性能测试的工具,它通常使用默认的端口 4444 进行通信。如果您没有修改默认配置,则 ServerAgent 将会在 4444 端口上运行,并等待来自 JMeter 的连接。
如果您已经启动了 ServerAgent 并希望验证它是否正在侦听 4444 端口,请使用以下命令:
netstat -tlnp | grep 4444
该命令将显示所有正在侦听 4444 端口的进程。如果 ServerAgent 正在运行并已正确配置,则应该看到类似于以下内容的输出:
tcp 0 0 0.0.0.0:4444 0.0.0.0:* LISTEN 12345/java
其中,12345 是 ServerAgent 进程的 PID。
25. 性能分析和调优
1. 性能测试瓶颈分析
在实际的性能测试中,会遇到各种各样的问题,比如TPS压不上去,导致这种现象的原因很多,作为测试人员应配合开发人员进行分析尽快找出瓶颈的所在。
常见性能瓶颈分析:
- 服务器资源分析—— 影响应⽤服务器和数据库服务器处理的速率 和 网络传输速率
- CPU瓶颈分析
- CPU已压满(接近100%),需要再看其他指标的拐点出现的时刻是否与CPU压满的时刻基本一致
- 内存瓶颈分析
- 内存不足时,操作系统会使用虚拟内存,从虚拟内存读取数据,影响处理速度
- 磁盘I/O瓶颈分析
- 磁盘I/O成为瓶颈时,会出现磁盘I/O繁忙,导致交易执行时在I/O处等待
- 网络带宽
- 如果接口传递的数据包过大,超过了带宽的传输能力,就会造成网络资源竞争,导致TPS上不去
- CPU瓶颈分析
- JVM瓶颈分析—— JAVA程序运⾏的环境
- 分析JVM的内存
- 数据库瓶颈分析—— 数据库程序运⾏环境分析
- 慢查询
- 数据库的连接池设置太小,导致数据库连接出现排队
- 数据库出现死锁
- 程序内部实现机制 —— 开发⼈员编写的代码分析
- 压测机 —— 影响性能结果
- JMeter单机负载能力有限,如果需要模拟的用户请求数超过其负载极限,也会导致TPS压不上去
2. 性能调优的步骤
- 确定问题。根据性能测试的结果来分析确定bug —— 测试⼈员职责
- 分析原因。分析问题产⽣的原因 —— 开发⼈员职责
- 给出解决⽅案。可以是修改软件配置、增加硬件资源配置、修改代码等 —— 开发⼈员职责
- 验证解决⽅案。—— 测试⼈员回归测试
- 分析验证结果 —— 既要保证有问题的指标得到解决,⼜要保证其他指标没有出现新问题
- 注意:
性能分析和调优需要经过很多轮,才能最终解决问题
1、服务器资源分析 —— CPU瓶颈
每个程序运行都需要占用CPU,那么单CPU的机器是如何同时运行多个程序的?
-
时间片即CPU分配给各个程序的时间,每个程序被分配一个时间段,称作它的时间片,即该程序允许运行的时间

-
CPU时间:单位HZ,
- 将CPU划分为若干个时间片,为每个程序分配对应的时间片,保证所有的程序占⽤时间片来串行执行
-
CPU使用率:表示一段时间内,正在使用的CPU时间段 / 总的CPU时间段 * 100%
-
CPU使用率分为用户态、系统态和空闲态
- 总时间片 = ⽤户CPU + 系统CPU + 空闲CPU
- Ø 用户态:表示 CPU 处于应用程序执行的时间;所有应⽤程序运行时消耗的CPU;
- Ø 系统态:表示系统内核执行的时间;操作系统运⾏消耗的CPU;
- Ø 空闲态:表示空闲系统进程执行的时间
查看CPU使用率的命令:top
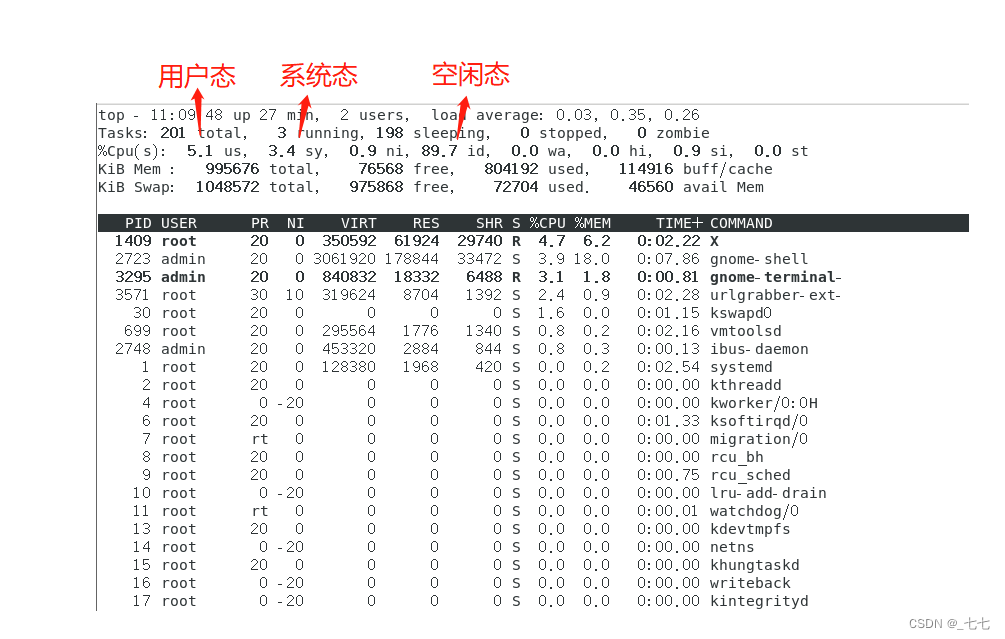
测试关注点:
- 当CPU使用率高时,确定是用户CPU高,还是系统CPU高
- 如果是用户CPU高,说明某个软件程序的CPU资源占用率高,需要定位代码程序运行的效率
- 如果是系统CPU高,同步观察是否是其他资源(磁盘IO、内存、网络等)不足
2、服务器资源分析 —— 内存和虚拟内存
- 内存:又称主存储器/物理内存,机器实际的内存空间,计算机中所有程序的运行都在内存中进行
- 虚拟内存:⼀种虚拟化的技术。是计算机系统内存管理的一种技术。当计算器内存不足时,可以使用虚拟内存进行补偿;从磁盘中读⼊数据,处理完成后写回磁盘,以此进行交换,保证在内存不足时,程序也能够运⾏。
- 在程序运行时,可以将程序的一部分装入内存,而将其余部分留在
外存(磁盘),就可以启动程序执行。 - 在程序执行过程中,当所访问的信息不在内存时,由操作系统将所
需要的部分调入内存,然后继续执行程序。 - 同时,操作系统将内存中暂时不使用的内容换出到外存上,从而腾
出空间存放将要调入内存的信息。 - 这样,系统好像为用户提供了一个比实际内存大得多的存储器,称
为虚拟存储器。
- 在程序运行时,可以将程序的一部分装入内存,而将其余部分留在
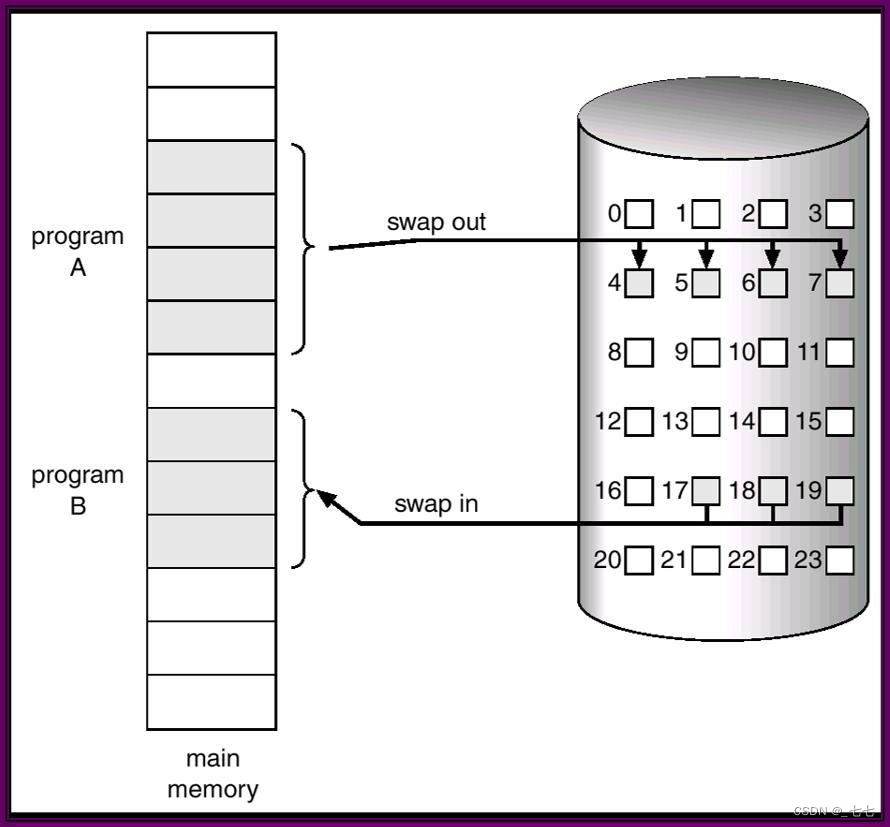
- 内存瓶颈:
- 内存不足时,操作系统会使用虚拟内存,从虚拟内存读取数据;而内存的速度要远快于磁盘速度,因此使用虚拟内存时性能大大降低。此当使⽤虚拟内存时,说明内存已经不⾜,可能存在问题
查看总量:top
查看虚拟内存的使用量:vmstat

Swap:
- si: 每秒从交换区写到内存的大小
- so: 每秒写入交换区的内存大小
测试关注点:
- 实际内存:查看内存使⽤百分⽐,检查是否超过80%
- 虚拟内存:查看swap的si和so是否为0,如果不为0,说明内存可能不足;(需要大量的从内存和虚拟内存之间读来读去,说明内存盛不开那么多进程,说明内存不足)
3、服务器资源分析 —— 磁盘IO瓶颈
磁盘IO瓶颈:影响性能的是磁盘的读写速度(Input和Output速率),不是磁盘大小。
查看磁盘IO使用的命令:iostat -x 1 1

- %util: 表示一秒中有百分之多少的时间用于 I/O
- %iowait:CPU等待输入输出完成时间的百分比。
测试关注点:
- 如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷
- 如果%iowait的值过高,表示硬盘存在I/O瓶颈
4、服务器资源分析 —— 网络瓶颈
网络瓶颈:影响性能的是网络的传输速度,与网络的总带宽进行对比,接近总带宽,说明网络存在瓶颈。
查看网络使用的命令:sar -n DEV 1 2
- rxkB/s: 每秒接收的数据量(千字节数)
- txkB/s: 每秒发送的数据量(千字节数)

测试关注点:
- 将每秒接收的数据量rxkB/s,与网络最大带宽进行对比,如果实际传输速率接近网络最大带宽,查看使用的百分比(如果⽆限接近100%,说明存在⽹络性能瓶颈)说明网络IO有瓶颈
补充介绍:
- 宽带:⽤户(业务)维度来描述⽹络速率的⽅式。例如:20M宽带、100M宽带、1000M宽带
- 速率单位:b(bit)/s
- 带宽:数据在⽹络中传输的速率,在技术中都是通过带宽来描述速率
- 速率单位:B(Byte)/s
1B = 8bit
- 速率单位:B(Byte)/s
- 实际情况:1000M宽带 —— 对应着的带宽速率为 1000/8 = 125M
5、数据库瓶颈分析 —— 慢查询
- 慢查询定义:指执行速度低于设置的阀值的SQL语句
- 作用:帮助定位查询速度较慢的SQL语句,方便更好的优化数据库系统的性能
- 查询慢查询的相关参数:
show variables like "" - 设置慢查询的相关参数:
set global 参数名 = 值 - MySQL慢查询参数介绍:
show variables like 'slow_query_log': 慢查询日志开启状态[ON:开启,OFF:关闭]show variables like 'slow_query_log_file': 慢查询日志存放位置show variables like 'long_query_time': 慢查询时长设置(超过该时长才会被记录,单位:秒)
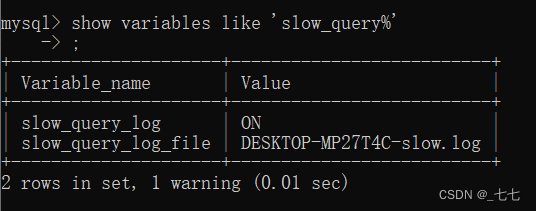
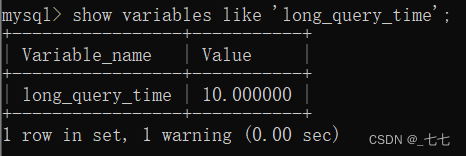
- 慢查询开启并配置:
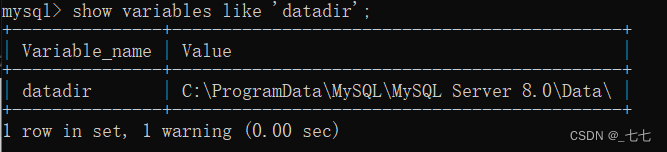
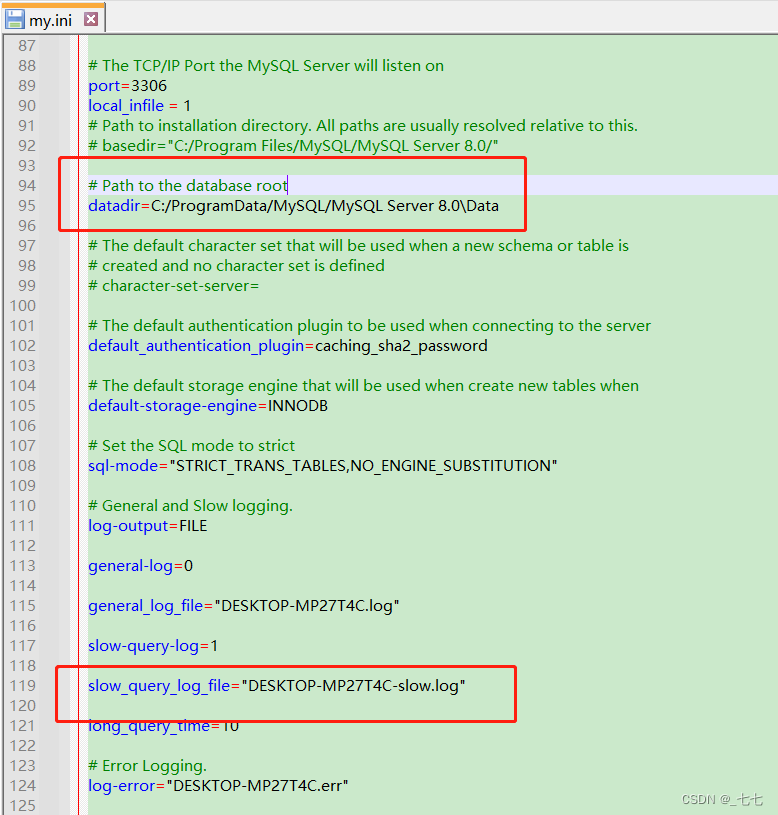
mysql> set global slow_query_log='ON'; #开启慢查询日志mysql> set global slow_query_log_file='/data/slow_query.log'; #设置慢查询日志存放位置mysql> set global long_query_time=1; # 设置慢查询时间标准,设置之后会在下次会话才生效
- 测试关注点:
基于当前记录下来的慢查询sql进行进一步的分析,判断是否存在问题,需要修改
6、数据库瓶颈分析 —— 数据库连接池
-
数据库连接池:
事先建立好连接,当程序请求sql执行时,直接分配空闲连接,使用完成后释放连接。节省了SQL语句执行前后连接的建立和关闭的时间。 -
数据库连接池定义:
数据库连接池是负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个。 -
作用:
可以提高对数据库操作的性能
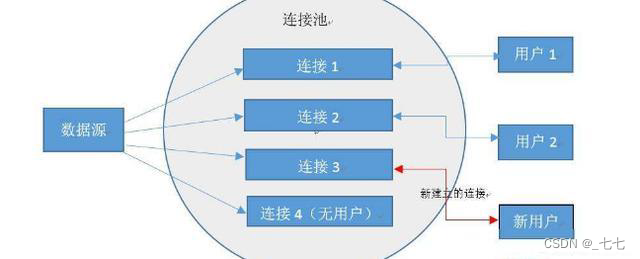
当客户请求数据库连接时
-
- 首先查看连接池中是否有空闲连接,如果存在空闲连接,则将连接分配给客户使用;
-
- 如果没有空闲连接,则查看当前所开的连接数是否已经达到最大连接数,如果没达到就重新创建一个连接给请求的客户;
-
- 如果达到就按设定的最大等待时间进行等待;
-
- 如果超出最大等待时间,则抛出异常给客户;
测试关注点:
- MYSQL官网给出了一个设置最大连接数的建议比例:Max_used_connections / max_connections * 100% ≈ 85%,需要关注MYSQL的最大连接数 和 系统运行时数据库已建立连接数的比例
- 如果已使用连接数与最大连接数比例超过85%(利用率超过85%,连接池可能会被占满),需要增加最大连接数设置,否则会造成连接失败
- 如果已使用连接数与最大连接数比例小于10%(利用率过低,说明资源存在浪费,可能会影响其他性能指标),那显然设置的过大,会造成系统资源的浪费
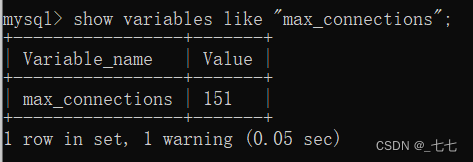
查看 MYSQL 最大连接数:
- 最大连接数:show variables like “max_connections”;
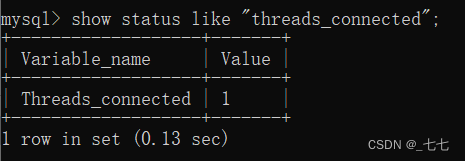
查询当前数据库已建立连接数:
- show status like “threads_connected”;
7、数据库瓶颈分析 —— 数据库死锁
MySQL主要有两种锁:表级、行级。
- 表级锁:开销小,加锁快;不会出现死锁;锁定粒度最大,并发度最低。
- 行级锁:开销大,加锁慢;会出现死锁;锁定粒度最小,并发度也最高。
死锁:是指两个或两个以上的进程在执行过程中,因争夺资源而造成的一种互相等待的现象。
- 若无外力作用,它们都将无法推进下去.此时称系统处于死锁状态或系统产生了死锁。
- 表级锁不会产生死锁
测试关注点(初步确定死锁):
-
show open tables where in_use>=1 查询当前是否锁表
- 如果表锁了,这个sql可以查询出来
- 但是这个sql查出来的表,不一定是被锁住的。因为用查询,如果耗费时间很长,也会查询出来
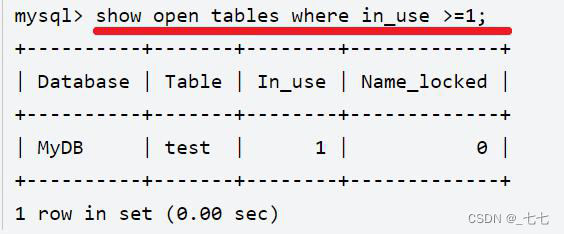
-
show processlist:查看执行时间最长的线程,找到对应sql,找到表
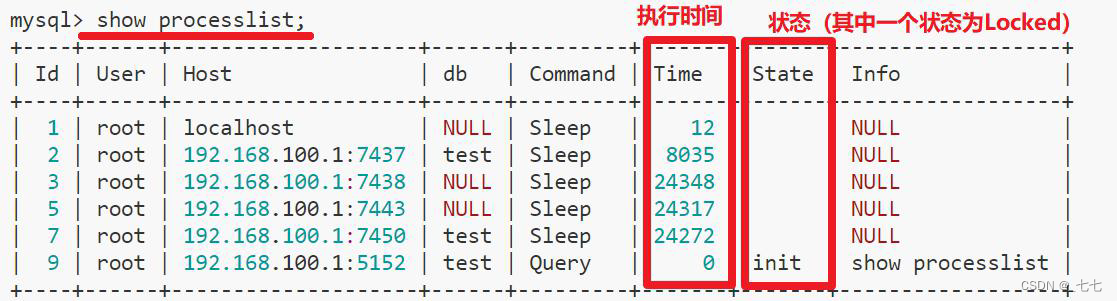
- kill process_id:如果需要先紧急解决问题,可以先手动杀死死锁的连接
8、 JAVA应用瓶颈分析 —— JVM内存
JVM内存:Java 虚拟机在执行 Java 程序的过程中所管理的不同的内存数据区域。可简单分为:堆内存和非堆内存
- 堆内存:主要存放用new关键字创建的对象,所有对象实例以及数组都在堆上分配。 —— 给开发人员使用的(关注)
- 非堆内存:保存虚拟机自己的静态数据,存放加载的Class类级别静态对象如类、方法等。 —— 给JVM自己使用的
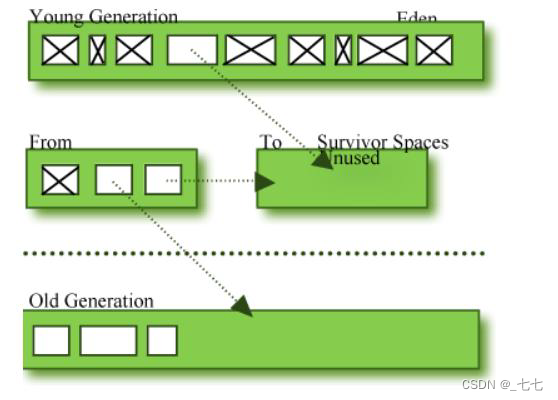
JVM堆内存的管理机制(JAVA垃圾回收机制):
- 年轻代存储“新生对象”,我们新创建的对象存储在年轻代中。
- 当年轻内存占满后,会触发Minor GC,清理年轻代内存空间。
- 老年代存储长期存活的对象和大对象。年轻代中存储的对象,经过多次GC后仍然存活的对象会移动到老年代中进行存储。
- 老年代空间占满后,会触发Full GC。Full GC是清理整个堆空间,包括年轻代和老年代
JAVA应用瓶颈分析 —— JVM内存分析
常见的内存问题:
- 内存泄漏:
- 内存泄露 memory leak,是指程序在申请内存后,无法完全释放已申请的内存空间。
- 一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
- 内存溢出:
- 内存溢出 out of memory,是指程序在申请内存时,没有足够的内存空间供其使用,出现out of memory
- memory leak会最终会导致out of memory
测试关注点:
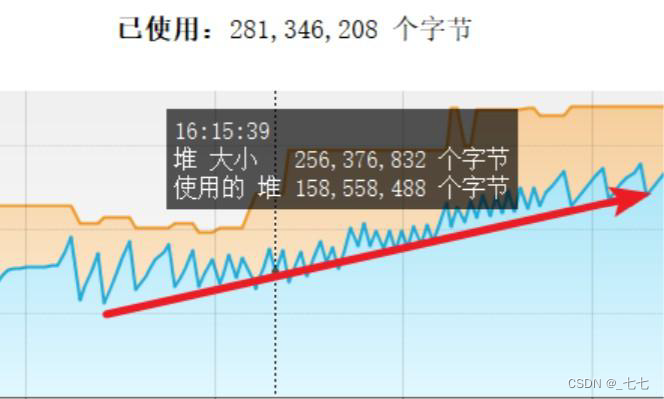
-
堆内存使用量持续增长 —— 可能是内存泄漏
-
Full GC比较慢,执行时会停止程序一些事务的处理。
因此Full GC频率不能过高(低于10分钟) -
如果Full GC之后,堆中仍然无法存储对象,就会出现内存溢出 —— 程序出现crash(崩溃)
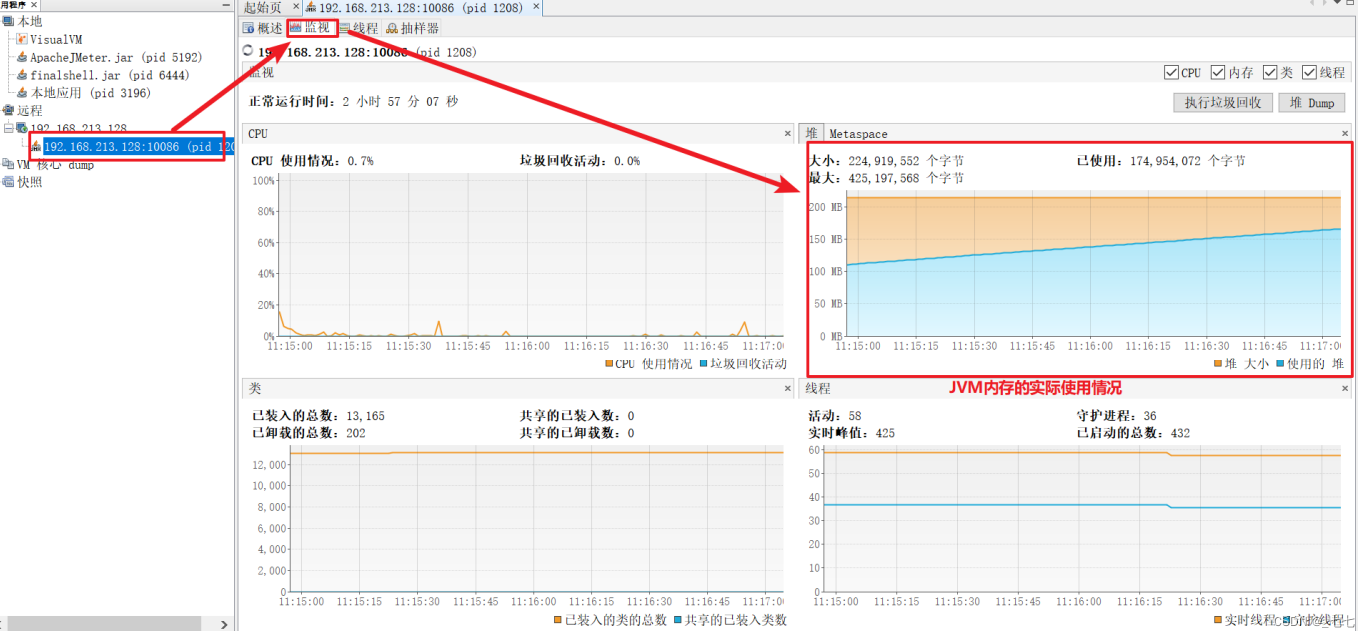
JVM监控 —— 使用本地jvisualvm远程监控服务器
-
在JAVA程序启动时,添加启动参数
-
进入本地jdk安装目录bin目录,找到jvisualvm.exe并启动
-
右键“远程”选择“添加远程主机”,并输入主机IP

-
右键主机选择“添加JMX连接”,并输入JMX端口
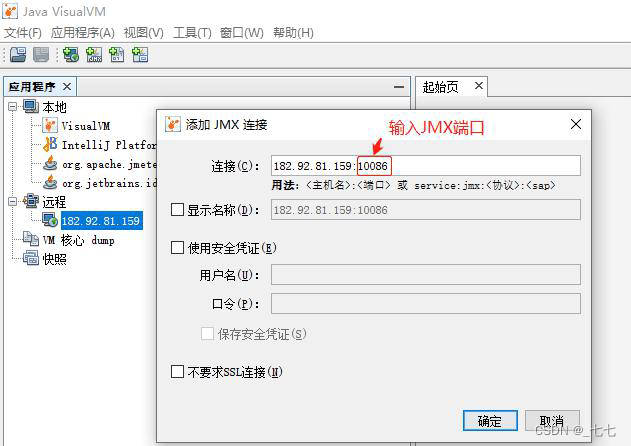
-
连接成功后在主机下会有对应的连接显示,双击查看监控信息
9、压测机瓶颈分析 —— 压测机
压测机影响性能测试结果的原因主要是:
- JMeter单机负载能力有限,如果需要模拟的用户请求数超过其负载极限,也会导致TPS压不上去
压测机资源的监控方法: - Windows测试机:自带“任务管理器”
- Linux测试机:PerfMon组件
解决方案:
- 采用分布式执行的方法来提高负载量,达到系统性能测试要求的TPS














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









