







文章目录
Web自动化测试环境搭建步骤
| Python开发环境 | 安装Selenium | 安装浏览器 | 安装浏览器驱动 |
|---|---|---|---|
| python:解释器pycharm:编码工具 | Selenium提供自动化实现的常用方法 | 脚本结果直接体现Chrome、FireFox… | 保证能够用程序驱动浏览器,实现自动化测试 |
一、Web自动化测试 Selenium环境搭建
1、Python 安装Selenium
安装:
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
pip config get global.index-url
安装包
pip install selenium
查看包
pip show selenium
卸载包
pip uninstall selenium

升级 pip (可选)
WARNING: You are using pip version 21.1.3; however, version 21.3.1 is available.
You should consider upgrading via the 'd:\python39\python.exe -m pip install --upgrade pip' command.
C:\Users\Administrator>d:\python39\python.exe -m pip install --upgrade pip
Requirement already satisfied: pip in d:\python39\lib\site-packages (21.1.3)
Collecting pip
Downloading pip-21.3.1-py3-none-any.whl (1.7 MB)
|████████████████████████████████| 1.7 MB 31 kB/s
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 21.1.3
Uninstalling pip-21.1.3:
Successfully uninstalled pip-21.1.3
Successfully installed pip-21.3.1
2、webdriver 驱动
- 不同浏览器都有自己独立驱动程序
不同的版本需要下载匹配其版本的驱动程序
- Chrome
点击下载chrome的webdriver:
https://googlechromelabs.github.io/chrome-for-testing/
http://npm.taobao.org/mirrors/chromedriver/
不同的Chrome的版本对应的chromedriver.exe 版本也不一样,下载时不要搞错了。如果是最新的Chrome, 下载最新的chromedriver.exe 就可以了。

http://chromedriver.storage.googleapis.com/index.html?path=95.0.4638.54/
- Firefox
Firefox驱动下载地址为:
https://github.com/mozilla/geckodriver/releases/
- IE
IE浏览器驱动下载地址为:
http://selenium-release.storage.googleapis.com/index.html
- 根据自己selenium版本下载对应版本的驱动即可,python的话,下载里面的IEDriverServerxxx.zip即可,这个是区分32和64位系统的,根据自己的系统下载即可;
- 需要注意的是,如果要打开IE浏览器的话,需要在浏览器的Internet选项中的安全页里有4个安全选项,Internet、本地Internet、受信任的站点、受限制的站点,这4个里面都有一个启用保护模式,都需要勾选上才可以,还得把驱动的路径加入到环境变量中。
3、导入webdriver模块
- windows:
1、解压下载的驱动,获取到chromedriver.exe
2、将chromedriver.exe复制到项目所在目录即可
实例:
通过程序启动浏览通过程序启动浏览器,并打开百度首页,暂停3秒,关闭浏览器,并打开百度首页,暂停3秒,关闭浏览器
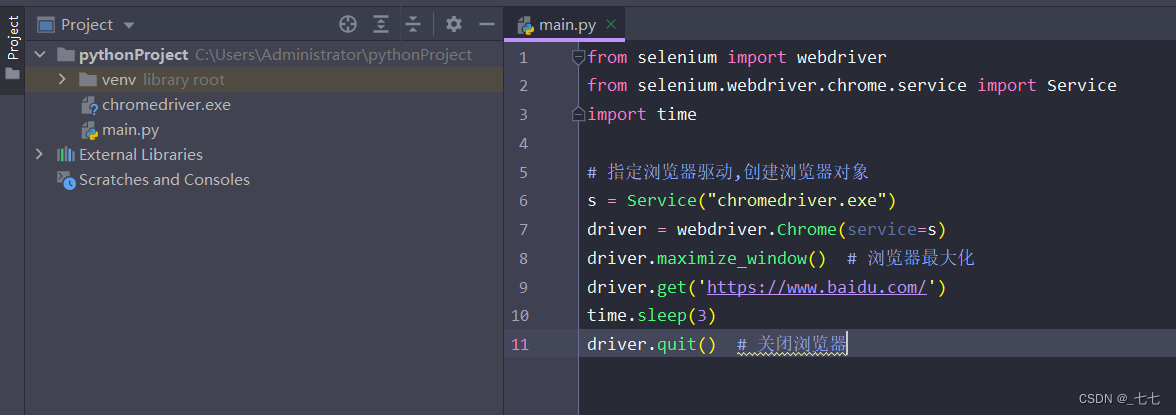
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
# 指定浏览器驱动,创建浏览器对象
s = Service("chromedriver.exe")
driver = webdriver.Chrome(service=s)
driver.maximize_window() # 浏览器最大化
driver.get('https://www.baidu.com/') #输入url
time.sleep(3)
driver.quit() # 关闭浏览器
二、webdriver api
1 浏览器操作api
# 指定浏览器驱动,创建浏览器对象
s = Service("chromedriver.exe")
driver = webdriver.Chrome(service=s)
------------------------------------
driver.get('https://www.baidu.com/') # 打开指定url
driver.close() # 关闭当前窗口
driver.quit() # 关闭浏览器
driver.maximize_window() # 浏览器最大化
driver.minimize_window() # 浏览器最小化
driver.set_window_size() # 自定义窗口大小 def set_window_size(self, width, height, windowHandle='current') -> dict
driver.refresh() # 刷新
driver.forward() # 前进
driver.back() # 后退
driver.title # 获取当前title
driver.current_url # 获取当前url
driver.page_source # 获取页面源码
driver.find_element(By.ID, 'su').click() # 点击
example:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
# 指定浏览器驱动,创建浏览器对象
s = Service("chromedriver.exe")
driver = webdriver.Chrome(service=s)
driver.maximize_window() # 浏览器最大化
driver.get('https://www.baidu.com/')
time.sleep(3)
driver.get('https://cn.bing.com/')
driver.refresh() # 刷新
if '必应' in driver.title and 'bing' in driver.current_url and '必应' in driver.page_source:
print("pass")
else:
print("false")
time.sleep(3)
driver.back() # 后退
time.sleep(3)
driver.forward() # 前进
driver.minimize_window() # 浏览器最小化
time.sleep(3)
driver.quit() # 关闭浏览器
2 元素定位api
方式一
from selenium.webdriver.common.by import By
driver.find_element(by=By.ID, value: Optional[str] = None))
# 返回的数据为所有符合条件的元素对象的列表
# 定位所有符合条件的元素
driver.find_elements(by=By.ID, value: Optional[str] = None)
class By(object):
"""
Set of supported locator strategies.
"""
ID = "id"
XPATH = "xpath"
LINK_TEXT = "link text"
PARTIAL_LINK_TEXT = "partial link text"
NAME = "name"
TAG_NAME = "tag name"
CLASS_NAME = "class name"
CSS_SELECTOR = "css selector"
id 元素id属性值定位
name 通过元素name定位
CLASS_NAME通过元素class属性值定位
LINK_TEXT 通过元素的文本值定位
PARTIAL_LINK_TEXT通过元素的部分文本值定位
TAG_NAME 通过元素的标签名定位
CSS_SELECTOR 通过元素在HTML页面中的位置定位 使用css
XPATH 通过元素在HTML页面中的位置定位
example:

from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
s = Service(r'D:\pythonProject\testProject001\GUI\webdriver\chromedriver.exe')
driver = webdriver.Chrome(service=s)
driver.maximize_window() # 浏览器最大化
driver.get('https://www.baidu.com/')
time.sleep(1)
element_1 = driver.find_element(By.ID, 'su') # 使用id属性值定位
element_2 = driver.find_element(By.CLASS_NAME, 'wrapper_new') # 使用class属性值定位
element_3 = driver.find_element(By.TAG_NAME, 'input') # 标签
element_4 = driver.find_element(By.CSS_SELECTOR, '#su') # 使用css定位元素
element_5 = driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input') # 使用xpath 绝对路径
print(element_1)
print(element_2)
print(element_3)
print(element_4)
print(element_5)
# 完整文本值
query_1 = driver.find_element(By.LINK_TEXT, '新闻')
print(query_1)
# 部分文本值
query_2 = driver.find_element(By.PARTIAL_LINK_TEXT, "新")
print(query_2)
driver.quit()
# <selenium.webdriver.remote.webelement.WebElement (session="b1c0f8ebfa7461a185cd84bc48a96781", element="b8f693d7-bfcc-4f10-b941-9f6f3ed671e7")>
# <selenium.webdriver.remote.webelement.WebElement (session="b1c0f8ebfa7461a185cd84bc48a96781", element="2d0c1c52-bb15-48dd-9010-5c8039517b79")>
# <selenium.webdriver.remote.webelement.WebElement (session="b1c0f8ebfa7461a185cd84bc48a96781", element="d2d062e8-bb21-4a58-8185-352d8a8cc184")>
# <selenium.webdriver.remote.webelement.WebElement (session="b1c0f8ebfa7461a185cd84bc48a96781", element="b8f693d7-bfcc-4f10-b941-9f6f3ed671e7")>
# <selenium.webdriver.remote.webelement.WebElement (session="b1c0f8ebfa7461a185cd84bc48a96781", element="b8f693d7-bfcc-4f10-b941-9f6f3ed671e7")>
方式二(已过时)
driver.find_element_by_id(id属性值)
driver.find_element_by_name("passwordA").send_keys("123456")
driver.find_element_by_class_name("telA").send_keys("18611111111")
driver.find_element_by_tag_name("input").send_keys("admin")
# link_text 全部值
driver.find_element_by_link_text(超链接的全部文本内容)
driver.find_element_by_link_text("新浪").click()
# 局部文本:从字符串任意位置开始,一截连续字符集
driver.find_element_by_partial_link_text(超链接的局部文本内容)
# xpath
driver.find_element_by_xpath(xpath表达式)
---
# 查找所有的input标签
inputs = driver.find_elements_by_tag_name("input")
inputs[0].send_keys("admin")
inputs[1].send_keys("123456")
inputs[2].send_keys("13800001111")
inputs[3].send_keys("123@qq.com")
# for input in inputs:
# input.send_keys("admin")
3 xpath定位函数api

-
绝对路径定位:从html开始,到目标元素为止。如:
/html/body/div[1]/div[2]/div[5]/div[1]/div/form/span[2]/input -
相对路径定位:
//*[]如:
以//开始,后续每个层级都使用/来分隔。
//fieldset/p[1]/input- 属性定位使用
@
//*[@id="su"]或者//input[@id="su"]代表id为su的input标签。
//input[@type='submit']
//*[@value='提交'] - 属性与逻辑结合:
//input[@value='提交' and @class='banana'] - 层级与属性结合:
//div[@id='test1']/input[@value='提交']
- 属性定位使用
-
功能函数:
start-with:定位以指定属性 指定内容 开头的元素。
'//*[starts-with(@type,"submit")]'contains:定位指定属性 包含指定内容的元素。
# 利用局部属性值定位元素 '//*[contains(@value,"百度一下")]'text():定位文本值包含指定内容的元素。
# 利用元素的文本定位元素 '//*[contains(text(),"百度一下")]'
举例:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
s = Service(r'D:\pythonProject\testProject001\GUI\webdriver\chromedriver.exe')
driver = webdriver.Chrome(service=s)
driver.maximize_window() # 浏览器最大化
driver.get('https://www.baidu.com/')
time.sleep(1)
# 相对路径
element_1 = driver.find_element(By.XPATH, '//div[@id="wrapper"]/div/div/div/div/form/span[2]/input')
print(element_1)
# 绝对路径
element_2 = driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input')
print(element_2)
element_3 = driver.find_element(By.XPATH, '//*[starts-with(@type,"sub")]')
print(element_3)
element_4 = driver.find_element(By.XPATH, '//*[contains(@value,"百度一下")]')
print(element_4)
element_5 = driver.find_element(By.XPATH, '//*[contains(text(),"百度一下")]')
print(element_5)
driver.quit()
4 元素交互操作:点击、输入、清空、获取文本、获取元素指定属性
element.click() --单击
element.send_keys(value) --输入
element.clear() --清空
element.text --获取元素文本
element.size --获取元素大小
element.get_attribute('属性名') --获取元素指定属性的值
element.find_elements() --定位子元素
element.is_displayed() --判断元素是否可见
element.is_enabled() --判断元素是否可用
举例


from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
s = Service(r'D:\pythonProject\testProject001\GUI\webdriver\chromedriver.exe')
driver = webdriver.Chrome(service=s)
driver.maximize_window() # 浏览器最大化
driver.get('https://cn.bing.com/')
time.sleep(1)
query = driver.find_element(By.ID, 'sb_form_q') # 定位输入框
query.clear() # 情况输入框
query.send_keys('python') # 输入内容
search = driver.find_element(By.ID, 'search_icon') # 搜索
time.sleep(1)
search.click() # 点击
if 'Downloads' in driver.page_source:
print("search finish")
else:
print("search fail")
# 使用find_elements 获取所有的属性值
rs = driver.find_elements(By.CLASS_NAME, "sh_favicon")
for i in rs:
print(i.get_attribute('href'))

5 浏览器操作
- 设置浏览器显示范围
窗口最大化 dirver.maxmize_window()
设置窗口大小 dirver.set_window_size(width, height)
设置窗口位置 dirver.set_window_position(x, y)
- 浏览器显示页面操作
页面后退操作 dirver.back()
页面前置操作 dirver.forword()
设置窗口位置 dirver.refresh()
- 浏览器关闭操作
关闭当前窗口 dirver.close()
关闭浏览器 dirver.quit()
- 获取浏览器信息
获取标题 dirver.title
获取网页地址 dirver.current_url
6 页面交互操作
- 下拉框
1.导包
from selenium.webdriver.support.select import Select
2.创建select对象
select = Select(element)
3.选择选项
select.select_by_index(index) 根据下标
select.select_by_value(value) 根据选项value属性值
select.select_by_visible_text(text) 根据选项文本
<label>
<select id = 'test'>
<option>北京</option>
<option>上海</option>
<option>天津</option>
<option>成都</option>
<option value="cq">重庆</option>
</select>
</label>
---
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
import time
s = Service('chromedriver.exe')
driver = webdriver.Chrome(service=s)
path = "file://" + os.path.dirname(__file__) + '\\test.html'
driver.get(path)
element = driver.find_element(By.ID, 'test')
select = Select(element)
# 选项索引
select.select_by_index(1)
time.sleep(3)
# 选项value值
select.select_by_value('cq')
time.sleep(3)
# 选项名称选择
select.select_by_visible_text('成都')
time.sleep(1)
driver.quit()
- 弹出框
获取弹出框对象
alert = driver.switch_to.alert
alert.text 获取弹出框文本
弹出框处理方法
alert.accept() 接受弹出框,即点击弹出框的确定
alert.dismiss() 取消弹出框
<script>
setTimeout((()=>{
alert('test')
}),3000)
</script>
---
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
s = Service('chromedriver.exe')
driver = webdriver.Chrome(service=s)
path = "file://" + os.path.dirname(__file__) + '\\test.html'
driver.get(path)
time.sleep(5)
alert = driver.switch_to.alert
print(alert.text)
# 接受弹出框
alert.accept()
# 取消弹出框
alert.dismiss()
time.sleep(1)
driver.quit()
- 滚动条
定义Js字符串 js = "window.scrollTo(0,1000)"
执行Js字符串 driver.execute_script(js)
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
s = Service('chromedriver.exe')
driver = webdriver.Chrome(service=s)
path = "file://" + os.path.dirname(__file__) + '\\test.html'
driver.get(path)
time.sleep(3)
js = "window.scrollTo(0,1000)"
driver.execute_script(js)
time.sleep(1)
driver.quit()
- ActionChains鼠标类
点击、右击、双击、悬停 、拖拽等
# 导包
from selenium.webdriver import ActionChains
# 实例化鼠标对象
action = ActionChains(driver)
调用鼠标方法
action.move_to_element(element) 鼠标悬停
action.context_click(element) 鼠标右击
action.double_click(element) 鼠标双击
action.drag_and_drop(source, target) 拖拽
执行鼠标操作
action.perform()
调用鼠标方法井不会去执行鼠标操作,必须调用perform才会执行
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time
# 导包
from selenium.webdriver import ActionChains
s = Service('chromedriver.exe')
driver = webdriver.Chrome(service=s)
path = "file://" + os.path.dirname(__file__) + '\\test.html'
driver.get(path)
# 实例化鼠标对象
action = ActionChains(driver)
element = driver.find_element(By.CLASS_NAME, 'box')
# 鼠标悬停
action.move_to_element(element)
action.perform()
time.sleep(3)
拖拽
from time import sleep
from selenium import webdriver
# 1、获取浏览器
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
driver = webdriver.Chrome()
# 2、打开url
driver.get("file:///Users/Documents/web/drop.html")
sleep(3)
# 获取ActionChains对象
action = ActionChains(driver)
div1 = driver.find_element(By.CSS_SELECTOR, "#div1")
div2 = driver.find_element(By.CSS_SELECTOR, "#div2")
action.drag_and_drop(div1, div2).perform()
# 4、关闭浏览器
sleep(3)
driver.quit()
7 元素等待
强制等待
- 强制等待:
time下的sleep()方法;- 缺点:影响脚本运行效率
隐式等待
-
隐式等待:
implicitly_wait(t)- 在指定的时间内等待页面完全加载完成,如果加载完成的时间小于t,剩余时间(t-加载时间)就不再等待;
- 如果在时间t内未加载完成则报错;
- 作用范围为全局;
- 用来提高效率;
- 定位元素时,如果能定位到元素则直接返回该元素,不触发等待;
- 如果不能定位到该元素,则间隔一段时间后再去定位元素;
- 如果在达到最大时长时还没有找到指定元素,则抛出元素不存在的异NoSuchElementException。
driver.implicitly_wait(10)例子:
- 在查找元素之前,WebDriver 会等待最多10秒,以确保元素出现在页面上。
- 如果元素在10秒内没有找到,WebDriver 将抛出NoSuchElementException异常。因此,通过设置隐式等待时间,我们可以在查找元素时增加一定的容错性,等待元素出现的时间更长一些。
- 隐式等待适用于整个 WebDriver 实例的生命周期,也就是说,只需设置一次即可,对后续的元素查找操作都会生效
from selenium import webdriver # 创建 WebDriver 实例 driver = webdriver.Chrome() # 设置隐式等待时间为10秒 driver.implicitly_wait(10) # 打开网页 driver.get("https://www.example.com") # 查找元素并操作 element = driver.find_element_by_id("myElement") element.click() # 关闭 WebDriver driver.quit()
显式等待
-
显式等待:
WebDriverWait()- 特殊的隐式等待,等待指定的元素加载完成;
- 定位 元素时,如果能定位到元素则直接返回该元素,不触发等待;
- 如果不能定位到该元素,则间隔一段时间后再去定位元素;
- 如果在达到最大时长时还没有找到指定元素,则抛出超时异常 TimeoutException
# 导包 from selenium.webdriver.support.ui import WebDriverWait # 创建显示等待类对象 WebDriverWait(driver, timeout, poll_frequency=0.5) # poll_frequency 轮询时间 0.5 # 调用utils方法 until(method):直到...时class WebDriverWait(object): def __init__(self, driver, timeout, poll_frequency=POLL_FREQUENCY, ignored_exceptions=None): # driver 浏览器对象 # timeout 超时时间 # poll_frequency 扫描间隔时间 一般是0.5 def until(self, method, message=''): # until(element)指定加载元素举例:
from selenium import webdriver from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By import time from selenium.webdriver.support.ui import WebDriverWait s = Service(r'D:\pythonProject\testProject001\GUI\webdriver\chromedriver.exe') driver = webdriver.Chrome(service=s) driver.maximize_window() # 浏览器最大化 driver.get('https://cn.bing.com/') start_time = time.time() # driver.implicitly_wait(100) # 隐式等待 # 每隔0.5秒扫描元素 sb_form_q 直到元素超时或出现 # 轮询时间为0.5 # WebDriverWait() 方法内部,它会将当前的 WebDriver 实例作为参数传递给 lambda 表达式 query = WebDriverWait(driver, 100, 0.5).until(lambda ele: driver.find_element(By.ID, 'sb_form_q')) el = WebDriverWait(driver, 10, 0.5).until(lambda x: x.find_element(By.CSS_SELECTOR, "#username")) # query = driver.find_element(By.ID, 'sb_form_q') # 定位输入框 query.clear() # 清空输入框 query.send_keys('python') # 输入内容 el.send_keys("admin") search = driver.find_element(By.ID, 'search_icon') # 搜索 search.click() # 点击 print(time.time() - start_time)-
WebDriverWait(driver, 100, 0.5):创建一个 WebDriverWait 对象,参数包括 WebDriver 实例 driver、最大等待时间(秒)和轮询间隔时间(秒)。在这里,最大等待时间为 100 秒,轮询间隔时间为 0.5 秒。
-
.until(lambda ele: driver.find_element(By.ID, ‘sb_form_q’)):将 lambda 表达式传递给 until 方法。until 方法会反复调用该 lambda 表达式,直到返回值为 True 或超过最大等待时间。在这里,lambda 表达式接受一个参数 ele,表示待查找的元素。它使用 driver.find_element(By.ID, ‘sb_form_q’) 语句来查找具有 ID 为 ‘sb_form_q’ 的元素。
-
lambda 表达式是一种匿名函数,它可以在代码中创建一个简单的、临时的函数。
lambda 表达式的语法如下:
lambda arguments: expression
其中,arguments 是该匿名函数的参数,可以是一个或多个参数,用逗号分隔。expression 是函数体,表示函数要执行的操作,并返回结果。- 它是一种匿名函数,没有函数名。
- 它可以接受任意数量的参数,包括可选参数和默认参数。
- 它只能包含一个表达式,而不能包含复杂的语句块。
隐式等待和显示等待对比
| 隐式等待 | 显示等待 | |
|---|---|---|
| 作用域 | 只用设置一次,对全局生效 | 只对指定元素生效 |
| 抛出异常 | NoSuchElementException | TimeOutException |
| 使用方法 | driver.implicitly_wait(timeout) | 通过WebDriverWait对象 |
| 其它 | 必须等待整个页面加载完成 | 只关注指定元素是否加载 |
8 Frame切换
针对html
- frameset形式
- iframe标签形式
切换指定iframe
driver.switch_to.frame(frame_reference)
frame_reference:iframe标签元素对象
恢复默认页面
driver.switch_to.default_content()
举例:
# 获取注册A iframe元素
A = driver.find_element(By.CSS_SELECTOR, "#idframe1")
# 1、切换到A
driver.switch_to.frame(A)
# 2、注册A操作
driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
time.sleep(3)
# 3、回到默认目录 注册.html
driver.switch_to.default_content()
# 4、获取注册B iframe元素
B = driver.find_element(By.CSS_SELECTOR, "#idframe2")
# 5、切换到B
driver.switch_to.frame(B)
# 6、注册B操作
driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
time.sleep(3)
driver.quit()
9 多窗口切换
selenium需要通过窗口的句柄来实现窗口的切换
获取所有窗口句柄
handles = driver.window_handles
切换指定窗口
driver.switch_to.window(handles[n])
例子
driver = webdriver.Chrome()
path = "file://" + os.path.dirname(__file__) + '\\test.html'
driver.get(path)
"""
为什么要处理多窗口?-- selenium默认焦点在启动窗口,要操作其他窗口必须处理。
需求:
1、打开注册示例页面
2、点击注册A网页链接
3、填写注册A网页内容
"""
driver.find_element(By.LINK_TEXT, "注册A").click()
handles = driver.window_handles
print("操作之后所有窗口的句柄:", handles)
# 重点:切换窗口
driver.switch_to.window(handles[1])
# 填写注册A网页 用户名
driver.find_element(By.CSS_SELECTOR, "#username").send_keys("admin")
time.sleep(3)
driver.quit()
工具封装
driver = webdriver.Chrome()
driver.implicitly_wait(10)
# 2、打开url
driver.get("file:///Users/lgy/Documents/fodder/web/Register.html")
"""
需求:
如何随心所欲切换窗口?
思路:
1、获取所有窗口句柄
2、切换窗口
3、获取当前所在窗口title
4、判断title是否为需要的窗口
5、执行代码
需求:
1、打开注册示例页面
2、点击 注册A网页 注册B网页
3、在A网页和B网页中输入 对用户名输入 admin
"""
def switch_window(title):
# 1、获取所有窗口句柄
handels = driver.window_handles
# 2、遍历句柄进行切换
for handel in handels:
# 操作
driver.switch_to.window(handel)
# 获取当前窗口title 并且 判断是否自己需要的窗口
if driver.title == title:
# 操作代码
print("已找到{}窗口,并且已切换成功".format(title))
title_A = "注册A"
title_B = "注册B"
# 打开注册A和注册B网页
driver.find_element(By.LINK_TEXT, "注册A网页").click()
driver.find_element(By.LINK_TEXT, "注册B网页").click()
# 填写注册A网页 用户名
switch_window(title_A)
driver.find_element(By.CSS_SELECTOR, "#userA").send_keys("admin")
switch_window(title_B)
driver.find_element(By.CSS_SELECTOR, "#userB").send_keys("admin")
# 4、关闭浏览器
sleep(3)
driver.quit()
10 窗口截图
driver.get_screenshot_as_file(imgpath)
imgpath:图片保存路径
举例:
driver = webdriver.Chrome()
# 2、打开url
driver.get("file:///Users/lgy/Documents/fodder/web/%E6%B3%A8%E5%86%8CA.html")
# 3、查找操作元素
driver.find_element(By.CSS_SELECTOR,"#userA").send_keys("admin")
driver.find_element(By.CSS_SELECTOR,"#passwordA").send_keys("123456")
driver.find_element(By.CSS_SELECTOR,"#telA").send_keys("13600001111")
driver.find_element(By.CSS_SELECTOR,"#emailA").send_keys("123@qq.com")
# 截图
driver.get_screenshot_as_file("register.png")
driver.get_screenshot_as_file("error_{}.png".format(time.strftime("%Y_%m_%d %H_%M_%S")))
# 4、关闭浏览器
sleep(3)
driver.quit()
11 验证码\Cookie跳过登陆
手工登陆 - 获取cookie - 脚本添加cookie - 刷新页面
driver.get_cookie(name) --> 获取指定cookie
driver.get_cookies() --> 获取本网站所有本地cookies
driver.add_cookie(cookie_dict) --> 添加cookie
cookie_dict:一个字典对象,必选的键包括:"name" and "value"
举例:
"""
需求:使用cookie实现百度登录
依赖cookies: BDUSS
"""
from time import sleep
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
driver.maximize_window()
# 添加cookie
data = {"name": "BDUSS", "value": "由于安全问题,暂时删除。"}
driver.add_cookie(data)
driver.get_cookies()
# 暂停3秒
sleep(3)
# 刷新
driver.refresh()
sleep(3)
driver.quit()
三、PO模式
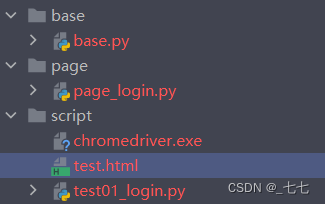
结构
- base: 存放所有Page页面公共方法
- page: 将页面封装为对象
- script: 测试脚本
base
"""
Base类:存放所有Page页面公共操作方法!
"""
from selenium.webdriver.support.wait import WebDriverWait
class Base:
def __init__(self, driver):
self.driver = driver
# 查找元素
def base_find(self, ele, timeout=10, poll_frequency=0.5):
# 显示等待 -> 查找元素 loc = (By.ID,"userA") *loc=loc[0],loc[1]
return WebDriverWait(self.driver, timeout, poll_frequency).until(lambda x: x.find_element(*ele))
# 输入方法
def base_input(self, ele, value):
# 1、获取元素
el = self.base_find(ele)
# 2、清空操作
el.clear()
# 3、输入内容
el.send_keys(value)
# 点击方法
def base_click(self, ele):
self.base_find(ele).click()
# 获取文本值方法
def base_get_text(self, ele):
return self.base_find(ele).text
page_login
"""
模块名:page_模块单词
类名:大驼峰将模块移植进来,去掉下划线和数字。
方法:自动化测试当前页面要操作那些元素,就封装那些方法
"""
from selenium.webdriver.common.by import By
# 用户名
from base.base import Base
username = (By.CSS_SELECTOR, "#username")
# 密码
pwd = By.CSS_SELECTOR, "#password"
# 验证码
verify_code = By.CSS_SELECTOR, "#verify_code"
# 登录按钮
login_btn = By.CSS_SELECTOR, "#login"
# 昵称
nick_name = By.CSS_SELECTOR, ".userinfo"
class PageLogin(Base):
# 输入用户名
def __page_username(self, value):
self.base_input(username, value)
# 输入密码
def __page_pwd(self, value):
self.base_input(pwd, value)
# 输入验证码
def __page_verify_code(self, value):
self.base_input(verify_code, value)
# 点击登录按钮
def __page_click_login_btn(self):
self.base_click(login_btn)
# 获取昵称
def page_get_nickname(self):
return self.base_get_text(nick_name)
# 组合业务方法 (强调:测试业务成调用此方法,便捷。)
def page_login(self, phone, password, code):
self.__page_username(phone)
self.__page_pwd(password)
self.__page_verify_code(code)
self.__page_click_login_btn()
test script
import os
import unittest
from selenium import webdriver
from page.page_login import PageLogin
class TestLogin(unittest.TestCase):
def setUp(self) -> None:
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.path = "file://" + os.path.dirname(__file__) + '\\test.html'
self.driver.get(self.path)
self.login = PageLogin(self.driver)
def tearDown(self) -> None:
self.driver.quit()
def test01_login(self,phone="13600001111",password="123456",code="8888"):
# 调用登录业务
self.login.page_login(phone,password,code)
# 断言
nickname = self.login.page_get_nickname()
print("nickname:", nickname)
数据驱动
1、UI自动化测试中数据驱动的核心是:
- 利用参数化技术使用同样的测试步骤来执行不同的测试数据,验证各种测试情况
- 将测试数据和测试脚本分离,编写完成操作脚本后,将重点放到数据的维护和构建上
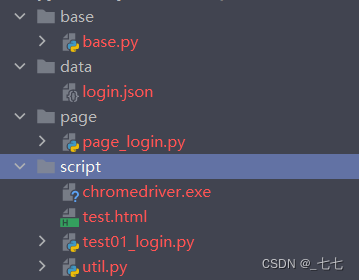
/data/login.json
{
"login": [
{
"desc":"登录成功",
"phone": "13600001111",
"password": "123456",
"code": "8888",
"expect_text": "13600001111"
}
]
}
util.py
import json
# 读取json工具
import os
def read_json(filename, key):
filepath = os.path.dirname(__file__) +os.sep + '..'+os.sep + "data" + os.sep + filename
arr = []
with open(filepath, "r", encoding="utf-8") as f:
for data in json.load(f).get(key):
arr.append(tuple(data.values())[1:])
# 切片表示对元组进行切片操作,从索引为1 的位置开始截现到未尾,这样做是为了去除元组的第一个元素。
return arr
if __name__ == '__main__':
"""
[(),()]
"""
print(read_json("login.json", "login"))
script/test01.py
import os
import unittest
from selenium import webdriver
from page.page_login import PageLogin
from parameterized import parameterized
from util import read_json
class TestLogin(unittest.TestCase):
def setUp(self) -> None:
self.driver = webdriver.Chrome()
self.driver.maximize_window()
self.path = "file://" + os.path.dirname(__file__) + '\\test.html'
self.driver.get(self.path)
self.login = PageLogin(self.driver)
def tearDown(self) -> None:
self.driver.quit()
# def test01_login(self,phone="13600001111",password="123456",code="8888"):
@parameterized.expand(read_json("login.json", "login"))
def test01_login(self, phone, password, code, expect_text):
# 调用登录业务
self.login.page_login(phone, password, code)
# 断言
nickname = self.login.page_get_nickname()
print("nickname:", nickname)















 9854
9854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









