





论文研究10:Audio-Visual Speech Separation and Dereverberation With a Two-Stage Multimodal Network
abstract
背景噪音,干扰语音和房间混响经常会在实际收听环境中使目标语音失真。在这项研究中,我们着眼于联合语音分离和混响,其目的是将目标语音与背景噪声,干扰语音和房间混响分离开。为了解决这个根本上困难的问题,我们提出了一种利用音频和视频信号的新型多模态网络。所提出的网络体系结构采用两阶段策略,在第一阶段采用分离模块来衰减背景噪声和干扰语音,在第二阶段采用去混响模块来抑制房间的混响。这两个模块首先分别进行训练,然后基于新的多目标损失函数进行集成以进行联合训练。我们的实验结果表明,与多个一阶段和两阶段基线相比,拟议的多模式网络始终能够产生更好的客观清晰度和感知质量。我们发现,与未经处理的混合物相比,我们的网络的ESTOI改善了21.10%,PESQ改善了0.79。而且,我们的网络体系结构不需要知道说话者的数量。
I. INTRODUCTION
在像鸡尾酒会这样的声学环境中,人类听觉系统能够在出现说话者干扰,背景噪声和房间混响的情况下,追踪单个目标语音源。 语音分离,通常也称为鸡尾酒会问题,是将目标语音与背景干扰分离的任务[6],[45]。 来自其他来源的干扰声音和来自表面反射的混响都会破坏目标语音,这会严重降低人类听众的语音清晰度,以及语音处理计算系统的性能。 数十年来,已经进行了许多研究来改善语音分离的性能。 受计算听觉场景分析(CASA)中的时频(T-F)掩蔽概念的启发,语音分离最近被公式化为监督学习,其中从训练数据中学习目标语音或背景干扰内的判别模式[44]。 由于使用了深度学习,在过去的十年中,有监督的语音分离性能得到了显着提高[49],[45]。 然而,在不利的声学环境中产生高质量的分离语音仍然是一个具有挑战性的问题。
在最近几年中,说话人分离吸引了相当多的研究关注,其目的是提取多个语音源,每个说话人一个。独立于说话者的语音分离(在训练和测试之间不需要所有说话者都相同)容易受到标签歧义(或排列)问题的困扰[51],[14]。独立于说话人的语音分离的著名方法包括深度聚类[14]和不变排列训练(PIT)[57],它们从不同角度解决了标签的歧义。深度聚类将说话人分离视为频谱聚类,而PIT使用动态计算的损失函数进行训练。最近的许多研究扩展了这两种方法。例如,在[27]中采用了名为TasNet的扩张卷积神经网络(CNN)进行时域语音分离,其中在训练过程中应用了发声级PIT [24]。解决标签歧义的另一种方法是使用目标说话者的扬声器区分性声音提示作为分离的辅助输入。在最近的一项研究中[46],预先录制的来自目标说话者的简短话语被用作注意力控制的锚点,注意力控制选择要分离的目标说话者。类似地,在[48]中,说话者识别网络根据目标说话者的参考信号产生说话者区分嵌入。然后将嵌入的矢量以及嘈杂混合物的频谱图输入到分离网络中。这种方法的潜在优势是不需要知道发言人的数量。
说话者的面部动作或嘴唇动作等视觉提示可以补充说话者语音中的信息,从而有助于语音感知,特别是在嘈杂的环境中[28],[29],[38]。基于这一发现,人们开发了各种算法来组合音频和视频信号,以多模式的方式进行语音分离[36]。最近有兴趣使用深度神经网络(DNN)来实现此目标。侯等人。 [17]设计了基于多任务学习的视听语音增强框架。他们的实验结果表明,在没有视觉输入的情况下,视听增强框架始终优于相同的架构。在[9]中开发了一种类似的模型,其中训练了CNN以直接从嘈杂的语音和输入视频中估计干净语音的幅度谱图。此外,Gabbay等。 [8]采用视频语音转换方法合成语音,随后将其用于构造用于语音分离的T-F掩码。其他相关研究包括[16],[54],[21]。
尽管上述基于深度学习的视听方法比传统的视听方法大大提高了分离性能,但它们不能解决说话人泛化的问题,这是有监督语音分离中的关键问题。换句话说,仅以与说话者相关的方式对他们进行了评估,不允许说话者从训练过渡到测试。最近的研究[7],[1],[33],[30],[53]已经开发了与说话者无关的语音分离算法。 Ephrat等[7]设计了一种基于扩张卷积和双向长短期记忆(BLSTM)的多流神经网络,与以前的几种依赖于说话人的模型相比,它的性能要好得多。 Afouras等[1]利用两个子网分别预测干净语音的幅度谱图和相位谱图。在[33]中,训练DNN以预测音频和视频流是否在时间上同步,然后将其用于产生用于语音分离的多感官特征。 Wu等[53]开发了用于目标说话人分离的时域视听模型。请注意,这些研究针对的是近距离交谈场景中的单声道语音分离。
在真实的声学环境中,语音信号通常会由于表面反射的混响而失真。去混响已被积极研究了数十年[3],[32],[31],[11]。尽管基于深度学习的方法近年来显着改善了混响效果[10],[52],[55],[58],但混响仍然是公认的挑战,尤其是当混响与背景噪声,干扰语音或两者共有。尽管在视听语音分离方面取得了令人鼓舞的进展,但最近的研究很少以多模态方式处理语音分离和去混响。考虑到在嘈杂和混响环境中分离和混响对人和机器听众的重要性(例如,自动语音识别),我们在本研究中解决了与说话者无关的多通道语音分离和混响,其目的是将目标语音与干扰语音,背景分开噪音和房间混响。受近期有关语音分离的著作[22],[42],[58]的启发,我们认为,由于它们的内在差异,解决分离阶段和分离混响可能更有效。因此,我们首先使用扩张的CNN从干扰语音和背景噪声中分离出目标混响语音,然后采用BLSTM来消除分离后的语音信号的失真。随后,对两阶段模型进行联合训练以优化新的多目标损耗函数,该函数将TF域中的均方误差(MSE)损耗与标度不变信噪比(SI-SNR)损耗相结合。时域。我们的实验结果表明,与未处理的混合物相比,拟议的多峰网络将扩展的短期目标清晰度(ESTOI)[20]提高了21.10%,语音质量的感知评估(PESQ)[37]提高了0.79。此外,我们发现拟议的网络大大优于几个一阶段和两阶段基准。在这项研究中,在存在干扰语音,背景噪声和房间混响的远场场景中,对基于视听的联合语音分离和混响进行了彻底研究。
本文的其余部分安排如下。 在第二部分中,我们介绍了多通道远场信号模型。 第三节简要介绍了本研究中使用的几种听觉和视觉特征。 在第四节中,我们详细描述了我们提出的视听多模式网络架构。 第五节提供了实验设置。在第六节中,我们介绍并讨论了实验结果。 第七节总结了本文。
II. MULTI-CHANNEL FAR-FIELD SIGNAL MODEL
令k和m分别为时间样本索引和通道索引。 因此,远场语音混合y(m)可以建模为
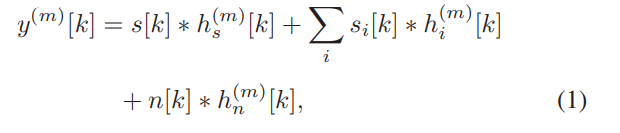
其中s,si和n分别表示目标语音源,第i个干扰语音源和背景噪声源,而hs,hi和hn分别对应于目标语音源i 干扰语音源和背景噪声源。 卷积运算用*表示。 这项研究的目的是从M通道远场语音混合物y = [y(1),y(2),…,y(M)]估计无回声目标语音信号,以及 目标的视觉流和干扰说话者的嘴唇图像。 在这项研究中,我们使用如图1(a)所示的九个麦克风的线性阵列。 我们将从左到右的九个麦克风分别编号为0、1,…,8。 在不失一般性的前提下,我们将麦克风0拾取的干净语音信号作为目标信号。

III. AUDITORY AND VISUAL FEATURES
在这项研究中,我们假设所有信号均以16 kHz采样。 使用32毫秒的平方根Hann窗口将语音信号分段为一组时间帧,相邻帧之间有50%的重叠。 我们将所有视频中人脸图像的视觉流重新采样为每秒25帧(FPS),然后使用dlib库中的工具执行人脸检测。从这些预处理数据中,我们提取了三个听觉特征和一个视觉特征 用于多模式语音分离和混响。
A. Log-Power Spectrum
麦克风0接收到的嘈杂混合物的对数功率谱(LPS)是标准频谱表示,是在512点短时傅立叶变换(STFT)上计算得出的,导致257维(257-D) LPS功能。 LPS功能的一个示例如图2(a)所示。

通道间相位差(IPD)是一种信息丰富的空间提示,可以反映声源到达方向(DOA)的细微变化。 给定一对信道m1和m2,IPD定义为:
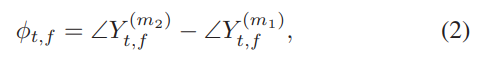
其中Y(m1)t,f和Y(m2)t,f是在时间帧t和频率bin f处T-F单元中有噪声混合物的STFT值。 在这项研究中,我们利用通道间相位差(cosIPD)的余弦值,即:
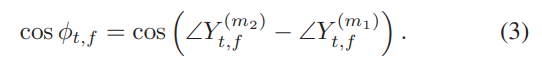
具体来说,我们将cosIPD连接在五对通道之间,分别是(0,8),(0,4),(1,4),(4,6)和(4,5),对应于五个不同的麦克风距离( 麦克风编号请参见图1(a)。 IPD和cosIPD功能分别如图2(b)和(c)所示。
C. Angle Features
我们导出目标扬声器的角度特征(AF),该特征首先在[5]中使用:
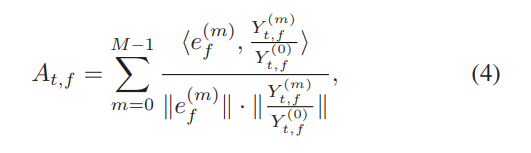
其中M表示麦克风的数量,ef(m)是目标说话者在通道m和频率仓f处的DOA的转向矢量系数。 内积用<·,·>表示,向量范数用·表示。 请注意,ef(m)和Yt,f(m) / Yt,f(0)均为复数值,并且在操作<·,·>和||·||中被视为2维矢量。 它们的实部和虚部被视为两个向量分量。 根据麦克风阵列的几何形状和目标语音信号的到达方向来计算转向矢量,这可以通过从180度广角摄像头捕获的视频中跟踪目标说话者的脸部来获得,该视频由位于麦克风阵列中心,如图1(a)所示。 180度广角摄像头与线性麦克风阵列对齐,因此可以轻松计算出DOA,如图1(b)所示。 在我们的实验中,我们模拟视觉数据,而不是使用真实的相机收集视觉数据。
D. Lip Features
基于嘴巴区域,脸部视觉流的每一帧都被裁剪为112×112的大小,这相当于嘴唇图像的视觉流。 使用OpenCV中的工具将这些图像转换为灰度。 来自所有检测到的说话者(包括目标说话者和干扰说话者)的视觉流被传递到多模式网络中。 请注意,多个说话者的脸部同时被相机检测到,用户可以将其中的任何一个视为目标说话者。 因此,相应的目标面部用于确定目标语音的到达方向以进行角度特征计算。 从另一个角度来看,嘴唇特征和角度特征选择要分离的说话者,并允许网络监听来自目标说话者方向的语音信号。
IV. A TWO-STAGE MULTIMODAL NETWORK FOR JOINT SEPARATION AND DEREVERBERATION
在本节中,我们详细描述了我们提出的用于联合分离和混响的两阶段多峰网络架构,该架构包括两个模块,即分离模块和混响模块。 提出的架构如图3所示。

A. Separation Stage
在分离阶段,将从通道0计算的LPS特征首先通过层归一化[4]层。 然后将归一化的LPS特征,cosIPD特征和角度特征串联到1799-D特征向量的序列中。 随后,将序列馈入具有256个大小为1的内核的一维卷积层(即逐点卷积层)以进行降维。 然后使用八个具有扩张率1,2,…,27的连续一维卷积块的堆栈来生成一系列音频嵌入。图4(a)中描述了扩张的卷积块。
说话者的视觉流被馈送到在[1]中开发的时空残留网络(Resnet),该网络包括一个3-D卷积层,然后是一个18层ResNet [13]。对应于不同说话者的时空残留网络彼此共享权重。如图3所示,目标说话者的输出以及所有干扰说话者的输出的逐个元素平均值被传递到一维卷积块中(见图4(b)),从而得出视觉嵌入的两个序列。类似于时空残差网络,目标说话人和干扰说话人的一维卷积块共享权重。由一维卷积块产生的两个序列被串联为一个1024维嵌入向量序列,随后将其暂时上采样到62.5 FPS(= 16000 /(50%×0.032×16000))以适合帧速率音频嵌入。跨时空残差网络的输出针对不同干扰说话者的平均操作允许多模态网络接受来自任意数量的干扰说话者的视频流。 换句话说,与[7]中开发的网络不同,我们的多模态网络与干扰说话者的数量无关,后者只能用于固定数量的说话者。 请注意,当没有检测到干扰说话者时,我们将全零“可视流”用作干扰说话者分支的时空残差网络的输入。 应当指出的是,另一种方法是仅使用目标说话者的视觉流,如[53]中所述,而另外使用干扰说话者的视觉流则可能导致更强劲的性能,尤其是当目标说话者的嘴唇图像很明显时 模糊或相机仅捕获目标说话者的侧面。

我们将产生音频和视觉嵌入的两个网络分支分别称为音频子模块和视觉子模块。音频和视频嵌入被级联,然后被馈送到具有256个内核的一维逐点卷积层,以进行视听特征融合和尺寸缩减。随后,将学习到的高级特征传递到膨胀卷积块的三个重复中(参见图4(a)),以对时间依赖性进行建模。在每个重复中的八个堆叠卷积块的扩张率分配有指数增长的值,即1、2,…,27,它们在时间方向上成指数地扩展接收场,从而允许有助于估计的时间上下文聚合。这种设计最初受到WaveNet的启发,用于语音合成[43],并已在最近的研究[35],[40],[41],[27]中成功地应用于语音分离。具有整流线性单位(ReLU)的一维点状卷积层用于估计比率掩码,然后将其按元素乘以来自通道0的有噪声混合物的幅度谱图,以产生分离的混响语音。
在训练过程中,估计的幅度与噪声相位(从通道0开始)组合在一起,以通过短时傅立叶逆变换(iSTFT)重新合成时域信号。 训练分离网络以使SI-SNR最大化,在最近的研究中,SI-SNR通常被用作说话人分离的评估指标[19],[25],[27],[50]。 因此,SISNR损失函数可以定义为
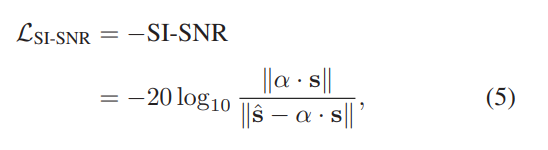
其中s∈R1×T和ˆs∈R1×T分别表示地面真实目标信号(即此阶段的混响目标语音)和带有T个时间采样的估计信号,α表示比例因子,定义为

请注意,在计算之前,将s和s归一化为零均值,以确保尺度不变。
B. Dereverberation Stage
在干扰语音和背景噪声减弱之后,原始问题减少到单通道语音去混响,即从分离模块估计的混响目标语音中恢复无回声目标语音。在此阶段,我们使用具有四个隐藏层的BLSTM网络执行光谱映射,该光谱映射将分离模块估算的光谱幅度作为输入。在此阶段中使用频谱映射而不是比率屏蔽的原因有两个。首先,在目标语音和背景干扰不相关的前提下,比率掩蔽是合理的,可以分离,这对于加性噪声(包括背景噪声和干扰性语音)非常适用,但对于混响干扰则不如卷积干扰[45]。其次,语音分离算法通常将处理伪像引入目标语音信号中[15],[47]。比率屏蔽可能很难抑制分离模块引入的这种处理伪像,尤其是考虑到这些伪像与目标语音信号相关时。
在训练过程中,冻结了分离模块中训练有素的参数,并训练了去混响模块中的参数以优化MSE损失函数,该函数比较了真实的幅度谱图| S |。 估计幅度的频谱图| Sˆ |:
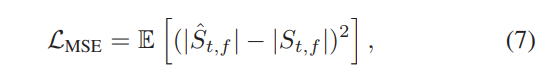
其中E代表小批量中所有训练样本的所有T-F单元的平均运算。 复数模量由|·|表示,即复数的绝对值。 使用MSE损失而不是SI-SNR损失是受以下观察的激励:采用SI-SNR损失进行训练会导致语音去混响的收敛速度慢得多,并且与说话者分离相比会导致性能下降,这很可能是因为SI -SNR损失基于时域中的采样误差,因此对直接声音和混响之间高度相关的结构敏感[26]。
C. Joint Training With a Multi-Objective Loss Function
在对这两个模块分别进行了良好的训练之后,我们将它们视为联合培训(JT)的集成网络。 类似于去混响阶段,训练网络的一种直接方法是优化在去混响模块的输出上计算出的MSE损耗,如式(7)所示。 但是,与SI-SNR损耗不同,MSE损耗仅反映目标幅度和估计幅度之间的差异,而相位仍未得到解决。 最近的一项研究[34]表明,通过准确的相位谱估计,可以在客观和主观语音质量上都取得显着改善,这暗示了处理相位对产生高质量分离语音的重要性。 由于SI-SNR损耗是在时域中计算的,因此幅度误差和相位误差都被合并了。 换句话说,利用SI-SNR损失进行的训练隐含地涉及相位估计。
基于这一事实,我们设计了一种用于联合训练的多目标损失函数,该函数结合了MSE损失和SI-SNR损失:
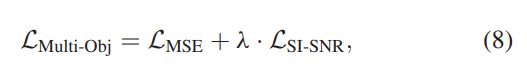
其中λ是预定义的加权因子。 但是,这两种损失的这种组合是未知效果的,因为MSE损失保证为非负,而Eq(5)中的SI-SNR损失是无穷大的。 具体而言,此设计存在两个关键缺陷。 首先,选择合适的λ值是很棘手的,它权衡具有不确定符号的损耗LSI-SNR。 其次,当LMSE接近-λ·LSI-SNR时,由于接近零的梯度,不鼓励多模态网络学习。
为了减轻这些问题,一种直观的方法是定义一个替代的SI-SNR损耗,该损耗应确保与MSE损耗一样非负。 请注意, (5)可以改写成:
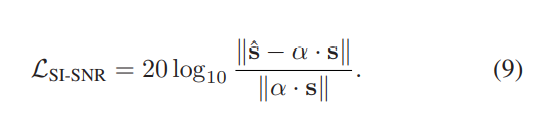
因此,我们定义了一个新的SI-SNR损耗为:
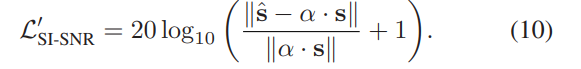
因此,我们用多目标损失函数训练多模态网络:
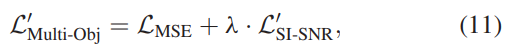
其中LMSE∈[0,+∞)和L‘SI-SNR∈[0,+∞)。 在推论过程中,将估计的频谱幅度与噪声相位结合起来以恢复时域波形。
V. EXPERIMENTAL SETUP
我们为此研究创建了一个新的中文普通话视听数据集。 具体来说,我们从YouTube收集了大约10,000个汉语普通话讲座视频,然后将它们传递到数据集创建管道,如图5所示。管道中的一系列处理步骤导致了一个视听数据集,包括大约170,000个 短片,总时长约155小时。 持续时间在500毫秒到13 s之间的数据集中的每个视频剪辑对应于音频信号(即视频剪辑的音轨)和灰度级嘴唇(嘴)图像的可视流。

基于此新的视听数据集,我们模拟了用于多模式语音分离和去混响的多通道数据。来自中文普通话数据集中不同说话者的音频信号被视为语音源(目标源或干扰源)。此外,从室内记录的255种噪声中随机抽取被视为噪声源。这些声源和麦克风阵列(参见图1(a))随机放置在模拟房间中,在该房间中,声源与麦克风阵列中心之间的距离限制在0.5 m至6 m的范围内。为了包括各种各样的混响环境,我们使用图像方法[2]在2,000个不同的模拟房间中生成了大量的6,000个房间脉冲响应(RIR)。房间大小在4 m×4 m×3 m至10 m×10 m×6 m的范围内随机采样,混响时间(T60)在0.05 s至0.7 s的范围内。 SNR从6、12、18、24和30 dB中随机选择,目标干扰比(TIR)从-6、0和6 dB中选择。 SNR和TIR都在混响信号上定义:
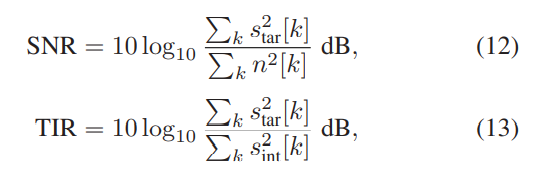
其中,star,sint和n分别表示混响目标语音,混响干扰语音和混响噪声。 根据第二节中描述的信号模型,我们分别在训练集,验证集和测试集中创建了大约45,000、200和500种混合。 请注意,所有的测试扬声器和噪音都从训练集和验证集中排除。 换句话说,我们以与说话者和噪声无关的方式评估模型。
训练集和测试集都包含两个扬声器的混合和三个扬声器的混合,其分布分别如图6(a)和(b)所示。 此外,目标语音信号的DOA与干扰语音信号之间的角度分布如图6(c)和(d)所示。 在三个扬声器(即两个干扰扬声器)的情况下,我们从图6(c)和(d)的两种计数方法中选择较小的角度,即AngleDOA = min {∠(DOAtar,DOAint1),∠( DOAtar,DOAint2)}。

使用Adam优化器[23]在4秒的视听块上训练所有模型,学习率为0.0002。 最小批量大小在块级别设置为20。 通过交叉验证选择最佳模型。 在两阶段方法中,在将分离模块产生的光谱幅度馈入BLSTM层之前,先通过层归一化操作对其进行归一化。 在四个堆叠的BLSTM层之上,具有ReLU非线性的完全连接层用于估计无回声目标语音的频谱幅度。 具体而言,从输入层到输出层,BLSTM分别具有257、512、512、512、512和257个单元。 对于联合训练,我们根据经验选择0.01、0.02、0.05、0.08、0.1、0.2和0.4作为λ值,以权衡MSE损失和SI-SNR损失的重要性。
在这项研究中,我们主要使用两种指标来评估模型,即ESTOI和PESQ。 ESTOI是短时客观清晰度(STOI)的改进版本[39],这是一种客观的语音清晰度估计器,通常用于评估语音增强的性能。 具体地说,如果目标语音信号被具有强时间调制的附加噪声源失真,例如,STOI与主观听觉测试结果不高度相关。 竞争者[20]。 相反,ESTOI在这种情况下以及STOI表现良好的情况下都表现良好。 此外,PESQ是一种语音质量估计器,旨在针对某些降级预测语音质量听力测试的平均意见得分。 STOI分数通常介于0和1之间,而PESQ分数通常介于-0.5和4.5之间。 对于这两个指标,得分越高表示性能越好。
VI. EXPERIMENTAL RESULTS AND ANALYSIS
A. Results and Comparisons
表一给出了ESTOI和PESQ中不同方法的综合比较。数字代表每种测试条件下测试样品的平均值。我们首先比较ID为1-4的四个单阶段基线(ID参见表I),其中分离和去混响在单个阶段中共同执行。这些方法在训练过程中将消声目标语音信号视为所需信号。在方法3和4中,采用具有图3中分离模块架构的膨胀式CNN,将目标语音与干扰语音,背景噪声和房间混响分离。具体而言,方法3使用LSI-SNR训练膨胀的CNN,方法4使用LMSE训练。如表I所示,在ESTOI和PESQ中,方法4始终优于方法3,这表明在存在房间混响的情况下,LMSE比LSI-SNR更具优势。在方法2中,我们从方法4的基线中删除了可视子模块,这导致了纯音频基线。可以看到,方法4始终比方法2产生更高的ESTOI和PESQ,这证明了视觉输入的有用性,从而证明了多模式分离和混响的有效性。方法1(简称为“ BLSTM”)使用BLSTM模型,该模型将原始LPS,cosIPD和AF功能以及视觉子模块产生的视觉嵌入作为输入。它具有四个BLSTM隐藏层,每层中有512个单位,并且使用带有ReLU的完全连接层来估计比率掩码。从表I中,我们可以看到方法4产生的ESTOI和PESQ比方法1高。

现在,我们比较ID为5-7和9-16的两阶段方法,其中在第一阶段执行分离,在第二阶段执行混响。在方法5和6中,图3中的分离模块和去混响模块被分别良好地训练,而整个网络没有被共同地训练。具体而言,方法5在去混响阶段训练具有SI-SNR损失LSI-SNR的BLSTM,而方法6训练具有MSE损失LMSE。如表I所示,这两种方法产生相似的ESTOI,而方法5则比方法6产生了0.12的PESQ改善。应该指出的是,ESTOI旨在测量语音的客观清晰度,不适用于评估混响。此外,方法5和6均明显优于一级基线(即1-4)。例如,方法6与方法4相比,将ESTOI提高了2.33%,将PESQ提高了0.19。此外,方法6产生了比方法7高得多的ESTOI和PESQ,其中,去混响模块中的BLSTM被单通道加权预测误差所代替(WPE)最小化[56]方法。 WPE方法是语音去混响的一种代表性方法。从方法6(无联合培训)到方法9(有联合培训)从根本上改善了这两个指标。请注意,方法9中使用了MSE损失LMSE(即λ= 0的L 'Multi-Obj)进行联合训练。为进一步证明我们提出的两阶段方法的有效性,我们另外训练了一种与以下结构相同的网络在图3中,从头开始训练整个网络,这与方法9不同,在联合优化之前,方法9在两个单独的阶段训练膨胀的CNN和BLSTM。该网络相当于一个单阶段方法,即方法8。我们可以观察到,方法9比方法8显着提高了ESTOI 9.16%,PESQ改进了0.36。可以通过联合训练扩张的CNN和BLSTM与多目标损失函数L’Multi-Obj在第IV-C节中描述。我们发现,就ESTOI和PESQ而言,λ= 0.08导致最佳性能,与未经处理的混合物相比,它的ESTOI改善了21.10%,PESQ改善了0.79。对于表I中的所有方法,就ESTOI和PESQ而言,较小的DOA角对应于未处理混合物的较小改进,因为当目标信号和干扰语音信号之间的DOA角减小时,角度特征的判别力和有效性降低。


此外,图7显示了未处理混合物的SI-SNR改善(SI-SNRi),其中SI-SNRi的计算方式为SI-SNRi = SI-SNRprocessed-SI-SNRunprocessed。可以观察到,方法3和5训练网络直接使SI-SNR最大化,比方法4和6产生更好的SI-SNRi。我们提出的方法(即10-16)比方法7产生更好的SI-SNRi(扩张式CNN + WPE)并接近8(一级)。当λ= 0.08时,我们提出的两阶段方法比未处理的混合物将SI-SNR提高5.91 dB。 λ的进一步增加会导致SI-SNR稍高,因为λ的值越大,会导致训练期间对SI-SNR损失的重视程度越高。图8显示了我们提出的两阶段多模态网络(λ= 0.08)的未处理混合物,消声目标语音和估计语音的频谱图示例。可以在下面找到更多示例。3我们还使用网络版Google的汉语普通话语音识别引擎对我们提出的方法以及两个基准进行了评估。4提出了相对于未处理混合物的误码率(WER)的相对改进。在表II中,相对WER改善的计算方式为(WERunprocessed-WERprocessed)/ WERunprocessed。请注意,未经处理的混合物产生的WER为92.90%。表II中的第一个基线是具有与图3中的分离模块相同架构的扩张式CNN,经过训练可将混响目标语音与干扰语音和背景噪声分离。 换句话说,在此基准中不执行混响,相对于未处理的混合物,WER相对提高了37.13%。 通过额外使用WPE方法进行混响,可获得相对较大的改进。 如表II所示,与未处理的混合物相比,我们提出的方法相对WER改善了46.17%,这明显好于两个基线。 另外,无回声目标语音(即groundtruth)相对于未处理的混合物产生了87.5%的相对WER改善,这为分离和混响系统提供了上限。

我们进一步评估一组说话者组合中的方法6、7、8和13,这些方法是通过在混响环境中混合目标语音和背景噪声而创建的。 表III列出了使用不同说话者数量的混音的ESTOI和PESQ结果,其中所有模型都针对使用两个或三个说话者的混音进行了训练。 可以观察到,方法6和方法7仅比未处理的混合物在ESTOI和PESQ上有轻微的改善,并且可以通过方法8获得进一步的改善。请注意,方法6-8在单说话者混合物上表现出与以下相反的性能趋势 两扬声器和三说话者混音的效果。 我们提出的方法(即方法13)产生的ESTOI和PESQ始终高于三个基准,这表明它在单扬声器场景中具有相对较强的泛化能力。 此外,我们可以看到,随着说话者的干扰,问题变得更加棘手。

此外,在图9(a)和(b)中介绍了所提出的方法(ID为13)针对不同的直接混响比(DRR)[32]范围所产生的ESTOI和PESQ结果。 图9(c)和(d)显示了对未处理混合物的改进。 根据与目标说话者相对应的RIR计算DRR,如下所示:
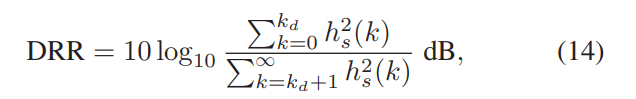
其中,hs表示与第一麦克风上的目标扬声器相对应的RIR,kd是将RIR分为两部分的时间索引,一个用于直接路径传播,另一个用于反射路径引起的混响。 请注意,由于各种其他因素(例如随机选择的SNR和TIR),具有较高DRR的未处理样本并不总是对应于较高的PESQ值。 可以观察到,对于不同的DRR范围,ΔESTOI并没有表现出明显的趋势,因为DRR主要与语音质量有关,而与客观清晰度无关。 如图9(d)所示,较高的DRR对应较大的ΔPESQ。

B. Investigation of Separation Performance
现在,我们研究分离模块的性能。 经过独立训练的分离模块(在联合训练之前)用于调查。 我们使用带有PIT的相同扩张型CNN作为基线模型。 请注意,我们不在PIT基线中使用角度特征和嘴唇特征,因为这些特征是特定于说话者或特定于方向的,因此不适用于PIT设置。 PIT基线有两个输出,一个用于目标混响语音,另一个用于残差信号。 残留信号是通过从第一通道混合中减去目标混响语音得出的,该混响包含干扰性混响语音和背景噪声。 我们使用等式中的SI-SNR损失训练PIT基线。 (5)。 如表IV所示,建议的分离模块明显优于PIT基线,这表明视觉信息以及角度特征都改善了分离性能。
C. Impact of Visual Features on Separation and Dereverberation
本节将进一步研究视觉信息对分离和混响的影响。我们首先将建议的方法与新的基线模型进行比较,该模型在整个网络中不使用任何可视输入。通过从图3所示的多模式网络中删除可视子模块,可以轻松得出基线。表V列出了ESTOI,PESQ和SI-SNRi结果。我们可以观察到视觉信息的删除会显着降低这三个指标的性能,这表明视觉输入的有效性。为了研究视觉特征对混响的影响,我们另外训练了一个基线模型进行比较,该模型在分离模块和混响模块中都使用了视觉嵌入。两个模块中使用的视觉嵌入是通过同一视觉子模块学习的。具体来说,我们将分离模块的输出光谱与视觉嵌入连接起来,然后将其馈入BLSTM进行去混响。请注意,分离后的光谱和视觉嵌入在串联之前先通过层归一化层。如表V所示,与所建议的方法相比,包含去混响的视觉特征对ESTOI和SI-SNRi的改善很小,而对PESQ的改善却很小。一种解释是,由于联合训练,去混响模块隐含地受益于分离模块中的视觉特征。因此,没有必要在混响模块中明确使用视觉特征。

D. Robustness Against Missing Visual Frames
在实际应用中,说话者的嘴唇图像不会始终被捕获,尤其是当它们不临时面向相机时。 这些嘴唇图像被认为是缺少视觉输入。 在这种情况下,我们通过以下方式补偿丢失的嘴唇图像。 如果目标框丢失或说话者的嘴巴受到干扰,则会填充最新的现有框。 为了研究我们提出的方法针对丢失的嘴唇信息的鲁棒性,我们随机丢弃每个说话者的帧,并在推理过程中应用补偿方法。 我们研究了三种情况:(1)仅干扰说话者的嘴唇信息部分丢失; (2)仅目标说话者的嘴唇信息部分丢失; (3)所有说话者的嘴唇信息部分丢失。

表VI显示,即使所有说话人的嘴唇信息都不完整,该方法对于丢失40%的帧丢失率的嘴唇信息也具有鲁棒性。 对于80%的可视帧丢失率,如果仅部分丢失了说话者的嘴唇信息,则性能几乎不会降低。 但是,如果缺少80%的目标说话者的嘴唇图像,则ESTOI和PESQ都会大大降低。 如果干扰说话者的嘴唇信息完整,则这种减少会变得更缓和,这表明存在干扰说话者的嘴唇信息会提高抵抗丢失视觉帧的鲁棒性。 此外,我们想指出的是,即使所有扬声器的唇框缺失了80%,我们的系统仍然可以正常工作。 这可能是由于使用了角度功能(请参阅第III-C节),这些功能为目标说话者提供了有用的方向提示。
E. Robustness Against Reduced Lip Image Resolution
在实践中,由于相机质量较差,嘴唇图像的分辨率可能会很低。 为了研究所提出的方法针对较低图像分辨率的鲁棒性,我们降低了测试样本的所有扬声器的嘴唇图像分辨率。 具体来说,我们首先将嘴唇图像从112×112下采样到64×64,然后再将它们上采样回到112×112。这样的操作会降低图像分辨率。 如表VII所示,所提出的模型对于降低的图像分辨率是鲁棒的。

VII. CONCLUDING REMARKS
在这项研究中,我们提出了一个两阶段多模态网络,用于在嘈杂和混响环境中进行视听分离和混响,其原因是加性干扰(例如,干扰语音和背景噪声)和卷积性干扰(例如,房间混响)会导致失真以本质上不同的方式针对语音。基于扩张的基于CNN的分离模块(同时接收音频和视觉输入)被用于将混响目标语音与干扰语音和背景噪声分离。分离模块的输出随后通过基于BLSTM的混响模块。首先分别训练两个模块,然后共同训练以优化新的多目标损失函数,该函数将时域损失和T-F域损失结合在一起。系统评估表明,我们提出的两阶段多模式网络在客观清晰度和感知质量方面始终优于几个一阶段和两阶段基线。我们发现,与未处理的混合物相比,拟议的网络大大改善了ESTOI和PESQ。此外,我们的网络体系结构可以接受来自任意数量的干扰说话者的视频流,这比不允许说话者数量从培训更改为测试的多模式网络更具优势。
应当注意,所提出的模型是非因果系统,其利用大量未来信息进行估计。 这种模型不适用于实时处理,这在许多实际应用中都有很高的要求。我们已经初步研究了一些因果模型和部分因果模型用于实时处理,没有或只有很低的延迟。 对于将来的工作,我们将投入更多的精力来设计新的多模式网络体系结构,以在远场场景中实现实时语音分离和混响。














 3788
3788











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









