





SED文章翻译:LARGE-SCALE WEAKLY SUPERVISED AUDIO CLASSIFICATION USING GATED CONVOLUTIONAL NEURAL NETWORK
abstract
在本文中,我们提出了一种门控卷积神经网络和一种基于时间注意力的音频事件分类方法,在声场景和事件检测和分类 (DCASE) 的大规模弱监督声音事件检测任务中获得第一名) 2017 年的挑战。此任务中从 YouTube 视频中提取的音频剪辑被手动标记为一个或多个音频标签,但没有音频事件的时间戳(即没有短时label),因此称为弱标记数据。在这个挑战中定义了两个子任务,包括使用这种弱标记数据的音频标记和声音事件检测。我们提出了一个卷积循环神经网络 (CRNN),它具有非线性的应用于对数梅尔谱图的可学习门控线性单元 (GLU)上 。此外,我们提出了一种沿帧的时间注意方法,以根据弱标记数据预测块中每个音频事件的位置。我们系统的性能在 DCASE 2017 挑战的这两个子任务中作为一个团队排名第一和第二,F 值分别为 55.6% 和 Equal error 0.73。
1. INTRODUCTION
音频分类是一项将录音分类为不同类别的任务。弱标记音频数据仅包含音频事件的存在或不存在,但不包含音频事件的时间戳 [1]。弱标记音频分类在信息检索[2]、公共区域异常声音监控和工业使用[3]中有很多应用。一些挑战将音频分类划分为子任务,包括音频场景分类 [4] 和声音事件检测 [4]。最近,作为声学场景和事件检测和分类 (DCASE) 2017 挑战的一部分,提出了大规模弱监督声音事件检测任务 [5]。在这个挑战中,数据集是包含交通和警告声音的谷歌音频集 [6] 的子集。该任务包括音频标记 (AT) [7] 子任务和弱监督声音事件检测 (SED) [8] 子任务。 AT 任务旨在预测录音的一个或多个标签,而 SED 需要预测音频事件的时间戳。
许多音频分类方法都是基于帧包[9]假设,其中一段录音被切成段,每个段继承录音的标签。 然而,这种假设是不正确的,因为某些音频事件仅在音频剪辑中发生很短的时间。 多实例学习 (MIL) [1] 已应用于训练弱标记数据。 最近最先进的音频分类方法 [10, 11] 将波形转换为时频 (T-F) 表示。 然后将 T-F 表示视为输入 CNN 的图像。 然而,与对象通常居中并占据图像的主要部分的图像分类不同,音频事件可能只发生在音频记录中的一小部分。 为了解决这个问题,一些用于音频分类的注意力模型 [12] 被应用于关注音频事件并忽略不相关的特征。
在本文中,我们提出了一个统一的神经网络模型,它同时适用于音频标记任务和弱标记声音事件检测任务。 本文的第一个贡献是在卷积神经网络的每一层之后应用可学习的门控线性单元(GLU)[13]替换ReLU激活[14]进行音频分类。 这个可学习的门能够控制到下一层的信息流。 当门值接近 1 时,对应的 T-F 单元被关注。 当门值接近 0 时,则忽略相应的 T-F 单元。 在卷积层之后,循环层用于利用时间信息。 然后提出了一种时间注意方法来定位块中的音频事件。该注意部分有助于捕获音频事件并忽略不相关的音频段,因此它能够从弱标记的数据中检测声音事件。

2. PROPOSED GATED LINEAR UNITS IN CRNN FOR AUDIO TAGGING
2.1 CRNN
CRNN 已成功用于音频分类任务 [15, 11]。 对于音频标签,[16, 12] 中提出了一种基于 CRNN 的方法来预测音频标签。 首先,录音的波形被转换为 T-F 表示,例如对数梅尔频谱图。 然后将卷积层应用于 T-F 表示以提取高级特征。 然后采用双向循环神经网络 (Bi-RNN) 来捕获时间上下文信息,然后使用前馈神经网络 (FNN) 来预测每一帧每个音频类的后验信息。 最后,通过对所有帧的后验求平均得到每个音频标签的预测概率。
在训练阶段,我们在预测概率和录音的真实情况之间应用二元交叉熵损失。 神经网络的权重可以通过使用反向传播计算的损失函数的梯度来更新。 损失可以定义为:
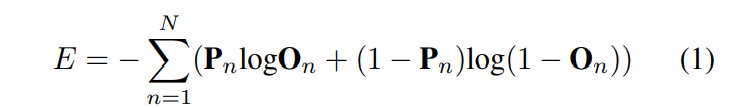
其中 E 是二进制交叉熵,On 和 Pn 分别表示第 n 个音频剪辑的估计和参考标签概率向量。 数字 N 代表小批量大小。
2.2 Mini-batch data balancing
本次挑战中定义的数据集高度不平衡,导致每个类别的样本数量差异很大。 例如,“汽车”类在数据集中出现了 25744 次,而“汽车警报”只出现了 273 次。 这种高度不平衡的数据会使训练偏向于出现大量事件的类别。 由于我们使用 mini-batch 来训练网络,因此存在一种极端情况,即 mini-batch 中的所有样本都是“汽车”。 为了解决这个问题,我们在小批量中平衡不同类别的频率,以确保最频繁的样本数量平均是小批量中最不频繁样本的 5 倍。
2.3. Gated linear units in CNNs
我们建议使用门控线性单元 (GLU) [13] 作为激活函数来替代 CRNN 模型中的传统 ReLU [14] 激活函数。 GLU 在 [13] 中首次被提出用于语言建模。 在音频分类中使用 GLU 的动机是将注意力机制引入神经网络的所有层。 GLU 可以控制一个 T-F 单元流到下一层的信息量。 如果一个 GLU 门值接近于 1,则对应的 T-F 单元被参与。 如果 GLU 门值接近 0,则忽略相应的 T-F 单元。 通过这种方式,网络可以学习关注音频事件并忽略不相关的声音。 GLU 定义为:
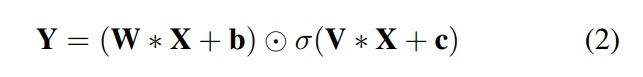
分别代表点乘和卷积乘。
该模型的框架如图 1 所示。一对卷积网络用于生成门控输出和线性输出。 这些 GLU 可以通过为梯度传播提供线性路径同时通过 sigmoid 操作保持非线性能力来减少深度网络 [13] 的梯度消失问题。 每层的输出是由门 σ(V ∗ X + c) 调制的线性投影 (W ∗ X + b)。 类似于长短期记忆 (LSTM) [17] 或门控循环单元 (GRU) [18] 中的门控机制,这些门将矩阵的每个元素 (W * X + b) 相乘并控制传入的信息层次结构[13]。 从特征选择的角度来看,GLU 可以被视为对每个特征图的时频 (T-F) bin 的注意方案。 该方案可以通过将其值设置为接近 1 否则设置为零来处理具有相关音频事件的 T-F bin。
2.4. Fusion of system results
系统结果的融合对于提高系统的鲁棒性在经验上很重要。 在这项工作中,我们采用两级融合策略。 由于神经网络由基于梯度的优化算法以固定或动态变化的学习率进行训练,因此性能将逐渐变好,但会随着时间的推移而波动。 因此,我们的第一个融合策略是在同一系统的多轮训练之间进行的。 这将提高其系统的稳定性。 第二个融合策略是对来自具有不同配置的不同系统的后验进行平均。
3. PROPOSED LOCALIZATION FOR WEAKLY SUPERVISED SOUND EVENT DETECTION
与第二节中不需要预测每个音频事件的时间位置的音频标记任务不同。 声音事件检测 (SED) 任务需要预测每个发生的音频事件的时间位置。 如果没有强标签,即帧级标签,问题会更加困难。 这就是DCASE2017挑战任务4中定义的所谓弱监督SED。
如图 1 的定位模块所示,引入了一个额外的前馈神经网络(FNN),以 softmax 作为激活函数,以帮助推断每个发生类的时间位置。 为了保持输入整个音频频谱图的时间分辨率,我们通过仅在频谱轴上池化而不在时间轴上池化来调整图 1 所示 CNN 中的池化步骤。 因此,图 1 中以 sigmoid 为激活函数的前馈网络将在每一帧进行分类,同时图 1 中以 softmax 为激活函数的前馈网络将关注每个类的最显着帧 .
4.exp and result
Log Mel 滤波器组和 Mel 频率倒谱系数 (MFCC) 在我们的系统中用作特征。 每个音频录制特征都有 240 帧 x 64 mel 通道。 如图 1 所示,采用了三个门控卷积神经网络块。 每个卷积网络有 64 个 33 大小的过滤器。 音频标记子任务的池化大小为 22,而声音事件检测子任务的池化大小为 1*2,这意味着沿时间轴不应用池化以保持声音事件检测的时间分辨率。 使用了一个具有 128 个单元的双向门控循环神经网络。 前馈神经网络有 17 个输出节点,每个节点对应一个音频事件类。 应用 Adam [19] 优化器,学习率固定为 0.001。 这些超参数是凭经验选择的
5.conclusion
在本文中,我们提出了一种统一的音频标记和弱监督声音事件检测方法。 提出了一种门控 CRNN 方法,其中可学习的门控线性单元可以帮助选择与最终标签对应的最相关的特征。 还提出了一种基于时间注意力的定位方法,以弱监督模式沿块定位发生的事件。 最终的系统让我们在 DCASE2017 挑战的音频标记子任务中以 57.7% 的 F1 分数排名第一。 我们还在弱监督声音事件检测子任务中作为团队排名第二。 在不久的将来,我们将在 Google Audio Set [6] 上评估我们提出的门控和注意力方法。















 469
469











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









