







在索引的建立上,建议不要把内容较长的字段(例如:身份证)作为主键,太占用空间。
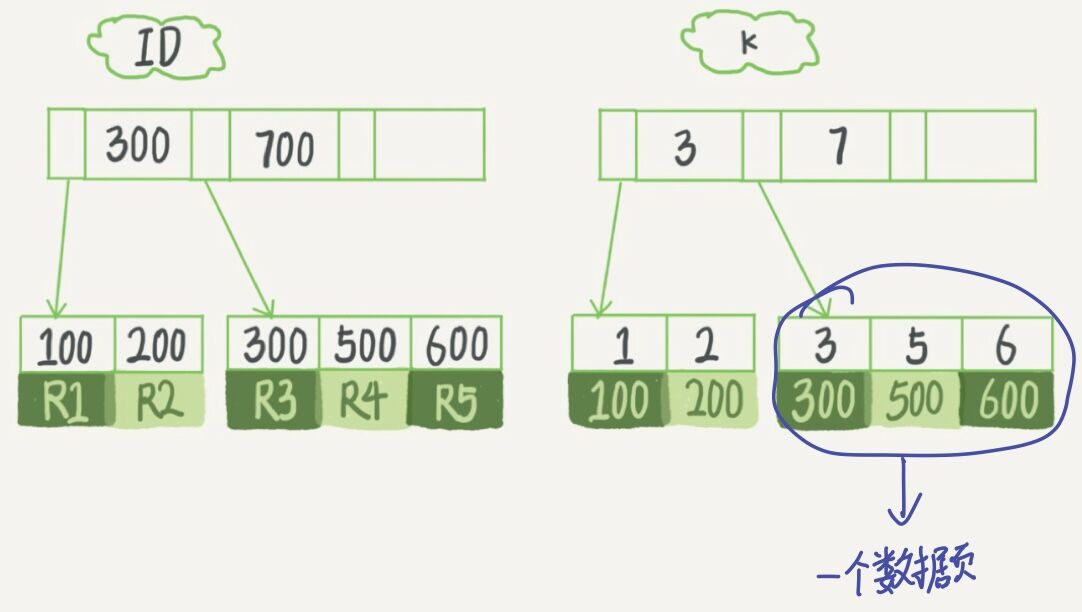
上面有两个索引,我们分析下在查询和更新语句中性能如何?
查询过程
假设查询的语句是 select id from T where k=5。
- 在普通索引上,查到满足条件的第一个记录(5,500)之后,再查找下一条记录,查到碰到不满足条件 k=5 的记录为止。
- 在唯一索引上,由于索引有唯一性,所以找到第一个满足条件的记录之后,就停止检索。
性能差距:微乎其微。
因为,InnoDB 是按照页来读写的,默认页大小是 16KB。所以当找到 k=5 的记录时,它所在的页已经在内存里面了,哪怕找下一个也是很容易的。只是,这个 k=5 刚好是这个页的最后一条,那么就麻烦点。
不过,对于一个整型字段,一个页可以放近千个 key,出现这种情况概率很低,所以忽略不计。
更新过程
首先介绍一下 change buffer。
当更新一条语句时,这个数据页在内存中,则直接更新。如果不在,那么首先将更新操作缓存到内存中的 change buffer,等到下次查询访问这个数据页的时候,将数据页放入内存,再将 change buffer 中的操作同步到数据页中。
change buffer 是可以持久化的数据,它在内存中有拷贝,也会被写到磁盘上。
将 change buffer 的内容操作到原始数据页中,这个叫 merge。除了访问这个数据页时会触发 merge,系统有后台线层定期 merge,在数据库正常关闭(shutdown)也会 merge。
merge 的执行流程:
- 从磁盘读入数据页到内存(老版本的数据页);
- 从 change buffer 里找出这个数据页的记录(可能有多个),依次应用,得到新版的数据页;
- 写 redo log。这个 redo log 包含了数据的变更和 change buffer 的变更。
到这里 merge 过程就结束了。
有了 change buffer,就可以减少读磁盘。并且,数据页读入内存也会占用 buffer pool 的,所以也能提高内存利用率。
༼ つ ◕_◕ ༽つ那什么时候用 change buffer比较好呢?
其实,唯一索引都不会用 change buffer,因为,不读入内存,你不能判断它是否已经存在。所以 change buffer 只有普通索引能用。
change buffer 用的是 buffer pool 里的内存。大小可以用innodb_change_buffer_max_size来调,当这个参数为 50 时,表示 change buffer 最多用 buffer pool 的 50%。
那么插入一个新记录(4,400),InnoDB 会怎么做呢?
当这个目标的数据页在内存中时:
- 唯一索引,找到 3 和 5 之间的位置,判断到没有冲突,插入,语句结束。
- 普通索引,找到 3 和 5 之间的位置,插入,结束。
这个的差别就是多了个判断,基本构不成区别。
可是,当这个目标数据页不在内存中时:
- 唯一索引,先将数据页调入内存,判断是否有冲突,再插入,结束
- 普通索引,直接将更新记录写入 change buffer,语句执行结束。
在数据库中,从磁盘读入内存涉及到随机 IO 访问,是数据库中成本最高的开销之一。所以减少随机 IO,会对性能有着明显提升。
change buffer 的使用场景
对于写多读少的业务来说,页面写完之后不会立马被访问到,使用 change buffer 的使用效果最好。
反而读多写少的业务,写完后马上做查询,这样随机 IO 访问不会减少,反而 change buffer 还会增加开销,拖慢性能。
在实际中,普通索引和 change buffer 配合使用,对于数据量大的表更新优化还是很明显的。
change buffer 和 redo log
当我们要插入这条语句时:
insert into t(id,k) values(id1,k1),(id2,k2)
此时,k1 所在的数据页在内存(InnoDB buffer pool)中,k2 的数据页在磁盘中,redo log也是在磁盘中。
- k1 直接在内存中更新;
- k2 数据页不在内存中,就往 change buffer 写入(我要向 k2 数据页插入一行)这个信息;
- 将上面两个动作写入 redo log 中。
做完这些,这个事务就完成了。写了两次内存,一次磁盘。
༼ つ ◕_◕ ༽つ那么读 k1,k2 的时候怎么办呢?
- 读 k1 时,直接从内存返回。(如果在 WAL 之后读数据,是不是一定读磁盘?其实不用,磁盘中的 k1 还是以前的数据,现在读是直接读内存的数据。)
- 读 k2 时,要把 k2 的数据页从磁盘读入内存中,然后应用 change buffer 中的操作日志,生成一个正确的版本并返回结果。
当要读 k2 的时候,数据才被写入数据页。
所以两者的区别是:
- redo log 主要是节省随机写磁盘的 IO 消耗(转成顺序写)
- change buffer 主要节省的是随机读磁盘的 IO 消耗。
小结
唯一索引用不了 change buffer 的优化,因此如果业务能接受,从性能的角度出发,优先考虑非唯一索引。















 211
211











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









