







文章目录
1. 基数排序原理
- 基数:10进制的基数是10,二进制的基数是2,26个英文字母的基数是26
算法步骤:
- 求出待排序序列中最大关键字的位数d ,然后从低位到高位进行基数排序
- 按个位将关键字依次分配到桶中,然后将每个桶中的数据都依次收集起来
- 按十位将关键字依次分配到桶中,然后将每个桶中的数据都依次收集起来
- 依次进行下去,直到d 位处理完毕,得到一个有序的序列
例子:
10个学生的成绩:68, 75, 54, 70, 83, 48, 80, 12, 75* , 92 对成绩进行基数排序
- 最大分数是92,两位数,因此只要进行两趟基数排序
- 创建0-9号一共10个桶,将学生成绩先按个位数字放入对应的桶中
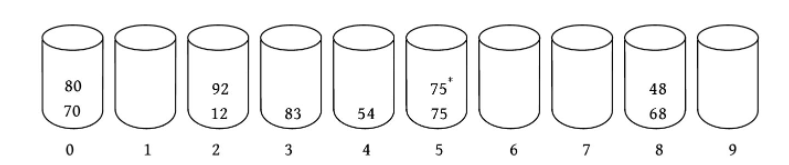
- 按桶的编号进行收集,得到分数序列
70, 80, 12, 92, 83, 54, 75, 75* , 68, 48 - 继续分配,这次按分数的10位数,划分到对应的桶中

- 再次收集,得到排好序的序列:
12 48 54 68 70 75 75* 80 83 92
代码实现:
public static void radixSort(int[] data) {
int n=data.length;//元素个数
int maxVal=Arrays.stream(data).max().getAsInt();//获取最大元素
int maxLen=(""+maxVal).length();//获取最大元素的长度(位数)
int radix=1;//
for(int i=1;i<=maxLen;i++) {
int[] cnt=new int[10];//计数器
int[] tmp=new int[n];//辅助数组
for(int j=0;j<n;j++) {
int num=(data[j]/radix)%10;//先取个位数 再去十位数
cnt[num]++;//统计每个桶中的元素个数
}
for(int k=1;k<10;k++) {
cnt[k]+=cnt[k-1];//桶中元素累加
}
for(int k=n-1;k>=0;k--) {
int num=(data[k]/radix)%10;
tmp[--cnt[num]]=data[k];
}
radix*=10;
System.arraycopy(tmp,0, data, 0, n);//将tmp数组内容赋值到原数组中
System.out.println("第"+i+"趟排序结果:"+Arrays.toString(data));
}
}

- 时间复杂度: O ( n d ) O(nd) O(nd): n是元素个数,d是最大数字的位数
- 空间复杂度: O ( n + r ) O(n+r) O(n+r): tmp数组大小为n, cnt数组的大小为基数r
- 基数排序是按关键字出现的顺序依次进行的,是稳定的排序方法
2. 后缀数组
2.1 后缀
后缀指从某个位置开始到字符串末尾的一个特殊子串
以字符串s =“aabaaaab”为例,Suffix(i)表示从第i个字符开始的后缀(i从0开始)
Suffix(0): “aabaaaab”
Suffix(1): “abaaaab”
Suffix(2): baaaab
Suffix(3): “aaaab”
Suffix(4): “aaab”
Suffix(5): “aab”
Suffix(6): “ab”
Suffix(7): “b”
2.2 后缀数组
将后缀按字典序排序,取其下标,得到后缀数组
Suffix(3): “aaaab”
Suffix(4): “aaab”
Suffix(5): “aab”
Suffix(0): “aabaaaab”
Suffix(6): “ab”
Suffix(1): “abaaaab”
Suffix(7): “b”
Suffix(2): baaaab
后缀数组为SA[]={3,4,5,0,6,1,7,2}
2.2 排名数组
排名数组指下标为i 的后缀排序后的名次

后缀数组和排名数组是互逆的:

3. 后缀数组的实现
3.1 构建思路
后缀数组有两种方法构建,DC3算法和倍增算法,DC3法的时间复杂度为O(n), 但代码复杂,倍增法的时间复杂度为O(nlogn), 代码量较少
采用倍增算法,对字符串从每个下标开始的长度为2k 的子串进行排序,得到排名。k 从0开始,每次都增加1,相当于长度增加了1倍。当2k ≥n 时,从每个下标开始的长度为2k 的子串都相当于所有后缀。每次子串排序都利用上一次子串的排名得到。
以字符串aabaaaab为例:
-
对长度为1的子串进行排名
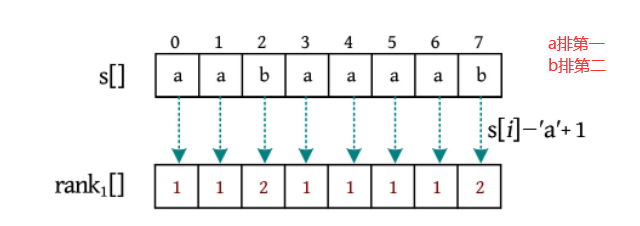
-
对长度为 2 × 1 = 2 2\times1=2 2×1=2的子串进行排名
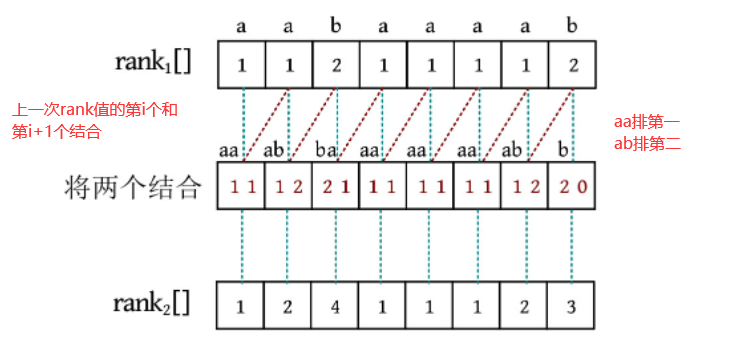
-
对长度为 2 × 2 = 4 2\times2=4 2×2=4的子串进行排名
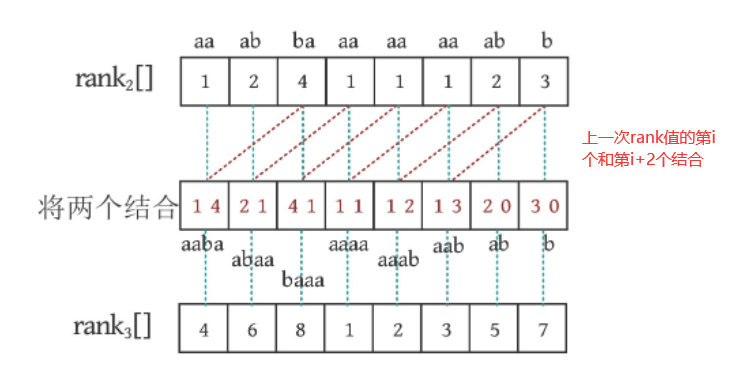
-
对长度为 2 × 3 = 6 2\times3=6 2×3=6的子串进行排名
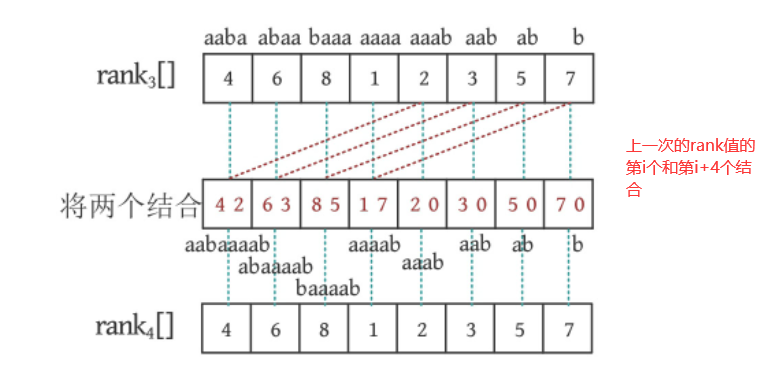
第3步中排名数组的值各不相同,实际上已经得到了后缀排名了,所以第4步的结果和第3步一样
根据前面介绍的,排序数组的值和后缀数组的值是互逆的,比如排名第4的后缀是aaba(索引位置是0),即rank[0]=4, 所以SA[4]=0, 以此类推,得到后缀数组的值SA={3, 4, 5, 0, 6, 1, 7, 2}
重点:
rank排名数组:索引是后缀字符串的开始位置,值是改字符串对应的排名
sa后缀数组:索引是后缀字符串对应的排名,值是改后缀字符串开始的索引
3.2 后缀数组的代码实现与分析
public static int[] calSuffixArray(String s) {
int n=s.length()+1;//字符串长度
int m=3;//基数
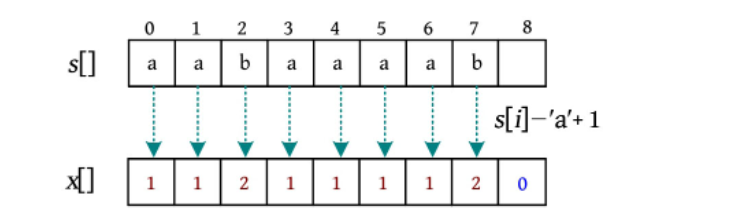
int[] x=new int[n];//x数组存储字符串转化后的数字 多一个位置防止比较时越界,在末尾用0封装
for(int i=0;i<n-1;i++) {
x[i]=s.charAt(i)-'a'+1;
}
x[n-1]=0;
System.out.println("x: "+Arrays.toString(x));
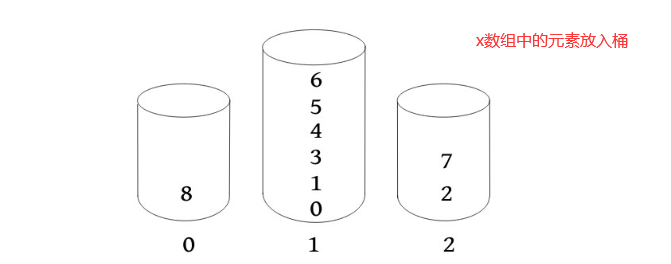
int[] cnt=new int[m];//计数数组---桶
int[] sa=new int[n];//后缀数组
for(int i=0;i<n;i++) {
cnt[x[i]]++;//记录每个数字出现的次数
}
System.out.println("cnt: "+Arrays.toString(cnt));
for(int i=1;i<m;i++) {
cnt[i]+=cnt[i-1];//累加次数
}
System.out.println("cnt: "+Arrays.toString(cnt));
for(int i=n-1;i>=0;i--) {
sa[--cnt[x[i]]]=i;
}
System.out.println("初始时单个字符的排名:");
System.out.println("x: "+Arrays.toString(x));
System.out.println("sa: "+Arrays.toString(sa));
System.out.println("进入循环处理.....");
int[] y=new int[n];
for(int k=1;k<=n;k<<=1) {
System.out.println("k="+k+"------------------------");
int p=0;
for(int i=n-k;i<n;i++) {
y[p++]=i;
}
for(int i=0;i<n;i++) {
if(sa[i]>=k) {
y[p++]=sa[i]-k;
}
}
//将第2关键字的排序结果转化为排名 正好是第一关键字
int[] wv=new int[n];
for(int i=0;i<n;i++) {
wv[i]=x[y[i]];
}
//对第一关键字进行计数排序 得到新的sa数组
cnt=new int[m];
for(int i=0;i<n;i++)
cnt[wv[i]]++;//计数
for(int i=1;i<m;i++)
cnt[i]+=cnt[i-1];//计数累加
for(int i=n-1;i>=0;i--)
sa[--cnt[wv[i]]]=y[i];
System.out.println("sa: "+Arrays.toString(sa));
System.out.println("交换前的y: "+Arrays.toString(y));
//y数组已经没用 此时需要计数新的x数组 就让y保存旧的x数组中的数据
int[] tmp=x;
x=y;
y=tmp;
System.out.println("旧的x: "+Arrays.toString(x));
p=1;
x[sa[0]]=0;
for(int i=1;i<n;i++) {
x[sa[i]]=(y[sa[i-1]]==y[sa[i]]&&y[sa[i-1]+k]==y[sa[i]+k])?p-1:p++;
}
m=p;
System.out.println("交换后的y: "+Arrays.toString(x));
System.out.println("新的x: "+Arrays.toString(x));
}
return sa;
}
第一段代码分析:
int n=s.length()+1;//字符串长度
int m=3;//基数
int[] x=new int[n];//x数组存储字符串转化后的数字 多一个位置防止比较时越界,在末尾用0封装
for(int i=0;i<n-1;i++) {
x[i]=s.charAt(i)-'a'+1;
}
x[n-1]=0;
System.out.println("x: "+Arrays.toString(x));
//下面是基数排序部分
int[] cnt=new int[m];//计数数组---桶
int[] sa=new int[n];//后缀数组
for(int i=0;i<n;i++) {
cnt[x[i]]++;//记录每个数字出现的次数
}
System.out.println("cnt: "+Arrays.toString(cnt));
for(int i=1;i<m;i++) {
cnt[i]+=cnt[i-1];//累加次数
}
System.out.println("cnt: "+Arrays.toString(cnt));
for(int i=n-1;i>=0;i--) {
sa[--cnt[x[i]]]=i;
}
System.out.println("初始时单个字符的排名:");
System.out.println("x: "+Arrays.toString(x));
System.out.println("sa: "+Arrays.toString(sa));
-
先将字符转化成对应的数字,比如a对应1,b对应2,存储在x数组中,另外x数组的长度比字符串长度多1,该位置存储0,防止后面出现下标为-1的情况
-
然后使用前面提到的基数排序
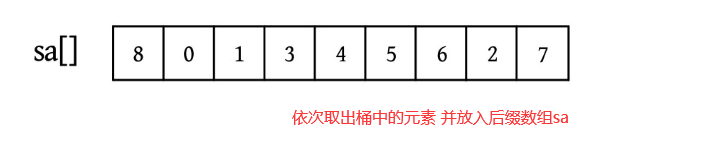
到此为止,初始化操作就完成了
第二部分代码分析(核心代码)
刚刚只处理了单个字符的排名,即子串长度是1,那么如果要处理子串长度为2的情况呢?
int p=0;
for(int i=n-k;i<n;i++) {
y[p++]=i;
}
for(int i=0;i<n;i++) {
if(sa[i]>=k) {
y[p++]=sa[i]-k;
}
}
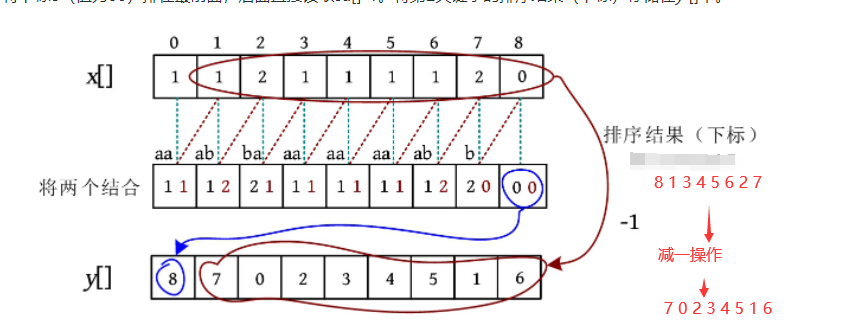
解释一下:8 1 3 4 5 6 2 7 , 在x数组中的位置1-8处,x[8]=0最小,所以对应的下标8排在最前面,然后是x[1]=x[3==x[4]=x[5]=x[6]=1第2小,按顺序取1 3 4 5 6
上面的y[]数组的结果实际上就是根绝第2关键字(第2个字符)进行排序的结果,以y[1]=7为例,表示排第一的子串从下标7开始,对应"b",第2个字符没有,最小;y[2]=0,表示排第2的子串从下标0开始,对应"aa",y[3]=2,表示排第3的子串从下标2开始,对应"ba…,所以相当于是根据第2关键字进行了一个排序,没有第2关键字的排第一
当考虑长度为2的子串时,可以发现改子串是由子串长度为1的情形下加上后面一个字符构成的,现在考虑按第2个字符进行排序,只需要将x中索引位置1-8的对应的单个字符的排名减一即可,why?
可以这样理解,原来的字符串是aabaaaab 现在只考虑第一个a后面的字符串,即abaaaab 原始字符串中第2个a排第2,现在第一个a走了,它就排第一了。(比如在x []数组中,第2个元素1原来的下标为1,现在结合后对应的下标为0)
if(sa[i]>=k): 加上这个判断是因为,不是所有字符的排名都可以上升的,举个例子,一个班上的第k名走了,每个人的排名都会受影响吗?不是,假设走的是第4名,前三名依然是前三名,只有第k名及其以后的排名会收影响
//将第2关键字的排序结果转化为排名 正好是第一关键字
int[] wv=new int[n];
for(int i=0;i<n;i++) {
wv[i]=x[y[i]];
}
//对第一关键字进行计数排序 得到新的sa数组
cnt=new int[m];
for(int i=0;i<n;i++)
cnt[wv[i]]++;//计数
for(int i=1;i<m;i++)
cnt[i]+=cnt[i-1];//计数累加
for(int i=n-1;i>=0;i--)
sa[--cnt[wv[i]]]=y[i];
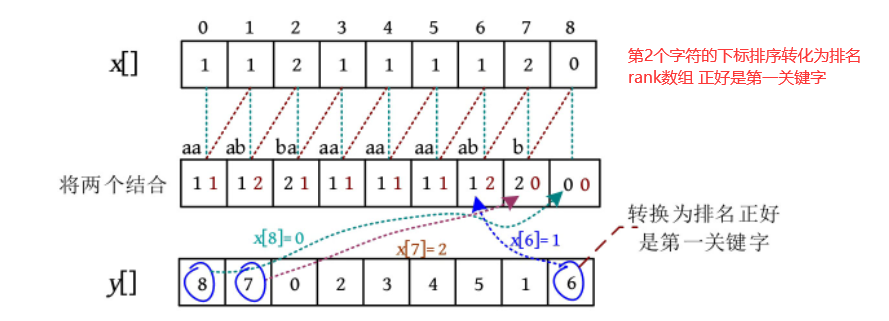
wv=0, 2, 1, 2, 1, 1, 1, 1, 1 , 前面的y[]数组其实已经对第2关键字排过序了,现在只需要根据按第2关键字排序后的序列对第一关键字进行基数排序即可,wv就是根据按第2关键字排序后的序列,然后对wv再按第一关键字进行基数排序(相当于基数排序中的个位处理好了处理十位)
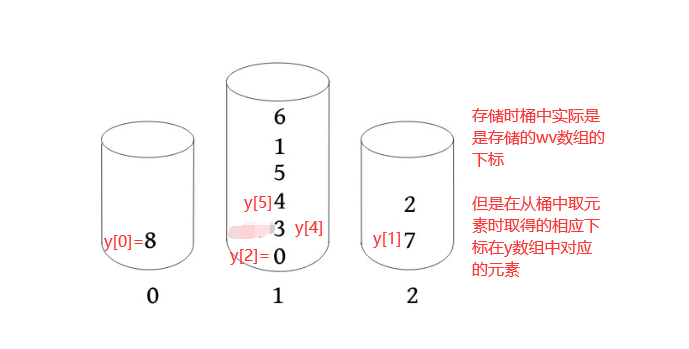

到此为止,新的sa数组已经计算出来了,现在需要计算新的x数组(排名数组)
核心代码如下:
//y数组已经没用 此时需要计数新的x数组 就让y保存旧的x数组中的数据
int[] tmp=x;
x=y;
y=tmp;
System.out.println("旧的x: "+Arrays.toString(x));
p=1;
x[sa[0]]=0;//sa[0]一直等于8 该位置赋值0 多出来的位置
for(int i=1;i<n;i++) {
x[sa[i]]=(y[sa[i-1]]==y[sa[i]]&&y[sa[i-1]+k]==y[sa[i]+k])?p-1:p++;
}
m=p;//改变桶的数量 因为刚开始只有排名0 1 2 后面排名会有3 4 5 6....
System.out.println("交换后的y: "+Arrays.toString(x));
System.out.println("新的x: "+Arrays.toString(x));
}
sa[i]表示的是下标,x[sa[i]]表示的是以某个下标开始的子串的排名
sa[i-1]和sa[i]表示第i-1名和第i名的下标:
-
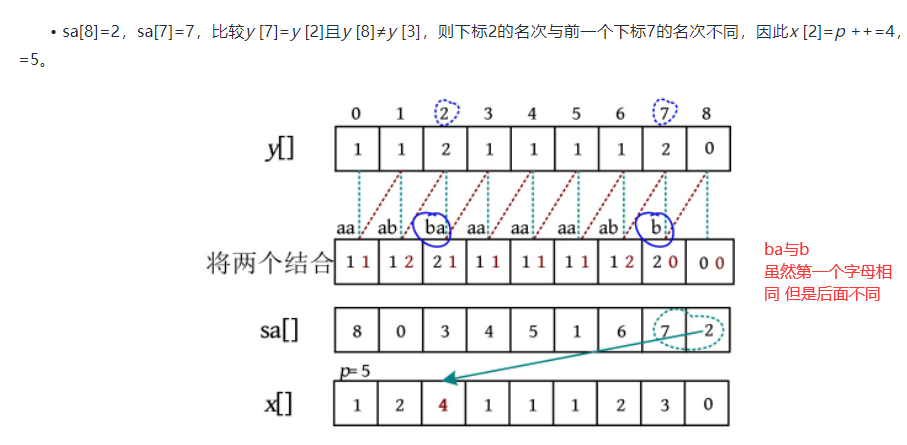
如果这两个下标在旧的排名数组中对应的排名不一样,则以sa[i]作为起始下标的子串的排名+1
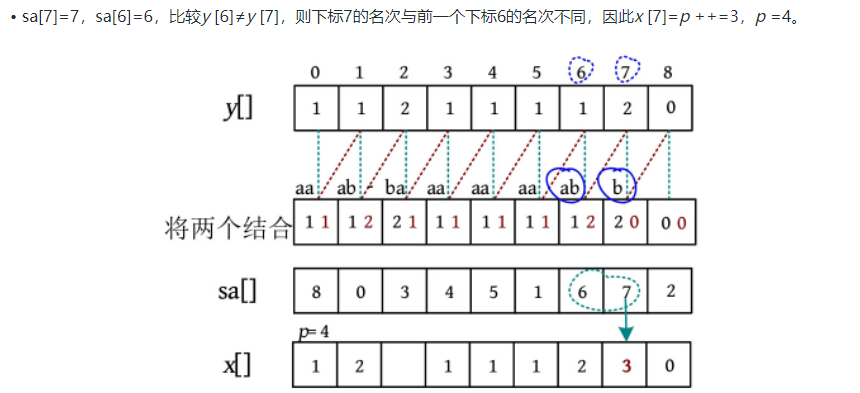
-
如果这两个下标在旧的排名数组中对应的排名一样,即y[sa[i-1]]==y[sa[i], 但是第2部分的排名不一样,即y[sa[i-1]+k]!=y[sa[i]+k], 排名还是加一
-
如果这两个下标在旧的排名数组中对应的排名一样,即y[sa[i-1]]==y[sa[i], 第2部分的排名也一样,即y[sa[i-1]+k]==y[sa[i]+k], 则排名不变
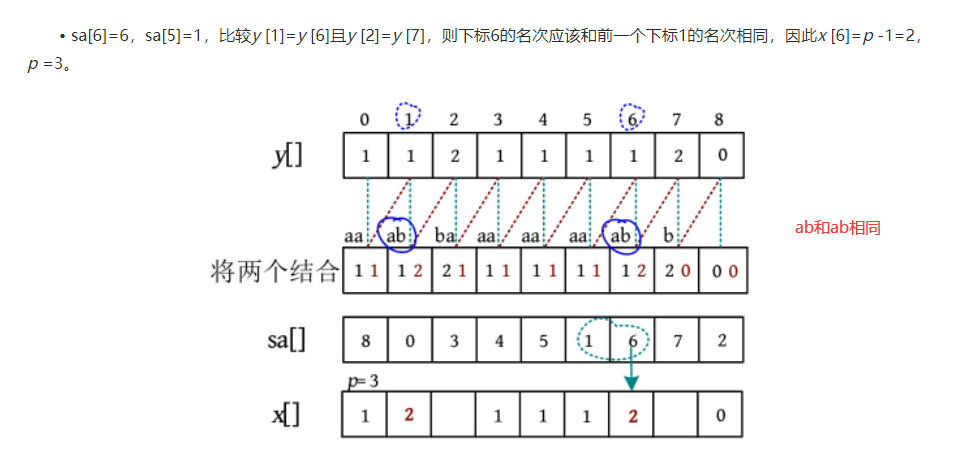
按照上面的思路,后续处理长度为4,8的子串,当处理完长度为2的子串之后,这些长度为2的子串的排名已经知道了,因此当处理长度为4的子串时,分为两个长度为2的子串,先对第2关键字排序(后面的长度为2的子串),再对第一关键字(前面的长度为2的子串)排序,所以这里的基数排序利用了上一次排序的结果,每次只需要进行两趟基数排序,即使时长度为4的字符串也只要2趟
到此为止,后缀数组求解结束
4. 最长公共前缀LCP求解
两个字符串长度最大的公共前缀,比如s1=abcxd”= s2=abcdef 则s1和s2的LCP是”abc“, 长度为3
对于sa[i], 它表示排名为i的后缀的开始下标,以s =“aabaaaab”为例,sa[3]=5, suffic(sa[3])=aab, 表示从第5个字符开始的后缀
定义一个数组height, height[i]表示排名第i个后缀和排名第i-1的后缀之间的LCP长度

如何求出height[i]? 最简单的一种方法是找到排名为i-1的后缀的开始下标j, 排名为i的后缀的开始下标为i, 然后往后比较字符是否相等,不能则结束,下一次计算时又从开始下标i和j开始比较,这样两两比较的实际复杂度为 O ( n 2 ) O(n^2) O(n2)
如何降低复杂度?
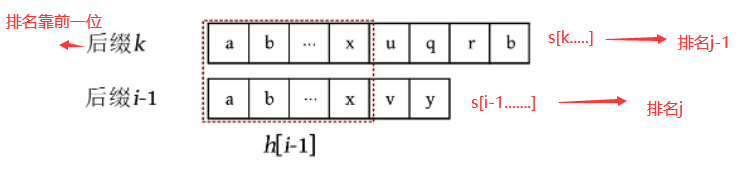
定义一个数组h, h[i]表示从下标i开始的字符串与其前一个排名的字符串的的LCP长度,则有以下关系
h [ i ] ≥ h [ i − 1 ] − 1 h[i]\ge h[i-1]-1 h[i]≥h[i−1]−1
简单证明:
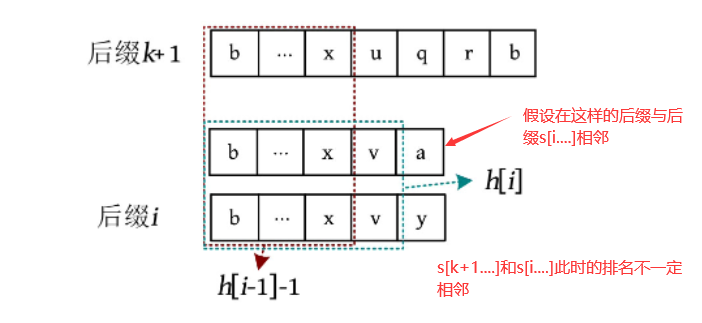
如第2张图所示,去掉了第一个字母后,h[i]的长度可能比h[i-1]-1的长度长,也可能相等(中间不存在其他后缀),所以h[i]的长度大于等于h[i-1]-1, ok, 利用这个性质来简化复杂度,代码如下所示:
public static int[] calHeight(int[] sa,String s) {
int n=sa.length;
//s=" "+s;
int[] rank=new int[n];
int[] heights=new int[n];
for(int i=0;i<n;i++)
rank[sa[i]]=i;//构建rank排名数组
System.out.println("rank: "+Arrays.toString(rank));
int j=-1,k=0;
for(int i=0;i<n-1;i++) {
if(k>0)
k--;
j=sa[rank[i]-1];//j是排名i-1的后缀的开始位置
while(i+k<n-1&&j+k<n-1&&s.charAt(i+k)==s.charAt(j+k))
k++;
heights[rank[i]]=k;
}
System.out.println("heights: "+Arrays.toString(heights));
return heights;
}
代码中第一次处理以s[0]开始的后缀,假设以s[0]开始的后缀排名为i, 找到排名为i-1的后缀的开始位置j, 然后进行比较,直到不相等,第一次k=0; 当第二次进入循环时,i=1, 即处理以以s[1]开始的后缀, 根据前面的关系,
h
[
1
]
≥
h
[
1
−
1
]
−
1
=
h
[
0
]
−
1
h[1]\ge h[1-1]-1=h[0]-1
h[1]≥h[1−1]−1=h[0]−1
所以处理以s[1]开始的后缀的后缀时,不需要从头开始比较,因为前k个字符一定相等,因此比较第i+k个字符即可,注意这里k需要减一,因为k=h[i-1],而h[i]>=h[i-1]-1
代码中注意点:
数组的长度是n, 这里的n比字符串的长度多1,即字符串的长度是n-1
到此为止,height数组求解完毕
给出任意两个后缀,如果求出这两个后缀的LCP?
性质:
对于任意两个后缀suffix(i )、suffix(j ),若rank[i ]<rank[j ],则它们的最长公共前缀长度为height[rank[i ]+1], height[rank[i ]+2], …, height[rank[j ]]的最小值。
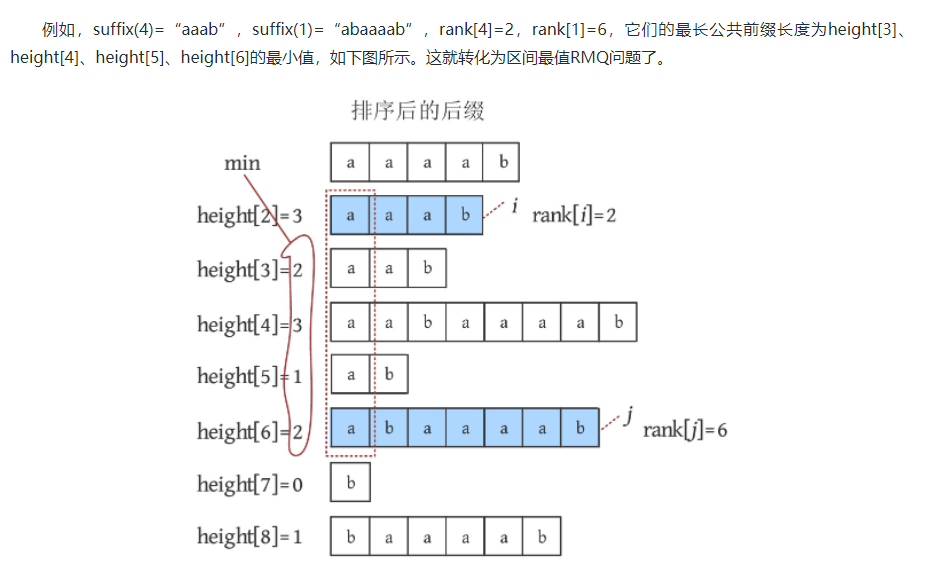
5. 后缀数组应用
最长重复子串

该问题等价于求解height数组的最大值,因为对于任意两个后缀而言,其排名越靠近,它们的公共前缀越长,height数组保存的就是两个相邻排名的后缀的LCP长度,如果同时是两个后缀的LCP,说明该子串重复了
class Solution {
public String longestDupSubstring(String s) {
int[] sa=calSuffixArray(s);//计算后缀数组
int[] height=calHeight(sa,s);//计算height数组
int max=-1,index=-1;
for(int i=1;i<height.length;i++){
if(height[i]>max){
//height[i]表示排名第i的后缀的与排名第i-1的后缀的LCP长度
max=height[i];//寻找后缀的最长LCP和对应的开始下标
index=sa[i];//sa[i]表示排名第i的后缀的开始下标
}
}
return s.substring(index,index+max);
}
public int[] calSuffixArray(String s) {
int n=s.length()+1;//字符串长度
int m=27;//基数
int[] x=new int[n];//x数组存储字符串转化后的数字 多一个位置防止比较时越界,在末尾用0封装
int[] ss=new int[n];
for(int i=0;i<n-1;i++) {
x[i]=s.charAt(i)-'a'+1;
}
x[n-1]=0;
int[] cnt=new int[m];//计数数组---桶
int[] sa=new int[n];//后缀数组
for(int i=0;i<n;i++) {
cnt[x[i]]++;//记录每个数字出现的次数
}
for(int i=1;i<m;i++) {
cnt[i]+=cnt[i-1];//累加次数
}
for(int i=n-1;i>=0;i--) {
sa[--cnt[x[i]]]=i;
}
int[] y=new int[n];
for(int k=1;k<=n;k<<=1) {
int p=0;
for(int i=n-k;i<n;i++) {
y[p++]=i;
}
for(int i=0;i<n;i++) {
if(sa[i]>=k) {
y[p++]=sa[i]-k;
}
}
//将第2关键字的排序结果转化为排名 正好是第一关键字
int[] wv=new int[n];
for(int i=0;i<n;i++) {
wv[i]=x[y[i]];
}
//对第一关键字进行计数排序 得到新的sa数组
cnt=new int[m];
for(int i=0;i<n;i++)
cnt[wv[i]]++;//计数
for(int i=1;i<m;i++)
cnt[i]+=cnt[i-1];//计数累加
for(int i=n-1;i>=0;i--)
sa[--cnt[wv[i]]]=y[i];
int[] tmp=x;
x=y;
y=tmp;
p=1;
x[sa[0]]=0;
for(int i=1;i<n;i++) {
x[sa[i]]=(y[sa[i-1]]==y[sa[i]]&&y[sa[i-1]+k]==y[sa[i]+k])?p-1:p++;
}
m=p;
}
return sa;
}
public int[] calHeight(int[] sa,String s) {
int n=sa.length;
//s=" "+s;
int[] rank=new int[n];
int[] heights=new int[n];
for(int i=0;i<n;i++)
rank[sa[i]]=i;//构建rank排名数组
int j=-1,k=0;
for(int i=0;i<n-1;i++) {
if(k>0)
k--;
j=sa[rank[i]-1];//j是排名i-1的后缀的开始位置
while(i+k<n-1&&j+k<n-1&&s.charAt(i+k)==s.charAt(j+k))
k++;
heights[rank[i]]=k;
}
return heights;
}
}
//O(nlogn)
//O(n)
图中图片来源以及参考:《算法训练营:进阶篇》
















 125
125











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











