







 本文介绍了信息论中的核心概念——熵与相对熵。熵用于衡量系统的不确定性,其值越大,系统的混乱程度越高;相对熵(KL散度)则用于度量两个概率分布之间的差异。文章详细解释了熵与相对熵的计算方法,并通过直观的例子帮助读者理解这两个概念。
本文介绍了信息论中的核心概念——熵与相对熵。熵用于衡量系统的不确定性,其值越大,系统的混乱程度越高;相对熵(KL散度)则用于度量两个概率分布之间的差异。文章详细解释了熵与相对熵的计算方法,并通过直观的例子帮助读者理解这两个概念。
1、熵
熵在信息论中是表现一个系统的混乱程度,熵越大代表系统混乱程度越高。
熵的单位是比特,所以在使用log的时候是以2位底的,举例:
当向计算机输入一个16位数据的时候,计算机本身可以取的值是2的16次方个 ,在输入之后这个值就确定下来了,那么现在就是从原来的1/2^16变成了1,那么这个的信息量就是16比特。
在了解熵之前先要了解信息量,信息量是用来描述一个事件从原来的不确定变为确定,难度有多大。信息量越大,说明难度就越高。
熵的评定和信息量相似,不同的是信息量针对的是一个事件,而熵针对的是一个系统。
关于熵公式的推导可以参考文末视频链接15:35开始。
信息量的计算:
信息量采用log表示,使用log其实本身是没有具体意义的,因为整个的推导都是通过定义开始的,定义本身是可以没有意义的,他的意义是在定义之后才被赋予的,关键在于在定义之后整体体系是否可以完成自洽。
熵的公式:
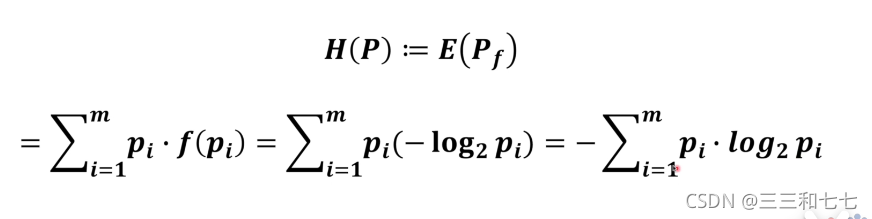
把系统中所有事件的信息量求出来再和对应事件的概率相乘得到的就是熵。
2、相对熵
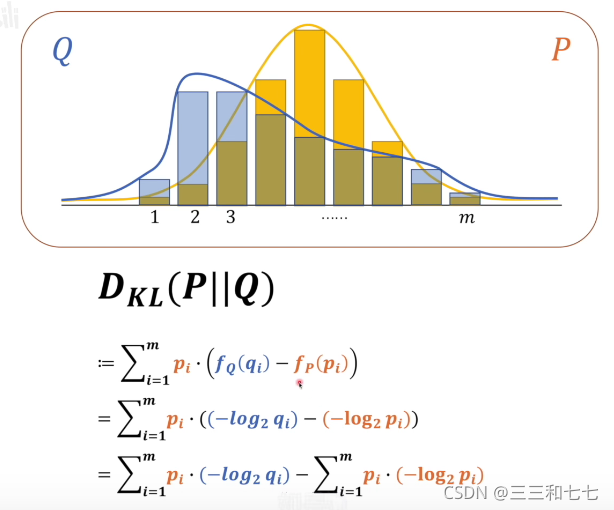
:图片引自B站视频,文末会附带链接。
相对熵又称KL散度,上图中的Q和P分别代表两个系统,fQ(qi)代表Q系统某一事件的信息量,fP(pi)代表P系统对应事件的信息量。(P||Q)代表以P为基准,考虑Q与P之间相差多少,
公式解释如下:
- DKL公式第二行:对于某一个事件,在Q系统中的信息量与对应在P系统中的信息量做差值,最后再做整体的期望(即求整体的平均值)
直观理解:如果Q想要达到和P一样的信息量的话,他们之前还差多少信息量 - DKL公式第四行(最后一行):
∑pi*(-log2pi)是代表P系统的信息熵,因为是以P系统为基准的,所以此值是恒定的。前面的∑pi*(-log2qi)也就是P的交叉熵H(P,Q)。因为后面的值是不变的,所以DKL的结果由前面P的交叉熵H(P,Q)决定。
当然在DKL=0的时候,Q和P之间是最接近的,无论是交叉熵H(P,Q)还是后面恒定的信息熵都是一个大于0的数。
根据吉布斯不等式可以获知,DKL的值永远大于等于0.这个定义也就规定了无论如何调整交叉熵一定比后面的信息熵大。所以交叉熵越小,那么两个概率模型就越相近。
参考视频:“交叉熵”如何做损失函数?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









