








1 树与二叉树
1.1树的概念
没有结点的数成为空树
树只有根节点时,根也是叶子
1.1.1树的技巧
1.完全二叉树 CBT的性质:
- 判断叶子? id * 2 > n
- 判断空节点? id > n
- 下标从 1 开始,根为 i i i ,左孩子为 2 ∗ i 2*i 2∗i => 用静态链表存储,下标就反映了结构关系
- 完全二叉树 CBT 结构固定,一旦节点数目确定,树的结构就确定了。
2.判断根节点:
不是任何节点的孩子,在输入时加数组统计即可。
3.输出时,最后一个节点后没有空格:
在遍历时添加一个计数器,当小于节点数时输出空格。
1.1.2 树的结构
一、动态二叉树
struct node{
int data;
node* lchild;
node* rchild;
[int layer;]
}
二、静态链表(数组)
一般是题目给出了树的节点编号,那可以直接用数组下标来映射编号,
−
1
-1
−1 代表
N
U
L
L
NULL
NULL.
node nodes[MAXN];
2 二叉树的遍历
2.0 二叉树的考点
二叉树的的两大考点:
1 遍历:
- 先序、中序、后序遍历: DFS
- 层序遍历: BFS
2 创建:
- 根据先序、中序序列建树
- 根据输入描述建树
树节点的结构:
struct node{
int data;
node* lchild;
node* rchild;
[int layer;]
}
2.1 遍历
2.1.1 前中后序遍历 : DFS
先序遍历:自顶向下,先执行,再深入
void preOrder(node* root){
// 出口
if(root == NULL) return;
// 递归式
printf("%d\n",root->data);
preOrder(root->left);
preOrder(root->right);
}
后序遍历:自底向上,先深入到底,向上返回是执行
void postOrder(node* root){
// 出口
if(root == NULL) return;
// 递归式
postOrder(root->left);
postOrder(root->right);
printf("%d\n",root->data);
}
2.1.2 层序遍历: BFS
节点带有层号
void LayerOrder(node* root){
// 创建队列
queue<node*> qu;
//初始节点入队
root->layer = 1;
qu.push(root);
// 队不空时循环
while(!qu.empty()){
// 出队一个元素
node* = qu.front();
qu.pop();
// 对其进行操作
printf("%d\n",top->data);
//所有可走点入队
if(top->lchild != NULL) {
lchild->layer = now->layer + 1;
qu.push(top->lchild);
}
if(top->rchild != NULL) {
rchild->layer = now->layer + 1;
qu.push(top->rchild);
}
}
}
2.2 建树
2.2.1 根据 前序、中序序列建树
思想:根据前序序列,在中序中找到 根节点 的位置,创建根节点,然后划分左右区间,向下递归,用 “递归区间” 作为终点判断条件。
核心:每一次递归只建立了一个根节点。
代码:
node* createTree(int Pre[],int In[],int preL,int preR,int inL,int inR){
// 递归终点
if(preL > preR) return NULL;
// 找到根节点的位置
int k;
for(k = inL;k <= inR;++k){
if(In[k] == Pre[preL]) break;
}
// 为了方便计算左右区间的边界,添加一个计数的变量
int numLeft = k - inL; // 左区间的元素个数
// 创建根节点
node* root = new node;
root->data = Pre[preL];
// 递归建立左右子树
root->lchild = createTree(Pre,In,preL+1,preL+numLeft,inL,k-1);
root->rchild = createTree(Pre,In,preL+numLeft+1,preR,k+1,inR);
return root;
}
典例: A1119-根据 前序、后序序列建树
题目大意:给出树的节点数,以及前序、后序遍历序列。若树唯一,输出“Yes”,以及中序遍历序列;否则输出“No”,以及任意一个中序遍历序列。
分析:
- 首先回顾 前、中序建树的过程:前序根节点确定,中序不确定,根据前序确定根节点,在中序中找到根,切分左右子树,递归。
- 在看 前、后序建树,前序、后序根节点都确定了,且一个在最前,一个在最后,无法切分左右子树。但必须得想办法,切分。
为什么前序和后序序列无法确定唯一的二叉树?
前序根节点 preL 的后一个 preL+1,一定是根的孩子(不知左右);后序根节点 postR 的前一个 postR-1 ,一定是根的孩子(不知左右)。
- 当 p r e [ p r e L + 1 ] ! = p o s t [ p o s t R − 1 ] pre[preL+1] != post[postR-1] pre[preL+1]!=post[postR−1] 时, => 说明有两个孩子,并且可区分左右,在后序中找到左孩子的根,即可划分出左右子树来。
- p r e [ p r e L + 1 ] = = p o s t [ p o s t R − 1 ] pre[preL+1] == post[postR-1] pre[preL+1]==post[postR−1]时,说明只有一个孩子,但无法确定是左/右孩子,故不唯一!!
由题意可知,当不唯一时,默认将其视为右孩子,建树,中序遍历。
注意点:
- 结束条件。尤其是只有一个元素的区间,需要特判。在前中序建树中,是通过 preL > preR 来结束的。但是在本题中,多加了判断条件 p r e [ p r e L + 1 ] ! = p o s t [ p o s t R − 1 ] pre[preL+1] != post[postR-1] pre[preL+1]!=post[postR−1] ,当区间长度为 1 时,超过了范围。
- 输出格式,最后要输出一个换行才算正确。不知为何,总之养成最后输出空行的习惯吧。
代码:
#include<cstdio>
#include<algorithm>
#define MAXN 50
using namespace std;
int n;
int pre[MAXN];
int post[MAXN];
struct node {
int data;
node* lchild;
node* rchild;
};
bool flag = true;
node* createTree(int preL,int preR,int postL,int postR) {
if(preL > preR) return NULL;
// 建立根节点
node* root = new node;
root->data = pre[preL] ;
// 区间长度为 1 时的特判
if(preL == preR) {
root->lchild = root->rchild = NULL;
return root;
}
//判断是否有两个孩子
if(pre[preL+1] != post[postR-1]) {
// 两个孩子
// 在后序序列中找左子树的根节点,切分左右子树
int k = postL;
while(k < postR && post[k] != pre[preL+1]) k++;
int numLeft = k - postL + 1; // 左子树的结点个数
root->lchild = createTree(preL+1,preL+numLeft,postL,k) ;
root->rchild = createTree(preL+numLeft+1,preR,k+1,postR-1);
} else {
// 一个孩子
flag = false;
// 默认当为右孩子来创建
root->lchild = NULL;
root->rchild = createTree(preL+1,preR,postL,postR-1);
}
}
int cnt;
void InOrder(node* root) {
if(root==NULL) return ;
InOrder(root->lchild);
printf("%d",root->data);
++cnt;
if(cnt < n) printf(" ");
else printf("\n");
InOrder(root->rchild);
}
int main() {
// printf("%d",flag);
scanf("%d",&n) ;
for(int i = 0; i < n; ++i) {
scanf("%d",&pre[i]);
}
for(int i = 0; i < n; ++i) {
scanf("%d",&post[i]);
}
node* root = createTree(0,n-1,0,n-1);
if(flag)
printf("Yes\n");
else printf("No\n");
InOrder(root);
return 0;
}
2.2.2 通过描述建树
一般是 题目给出: 节点的编号,以及左右孩子的编号,可以直接用静态链表存储。
典例: A1102 Invert a binary tree
题目:输入 N 表示节点个个数;以下 N 行,第 i 行 包含 i 号结点的左右子树,空则为 ‘-’,建树并将树翻转,输出层序、中序遍历序列。
考点:
1.根据描述建树,
2.树的翻转
3.层序遍历
4.中序遍历
思路:
1.既然给出了编号,则直接用 静态链表。
2.树的翻转,可用 “自顶向下”:先翻转左右孩子,再向下递归;也可用 “自底向上”。
代码:
struct node{
int data;
int lchild,rchild;
}nodes[MAXN];
树的翻转
自顶向下的先序
void invertTree(int root){
// 终点
if(root == -1) return;
swap(nodes[root].lchild,nodes[root].rchild);
invertTree(nodes[root].lchild);
invertTree(nodes[root].rchild);
}
自底向上的后序
void postOrder(int root){
// 终点
if(root == -1) return;
postOrder(nodes[root].lchild);
postOrder(nodes[root].rchild);
swap(nodes[root].lchild,nodes[root].rchild);
}
int n;
int main(){
scanf("%d",&n);
for(int i = 0;i < n;++i){
.....
}
3 普通树的遍历
3.0 普通树的考点
重点:普通树区别在于,用 vector 保存所有孩子节点,需要用遍历访问。
考点:
- 找某条路径(DFS)
- 遍历(BFS/DFS)
遍历又分:
- 先序遍历(DFS,由于有多个节点,所以只能先序,没有中序)
- 层序遍历(BFS)
遍历的话,可以优先考虑 BFS,不会爆栈。
补充:
- 一般都是给出 0 − > N − 1 ( 1 − > N ) 0->N-1(1->N) 0−>N−1(1−>N) 的编号,那么就用静态链表。注意也有例外。
3.1 普通树的定义
struct node{
int data;
vector<int> child;
}nodes[MAXN];
3.2 先序遍历 DFS
代码:
void PreOrder(int root){
// 1.终点
叶节点就是终点:没有孩子 vector.size() == 0
其实进不去 for 循环
// 2.操作
// 访问根节点
printf("%d",rnodes[root].data);
// 3.所有可走点 dfs
for(int i = 0;i < nodes[root].child.size();++i){
PreOrder(nodes[root].child[i]);
}
}
3.3 层序遍历 BFS
技巧:BFS 时对节点的操作,一般在 取队首元素时进行,此时只有一个节点,逻辑清晰。
而修改
i
n
q
inq
inq 数组,则在入队时就要修改
代码:
void LayerOrder(int root){
// 创建队列
queue<int> qu;
// 初始节点入队
qu.push(root);
// 队不空时循环
while(!qu.empty()){
// 出队一个元素
int now = qu.front();
qu.pop();
pop 后进行操作,不重不漏
// 操作
printf("%d",nodes[now].data);
// 所有可走点 入队
for(int i = 0;i < nodes[now].child.size();++i){
qu.push(nodes[now].child[i]);
}
}
}
典例:A1053-DFS找路径(题型一)
求一条从根到叶子的路径,其上的权值和为 S。
输入: N 节点个数,M 个描述,S 目标值。
M 行:节点编号,孩子个数,孩子编号
输出:所有满足条件的路径(输出节点权值)
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
struct node{
int data;
vector<int> child;
}nodes[110];
int n,m,s,id;
bool cmp(int a,int b){
return nodes[a].data > nodes[b].data;
}
vector<int> path;
void dfs(int root,int sum){
// 终点
if(sum == s && nodes[root].child.size() == 0){
path.push_back(nodes[root].data);
for(int i = 0;i < path.size();++i){
printf("%d",path[i]);
if(i < path.size()-1) printf(" ");
}
printf("\n");
path.pop_back();
return ;
}
// 剪枝
if(sum > s) return;
//操作:加入路径
path.push_back(nodes[root].data) ;
// 所有可走点 dfs
for(int i = 0;i < nodes[root].child.size();++i){
dfs(nodes[root].child[i],sum+nodes[nodes[root].child[i]].data);
}
// 恢复环境
path.pop_back();
}
int main(){
scanf("%d%d%d",&n,&m,&s);
for(int i = 0;i < n;++i){
scanf("%d",&nodes[i].data);
}
int num,tmp;
for(int i = 0;i < m;++i){
scanf("%d%d",&id,&num);
for(int j = 0;j < num;++j){
scanf("%d",&tmp);
nodes[id].child.push_back(tmp);
}
sort(nodes[id].child.begin(),nodes[id].child.end(),cmp);
}
dfs(0,nodes[0].data);
return 0;
}
典例:A1004-BFS遍历树(题型二)
题目:求每一层叶子节点个数
输入:N,M :节点数,非叶子节点数
M 行: ID k Id1 … idk
代码:
#include<cstdio>
#include<algorithm>
#include<vector>
#include<queue>
using namespace std;
int n,m;
vector<int> nodes[110];
vector<int> ans;
void bfs(int root){
// 创建队列
queue<int> qu;
// 初始节点入队
qu.push(root) ;
while(!qu.empty()){
int cnt = 0;
int top;
// 一次出队一层的元素
int s = qu.size();
for(int i = 0;i < s ;++i){
top = qu.front();
qu.pop();
if(nodes[top].size() == 0) ++cnt;
else{
for(int j = 0;j < nodes[top].size();++j)
qu.push(nodes[top][j]);
}
}
ans.push_back(cnt);
}
}
int id,k,t;
int main(){
scanf("%d%d",&n,&m);
for(int i = 0;i < m;++i){
scanf("%d%d",&id,&k);
for(int j = 0;j < k;++j){
scanf("%d",&t);
nodes[id].push_back(t);
}
}
bfs(1);
for(int i = 0;i < ans.size();++i){
printf("%d",ans[i]);
if(i < ans.size()-1) printf(" ");
}
return 0;
}
4 BST 二叉查找树
4.1 BST 的考点
基本性质:左子树都小于根,右子树都大于根。
重要性质:BST 的中序遍历序列是递增有序的。
题型:
BST的创建:
- 根据描述逐个插入建立BST,遍历(基本性质)
- 在中序遍历时填入有序序列建立BST(重要性质)
4.2 BST 的查找和插入
查找代码:
void search(node* root,int x){
// 终点
if(root == NULL) return ;
if(root->data == x) {
printf("ok");
...
return ;
}
if(root->data > x) search(root->lchild,x);
else search(root->rchild,x);
}
插入代码:
void insert(node* root,int x){
// 终点
在查找失败处插入即可
if(root == NULL){
root = new node;
root->data = x;
root->lchild = root->rchild;
}
else if(root->data > x) insert(root->lchild,x);
else insert(root->rchild,x);
}
4.3 BST 的删除
核心思想:保证删除该节点后,仍是 BST。
=> 通过不断替换,将待删节点换到叶子节点处,删除叶子节点
PS:删除过程首先要先查找啊
代码:用前趋替代。
struct node{
int data;
int lchild,rchild;
}nodes[MAXN];
寻找前驱节点
node* findMax(node* root){
while(root->rchild != NULL) root = root->rchld;
return root;
}
寻找后继节点
node* findMin(node* root){
while(root->lchild != NULL) root = root->lchld;
return root;
}
void deleteNode(node*& root,int x){
// 找到待删除结点
if(root->data == x){
// 叶子节点,则直接删除
if(root->lchild == NULL && root->rchild == NULL){
root = NULL;
// 左孩子不空,用前趋替代
}else if(root->lchild != NULL){
// 找到前趋
node* pre = findMax(root->left);
// 前趋换到根节点
root->data = pre->data;
// 删除该前趋
注意!!!参数是 root->lchild! 不是 pre ,否则只删了叶节点,并不满足 BST 了
deleteNode(root->lchild,pre->data);
}
else{
// 找到后继
node* next= findMax(root->right);
// 后继换到根节点
root->data = next->data;
// 删除该后继
deleteNode(root->rchild,next->data);
}
}
// 进行查找
else if(root->data > x) deleteNode(root->lchild,x);
else deleteNode(root->rchild,x);
}
PS leetcode 版本:不能对传入的参数指针本身修改,只能修改节点的域。
TreeNode* deleteNode(TreeNode* root, int key) {
if(root ==nullptr) return nullptr;
if( root->val > key) {
root->left = deleteNode(root->left,key);
}else if(root->val < key) {
root->right = deleteNode(root->right,key);
}else {
if(root->left == nullptr) return root->right;
if(root->right == nullptr) return root->left;
TreeNode* cur = root->right;
while(cur->left != nullptr) cur = cur->left;
cur->left = root->left;
root = root->right;
}
return root;
典例:A1043-根据描述建立 BST(题型一)
题目:给出一个序列,判断是否是 BST,或镜像 BST 的先序遍历序列。
输出:是则输出 YES 和后序序列,不是则输出 NO。
思路:一颗 BST ,按照其先序遍历序列插入建树,会得到一样的 BST。而按照中序和后序不行。
则按照该序列插入,再判断建的树的先序遍历序列是否相等即可。
两种方法:
1.建立 BST,判断,翻转,在判断;
2.建立 BST,调整 preOrder 左右子树的访问顺序,即可得到镜像树的访问序列,而不用翻转树。这样需要两套访问函数。
代码:
#include<cstdio>
#include<vector>
#define MAXN 1010
using namespace std;
int n;
struct node {
int data;
node* lchild;
node* rchild;
};
void insert(node*& root,int x) {
if(root == NULL) {
root = new node;
root->data = x;
root->lchild = root->rchild = NULL;
return ;
}
if(root->data > x) {
insert(root->lchild,x);
} else insert(root->rchild,x);
}
vector<int> path;
vector<int> path2;
// 先序遍历
void preOrder(node* root) {
if(root == NULL) return ;
path2.push_back(root->data);
preOrder(root->lchild);
preOrder(root->rchild);
}
void preOrder2(node* root) {
if(root == NULL) return ;
path2.push_back(root->data);
preOrder2(root->rchild);
preOrder2(root->lchild);
}
int cnt;
void postOrder(node* root) {
if(root == NULL) return;
postOrder(root->lchild);
postOrder(root->rchild);
printf("%d",root->data);
++cnt;
if(cnt < n) printf(" ");
}
void postOrder2(node* root) {
if(root == NULL) return;
postOrder2(root->rchild);
postOrder2(root->lchild);
printf("%d",root->data);
++cnt;
if(cnt < n) printf(" ");
}
int t;
int main() {
node* root = NULL;
scanf("%d",&n);
for(int i = 0; i < n; ++i) {
scanf("%d",&t);
path.push_back(t);
insert(root,t);
}
preOrder(root);
if(path2 == path) {
printf("YES\n");
postOrder(root) ;
return 0;
}
path2.clear();
preOrder2(root);
if(path2 == path) {
printf("YES\n");
postOrder2(root) ;
return 0;
}
printf("NO");
return 0;
}
典例:A1064-根据 BST 的重要性质创建 (题型二)
题目:给出一个序列,将其建立为 完全二叉树 形式的 BST,输出层序遍历序列。
分析:
完全二叉树的性质:
- 下标从 1 开始,根为 i i i ,左孩子为 2 ∗ i 2*i 2∗i => 用静态链表存储,下标就反映了结构关系
- 完全二叉树 CBT 结构固定,一旦节点数目确定,树的结构就确定了。
BST 的性质:
- 基本性质:左孩子小于根,右孩子大于根。
- 重要性质:中序遍历序列递增有序
思路:
- 用静态链表存储 BST,用 下标映射关系 表示 CBT,就不用保存 孩子指针了。
- 直接在确定的 二叉树 中(结构确定,只是还没填入值),在中序遍历过程中,将排序后的序列填入即可。
根据样例,画出预期的 CBT 、BST :
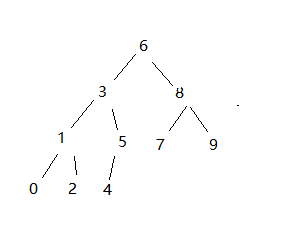
总结:本题用到的性质
- CBT 的结点个数确定,则结构确定
- BST 的中序序列递增有序,则在中序遍历时填入有序序列,构建 BST。
代码:
#include<cstdio>
#include<algorithm>
#include<queue>
using namespace std;
int n;
int a[1010];
struct node{
int data;
int lchild,rchild;
}nodes[1010];
int k;
void InOrder(int root){
// 终点: 空节点
if(root > n){
// printf("over!\n") ;
return ;
}
InOrder(root*2);
nodes[root].data = a[k++];
// printf("now :%d k : %d\n",nodes[root].data,k-1);
InOrder(root*2+1);
}
int cnt;
void LayerOrder(int root){
queue<int> qu;
qu.push(root);
while(!qu.empty()){
int top = qu.front();
qu.pop();
printf("%d",nodes[top].data);
if(cnt++ < n-1) printf(" ");
if(top*2 <= n)
qu.push(top*2);
if(top*2+1 <= n)
qu.push(top*2+1);
}
}
void preOrder(int root){
if(root >n ) return;
printf("%d ",nodes[root].data );
preOrder(root*2);
preOrder(root*2+1);
}
int main(){
k = 1;
scanf("%d",&n);
for(int i = 1;i <= n;++i){
scanf("%d",&a[i]);
}
sort(a+1,a+1+n);
InOrder(1);
// printf("建树ok");
// preOrder(1);
LayerOrder(1);
return 0;
}
5 AVL 树
5.1 AVL 树的考点
考点: AVL 树也是 BST,只是在 插入过程加入了 “调整” 操作。
调整过程总结:
Ⅰ. 为了判断失衡,引入 平衡因子(左子树高度 - 右子树高度)=> 树节点结构中添加 height 字段 : 结构变化(插入、!旋转!)时需要维护。
Ⅱ.失衡节点( 2/-2 )只会出现在根节点到插入节点的路径上,故在左子树插入只用考虑 L 型,右子树插入只考虑 R 型。
Ⅲ.调整方法总结:
- LL型:以 根节点 为根,右旋。
- LR型:以 根节点的右孩子 为根,左旋 为 LL;再以 根节点 为根, 右旋。
- RR型:以 根节点 为根,左旋。
- RL型:以 根节点的左孩子 为根,右旋为 RR;再以 根节点 为根,左旋。
核心:每次在对子树插入节点(调用递归插入函数)后,更新根节点高度;而空节点插入时则不用,因为一个节点不会失衡。
那么,更新函数将从插入点的父节点开始,向上一路更新高度并调整。
PS: 平衡因子为 正,则左边高啊,L 表示左边高,反之亦然。
涉及到:
1.添加
h
e
i
g
h
t
height
height 字段,并时刻维护。
2.判断失衡?
3.左旋、右旋。
右旋示意图:

模板,例题:A1066
#include<cstdio>
#include<algorithm>
#include<vector>
#include<queue>
#define MAXN 10010
using namespace std;
struct node {
int data;
node* lchild;
node* rchild;
int height;
} nodes[MAXN];
辅助函数:
// 初始化时参数较多,单独写一个 new 函数
node* newNode(int x) {
node* root = new node;
root->data = x;
root->lchild = root->rchild = NULL;
root->height = 1;
return root;
}
int getHeight(node* root) {
if(root == NULL) return 0;
return root->height;
}
void updateHeight(node* root) {
root->height = max(getHeight(root->lchild),getHeight(root->rchild)) + 1;
}
int getBalanceFactor(node* root) {
return getHeight(root->lchild) - getHeight(root->rchild);
}
void R(node*& root) {
node* tmp = root->lchild;
root->lchild = tmp->rchild;
tmp->rchild = root;
!!!!! 注意结构改变后,要更新高度!!!!
updateHeight(root);
updateHeight(tmp);
!!!!!!!!!
root = tmp;
}
void L(node*& root) {
node* tmp = root->rchild;
root->rchild = tmp->lchild;
tmp->lchild = root;
updateHeight(root);
updateHeight(tmp);
root = tmp;
}
插入 + 调整:
void insert(node*& root,int x) {
if(root == NULL) {
root = newNode(x);
return;
}
if(root->data > x) {
// 左子树中插入
insert(root->lchild,x);
// 更新树高
updateHeight(root);
// 左子树中,则只用考虑 L 型
if(getBalanceFactor(root) == 2) {
// LL
if(getBalanceFactor(root->lchild) == 1) {
R(root);
} else if(getBalanceFactor(root->lchild) == -1) {
L(root->lchild);
R(root);
}
}
}
// 右子树中
else {
insert(root->rchild,x);
updateHeight(root);
// 同理,只用考虑 R 型
if(getBalanceFactor(root) == -2) {
if(getBalanceFactor(root->rchild) == -1) {
L(root);
} else if(getBalanceFactor(root->rchild) == 1) {
R(root->rchild);
L(root);
}
}
}
}
int n,t;
int main(){
node* root = NULL;
scanf("%d",&n);
while(n--){
scanf("%d",&t);
insert(root,t);
}
printf("%d",root->data);
return 0;
}
6 并查集
6.1 并查集的考点
并查集的考点操作:
- 辅助数组 father[i], 表示 i 所在连通域的 根节点。
- 初始化,读入数据时,将节点的 father 都设为自身。
- 查询:从该节点开始,参照 father 数组,一路向上找到根节点。然后再走一遍,将路径上的结点的父节点都设为 “根” ,压缩路径。
- 合并:判断两节点是否属于同一连通域,然后修改其一 father 域。
注意: 合并的语法是 father[fa]=fb。是对 fa ,fb 两个根节点操作,为什么不能是 father[a] 呢,因为这是可能还没有执行路径压缩操作! - 统计连通域的个数:开一个 isRoot 数组,是根设为1 否则设为 0,统计 为 1 的个数;或统计
i
=
f
a
t
h
e
r
[
i
]
i = father[i]
i=father[i] 的个数。
(所以并查集也用在 “图” 中统计连通域)
代码模板:
int father[MAXN];
// 初始化
for(int i = 0;i < n;++i){
scanf("%d",&t);
father[t] = t;
}
// 查询
int findFather(int x){
int a = x;
// 找到根节点
while(x != father[x]) x = father[x];
// 此时 x 为根
//路径压缩
while(a != x){
int z = a;
a = father[a];
father[z] = x;
}
不要忘了返回!!!
return x;
}
// 合并
void Union(int a,int b){
int fa = findFather(a);
int fb = findFather(b);
if(fa != fb) father[fa] = fb;
}
典例: A1107 Social Clusters - 并查集的操作
题目:给出每个人的爱好,若两人有至少一个爱好相同,则属于同一个 cluster。
输出 cluster 的个数,以及每个 cluster 中的个数,降序排列。
难点:多了一个判断关系的函数,之前都是直接给出关系。这里添加一个函数,遍历两人的爱好,只要有相同就返回 true。
错误点:刚输入的人,要与前面所有人进行判断合并,而不能找到一个就停止。
因为其可能作为桥梁,串联起很多人,如果遇到一个就停下,则只合并了两人而已。
#include<cstdio>
#include<algorithm>
#include<vector>
using namespace std;
// 记录每个人的爱好
vector<int> hobby[1010];
int father[1010];
int findFather(int x){
int a = x;
while(x != father[x]) x = father[x];
while(a != x){
int z = a;
a = father[a];
father[z] = x;
}
return x;
}
void Union(int a,int b){
int fa = findFather(a);
int fb = findFather(b);
if(fa != fb) father[fa] = fb;
}
bool cmp(int a,int b){
return a > b;
}
// 判断两人是否有相同的爱好
bool haveRelation(int a,int b){
for(int i = 0;i < hobby[a].size();++i){
for(int j = 0;j < hobby[b].size();++j)
if(hobby[a][i] == hobby[b][j]) return true;
}
return false;
}
int isRoot[1010];
int n,k,t;
int main(){
scanf("%d",&n);
for(int i = 1;i <= n;++i) father[i] = i;
for(int i = 1;i <= n;++i){
scanf("%d:",&k);
while(k--){
scanf("%d",&t);
hobby[i].push_back(t);
}
for(int j = 1;j < i;++j){
if(haveRelation(i,j)){
// printf("%d & %d\n",i,j);
Union(i,j);
!!!! 错误! 要与前面所有人进行判断合并!!!
整个过程可能串联起多个 cluster,如果提前停止,则没有合并。
// break;
}
}
}
int cnt = 0;
for(int i = 1;i <= n;++i){
isRoot[findFather(i)]++; // 统计每个域中的节点数
if(father[i] == i) ++cnt; // 统计连通域的个数
}
sort(isRoot+1,isRoot+1+n,cmp);
printf("%d\n",cnt);
for(int i = 1;i <= cnt;++i){
printf("%d",isRoot[i]);
if(i < cnt) printf(" ");
}
return 0;
}
典例 * A1114 - 附带信息的并查集
题目大意:
给定每个⼈的家庭成员和其⾃⼰名下的房产,请你统计出每个家庭的⼈⼝数、⼈均房产⾯
积及房产套数。⾸先在第⼀⾏输出家庭个数(所有有亲属关系的⼈都属于同⼀个家庭)。随后按下列
格式输出每个家庭的信息:家庭成员的最⼩编号 家庭⼈⼝数 ⼈均房产套数 ⼈均房产⾯积。其中⼈均
值要求保留⼩数点后3位。家庭信息⾸先按⼈均⾯积降序输出,若有并列,则按成员编号的升序输出。
分析:并查集附带其他信息。如房产数、房产面积。
解决方案:
1.先建立网络拓扑关系;
2.将信息累加到根节点中。
教训:题目要求 -1 为空节点,那就不能用 > 0来判断,测试点4就是父母为 0000,卡了半天。
#include<cstdio>
#include<algorithm>
#include<vector>
#include<cmath>
#define MAXN 10000
using namespace std;
int father[MAXN]; // 父亲标记
int area[MAXN]; // 面积
int sets[MAXN]; // 套数
double avgArea[MAXN];
double avgSets[MAXN];
int num[MAXN] ; // 出现标记
bool has = {false}; // 有父亲标志
vector<int> vec; // 存放根
int n;
// 初始化
void init() {
for(int i = 0; i < MAXN; ++i) {
father[i] = i;
}
}
// 查找
int findFather(int x) {
int a = x;
while(x != father[x]) {
x = father[x];
}
while(a != x) {
int z = a;
a = father[a];
father[z] = x;
}
return x;
}
// 合并
void Union(int a,int b) {
int fa = findFather(a);
int fb = findFather(b);
if(fa != fb) {
if(fa > fb)
father[fa] = fb;
else father[fb] = fa;
}
}
bool cmp(int a,int b) {
double avgA = (double)(area[a]*1.0 / num[a]);
double avgB = (double)(area[b]*1.0 / num[b]);
if(avgA!=avgB) return avgA > avgB;
else return a < b;
}
int id,dad,mom,k,child;
int main() {
scanf("%d",&n);
init();
// 第一部分,先建立网络关系
for(int i = 0; i < n; ++i) {
scanf("%d%d%d%d",&id,&dad,&mom,&k);
num[id] = 1;
if(dad != -1) {
num[dad] = 1;
Union(dad,id);
}
if(mom != -1) {
num[mom] = 1;
Union(mom,id);
}
for(int j = 0; j < k; ++j) {
scanf("%d",&child);
num[child] = 1;
Union(child,id);
}
scanf("%d%d",&sets[id],&area[id]);
}
// 第二部分,将信息累加到根节点
int cnt = 0; // 统计连通域的个数
for(int i = 0; i < MAXN; ++i) {
// 出现过的合法节点
if(num[i] == 1) {
int fai = findFather(i);
// 统计家庭数
// 是根节点
if(fai == i) {
++cnt;
vec.push_back(i);
} else {
// 不是根节点
num[fai] += num[i];
sets[fai] += sets[i];
area[fai] += area[i];
}
}
}
sort(vec.begin(),vec.end(),cmp);
printf("%d\n",vec.size());
for(int i = 0; i < vec.size(); ++i) {
id = vec[i];
printf("%04d %d %.3lf %.3lf\n",id,num[id],(double)sets[id] / num[id],(double)area[id] / num[id]);
}
return 0;
}
7 堆
7.0 堆的考点
堆的实现形式:完全二叉树 CBT = > 静态链表
定义: 根节点 大于 孩子节点的 CBT
性质:
1.根节点大于孩子节点
2.CBT 的性质:
- 根为 i i i ,孩子为 2 ∗ i 2 * i 2∗i, 2 ∗ i + 1 2 * i+1 2∗i+1;
- 叶节点数为 ⌈ n 2 ⌉ \lceil \frac{n}{2}\rceil ⌈2n⌉,非叶子节点为 1 − ⌊ n 2 ⌋ 1-\lfloor \frac{n}{2}\rfloor 1−⌊2n⌋。
- 节点数目确定,则形状确定
考点:
- 建堆:按序填入,从最后往前逐个 downadjust
- 堆排序:建堆后,将根(最大值)与最后一个节点交换,迭代范围 -1,从根 downAdjust 恢复大根堆。重复至只剩一个节点
- 插入:在最后插入一个元素,然后 upAdjust
7.1 downAdjust 函数
核心思路:为了完成堆排序,需要维持 “大根堆” ,定义 downAdjust 函数完成 “1.将最大的值置于叶子节点”的交换过程,然后继续从交换点出发2.迭代至叶节点,保证一次调整后整棵树仍是大根堆。
从后往前(即从树的底部向上),依次以该节点为根,做 downAdjust ,这样保证了在对 i i i 节点判断时,其子树都已经是大根堆。假设根节点 i i i 需要与 2 ∗ i + 1 2*i+1 2∗i+1 交换,则交换后再从 2 ∗ i + 1 2*i+1 2∗i+1 出发向下迭代调整, 2 ∗ i 2*i 2∗i 的子树不需要动,因为已经是大根堆了。
downAdjust 向下调整 (维护大根堆)
若根小于孩子,则与孩子中的最大值交换,一直向下迭代至:1.没有孩子;2.比孩子都大.
步骤:
- while 循环迭代:i = low,j = 2*i 两个指针。
- 找到叶子中的最大值;判断、交换
- 若发生交换,更新指针,继续迭代;若未交换,结束。
void downAdjust(int low,int high){
// 定义两个指针用于迭代,i 为当前待调整的根, j 为孩子中最大节点
int i = low,j = 2 * i;
while(j < high){
//寻找孩子中的最大节点
if(j+1 <= high){
// 如果有右孩子
if(heap[j+1] > heap[j])
j = j + 1;
}
// 判断根与最大孩子的关系,是否需要交换
if(heap[i] < heap[j]){
swap(heap[i],heap[j]);
i = j;
j = 2 * i;
}else{
break;
}
}
}
7.2 建堆
过程;按序插入,从后往前逐个 downAdjust
代码:
// 按序插入
for(int i = 1;i <= n;++i){
heap[i] = a[i];
}
void createHeap(){
// 从后往前 逐个 downAdjust
从最后一个非叶子节点开始调整
for(int i = n/2;i >= 1;--i){
downAdjust(i,n);
}
}
7.3 堆排序
过程: 先建堆,然后将根节点与最后一个节点交换,迭代区间减一。
代码:
void heapSort(){
createHeap();
for(int i = n;i > 1;--i){
swap(heap[1],heap[i]);
downAdjust(1,i-1);
}
}
7.4 插入
步骤:在数组最后添加一个元素,然后向上调整。
因为已经是大根堆,只需与根节点比较,向上交换至不用换为止。
代码:
void insert(int x){
heap[++n] = x;
upAdjust(1,n);
}
void upAdjust(int low,int high){
int i = high,j = n/2;
while(j >= low){
if(heap[i] > heap[j]){
swap(heap[i],heap[j]);
i = j;
j = i / 2;
}else{
break;
}
}
}
典例: A1098 - 堆排序
题目: 给出原始序列和目标序列,判断是由插入排序得来的还是堆排序。
思路:涉及到插入排序和堆排序的中间结果,那肯定是要模拟两种排序。插入排序用sort代替,就做堆排序。
技巧:由于需要输出目标序列的下一次排序结果,则可以先判断,再做排序。这样先判断成功后,再做排序,就是目标的下一次。
代码:
#include<cstdio>
#include<algorithm>
#include<vector>
using namespace std;
int n;
int heap[120]; // 堆排序用
int src[120];
int dst[120];
int a[120]; // 插入排序用
bool check(int s[],int d[]) {
for(int i = 1; i<= n; ++i) {
if(s[i] != d[i]) return false;
}
return true;
}
void downAdjust(int low,int high) {
int i = low,j = 2 * i;
while(j <= high) {
// 找最大叶子
if(j+1 <=high) {
if(heap[j+1] > heap[j])
j = j + 1;
}
// 交换
if(heap[j] > heap[i]) {
swap(heap[i],heap[j]);
i = j;
j = 2*i;
}else break;
}
}
void createHeap(){
for(int i = n/2;i >= 1;--i){
downAdjust(i,n);
}
}
int main() {
scanf("%d",&n);
for(int i = 1; i <= n; ++i ) {
scanf("%d",&src[i]);
heap[i] = a[i] = src[i];
}
for(int i = 1; i <= n; ++i ) {
scanf("%d",&dst[i]);
}
// 先插入排序
for(int k = 2; k <= n; ++k) {
// 总共 n-1 次排序
int ok = 0;
if(check(a,dst) && k!=2) {
ok = 1;
}
sort(a+1,a+k+1);
if(ok) {
printf("Insertion Sort\n");
for(int i = 1; i <= n; ++i) {
printf("%d",a[i]);
if(i < n) printf(" ");
}
return 0;
}
}
// 否则,是堆排序
printf("Heap Sort\n") ;
createHeap(); // 建堆
// printf("建堆OK\n");
// k-1 次堆排序
for(int k = n;k > 1;--k) {
int ok = 0;
if(check(heap,dst)){
ok = 1;
}
swap(heap[k],heap[1]);
downAdjust(1,k-1);;
if(ok){
for(int i = 1; i <= n; ++i) {
printf("%d",heap[i]);
if(i < n) printf(" ");
}
}
}
return 0;
}















 1087
1087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









