






参考源:https://www.liwenzhou.com/posts/Go/go_menu/
仅用于自己学习记录 感谢大大们的文章🙇
变量和常量
通过下面的代码片段可以了解到GO语言的常量和变量声明方式和使用形式。
main.go
package main // 声明 main 包,表明当前是一个可执行程序
import "fmt" // 导入内置 fmt 包
/*
变量赋值学习
*/
var name string = "BakaRice"
var name1, name2 = "Rice", "Baka" //同时声明多个变量
var ( //略写var
age int = 18
l = 18 //直接判断类型
)
const ( //略写const 同时声明多个常量
pi = 3.1415
e = 2.7182
)
//const同时声明多个常量时,如果省略了值则表示和上面一行的值相同
const (
n1 = 100
n2
n3
)
func foo() (int, string) {
return 10, "Baka_Rice"
}
func main() { // main函数,是程序执行的入口
x, _ := foo() //使用匿名变量忽略某值,匿名变量不占用命名空间,不会分配内存
Glen := 19 //函数内部独有的命名方式
fmt.Println("x=", x)
fmt.Println(name, name1, age, l, Glen)
fmt.Println("Hello BakaRiceWorld!") // 在终端打印 Hello BakaRiceWorld!
}
iota
iota是go语言的常量计数器,只能在常量的表达式中使用。
iota在const关键字出现时将被重置为0。const中每新增一行(注意此处是一行)常量声明将使iota计数一次(iota可理解为const语句块中的行索引)。 使用iota能简化定义,在定义枚举时很有用。
举个例子:
const (
n1 = iota //0 声明iota后置为0
n2 //1 以下每个常量依次+1
n3 //2
n4 //3
)
const (
n1 = iota //0
n2 = 100 //100
n3 = iota //2 插队后要声明回来 不然之后的常量都将为100
n4 //3
)
const n5 = iota //0
定义数量级 (这里的<<表示左移操作,1<<10表示将1的二进制表示向左移10位,也就是由1变成了10000000000,也就是十进制的1024。同理2<<2表示将2的二进制表示向左移2位,也就是由10变成了1000,也就是十进制的8。)
const (
_ = iota
KB = 1 << (10 * iota)
MB = 1 << (10 * iota)
GB = 1 << (10 * iota)
TB = 1 << (10 * iota)
PB = 1 << (10 * iota)
)
const (
a, b = iota + 1, iota + 2 //1,2
c, d //2,3 此处延续上面的iota+1 ,iota+2 ,但此时的iota已经变成了1
e, f //3,4 因为iota是每新增一行就+1 不是新增一个变量就+1
)
fmt.Print(a,b,c,d,e,f)
const (
a, b, c, d = iota + 1, iota + 2, iota + 3, iota //1,2,3,0
e, f, g, h //2,3,4,1
)
fmt.Print(a, b, c, d, e, f,g,h)
基本数据类型
整型
整型分为以下两个大类: 按长度分为:int8、int16、int32、int64 对应的无符号整型:uint8、uint16、uint32、uint64
其中,uint8就是我们熟知的byte型,int16对应C语言中的short型,int64对应C语言中的long型。
| 类型 | 描述 |
|---|---|
| uint | 32位操作系统上就是uint32,64位操作系统上就是uint64 |
| int | 32位操作系统上就是int32,64位操作系统上就是int64 |
| uintptr | 无符号整型,用于存放一个指针 |
不同平台的int和uint受制于系统,在涉及到二进制传输、读写文件的结构描述时,为了保持文件的结构不会受到不同编译目标平台字节长度的影响,不要使用int和uint。
浮点型
package main
import (
"fmt"
"math"
)
func main() {
fmt.Printf("%f\n", math.Pi)
fmt.Printf("%.2f\n", math.Pi)
}
数字字面量语法
// 十进制
var a int = 10
fmt.Printf("%d \n", a) // 10
fmt.Printf("%b \n", a) // 1010 占位符%b表示二进制
// 八进制 以0开头
var b int = 077
fmt.Printf("%o \n", b) // 77
// 十六进制 以0x开头
var c int = 0xff
fmt.Printf("%x \n", c) // ff
fmt.Printf("%X \n", c) // FF
复数
var c1 complex64
c1 = 1 + 2i
var c2 complex128
c2 = 2 + 3i
fmt.Println(c1)
fmt.Println(c2)
布尔值
bool 类型进行声明布尔类型 只有 true和 false两个值
默认值为false,不允许整型强制转换bool,bool无法参加值运算
字符串
Go 语言里的字符串的内部实现使用UTF-8编码。 字符串的值为双引号(")中的内容,可以在Go语言的源码中直接添加非ASCII码字符,例如:
s1 := "hello"
s2 := "你好"
s1 := `第一行
第二行
第三行
`
fmt.Println(s1)
常用操作
//求长度
ms1Len := len(ms1)
fmt.Println(ms1Len)
//拼接字符串
fmt.Println(ms1+s1+s2)
//判断是否包含
fmt.Println(strings.Contains(ms1,s1))
//前后缀判断
strings.HasPrefix()
strings.HasSuffix()
//子串出现的位置
strings.Index()
strings.LastIndex()
//join操作
strings.Join()
byte和rune类型
组成每个字符串的元素叫做“字符”,可以通过遍历或者单个获取字符串元素获得字符。 字符用单引号(’)包裹起来,如:
var a := '中'
var b := 'x'
Go语言的字符有两种:
unit8类型,或者说是byte类型,代表ASCII码的一个字符rune类型,代表一个UTF-8z字符
当需要处理中文,日本或者其他复合字符时,则需要用到rune类型,rune类型实际上是一个int32
//遍历字符串
func traversalString(){
s:="BakaRiceのコード"
//因为UTF-8编码下的一个汉字或者日文是由3-4个字节组成
//所以不能简单的按照字节来遍历一个包含日文或者中文的字符串
//如果这么做会出现乱码
for i:=0;i<len(s);i++ {
fmt.Printf("%v(%c)", s[i], s[i])
}
fmt.Println()
for _, r := range s { //rune
fmt.Printf("%v(%c) ", r, r)
}
fmt.Println()
//66(B)97(a)107(k)97(a)82(R)105(i)99(c)101(e)227(ã)129()174(®)227(ã)130(‚)179(³)227(ã)131(ƒ)188(¼)227(ã)131(ƒ)137(‰)
//66(B) 97(a) 107(k) 97(a) 82(R) 105(i) 99(c) 101(e) 12398(の) 12467(コ) 12540(ー) 12489(ド)
}
字符串底层是一个byte数组,所以可以和[]byte类型相互转换,字符串是不能修改的,字符串是由byte字节组成,所以字符串的长度是byte字节的长度,rune类型用来表示utf-8字符,一个rune字符由一个或多个byte组成。
修改字符串
要修改字符串,需要先将其转换成[]rune和[]byte,完成后再转换为string。无论哪种转换,都会重新分配内存,并复制字节数组
java中的string也是不可变的,直接声明的string对象是被放在常量池里的,stringbuilder(非同步,快) 和 stringbuffer(线程安全,慢)才是
func changeString() {
s1 := "Rice"
byteS1 := []byte(s1)
byteS1[0] = 'p'
fmt.Println(string(byteS1))
s2 := "狗语言学习中"
runeS2 := []rune(s2)
runeS2[0] = '苟'
fmt.Println(string(runeS2))
}
类型转换
Go语言只有强制类型转换,没有隐式类型转换,该语法只能在两个类型之间支持相互转换的时候使用
Java则存在隐式转换
1 . 小的类型自动转化为大的类型 byte b = 125; int i = b;
2. 整型转为浮点
3. 字符可以自动提升为整数
强制类型转换的基本语法如下:
T(表达式)
例子:
func sqrtDemo() {
var a, b = 3, 4
var c int
// math.Sqrt()接收的参数是float64类型,需要强制转换
c = int(math.Sqrt(float64(a*a + b*b)))
fmt.Println(c)
}
流程控制
1. if-else 语句
func ifDemo1(score int){
//score := 65
if score >= 90 {
fmt.Println("A")
}else if score > 75 {
fmt.Println("B")
}else {
fmt.Println("C")
}
}
特殊写法:先执行 score := 85; 后判断 score >= 90
if score := 85; score >= 90 {
fmt.Println("A")
}
2. for循环语句
func forDemo() {
for i := 0; i < 10; i++ {
fmt.Println(i)
}
}
//可以省略初始语句和结束语句
func forDemo2() {
i := 0
for ; i < 10; i++ {
fmt.Println(i)
}
}
无限循环
for {
//无限循环体
}
3. for range 键值循环
Go语言中可以使用for range遍历数组、切片、字符串、map 及通道(channel)。 通过for range遍历的返回值有以下规律:
数组、切片、字符串返回索引和值。
map返回键和值。
通道(channel)只返回通道内的值。
4. switch scase
- 每个switch语句最多只有一个default分支
- 一个分支可由多个值,多个case值中间用逗号分隔
- 分支可以使用表达式
fallthrough语法可以执行满足条件的case的下一个case,是为了兼容C语言中的case设计的。
func switchDemo1() {
finger := 3
switch finger {
case 1:
fmt.Println("大拇指")
case 2:
fmt.Println("食指")
case 3:
fmt.Println("中指")
case 4:
fmt.Println("无名指")
case 5:
fmt.Println("小拇指")
default:
fmt.Println("无效的输入!")
}
}
func testSwitch3() {
switch n := 7; n {
case 1, 3, 5, 7, 9:
fmt.Println("奇数")
case 2, 4, 6, 8:
fmt.Println("偶数")
default:
fmt.Println(n)
}
}
func switchDemo4() {
age := 30
switch {
case age < 25:
fmt.Println("好好学习吧")
case age > 25 && age < 35:
fmt.Println("好好工作吧")
case age > 60:
fmt.Println("好好享受吧")
default:
fmt.Println("活着真好")
}
}
func switchDemo5() {
s := "a"
switch {
case s == "a":
fmt.Println("a")
fallthrough
case s == "b":
fmt.Println("b")
case s == "c":
fmt.Println("c")
default:
fmt.Println("...")
}
}
- goto (跳转到指定标签)
goto语句通过标签进行代码间的无条件跳转。goto语句可以在快速跳出循环、避免重复退出上有一定的帮助。Go语言中使用goto语句能简化一些代码的实现过程。 例如双层嵌套的for循环要退出时:
func gotoDemo1() {
var breakFlag bool
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
// 设置退出标签
breakFlag = true
break
}
fmt.Printf("%v-%v\n", i, j)
}
// 外层for循环判断
if breakFlag {
break
}
}
}
func gotoDemo2() {
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
goto breakTag
}
fmt.Printf("%v-%v\n", i, j)
}
}
return
breakTag:
fmt.Printf("结束for循环")
}
- break (跳出循环)
break语句可以结束for、switch和select的代码块。
break语句还可以在语句后面添加标签,表示退出某个标签对应的代码块,标签要求必须定义在对应的for、switch和 select的代码块上。 举个例子:
func breakDemo1() {
BREAKDEMO1:
for i := 0; i < 10; i++ {
for j := 0; j < 10; j++ {
if j == 2 {
break BREAKDEMO1
}
fmt.Printf("%v-%v\n", i, j)
}
}
fmt.Println("...")
}
- continue(继续下次循环)
func continueDemo() {
forloop1:
for i := 0; i < 5; i++ {
// forloop2:
for j := 0; j < 5; j++ {
if i == 2 && j == 2 {
fmt.Println("Shoot!")
continue forloop1
}
fmt.Printf("%v-%v\n", i, j)
}
}
}
数组(Array)
数组是同一种数据类型元素的集合。 在Go语言中,数组从声明时就确定,使用时可以修改数组成员,但是数组大小不可变化。 基本语法:
// 定义一个长度为3元素类型为int的数组a
var a [3]int
数组定义
var 数组变量名 [元素数量]T
数组的长度必须是常量,并且长度是数组类型定义的一部分,一旦定义,长度就不能改变。
[5]int和[10]int是不同的类型
数组可以通过下标进行访问,下标是从0开始,最后一个元素下标是:len-1,访问越界(下标在合法范围之外),则触发访问越界,会panic。
数组初始化
func ArrayDemo1() {
var testArray [3]int //数组初始化int类型的零值
var numArray = [3]int{1, 2} //使用指定的初始值完成初始化
var cityArray = [3]string{"北京", "上海", "city"} //使用指定的初始值完成初始化
fmt.Println(testArray) //[0 0 0]
fmt.Println(numArray) //[1 2 0]
fmt.Println(cityArray) //[北京 上海 city]
}
第二种定义形式,让编译器根据初始值的个数自行推断数组的长度
func ArrayDemo2() {
var testArray [3]int
var numArray = [...]int{1, 2}
var cityArray = [...]string{"杭州", "上海", "深圳"}
fmt.Println(testArray) //[0 0 0]
fmt.Println(numArray) //[1 2]
fmt.Printf("type of numArray:%T\n", numArray) //type of numArray:[2]int
fmt.Println(cityArray) //[杭州 上海 深圳]
fmt.Printf("type of cityArray:%T\n", cityArray) //type of cityArray:[3]string
}
第三种定义:指定索引值的方式来初始化数组
func ArrayDemo3() {
a := [...]int{1: 1, 3: 5}
fmt.Println(a) // [0 1 0 5]
fmt.Printf("type of a:%T\n", a) //type of a:[4]int
}
数组遍历
func ArrayDemo4() {
var a = [...]string{"ShiYan", "OverWatch", "minecraft"}
for i := 0; i < len(a); i++ {
fmt.Println(a[i])
}
for index, value := range a {
fmt.Println(index, value)
}
}
切片
介绍Go语言中的切皮纳(slice)及它的基本使用
切片是一个拥有相同类型元素的可变长度的序列,它是基于数组类型做的一层封装,它非常灵活,支持自动扩容。
切片是一个引用类型,它的内部结构包括地址,长度,容量,切片一般用于快速的操作一块数据集合
切片的定义
声明切片类型的基本语法:
var name []T
//name表示变量名
//T表示切片的元素类型
func sliceDemo1() {
// 声明切片类型
var a []string //声明一个字符串切片
var b = []int{} //声明一个整型切片并初始化
var c = []bool{false, true} //声明一个布尔切片并初始化
//var d = []bool{false, true} //声明一个布尔切片并初始化
fmt.Println(a) //[]
fmt.Println(b) //[]
fmt.Println(c) //[false true]
fmt.Println(a == nil) //true
fmt.Println(b == nil) //false
fmt.Println(c == nil) //false
//fmt.Println(c == d) //切片是引用类型,不支持直接比较,只能和nil比较
}
切片的长度和容量
`len()`函数求长度,内置的`cap()`函数求切片的容量
切片表达式
切片表达式从字符串、数组、指向数组或切片的指针构造子字符串或切片。它有两种变体:
一种指定low和high两个索引界限值的简单的形式,
另一种是除了low和high索引界限值外还指定容量的完整的形式。
简单切片表达式
func sliceDemo2() {
a := [5]int{1, 2, 3, 4, 5}
s := a[1:3] // s:=a[low:high]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s))
//s:[2 3] len(s):2 cap(s):4
}
省略了low则默认为0;省略了high则默认为切片操作数的长度
a[2:] // 等同于 a[2:len(a)]
a[:3] // 等同于 a[0:3]
a[:] // 等同于 a[0:len(a)]
对于数组或字符串,如果0 <= low <= high <= len(a),则索引合法,否则就会索引越界(out of range)。
对切片再执行切片表达式时(切片再切片),high的上限边界是切片的容量cap(a),而不是长度。常量索引必须是非负的,并且可以用int类型的值表示;对于数组或常量字符串,常量索引也必须在有效范围内。如果low和high两个指标都是常数,它们必须满足low <= high。如果索引在运行时超出范围,就会发生运行时panic。
func sliceDemo3() {
a := [5]int{1, 2, 3, 4, 5}
s := a[1:3] // s := a[low:high]
fmt.Printf("s:%v len(s):%v cap(s):%v\n", s, len(s), cap(s))
s2 := s[3:4] // 索引的上限是cap(s)而不是len(s)
fmt.Printf("s2:%v len(s2):%v cap(s2):%v\n", s2, len(s2), cap(s2))
//s:[2 3] len(s):2 cap(s):4
//s2:[5] len(s2):1 cap(s2):1
}
完整切片表达式
对于数组,指向数组的指针,或切片a**(注意不能是字符串)**支持完整切片表达式:
a[low : high : max]
上面的代码会构造与简单切片表达式a[low: high]相同类型、相同长度和元素的切片。另外,它会将得到的结果切片的容量设置为max-low。在完整切片表达式中只有第一个索引值(low)可以省略;它默认为0。
完整切片表达式需要满足的条件是0 <= low <= high <= max <= cap(a),其他条件和简单切片表达式相同。
使用make()函数构造切片
make([]T,size,cap)
其中:
- T:切片的元素类型
- size:切片中元素的数量
- cap:切片的容量
func sliceDemo5() {
a := make([]int, 2, 10)
fmt.Println(a) //[0 0]
fmt.Println(len(a)) //2
fmt.Println(cap(a)) //10
}
上面代码中a的内部存储空间已经分配了10个,但实际上只用了2个。 容量并不会影响当前元素的个数,所以len(a)返回2,cap(a)则返回该切片的容量。
切片的本质
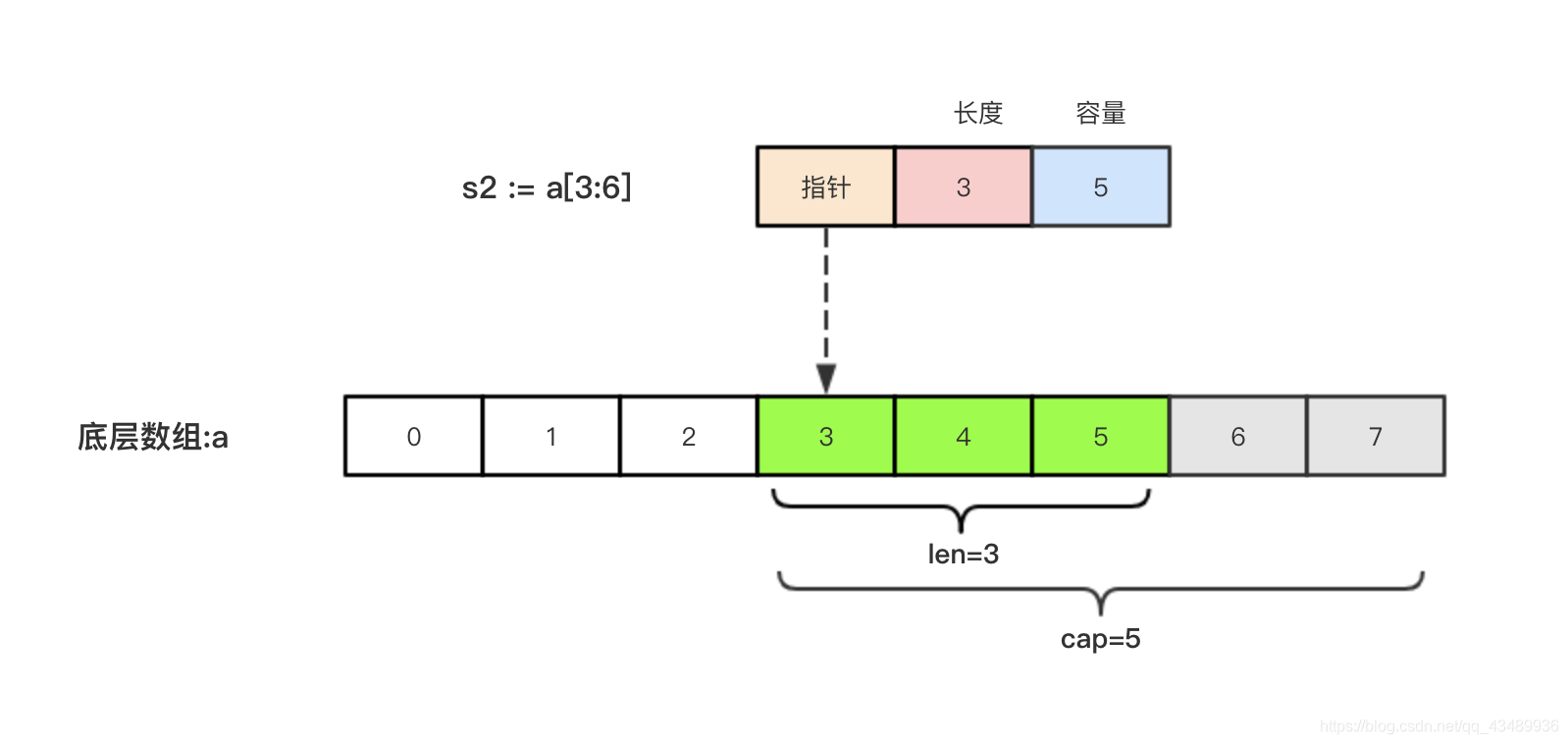
切片的本质就是对底层数组的封装,它包含了三个信息:底层数组的指针、切片的长度(len)和切片的容量(cap)。
举个例子,现在有一个数组a := [8]int{0, 1, 2, 3, 4, 5, 6, 7},切片s1 := a[:5],相应示意图如下。

切片s2 := a[3:6],相应示意图如下:
判断切片是否为空
要检查切片是否为空,请始终使用len(s) == 0来判断,而不应该使用s == nil来判断。
切片不能直接比较
切片之间是不能比较的,我们不能使用==操作符来判断两个切片是否含有全部相等元素。 切片唯一合法的比较操作是和nil比较。 一个nil值的切片并没有底层数组,一个nil值的切片的长度和容量都是0。但是我们不能说一个长度和容量都是0的切片一定是nil,例如下面的示例:
var s1 []int //len(s1)=0;cap(s1)=0;s1==nil
s2 := []int{} //len(s2)=0;cap(s2)=0;s2!=nil
s3 := make([]int, 0) //len(s3)=0;cap(s3)=0;s3!=nil
所以要判断一个切片是否是空的,要是用len(s) == 0来判断,不应该使用s == nil来判断。
切片的赋值拷贝
下面的代码中演示了拷贝前后两个变量共享底层数组,对一个切片的修改会影响另一个切片的内容,这点需要特别注意。
func sliceDemo6() {
s1 := make([]int, 3) //[0 0 0]
s2 := s1 //将s1直接赋值给s2,s1和s2共用一个底层数组
s2[0] = 100
fmt.Println(s1) //[100 0 0]
fmt.Println(s2) //[100 0 0]
}
切片遍历
func sliceDemo7() {
s := []int{1, 3, 5}
for i := 0; i < len(s); i++ {
fmt.Println(i, s[i])
}
for index, value := range s {
fmt.Println(index, value)
}
}
append()方法为切片添加元素
var s []int
s = append(s, 1) // [1]
s = append(s, 2, 3, 4) // [1 2 3 4]
s2 := []int{5, 6, 7}
s = append(s, s2...) // [1 2 3 4 5 6 7]
注意:通过var声明的零值切片可以在append()函数直接使用,无需初始化。
var s []int
s = append(s, 1, 2, 3)
每个切片会指向一个底层数组,这个数组的容量够用就添加新增元素。当底层数组不能容纳新增的元素时,切片就会自动按照一定的策略进行“扩容”,此时该切片指向的底层数组就会更换。“扩容”操作往往发生在append()函数调用时,所以我们通常都需要用原变量接收append函数的返回值。
func sliceDemo8() {
//append()添加元素和切片扩容
var numSlice []int
for i := 0; i < 10; i++ {
numSlice = append(numSlice, i)
fmt.Printf("%v len:%d cap:%d ptr:%p\n", numSlice, len(numSlice), cap(numSlice), numSlice)
}
}
[0] len:1 cap:1 ptr:0xc00000a0b8
[0 1] len:2 cap:2 ptr:0xc00000a110
[0 1 2] len:3 cap:4 ptr:0xc00000e3a0
[0 1 2 3] len:4 cap:4 ptr:0xc00000e3a0
[0 1 2 3 4] len:5 cap:8 ptr:0xc0000102c0
[0 1 2 3 4 5] len:6 cap:8 ptr:0xc0000102c0
[0 1 2 3 4 5 6] len:7 cap:8 ptr:0xc0000102c0
[0 1 2 3 4 5 6 7] len:8 cap:8 ptr:0xc0000102c0
[0 1 2 3 4 5 6 7 8] len:9 cap:16 ptr:0xc00007a000
[0 1 2 3 4 5 6 7 8 9] len:10 cap:16 ptr:0xc00007a000
Debugger finished with exit code 0
从上面的结果可以看出:
append()函数将元素追加到切片的最后并返回该切片。
切片numSlice的容量按照1,2,4,8,16这样的规则自动进行扩容,每次扩容后都是扩容前的2倍。
切片的扩容机制
$GOROOT/src/runtime/slice.go
扩容相关代码:
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
从上面的代码可以看出以下内容:
- 首先判断,如果新申请容量(cap)大于2倍的旧容量(old.cap),最终容量(newcap)就是新申请的容量(cap)。
- 否则判断,如果旧切片的长度小于1024,则最终容量(newcap)就是旧容量(old.cap)的两倍,即(newcap=doublecap),
- 否则判断,如果旧切片长度大于等于1024,则最终容量(newcap)从旧容量(old.cap)开始循环增加原来的1/4,即(newcap=old.cap,for {newcap += newcap/4})直到最终容量(newcap)大于等于新申请的容量(cap),即(newcap >= cap)
- 如果最终容量(cap)计算值溢出,则最终容量(cap)就是新申请容量(cap)。
需要注意的是,切片扩容还会根据切片中元素的类型不同而做不同的处理,比如int和string类型的处理方式就不一样。
完整代码:
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// The new slice's length is set to the old slice's length,
// NOT to the new requested capacity.
// This is for codegen convenience. The old slice's length is used immediately
// to calculate where to write new values during an append.
// TODO: When the old backend is gone, reconsider this decision.
// The SSA backend might prefer the new length or to return only ptr/cap and save stack space.
func growslice(et *_type, old slice, cap int) slice {
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice))
}
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.len < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
capmem = roundupsize(uintptr(newcap))
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\n")
// }
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
使用copy()函数复制切片
func main() {
a := []int{1, 2, 3, 4, 5}
b := a
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(b) //[1 2 3 4 5]
b[0] = 1000
fmt.Println(a) //[1000 2 3 4 5]
fmt.Println(b) //[1000 2 3 4 5]
}
由于切片是引用类型,所以a和b其实都指向了同一块内存地址。修改b的同时a的值也会发生变化。
Go语言内建的copy()函数可以迅速地将一个切片的数据复制到另外一个切片空间中,copy()函数的使用格式如下:
copy(destSlice, srcSlice []T)
其中:
srcSlice: 数据来源切片
destSlice: 目标切片
举个例子:
func main() {
// copy()复制切片
a := []int{1, 2, 3, 4, 5}
c := make([]int, 5, 5)
copy(c, a) //使用copy()函数将切片a中的元素复制到切片c
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1 2 3 4 5]
c[0] = 1000
fmt.Println(a) //[1 2 3 4 5]
fmt.Println(c) //[1000 2 3 4 5]
}
总结一下就是:要从切片a中删除索引为index的元素,操作方法是a = append(a[:index], a[index+1:]...)
切片练习
- 请写出下面代码的输出结果。
func main() {
var a = make([]string, 5, 10)
for i := 0; i < 10; i++ {
a = append(a, fmt.Sprintf("%v", i))
}
fmt.Println(a)
}
[ 0 1 2 3 4 5 6 7 8 9]
- 请使用内置的sort包对数组var a = […]int{3, 7, 8, 9, 1}进行排序(附加题,自行查资料解答)。
map
Go语言中提供的映射关系容器为map,其内部使用散列表(hash)实现。
map是一种无序的基于key-value的数据结构,Go语言中的map是引用类型,必须初始化才能使用。
map定义
Go语言中 map的定义语法如下:
map[KeyType]ValueType
其中,
KeyType:表示键的类型。
ValueType:表示键对应的值的类型。
map类型的变量默认初始值为nil,需要使用make()函数来分配内存。语法为:
make(map[KeyType]ValueType, [cap])
其中cap表示map的容量,该参数虽然不是必须的,但是我们应该在初始化map的时候就为其指定一个合适的容量。
java中有这类似的初始化分配内存的过程
HashMap<Integer,Integer> hp = new HashMap<>;
map使用
map中的数据都是成对出现的,map的基本使用示例代码如下:
func mapDemo1() {
scoreMap := make(map[string]int, 8)
scoreMap["张三"] = 90
scoreMap["小明"] = 100
fmt.Println(scoreMap)
fmt.Println(scoreMap["小明"])
fmt.Printf("type of a:%T\n", scoreMap)
}
map[小明:100 张三:90]
100
type of a:map[string]int
支持声明时填充,
- go的声明时填充:
func mapDemo2() {
userInfo := map[string]string{
"username": "BakaRice",
"password": "123456",
}
fmt.Printf("%v Type:%T", userInfo, userInfo)
}
map[password:123456 username:BakaRice] Type:map[string]string
- java的声明时填充:
HashMap<String, String> map = new HashMap<String, String>() {
{
put("name", "test");
put("age", "20");
}
};
看起来优雅了不少,一步到位,一气呵成的赶脚。然后问题来了,这里的双括号”{{}}”到底什么意思,什么用法呢?
双括号”{{}}”,用来初始化,使代码简洁易读。
第一层括弧实际是定义了一个匿名内部类 (Anonymous Inner Class),第二层括弧实际上是一个实例初始化块 (instance initializer block),这个块在内部匿名类构造时被执行。
map判断键是否存在
func mapDemo3() {
scoreMap := make(map[string]int)
scoreMap["Baka"] = 90
scoreMap["Rice"] = 100
value, valid := scoreMap["Baka"] //这里的value 以及 valid 名称可以替换
if valid {
fmt.Println(value)
} else {
fmt.Println("查无此人")
}
}
map遍历
k-v 遍历
func mapDemo4() {
scoreMap := make(map[string]int)
scoreMap["Baka"] = 90
scoreMap["Rice"] = 100
scoreMap["March"] = 60
for k, v := range scoreMap {
fmt.Println(k, v)
}
}
v 遍历
func mapDemo5() {
scoreMap := map[string]int{
"Baka": 90,
"Rice": 100,
"March": 60,
}
for k := range scoreMap {
fmt.Println(k)
}
}
使用delete()函数删除指定键
使用delete()内建函数从map中删除一组键值对,delete()函数的格式如下:
delete(map,key)
其中,
- map:表示要删除键值对的map
- key:表示要删除的键值对的键
示例代码如下:
func mapDemo6() {
scoreMap := map[string]int{
"Baka": 90,
"Rice": 100,
"March": 60,
}
delete(scoreMap, "Rice")
for k, v := range scoreMap {
fmt.Println(k, v)
}
}
按照指定顺序遍历map
func mapDemo7() {
rand.Seed(time.Now().UnixNano())
var scoreMap = make(map[string]int, 200)
for i := 0; i < 100; i++ {
key := fmt.Sprintf("stu%02d", i) //生成stu开头的字符串
value := rand.Intn(100) //生成0~99的随机整数
scoreMap[key] = value
}
//取出map中的所有key存入切片keys
var keys = make([]string, 0, 200)
for key := range scoreMap {
keys = append(keys, key)
}
//对切片进行排序
sort.Strings(keys)
//按照排序后的key遍历map
for _, key := range keys {
fmt.Println(key, scoreMap[key])
}
}
元素为map类型的切片
func mapDemo8() {
var mapSlice = make([]map[string]string, 3)
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
fmt.Println("after init")
// 对切片中的map元素进行初始化
mapSlice[0] = make(map[string]string, 10)
mapSlice[0]["name"] = "BakaRice"
mapSlice[0]["password"] = "123456"
mapSlice[0]["address"] = "China"
for index, value := range mapSlice {
fmt.Printf("index:%d value:%v\n", index, value)
}
}
值为切片类型的map
func mapDemo9() {
var sliceMap = make(map[string][]string, 3)
fmt.Println(sliceMap)
fmt.Println("after init")
key := "中国"
value, ok := sliceMap[key]
if !ok {
value = make([]string, 0, 2)
}
value = append(value, "北京", "上海")
sliceMap[key] = value
fmt.Println(sliceMap)
}
练习题
- 写一个程序,统计一个字符串中每个单词出现的次数。比如:”how do you do”中how=1 do=2 you=1。
func mapExam() {
var words = "how do you do"
strslice := strings.Split(words, " ")
fmt.Println(strslice)
countMap := make(map[string]int, 10)
for _, value2key := range strslice { // for index,value
countMap[value2key] += 1
}
for k, v := range countMap {
fmt.Println(k, "=", v)
}
}
- 观察下面代码,写出最终的打印结果。
func main() {
type Map map[string][]int
m := make(Map)
s := []int{1, 2}
s = append(s, 3)
fmt.Printf("%+v\n", s)
m["q1mi"] = s
s = append(s[:1], s[2:]...)
fmt.Printf("%+v\n", s)
fmt.Printf("%+v\n", m["q1mi"])
}
[1 2 3]
[1 3]
[1 3 3]


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









