







原论文
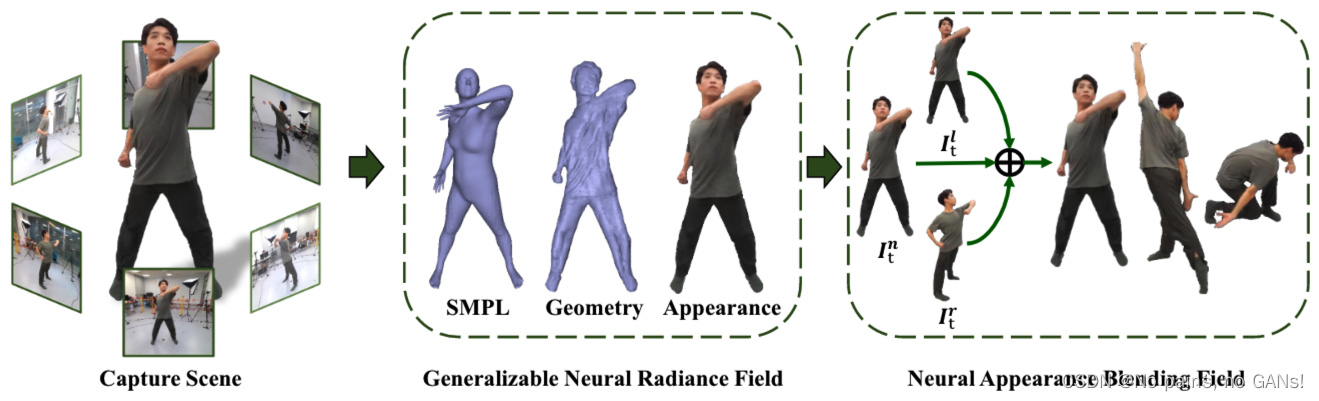
本文是从稀疏相机视图中,高效生成人体神经辐射场。
如下图所示,将 K K K 个稀疏视角的 T T T 帧同步视频作为输入,由即时高效的可泛化人体辐射场微调得到三维表征,此时合成的纹理会有明显的伪影并且缺乏高频细节,因此使用了神经外观混合场,通过聚合相邻视图的颜色来细化纹理。
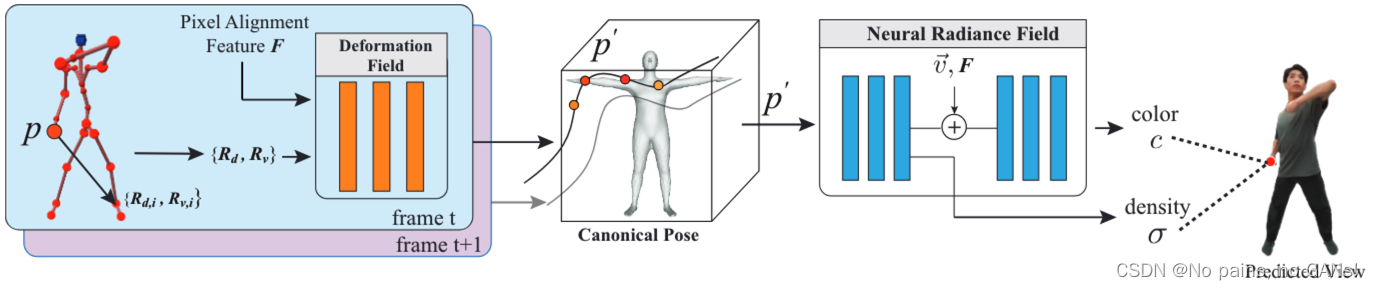
本文提出的 Generalizable Neural Radiance Field 是对 NeRF 的进一步扩展,保留了它的新颖视图合成和几何细节渲染能力。但是 NeRF 假设了场景中的对象是静态的,并且不同场景都需要重新训练,具有很大限制,因此对 NeRF 做了两个主要的改变,来处理动态人体以及获得泛化能力。具体地说,
-
将观察方向与聚合的像素对齐的特征相结合以获得泛化能力。
-
观察方向就是指下图中的 v ⃗ \vec{v} v,是从相机出发指向场景空间中任意点 p ∈ R 3 p \in \mathbb{R}^{3} p∈R3 的射线方向,
-
聚合的像素对齐的特征,可以拆解为特征、像素对齐的、聚合的三部分。具体来说,采用了 U-Net 来提取代表局部图像外观的特征。对于场景空间中任意点 p p p ,首先将其映射到 K K K 个视角的图片中的点 q k ∈ R 2 q^k\in \mathbb{R}^{2} qk∈R2(pixelNeRF、IBRNet等基于多视图合成的任务都采用了这种方法),这样就可以得到像素对齐的特征向量 f q k f_q^k fqk。为了得到一个表示 p p p 点的特征向量,还需要计算加权和,也就是聚合。将特征 f q k f_q^k fqk、 p p p 点对应的观察方向 $\vec{v} $ 以及相对于 p q k pq^k pqk 的夹角 θ q k \theta_q^k θqk 三者连接作为输入,采用了 MLP 来预测 K K K 个对齐特征的混合权重 ω i \omega_i ωi。这样就可以得到所需的聚合的像素对齐的特征 F F F。
-

最开始的 NeRF 把每张视角的图片只作为监督信号,没有直接用到图片里的信息,而本文将其融入到了模型中,增强了泛化能力。
-
本文将动态人体从当前时间帧扭曲到一个标准姿势,以便作为静态对象输入到 NeRF 中。(和另一篇HumanNeRF中采用的方法类似,依次进行刚性变换、非刚性变换)
-
作者在实验中发现 MLP 倾向于学习细微的位移,没有能力处理较大的形变。为了解决这个问题,本文将 SMPL 模型适配到当前时间帧的人体,并通过逆线性蒙皮变换 S \mathcal{S} S 扭曲为标准姿势。由此得到的模型预测结果通常与观测结果不一致,应用与姿态相关的非刚性变形场(MLP)来学习细微的位移。可以用下式表示,
p ′ = S ( p , M , w s ) + MLP d ( R d , R v , F p ) p^{\prime}=\mathcal{S}\left(p, \mathcal{M}, w^{s}\right)+\operatorname{MLP}_{d}\left(R_{d}, R_{v}, F_{p}\right) p′=S(p,M,ws)+MLPd(Rd,Rv,Fp)
其中, M \mathcal{M} M 是估计的运动, ω s \omega_s ωs 是采样点 p p p 对应的蒙皮权重。使用 R d ∈ R 24 R_d\in \mathbb{R}^{24} Rd∈R24 和 R v ∈ R 72 R_v\in \mathbb{R}^{72} Rv∈R72 来建模 p p p 与 SMPL 骨骼的24个关节点之间的距离和方向。 F P F_P FP 是聚合像素对齐特征。
-
得到标准姿态下的对应点 p ′ {p}' p′ 后,此时为静态的对应点,可以采用 NeRF 了。变形前的点 p p p 处的体密度 σ \sigma σ 只与 p ′ {p}' p′ 有关,而颜色 c c c 与观察方向 v ⃗ \vec{v} v 和聚合像素对齐特征 F F F 均有关。还是采用体渲染技术来合成最终的像素值。
-
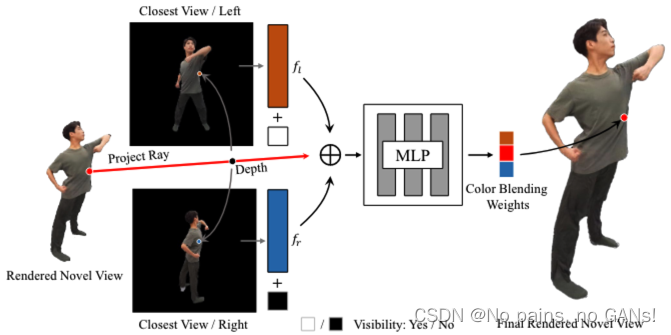
- 由于训练数据有限以及不同人体和场景之间的多样性,对于模型没有见过的人来说,会观察到伪影和缺陷。为了解决这个问题,本文采用了一种快速微调解决方案作为对原始框架的补偿。具体来说,网络经过各种主题/表演者的训练后,冻结特征混合网络,然后在推理阶段,给定一个没有见过的对象,优化形变场MLPD和可泛化的神经辐射场的网络参数。
作者观察到,由于输入视图的稀疏性,上面由 NeRF 渲染生成的纹理包含伪影并且缺少高频细节,提出了 Neural Appearance Blending。基于本文的数据采样方式,目标视图中的大多数纹理信息可以通过两个相邻输入视图来恢复。在推理阶段,首先根据可泛化的神经辐射场渲染得到目标视角下的深度图,然后将深度图中的任意点 q q q 投影到相邻视角的图像中(先在光线上根据深度取三维空间中的某个确定点 p p p,而不是随机采样,再投影),得到对应点的颜色、可见性(由深度图决定, p p p 点沿光线方向离成像点最近,就是可见的,否则不可见)以及特征,通过MLP预测权重系数,得到加权的颜色。















 594
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









