







文章目录
第六章:流水线技术
吞吐率,加速比和效率
- 吞吐率
吞吐率是完成的作业数与对应执行时间的比值,比如一个流水线在10025ns内完成了1000条指令,则吞吐率=1000 ÷ 10025=0.0998 - 加速比
加速比是流水线前指令的执行时间与流水线后执行时间的比值,比如采用流水线技术前,完成5道指令需要35ns,采用流水线技术后,除了第一轮的指令以外,后续的指令改进为了10ns,则加速比为
35 ÷ 10=3.5 - 效率
效率的定义有些复杂,直接看王道考研里的讲解,由图中可以看出,效率就是整个时空图里指令所占的有效区域和整个时空图面积的比值就是效率

静态流水线和动态流水线,静态流水线每一个时刻只能有一个功能段进行工作,假如同时有加法功能段和乘法功能段,这两个功能段无法重叠并行工作
第七章:存储系统
https://blog.csdn.net/sandalphon4869/article/details/102732281
存储器简单模型


存储芯片容量8k × 8的含义,前面的8代表8个存储单元,后面的8代表选通线数量,一共有8条,但只需要3条地址线,23=8即存储字长为8bit,8位,可以写成1Byte

内存区00000H-3FFFFH代表一共有2+4+4+4+4=18位二进制存储即218=256KB
对于SRAM6264和62256,强行记忆为256/64 × (6+2)
对于DRAM2164和21256,强行记忆为256/64 × 1

74LS138译码器特点为使能端的控制下,Y0Y4Y6和Y7只有一个可以输出即为高电平,其余全为低电平
在此题中,A15A14A13为000,Y0输出,详情参考以下解题过程

RAM和ROM

SRAM和DRAM的最大区别就是存储方式不一样,SRAM采用触发器存储,数据读出的时候不会影响存储器,并且不需要刷新,运行速度快,但是需要更多逻辑元件,集成度低,存储成本也变高。DRAM采用电容存储,读出数据破坏电容本身,需要刷新,运行速度慢但成本低集成度高


位扩展和字扩展


Cache性能分析

Cache初态为空,Cache一次读1个字,一共读100次,重复读10次,这一段话的含义有两种解读,第一种,Cache一次从主存中读1个字,读1000次,前100次全空,故丢失100次,命中率90%;第二种,Cache一次从主存中读50个字,读1000个字,第0次和第51次全空,故丢失2次,命中率99.8%;
Cache和主存同时被访问时,系统平均访问时间为
T平均=Cache命中率 × Cache访问时间 +(1-Cache命中率) × 主存访问时间
先访问Cache再访问主存时,系统平均访问时间为
T平均·=Cache命中率 × Cache访问时间 +(1-Cache命中率) × (主存访问时间+Cache访问时间)
系统效率
e = T / T平均
地址映射
- 全相联映射

①.主存容量1MB共20位,Cache4KB12位,分4块,则主存中以1KB为单位划分,则主存块内地址用10位,剩余的位数均为主存块号;
②.地址变换表有4个存储单元,每个存储单元包括10位;
∵地址变换表是4块1KBCache,所以是4个存储单元,1KB单元包括10位二进制
③.99%
-
直接映射
-
组相联映射
第八章:输入输出系统
总线
总线带宽是指单位时间内总线上传送的数据量
总线的带宽=总线的工作频率×总线的位宽/8
总线位宽是指总线能同时传送的二进制位数或数据总线的位数
总线的工作时钟频率以 MHZ 为单位,工作频率越高,总线工作速度越快,总线带宽越宽
磁盘存储器
非格式化容量=位密度×内圈磁道周长×每个记录面上的磁道数×记录面数
格式化容量=每个扇区的字节数×每道的扇区数×每个记录面的磁道数×记录面数
数据传输率=每个扇区的字节数×每道扇区数×磁盘的转速
第九章:多机系统
基本互连函数
- 恒等置换
r(xn-1xn-2…xi…x0)=xn-1xn-2…xi…x0
没啥可说的,最简单的一一对应连接
- 交换置换
h(xn-1xn-2…xi…x0)=xn-1xn-2…xi…x0(非x0)
假如N=8,则两端001与000相连,111与110相连
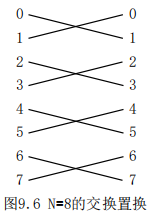
- 方体置换
Ci(xn-1xn-2…xi…x1x0)=xn-1xn-2…xi(非xi)…x1x0

方体置换中的i自己定,i=0的时候与交换置换相同,i=1的时候000与010相连,i=2的时候000与100相连
- 均匀洗牌置换
σ(xn-1xn-2…xi…x0)=xn-2…xi…x0xn-1
σ-1(xn-1xn-2…xi…x0)= x0xn-1xn-2…xi…x1
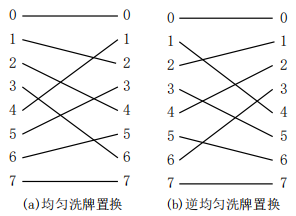
均匀洗牌置换将顺序推进了一位进行相连,比如100与001相连,101与011相连
逆均匀洗牌置换顺序后退了一位进行相连,比如001与100相连,011与101相连
- 加减2i置换
PM2+i(x)=x+2i mod N
PM2-i(x)=x-2i mod N

顾名思义,每一位与加减2i以后的位数相连
- 蝶形置换
β(xn-1xn-2…xi…x0)=x0xn-2…xi…x1xn-1
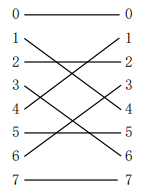
蝶形置换直接代公式,即是最高位和最低位交换
对称多处理器SMP
对称多处理机系统具有如下特点(详细):
- 系统是由两个以上的多个相同的处理机构成
- 多个处理机通过总线或其他互连方式连接在一起
- 所有的处理机通过相同的通道或不同的通道共享IO设备
- 每一处理机都能完成相同的功能,这或许是对称多处理 机中对称的由来
- 整个对称多处理机系统是在一个集中的操作系统统一管理下工作。操作系统能够为每一处理机按排进程或线程,对各处理机的工作进行统一地调度与控制
优点
- 对称性
- 单地址空间,易编程性,动态负载平衡,无需显示数据分配
- 高速缓存及其一致性,数据局部性,硬件维持一致性
- 低通信延迟,Load/Store完成
问题
- 欠可靠,总线、存储器或OS失效会造成系统崩溃
- 通信延迟(相对于CPU),竞争加剧
- 慢速增加的带宽(MB double/3年,IOB更慢)
- 不可扩放性(总线是不可扩放的,限制了处理器数量一般不能超过10,为了增大系统的规模,可改用交叉开关 连接或改用CC-NUMA或机群结构
















 2070
2070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









