







在pycharm中编写如下代码:
import requests
from bs4 import BeautifulSoup
import bs4
import re
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def remove_spaces_re1(string):
return re.sub(r"\s+","",string)
def fillUnivList(ulist,html):
soup = BeautifulSoup(html,"html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr,bs4.element.Tag):
tds = tr('td')
name = tds[1]('div')[2]('a')[0].string
rank = (str)(tds[0].string)
score = (str)(tds[4].string)
ulist.append([remove_spaces_re1(rank),remove_spaces_re1(name),remove_spaces_re1(score)])
def printUnivList(ulist,num):
print("{:^20}\t{:^16}\t{:^20}".format("排名","学校名称","总分"))
for i in range(num):
u = ulist[i]
print("{:^20}\t{:^16}\t{:^20}".format(u[0],u[1],u[2]))
if __name__ == '__main__':
uinfo = []
url = "https://www.shanghairanking.cn/rankings/bcur/2024"
html = getHTMLText(url)
fillUnivList(uinfo,html)
printUnivList(uinfo,20)
运行结果:
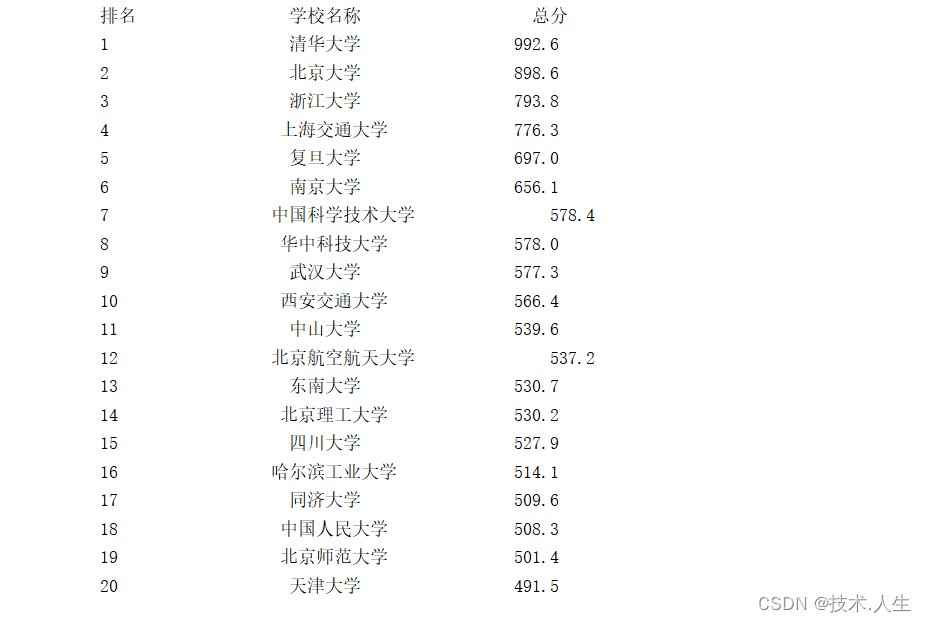
优化:
由于打印了中文,系统默认采用西文字符填充,我们可以自己采用中文字符填充,这里采用中文字符的空格填充chr(12288)
修改printUnivList函数
def printUnivList(ulist,num):
tplt = "{0:^20}\t{1:{3}^20}\t{2:^20}"
print(tplt.format("排名","学校名称","总分",chr(12288)))
for i in range(num):
u = ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288)))
运行结果:
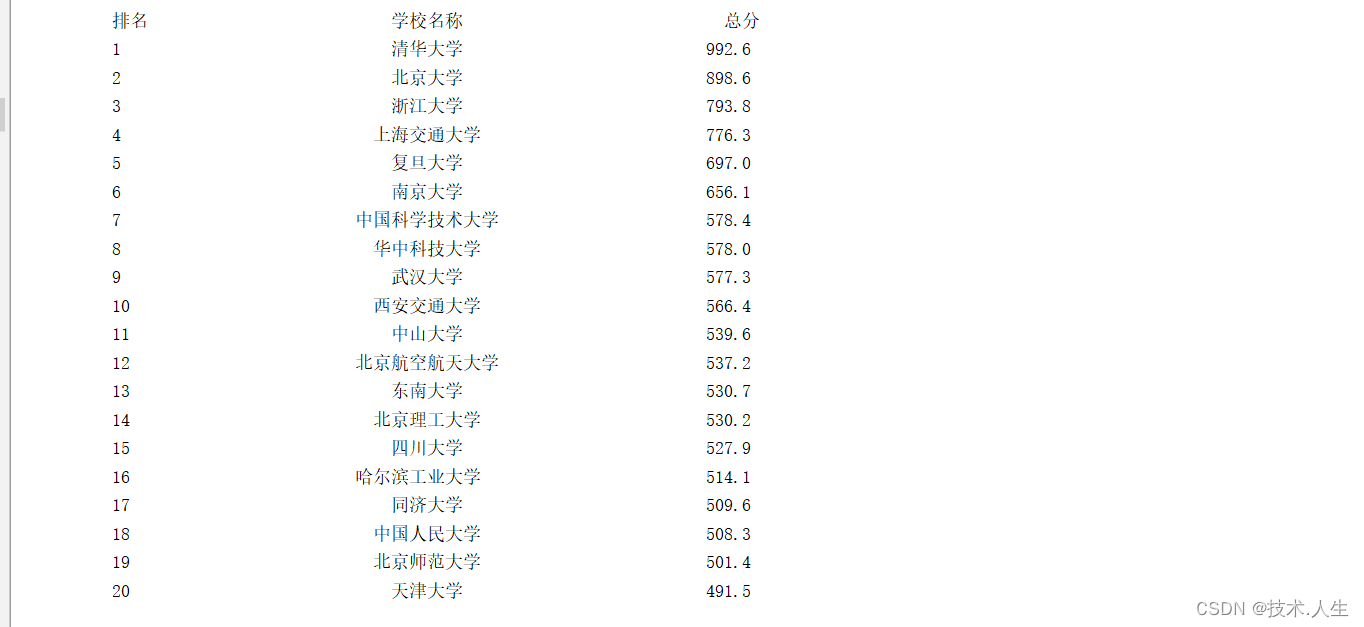


















 1191
1191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











