







 这篇博客详细介绍了Hadoop完全分布式的学习过程,包括克隆虚拟机、配置IP、环境安装、集群搭建、日志功能开启、shell脚本同步数据、集群启动与停止等步骤,适合初学者入门。
这篇博客详细介绍了Hadoop完全分布式的学习过程,包括克隆虚拟机、配置IP、环境安装、集群搭建、日志功能开启、shell脚本同步数据、集群启动与停止等步骤,适合初学者入门。
一:hadoop学习的准备工作
1.1:克隆虚拟机
找到自己配置好的虚拟机,右键管理->克隆->下一步
 设置克隆虚拟机的位置以及名字
设置克隆虚拟机的位置以及名字

点击完成,等待一段时间即可完成克隆
2.2配置克隆虚拟机
1.修改克隆机的静态ip
使用vim /etc/udev/rules.d/70-persistent-net.rules进入这个文件

vim /etc/sysconfig/network-scripts/ifcfg-lo(这个地方看网卡的名字)
可以先用ls /etc/sysconfig/network-scripts查看你自己下方网卡的
名字,你的网卡前缀为ifcfg,进入网卡即可开始配置
如果你的文件和下面的一样没有HAWDDR,可以加上HAWDDR=(刚刚复制的地址)


2.修改虚拟机的名称
这里提前说一下,如果你的主机名字和我的一样使用的是01,02这样的,建议改成1,2.这里提前说,是后面配置需要用到编程的命令,而01的使用是肯定没有1的使用方便的,所以本文自从伪分布式开始就编程hadoop1
vim /etc/sysconfig/network

3.修改host设置使得能够ping 虚拟机的名字即可ping通
vim /etc/hosts

2.2:下载解压安装hadoop 2.7.7以及jdk,完成环境的配置
下载含有tar-gz后缀的压缩文件
在虚拟机的/opt目录下创建两个文件夹:mkdir module/ software/
module:放置解压后的文件
software:放置压缩文件
用xftp进行文件的传输,将文件传输到software文件夹下
- 使用
tar -zxvf jdk-8u231-linux-x64.tar.gz -C /opt/module将文件解压缩到指定的文件夹下其中zxvf为压缩的可选项,可以看到解压的过程。-C为复制到文件,后面跟上复制到的地址 - 使用同样的方式解压缩hadoop压缩文件
2.3环境的配置:
使用
vim /etc/profile
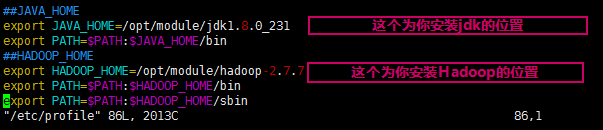
hadoop的配置还需要额外配置三个文件
我们要先来到hadoop2.7.7压缩文件下的etc目录,再从etc的目
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









