









Jpa-多表关联-OneToMany与ManyToOne
OneToMany 在
hibernate 中用于维护一对多的对应关系
ManyToOne 在 hibernate 中用于维护多对一的对应关系
准备
package com.mfyuan.model;
import jakarta.persistence.*;
import lombok.Getter;
import lombok.Setter;
import java.util.List;
@Getter
@Setter
@Entity
@Table(name = "t_process_batch", schema = "test")
public class TProcessBatch {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id", nullable = false)
private Long id;
@Column(name = "name", length = 500)
private String name;
@JoinColumn(name = "batch_id")
@OneToMany(cascade = CascadeType.PERSIST)
private List<TProcess> processList;
}
-- auto-generated definition
create table t_process_batch
(
id bigint auto_increment
primary key,
name varchar(500) null comment '流程批次名称'
);
-- auto-generated definition
create table t_process
(
id bigint auto_increment
primary key,
batch_id bigint null comment '流程批次id',
name varchar(500) null comment '流程名称'
);
JoinColumn
与 OneToMany 一起使用的情况下。
JoinColumn用于定义一对多的外键关系。
name:用 目标表 的那个字段作为 当前表 的外键,默认是 实体名_字段名
referencedColumnName:与 当前表 用那个字段进行关联,默认为 当前表的主键
注意:这里与 OneToOne 是反过来的
OneToMany
targetEntity
关联的目标实体类。默认为存储关联的字段的类型。
cascade*
表明那些操作需要级联操作。默认为空。但是查询的时候是会进行级联查询的。
PERSIST
只有插入(
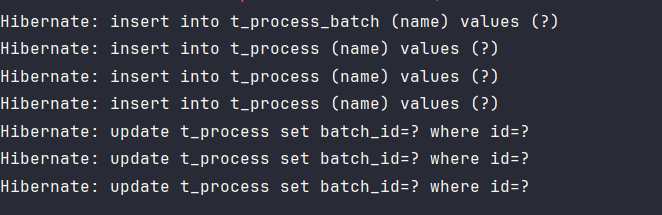
INSERT)操作时进行级联操作 插入主表的同时会插入子表。注意: 这里其实很奇怪,为什么插入子表后再通过
update来对batch_id进行更新。是这样t_process中并没有维护与t_process_batch的关系,所以采用先插入后更新的方式处理。后面使用mappedBy及@ManyToOne即可解决先插入后更新的问题了。
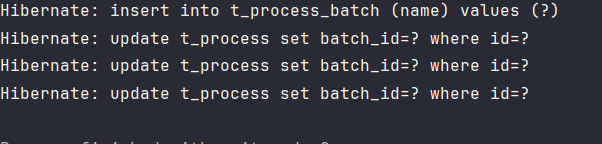
注意: 插入操作时,如果没有标注
PERSIST方法时则会出现更奇怪的问题,只插入主表,没有插入子表,但是对子表进行了更新操作。当然这里的 update 操作肯定是没有用的。
// 修改TProcessBatch.java中的 @OneToMany(cascade = {CascadeType.PERSIST})
@Test
public void testInsert(){
TProcessBatch tProcessBatch = new TProcessBatch();
tProcessBatch.setName("INSERT_PROCESS");
List<TProcess> processList = new ArrayList<>();
processList.add(new TProcess("INSERT_1"));
processList.add(new TProcess("INSERT_2"));
processList.add(new TProcess("INSERT_3"));
tProcessBatch.setProcessList(processList);
repository.save(tProcessBatch);
}
MERGE
只有更新(UPDATE)操作时进行级联操作,更新时如果将关联属性修改为 null 会把当前表的关联的字段改为 null。默认是不会删除关联表的行数据( 注意这里不会将关联表的行数据给删除,需要删除的话则需要开启 orphanRemoval)。
// 修改TProcessBatch.java中的 @OneToMany(cascade = {CascadeType.MERGE})
@Test
public void testUpdate(){
TProcessBatch tProcessBatch = new TProcessBatch();
tProcessBatch.setId(18L);
tProcessBatch.setName("UPDATE_PROCESS");
List<TProcess> processList = new ArrayList<>();
processList.add(new TProcess("UPDATE_1"));
processList.add(new TProcess("UPDATE_2"));
tProcessBatch.setProcessList(processList);
repository.save(tProcessBatch);
}
更新有两种情况
-
已有子表的关联信息
先查询是否存在主表及子表信息,更新完主表后,对子表进行插入,插入完成后,将所有旧的关联数据的关联字段修改为
null,再对将新插入的子表的关联字段进行更新。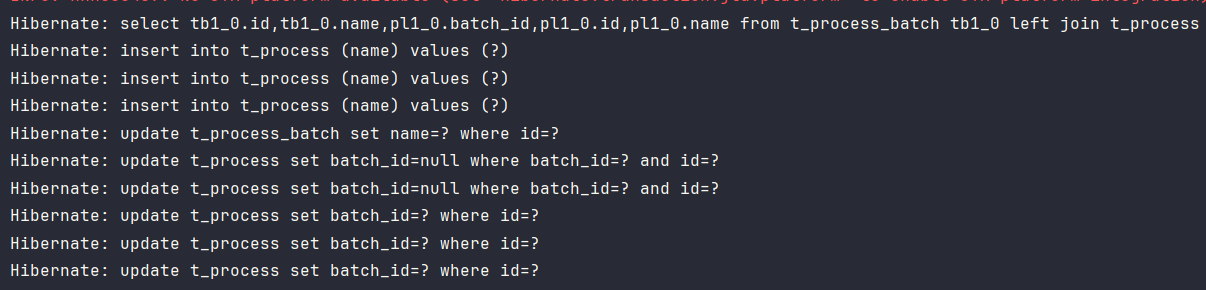
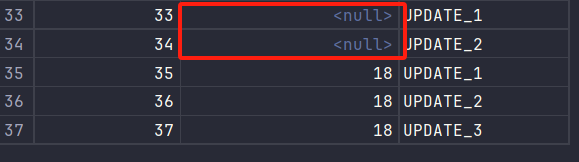
-
没有子表的关联信息
先查询是否存在主表及子表信息,更新完主表后,对子表进行插入,再对子表的关联字段进行更新。

REMOVE
只有删除(DELETE)操作时进行级联操作,删除主表的同时会把子表也删除
// 修改TProcessBatch.java中的 @OneToMany(cascade = {CascadeType.REMOVE})
@Test
public void testRemove(){
repository.deleteById(22L);
}
查询主表与子表的信息,将子表中所有存在关系行的关联字段改为
null,并删除子表信息,再删除主表信息。
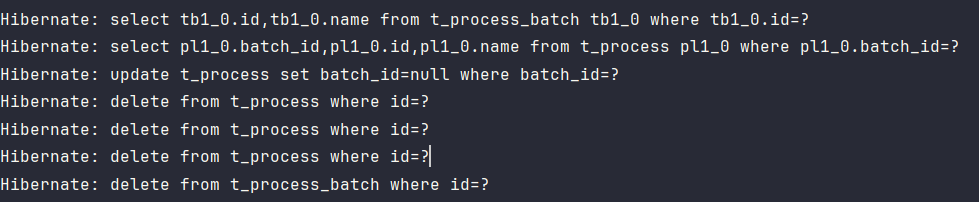
没有添加
CascadeType.REMOVE时不会对子表进行删除。

REFRESH
EntityManager.refresh() 方法用于重新加载实体的状态,从数据库中获取最新的数据,并覆盖当前持久化上下文中的实体状态
orphanRemoval
当进行更新操作时,将清空主表的关联数据或修改主表的关联数据时,会删除关联的子表数据。默认为 false(只是将子表的关联字段改为 null)。
// 修改TProcessBatch.java中的 @OneToMany(cascade = {CascadeType.MERGE},orphanRemoval=true)
@Test
public void testOrphanRemoval(){
TProcessBatch tProcessBatch = new TProcessBatch();
tProcessBatch.setId(26L);
tProcessBatch.setName("UPDATE_PROCESS1");
List<TProcess> processList = new ArrayList<>();
tProcessBatch.setProcessList(processList);
repository.save(tProcessBatch);
}
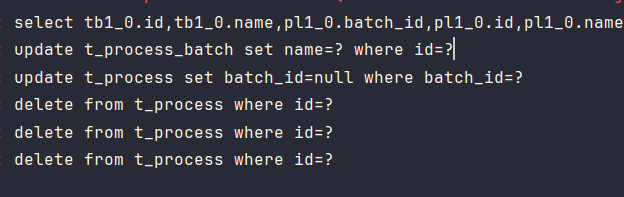
当对原有的子表集合进行操作时,会先将原有子表中所有与当前表有关联数据行的关联字段修改为
null,并对删除这些行。默认(false):只会改为null,不会删除。
fetch
LAZY:(默认与@OneToOne相反)如果是LAZY则是当我们使用关联表对象的时候才会去进行查询。注意 使用LAZY时需要@Transactional中进行使用,因为如果查询完session关闭了就不能从里面获取数据了。EAGER:立即获取数据与主表一起查出- 为什么不默认呢?因为如果这样的一对多关系存在很多个的话,一起查出来性能能很差,查出来的数据也不一定用。
// 默认情况下不加@Transactional 在使用子表数据的时候会报错
@Test
@Transactional
public void testOneToOneFetchLazy(){
TUserAccount tUserAccount = userAccountRepository.findById(6L).get();
System.out.println("================wait================");
System.out.println(tUserAccount.getUser());
}

// 修改TProcessBatch.java中的 @OneToMany(cascade = {CascadeType.ALL},orphanRemoval=true,fetch = FetchType.EAGER)

先只查主表,如果我们 没有使用则不会对关联表进行查询,而到我们获取关联表信息的时候再去对关联表进行查询。
optional
是否允许为空,默认是 true。为 false 时不能将关联字段设置为 null。表示为非空的关联关系。
MappedBy*
主要作用用于,多 与 一 进行 双向关联。表示关联关系为 当前字段类型的的实体 来进行维护,指定的值为 目标类型 中的外键字段。这里删除,更新,不会对关联进行操作。
一对多 <==> 多对一
当使用
MappedBy需要在 多 的这个关系中维护一个@ManyToOne的关联关系。而 一 只需要通过
@OneToMany通过MappedBy使用这个关系即可。
@Entity
@Table(name = "t_process_batch", schema = "test")
public class TProcessBatch {
//...
// 不在使用@JoinColumn来维护关联关系。
@OneToMany(mappedBy = "batch", cascade = {CascadeType.ALL},orphanRemoval = true,fetch = FetchType.EAGER)
private List<TProcess> processList;
}
@Entity
@Table(name = "t_process", schema = "test")
public class TProcess {
// 但是这里要使用JoinColumn来维护多对一的关系 name 只当前表用来关联的字段,referencedColumnName:默认为关联表的主键
@JoinColumn(name = "batch_id")
@ManyToOne
private TProcessBatch batch;
}
@Test
public void testQueryManyToOne(){
TProcess tProcess = processRepository.findById(73L).get();
System.out.println(tProcess);
}

因为进行了双向绑定,先通过查询将
TProcess与TProcessBatch多对一的数据查询出来,再通过得到的batch_id去进行 一对多 的查询。
ManyToOne
通常情况下:在进行插入的时候会查
ManyToOne这个对象中进行,而查询则会在OneToMany的对象中进行。这样更符合业务逻辑。
















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











