







Kubernetes
微服务、集群、分布式
微服务
先了解不用微服务,也就是版本之前的单体应用。大家开发程序,都是在一个项目下进行,如下:
项目结构:
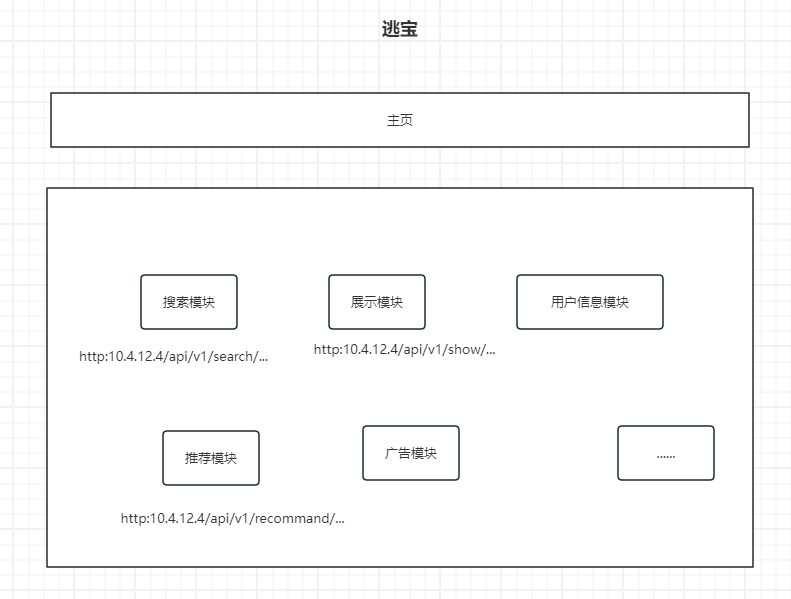
可以看到,各个模块(服务)都是在同一台机器上运行的(ip相同)
采用idea进行开发:
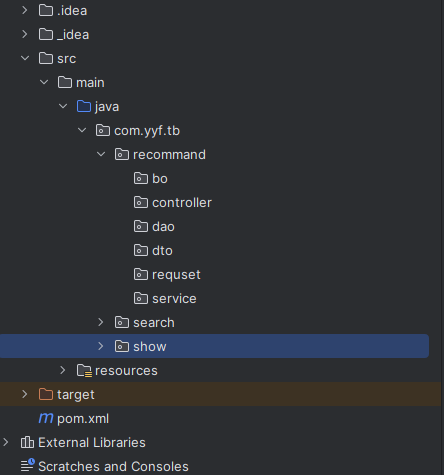
对应用进行微服务拆分后:
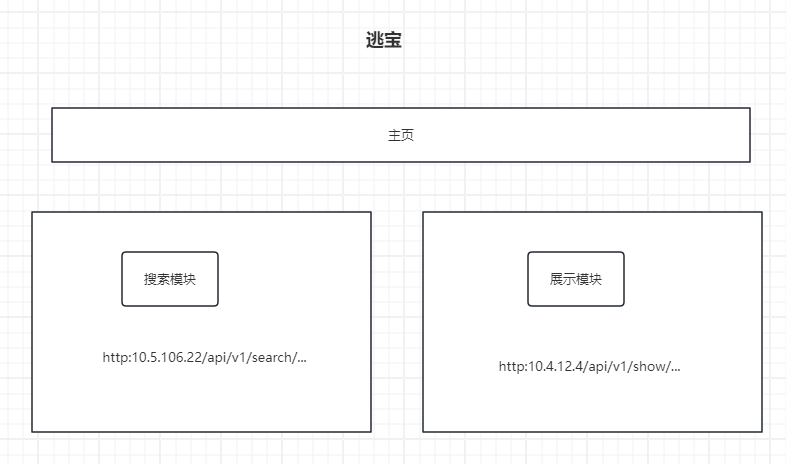
对系统进行分析,可以将服务进行拆分,分出来的就是一个一个的微服务,然后放到不同的机器上去运行。
微服务好处:高性能,高可用。
微服务缺点:协调是个大问题。
集群
同一个服务(服务在不同开发团队中所表示的含义可能不一样)在多个机器上跑,就构成一个集群。
如下:
3台机器都跑同样的搜索模块,如果一个机器能承载100qps的流量,那么三台就可以承载300qps,大幅度提高了性能。
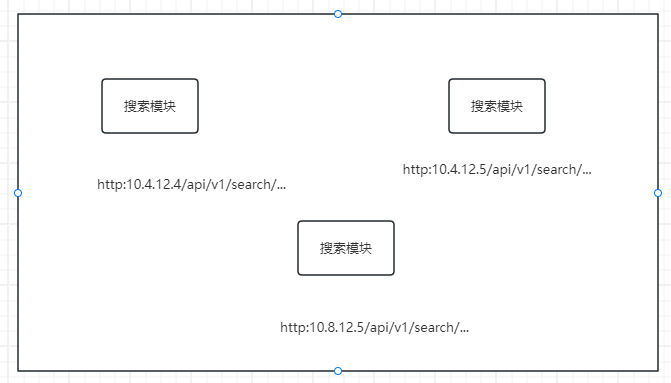
当然,单体应用,如果跑在了多个机器上,也可以称为集群,不过一般不这么干。
分布式
单体应用:如最开始的图片所示
分布式应用:将单体应用拆开,在不同的机器上提供不同的功能,这就是分布式
分布式好处:稳定,性能好,速度快
分布式坏处:消息同步始终是个问题,这里的消息是很宽泛的概念,不光指微服务之间的通信,还涉及到多个数据库数据的同步,注册中心实例之间的同步等,只要是分布式(或者也可以称为采用了集群)都要考虑到这个问题
总结
微服务、分布式、集群在企业中都是相伴随出现的。
k8s是干嘛的
容器
docker作为基础,这里就不讲了。一定要能够熟练使用这个工具。
简单理解:容器就是一个虚拟机(机器),里面跑了一个程序(微服务),用于对外提供特定的服务(如推荐服务)。
注意:容器不是一台虚拟机。
k8s作用
管理容器化集群的。
当我们将一个系统拆分成了多个微服务,然后又以分布式集群的方式部署在了很多地方(北京、上海、广州、香港),那怎么管理这些又多又乱的容器呢?k8s提供了统一的解决方案。

我们理解技术的时候,可以用分层的角度去看待,这些层并不一定是真正存在的,而是逻辑上被划分出来的,事实上,只有物理机层是真真正正的物理存在的,其他的要么是逻辑划分,要么是技术实现。
在之前讨论的机器这一概念,和之后将要讨论的机器的概念,现在统一一下,机器都是指虚拟机,而不是物理机,我们不关心物理机到底是什么情况。如下,物理机可以通过虚拟化技术创建很多虚拟机,我们只关心虚拟化后的机器即可,以后虚拟机简称虚机。
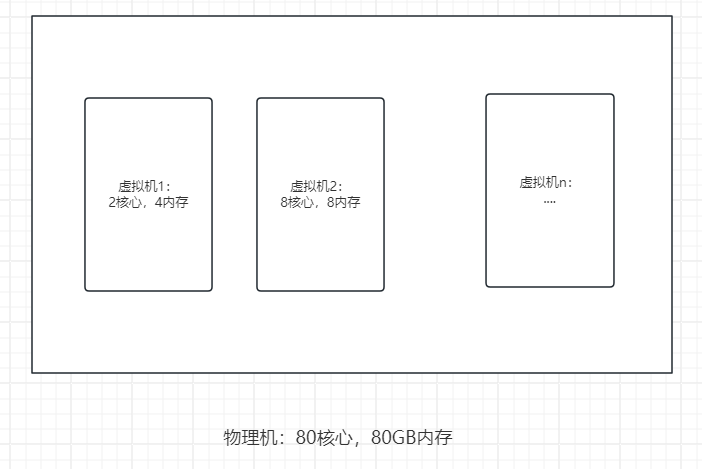
思考:上面这个物理机可以虚拟化的最大配置是多少?还是80c,80m。
k8s基础内容
总体架构
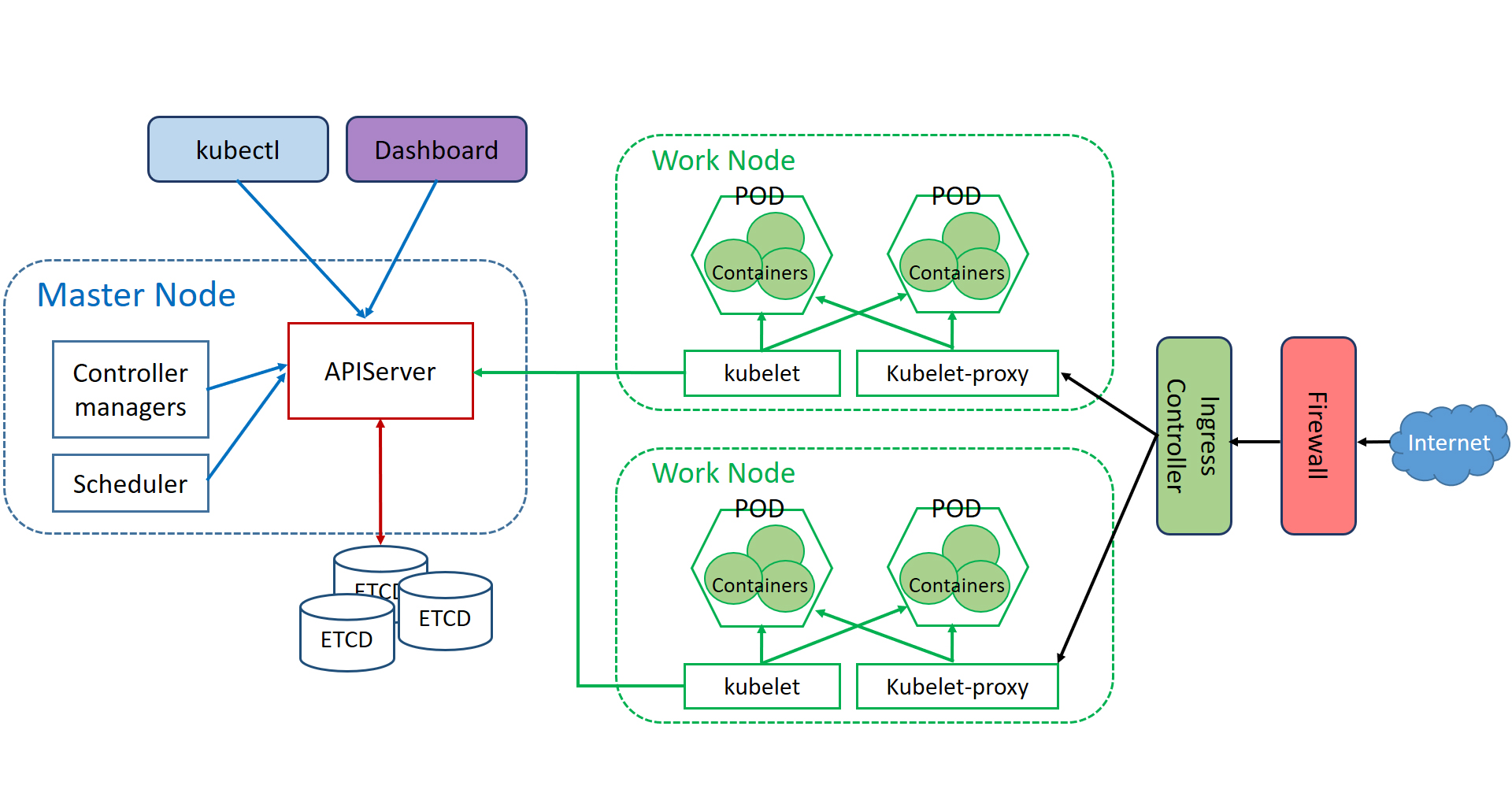
k8s是用于集群管理的,它本身有2种节点,Master Node(简称Master)和Work Node(简称Node),前者不负责运行程序(运行实际的微服务的容器),后者才运行容器。这2种node,实际上就是2种虚机,只是下载了不同的工具,所以具备了不同的能力。
特殊的,如果只有1个节点(1台机器),那么这个节点只能是Master,且可以同时当做Node使用。
使用k8s运行程序的步骤(k8s版hello world):
创建一个Controller,Controller中指定容器的镜像,然后运行这个Controller,即可。内部流程:
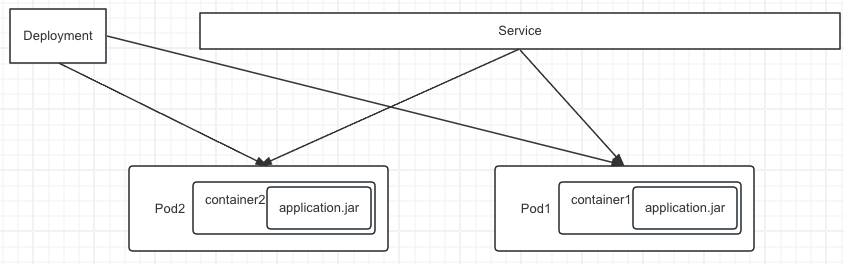
Master上会创建一个Deployment Controller,然后这个Controller根据情况选一个或多个Node,在这上面运行Pod(将Pod飘到指定Node上),Pod中包含了一个或多个容器Container。
特别说明:Pod中可以有多个容器,但一般都用1个。
创建命令:
kubectl create deployment nginx-deployment --image=nginx:1.7.9 --replicas=2
配置文件+apply命令:
nginx.yaml
apiVersion: extensions/v1beta1 # 当前配置格式的版本
kind: Deployment # 创建的资源,是一个Deployment的Controller
metadata: # 本资源-Deployment的元数据
name: nginx-deployment # name是必备的元数据项
spec: # 本资源-Deployment的规格说明
replicas: 2 # 副本数量,不指定则默认是1,这里是指Pod数量
template: # Pod的模版
metadata: # Pod的元数据
labels: # 这里规定至少定义一个label
app: web_server
spec: # Pod的规格说明
containers: # 每个Pod内的容器属性设置
- name: nginx # name必需
image: nginx:1.7.9 # image必需
kubectl apply -f nginx.yaml
核心概念
Master - 一台虚机,在k8s中作为主节点,负责管理功能,内部的组件具体实现
Node - 一台虚机,在k8s中作为工作节点,负责运行实际工作的容器(Pod)
Pod - k8s中的管理单元,一个Pod中可以包含1个或多个容器,可以理解为docker镜像逻辑上放在Pod中(一般来说,一个Pod中运行一个微服务容器,但是也有特殊的,比如引入了服务网格后,一个Pod中还要加一个Sidecarc容器,如Envoy)。
Controller - 控制器,负责运行Pod(容器)
Service - 暴露统一的ip和端口给外界,自己负责管理请求如何分发到多个Pod中,负责访问容器
Namespace - 逻辑上划分集群,比如我用3台虚拟机搭建了一个集群,可以通过建立namespace虚拟成多个集群,如default,kube-system,ns1,ns2等,便于管理资源。
资源:在k8s上运行的功能,99%都是资源,也就是使用yaml进行配置和创建的。
- 思考一下,ns如何实现配额管理。

简单介绍Node
Master节点
- API Server
k8s集群的前端接口,通过这个,使用集群的人可以来管理集群的资源
- Scheduler
主要负责管理Pod,将Pod放到哪个Node上
- Controller Manager
管理集群中的资源,由很多种Controller组成
- etcd
保存k8s集群的配置信息和状态信息,相当于一个配置数据库
- Pod网络
用于Pod直接相互通信的网络,比如flannel
Node节点
- kubelet
Node的agent,用于接受配置信息,创建运行容器,相当于Node中实际在干活的小人儿
- kube-proxy
用于和service交互,负责流量处理
- Pod网络
作用同上。
认识各个组件
Controller
负责运行Pod,包括将Pod放在哪种Node上去跑,以及定义Pod的属性,比如副本数量等。
Controller有多种,如下
- Deployment
最常用的Controller,可以跑多个Pod,它使用的是另一个Controller-ReplicaSet,但ReplicaSet一般不直接使用,因此,只使用Deployment即可。(此处展示一个yaml)
- DaemonSet
只能跑一个Pod,通常用于运行守护应用。每个Node上最多只有一个DaemonSet创建的Pod副本。
- StatefulSet—没怎么用过,主要是用于对顺序有要求的
多个Pod副本名称不变,多个Pod副本按照固定顺序启动,更新,删除
- Job
运行一次性任务
Service
Service用来处理外界访问k8s内部Pod,由于Pod的不稳定性(重启后会引起ip变化),引入了service来负责与外界稳定的交互,暴露稳定的ip。
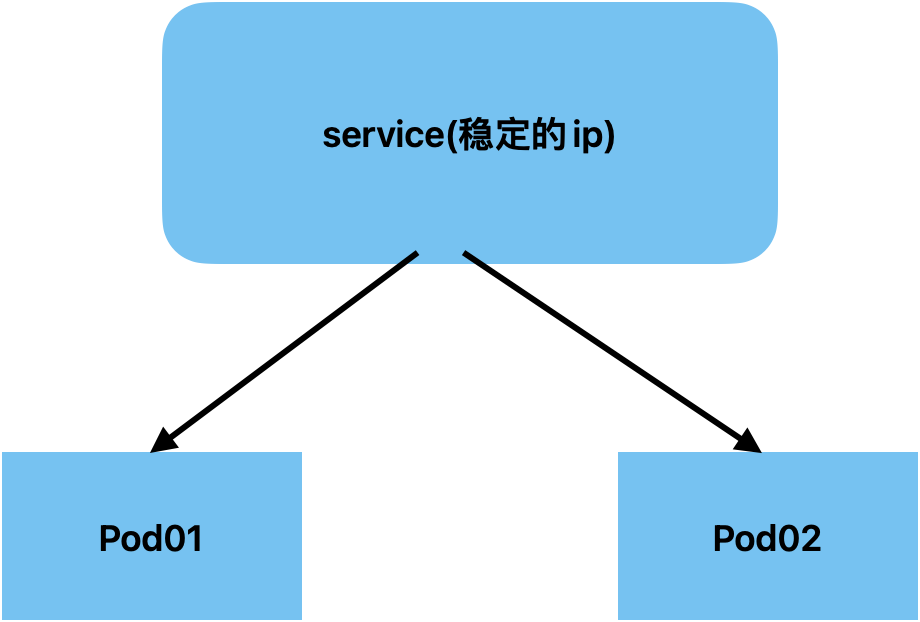
-
集群内部访问Service方式:
方式1:通过IP直接访问
如果知道了Service的IP地址,可以按照普通ip:port的形式直接访问Service,Service会根据负载均衡将流量分配到内部管理的各个Pod中
方式2:通过DNS访问
如果不知道Service的IP地址,但知道Service的名字和所属的命名空间,可以通过service_name.namespace_name:port的形式访问Service,如果namespace是default,可以直接使用service_name
-
外网访问Service方式:
方式1:通过Node的IP进行访问
使用这种方式就要换一种Service—NodePort,这种Service会直接将Node的某个端口映射到Service的端口上,外部可以通过Node的ip和刚分配到的port访问Node,然后Node将流量发送给Service,Service再将流量发送到各个Pod中。
方式2:通过ClusterIP进行访问
这是默认的方式,相当于把service的ip暴露出去,常用。
到了Service这里,一个简单的集群式程序就运行出来了。
Volume
k8s的Volume和docker的volume类似,提供的功能都是一样的,可以将容器的数据挂载到外部设备。但是,有一点很不一样,如果使用docker的volume,可以很简单的就挂载到运行这个docker镜像的机器上;而k8s的镜像是运行在Pod上,Pod又会被调度到Node上,对于k8s集群,Node一定有很多个,而Pod可能会重启被调度到别的Node,因此k8s的Volume就不能挂载到机器上(不稳定),而是挂载到云设备上(稳定)。
- emptyDir
本volume和Pod生命周期一致,不具备持久性,适合存储临时数据。
- hostPath
本volume是将主机上已经存在的目录挂载到Pod容器中,这样volume更加持久,Pod重启也会存在,但是增加了Pod与节点的耦合,用的不多,需要访问k8s或者docker内部数据(配置文件和二进制库)的会使用此volume。因此,书中没有给自己写的例子,而是给了kube-apiserver的Pod配置。
本volume不作为日常持久化volume使用
- 外部Storage Provider
这部分是使用云硬盘来作为volume,暂时没看。
- PersistentVolume—常用
这部分是常用的持久化存储方式,也是使用了外部存储系统,比如NFS。
这里PV和PVC配合使用,共同实现容器数据卷的挂载。
Secret
可以用来存储账号密码。
设置方式有4种,这里就不详细记录了。
在Pod中使用Secret的方式有2种,通过Volume或者使用静态变量,前者支持Secret的动态更新,后者不支持。
ConfigMap
可以用来存储一些非敏感信息,比如应用的配置信息。
Configmap和Secret使用非常相似。
设置方式也有4种,常用的通过引用外部文件和Volume。
由于配置信息通常是以文件的形式出现的,因此在Pod中使用Configmap的方式也常用Volume。
常用命令
# 命令行运行一个deployment
# k8s 1.18版本后 run后没有replicas选项,create deployment命令中存在replicas选项
kubectl run nginx-deployment --image=nginx:1.7.9 --replicas=2
# 新版的命令创建deployment--创建后,等待一段时间后2个Pod副本就启动了
kubectl create deployment nginx-deployment --image=nginx:1.7.9 --replicas=2
# 常用kubectl apply命令,代替上面的kubectl run和kubectl create命令,足够应付90%的场景。但kubectl apply一般都是跟yaml文件的
kubectl apply -f nginx.yaml
kubectl apply -f httpd.v1.yaml --record # 保存此次命令的记录
# 回滚
kubectl rollout undo deployment httpd --to-revision=2
# 查看services
kubectl get services
# 查看service为httpd-rec的具体信息
kubectl describe service httpd-rec
# 查看控制器deployment的信息,也可以查看别的控制器信息(其实是查看这个控制器管理的Pod副本的信息)
kubectl get deployment
kubectl describe deploment
kubectl get replicaset # 查看replicaset控制器的信息
kubectl get daemonset --namespace=kube-system # 查看kube-system命名空间下控制器daemonset的Pod副本信息
kubectl get job
# 查看pod
kubectl get pod
# 查看revision记录
kubectl rollout history deployment httpd
# 删除控制器资源--把其管理的Pod都删除
kubectl delete deployment niginx-deployment # 使用命令行创建的
kubectl delete -f nginx.yaml # 使用yaml文件创建的
# 给Node添加label
kubectl label node k8s-node1 disktype=ssd
# 查看node的label
kubectl get node --show-labels
# 查看Pod中某个container的日志
kubectl logs producer-consumer consumer
# Helm命令
helm init
helm search
helm install stable/mysql
yaml文件实例
对于任何资源:Controller、Pod、Service等等。都有2部分,metadata(元数据定义)和spec(规格说明),metadata中主要定义name,labels这些属性,spec就是要说明本资源使用的下一层资源。
Deployment
apiVersion: extensions/v1beta1 # 当前配置格式的版本
kind: Deployment # 指定创建的资源类型,是一个Deployment的Controller
metadata: # 本资源-Deployment的元数据
name: nginx-deployment # name是必备的元数据项
spec: # 本资源-Deployment的规格说明
replicas: 2 # 副本数量,不指定是1,这里是指Pod数量
template: # Pod的模版
metadata: # Pod的元数据
labels: # 这里规定至少定义一个label
app: web_server
spec: # Pod的规格说明
containers: # 每个Pod内的容器属性设置
- name: nginx # name必需
image: nginx:1.7.9 # image必需
Job
apiVersion: batch/v1
kind: Job
metadata:
name: myjob
spec:
completions: 6 # Pod运行成功的总数量
parallelism: 2 # 并行运行的Pod数量
template: # 对Pod模版的描述
metadata:
name: myjob # 这里就不需要指定label了
spec: # Pod的规格说明
containers:
- name: hello
image: busybox
command: ["echo", "hello k8s job! "]
restartPolicy: Never # Pod的重启策略
CronJob
apiVersion: batch/v2alpha1
kind: CronJob
metadta:
name: hello
spec: # 定时任务的规格描述
schedules: "*/1 * * * *" # 支持cron表达式
jobTemplate: # 这里有一个额外的template,定义Job的模版
spec: # CronJob控制器的规格描述
template: # 对Pod模版的描述,和之前的语法相同了
spec: # Pod的规格说明
containers: # 设置Pod的容器
- name: hello
image: busybox
command: ["echo", "hello k8s job! "]
restartPolicy: OnFailure # 设置Pod的重启策略
Service
apiVersion: v1
kind: Service # 使用的组件是Service
metadata:
name: httpd-svc
spec:
selector: # 标签选择器,选择标签为run: httpd的Pod
run: httpd
ports: # 设置端口相关配置,有点类似于containers的格式
- protocol: TCP
port: 8080 # Service对外暴露的端口
targetPort: 80 # 8080所映射的Pod的端口80
NodePortService
apiVersion: v1
kind: Service
metadata:
name: httpd-svc
spec: # 对Service的规格描述
type: NodePort # 使用新类型的Service,如果不指定这个字段,则默认使用ClusterIP类型的Service,外网不能访问
selector:
run: httpd
ports:
- protocol: TCP
nodePort: 30000 # 指定为Node分配的port,如果不指定本字段,则默认从30000~32767中随机分配一个port
port: 8080 # Service的port
targetPort: 80 # Pod的port
livenessProbe
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness
spec:
restartPolicy: OnFailure
containers: # 这里不用使用template,直接定义容器containers即可
- name: liveness
image: busybox
args: # 模拟一个程序执行,先创建/tmp/healthy 然后休眠30s,然后删除,然后休眠600s
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe: # 自定义liveness探针!关键,要在containers的下一层目录
exec: # 定义探测的语句
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10 # 容器初始化后10s运行
periodSeconds: 5 # 每隔5s执行1次,若连续三次失败,则认为容器发生故障
readinessProbe
和livenessProbe这个探针用法相同。
apiVersion: v1
kind: Pod
metadata:
labels:
test: readiness
name: readiness
spec:
restartPolicy: OnFailure
containers:
- name: readiness
image: busybox
args: # 模拟一个程序执行,先创建/tmp/healthy 然后休眠30s,然后删除,然后休眠600s
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe: # 自定义readiness探针!关键,要在containers的下一层目录
exec: # 定义探测的语句
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10 # 容器初始化后10s运行
periodSeconds: 5 # 每隔5s执行1次,若连续三次失败,则认为容器发生故障
readinessProbe—httpGet
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: web
spec:
replicas: 3
template:
metadata:
labels:
run: web
spec:
containers:
- name: web
image: myhttpd
ports: # 新位置,这里也可以定义port,现在有4个port了
- containerPort: 8080
readinessProbe:
httpGet: # 使用了httpGet的探测方式
scheme: HTTP # 可以不写,默认就是这个,还支持https
path: /healthy
port: 8080 # 还可以加host字段,可以不加,默认是容器ip
initialDelaySeconds: 10
periodSeconds: 5
--- # 3个-表示一个新的配置文件
apiVersion: v1
kind: Service
metadata:
name: web-svc
spec:
selector:
run: web
ports:
- protocol: TCP
port: 8080
targetPort: 80
rollingUpdate
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: app
spec:
strategy: # 设置控制器的策略
rollingUpdate: # 滚动更新的策略
maxSurge: 35%
maxUnavailable: 35%
replicas: 10
template:
metadata:
labels:
run: app
spec:
containers:
- name: app
image: busybox
args:
- /bin/sh
- -c
- sleep 3000
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 10
periodSeconds: 5
emptyDir
模拟生产者消费者
apiVersion: v1
kind: Pod
metadata:
name: producer-consumer
spec:
# 定义Pod的容器数据卷
volumes:
- name: shared-volume
emptyDir: {} # 定义本类型的volume
# 以下是container的相关定义
containers:
- image: busybox
name: producer
volumeMounts: # 挂载到容器数据卷上
- mountPath: /producer_dir # 本容器的位置
name: shared-volume # 使用名字就可以找到外部的容器数据卷
args: # 模拟生产者生产文件
- /bin/sh
- -c
- echo "hello k8s volume" > /producer_dir/hello ; sleep 30000
- image: busybox
name: consumer
volumeMounts:
- mountPath: /consumer_dir
name: shared-volume
args: # 模拟消费者读取文件
- /bin/sh
- -c
- cat /consumer_dir/hello ; sleep 30000
PV
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
persistentVolumeReclaimePolicy: Recycle
storageClassName: nfs
nfs:
path: /nfsdata/pv1
server: 192.168.56.105
PVC
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc1
spec:
accessModes:
- ReadWriteOnce
resource:
requests:
storage: 1Gi
storageClassName: nfs
通过PVC使用PV
apiVersion: v1
kind: Pod
metadata:
name: mypod1
spec:
# 指定外部的容器数据卷
volumes:
- name: mydata
persistentVolumeClaim:
claimName: mypvc1
containers:
- name: mypod1
image: busybox
args:
- /bin/sh
- -c
- sleep 30000
volumeMounts:
- mountPath: "/mydata" # 指定挂载到本地的目录
name: mydata # 指定挂载的外部容器数据卷选择哪个
动态供给StorageClass
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: standard
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp2
reclaimPolicy: Retain
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: slow
provisioner: kubernetes.io/aws-ebs
patameters:
type: io1
zones: us-east-1d, us-east-1c
iopsPerGB: "10"
Secret
apiVersion: v1
kind: Secret
metadata:
name: mysecret
data: # 里面的数据必须是base64编码后的结果
username: YWRtaW4=
password: MTIzNDU2
通过Volume使用Secret
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
volumes:
- name: foo
secret: # vulome这边可以直接挂载到secret上,将secret看成一个文件的形式
secretName: mysecret
containers:
- name: mypod
image: busybox
args:
- /bin/sh
- -c
- sleep 10; touch /tmp/healthy; sleep 30000
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
通过环境变量使用Secret
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: busybox
args:
- /bin/sh
- -c
- sleep 10; touch /tmp/healthy; sleep 30000
env: # 使用环境变量
- name: SECRET_USERNAME # 环境变量名
valueFrom:
secretKeyRef:
name: mysecret # Secret名
key: username
- name: SECRET_PASSWORD
valueFrom:
secretKeyRef:
name: mysecret
key: password
ConfigMap
apiVersion: v1
kind: ConfigMap
metadata:
name: myconfigmap
data:
logging.conf | # 注意这里是文件名,并且后面还有一个特殊符号 |
class: logging.handlers.RotatingFileHandler
formatter: precise
level: INFO
filename: %hostname-%timestamp.log
通过Volume使用ConfigMap
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: busybox
args:
- /bin/sh
- -c
- sleep 10; touch /tmp/healthy; sleep 30000
volumeMounts:
- name: foo
mountPath: "/etc/foo"
readOnly: true
volumes: # 设置外部挂载的容器数据卷
- name: foo
cofigMap:
name: myconfigmap
通过环境变量使用ConfigMap
apiVersion: v1
kind: Pod
metadata:
name: mypod
spec:
containers:
- name: mypod
image: busybox
args:
- /bin/sh
- -c
- sleep 10; touch /tmp/healthy; sleep 30000
env:
- name: CONFIG_1
valueFrom:
configMapKeyRef:
name: myconfigmap
key: config1
- name: CONFIG_2
valueFrom:
configMapKeyRef:
name: myconfigmap
key: config2
推荐资料
https://kubernetes.io/docs/tutorials/hello-minikube/
官网提供了一个minikube,可以在一台机器上开启一个k8s集群,自己跑着学习一下概念和常用组件的使用还是不错的。(Linux或Mac系统)
《每天5分钟玩转Kubernetes》
《深入剖析Kubernetes》
k8s高级内容
Rolling Update
滚动更新:这是k8s默认支持的。含义是:当有多个Pod副本时,如果我们要更新他们(运行新的yaml文件),那么k8s并不会一次将原来的Pod全部停了,然后再运行新的Pod,而是先更新一部分Pod,成功后再运行更多的Pod副本,直到所有新Pod都运行完成,则完成更新。实现了更新过程中始终有Pod在运行,保证了业务的连续性。
另外,滚动更新其实一般和回滚相关联,因为更新不一定是正向的,也可以用旧版本去更新新版本,这样逻辑上是更新,实际上是回滚。此时要在kubectl apply语句后面加上 - -record,这样就能把每个revision记录的详细信息保存起来,方便回滚的时候查看。
Health Check
k8s有默认的健康检查机制,会在每个容器启动后检查进程的返回码,如果非0,表示运行失败,此时根据restartPolicy来重启容器。
但是这种情况不能满足实际,有可能程序发生了故障,但进程并不会退出,比如服务器内部错误500,系统超载,资源死锁等。因此,k8s还提供了其他的健康检查方式。
-
livenessProbe
自定义健康检查的方式,失败则重启Pod。
-
readinessProbe
告诉k8s什么时候可以将容器加入到Service的负载均衡池中,以对外提供服务,失败则不加入Service
应用
- scale up
- rolling update
Helm
Helm是k8s的应用打包工具,类似于Ubuntu的apt或者centos的yum,可以很方便的管理k8s应用。
Helm主要管理2部分,chart和release。chart就类似于软件安装包,helm通过chart安装release,release就是具体运行的一个应用。
Helm包含2个组件:Helm客户端和Tiller服务器。简单理解,前者负责管理chart,后者负责管理release。
CRD
CRD 全称是 Custom Resource Definition, 其特点如下
- CRD 本身是 Kubernetes 的一种资源,允许用户自定义新的资源类型
- 除了 CRD 还需要用户提供一个 Controller,以实现自己的逻辑
- CRD 允许用户基于已有的 Kubernetes 资源,例如 Deployment、Configmap 等,拓展集群能力
- CRD 可以自定义一套成体系的规范,自造概念
参考博客
https://blog.csdn.net/weixin_41636021/article/details/128100860
k8s网络
网络模型:采用的是基于扁平地址空间的网络模型,主要包含4个方面
- Pod内容器直接的通信
- Pod之间的通信
- Pod与Service的通信
- 外部访问
网络方案:k8s采用CNI规范,目前有多种网络方案都是基于CNI规范,因此k8s可采用的网络方案很多,比如Flannel, Calico, Canal, Weave Net
Network Policy:类似于Pod,Service等,Network Policy也是一种资源,可以实现控制流量到不同Pod中,具体规则由Policy定义。
k8s集群监控
Weave Scope
Heapster—使用Grafana
Prometheus Operator—基于Prometheus,也使用了Grafana
Prometheus是一个很好的监控方案。
配套视频
【一起来认识一下Kubernetes吧!】 https://www.bilibili.com/video/BV1ec411C7MC/?share_source=copy_web&vd_source=2fc4a66fb7fe408b706bb10750c6ac28















 941
941











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









