







文章目录
1、概述
如图所示,线程安全集合类可以分为三大类
- 遗留的线程安全集合如 Hashtable ,Vector
- 使用 Collections 装饰的线程安全集合,如:
- Collections.synchronizedCollection
- Collections.synchronizedList
- Collections.synchronizedMap
- Collections.synchronizedSet
- Collections.synchronizedNavigableMap
- Collections.synchronizedNavigableSet
- Collections.synchronizedSortedMap
- Collections.synchronizedSortedSet
- java.util.concurrent.* 下的线程安全集合类,可以发现它们有规律,里面包含三类关键词: Blocking、CopyOnWrite、Concurrent
- Blocking 大部分实现基于锁,并提供用来阻塞的方法
- CopyOnWrite 之类容器修改开销相对较重,修改的时候是采用的拷贝的方式,适合于读多写少
- Concurrent 类型的容器,内部很多操作使用 CAS 优化,一般可以提供较高吞吐量,但是其具有弱一致性的特点,例如,当利用迭代器遍历时,如果容器发生修改,迭代器仍然可以继续进行遍历,这时内容是旧的,又例如,size 操作未必是 100% 准确
- 对比非安全容器,遍历时如果发生了修改,使用 fail-fast 机制也就是让遍历立刻失败,抛出 ConcurrentModificationException,不再继续遍历,而安全的容器,使用的便是 fail-save 机制
遗留的线程安全集合,为什么叫遗留,因为他们出现的比较早,而且保证线程安全的手法都是给方法上面添加 synchronized 关键字,并发效率太低
使用 Collections 装饰的线程安全集合,是如何操作的?以 Map 为例
public static <K,V> Map<K,V> synchronizedMap(Map<K,V> m) {
return new SynchronizedMap<>(m);
}
private static class SynchronizedMap<K,V>
implements Map<K,V>, Serializable {
private static final long serialVersionUID = 1978198479659022715L;
private final Map<K,V> m; // Backing Map
final Object mutex; // Object on which to synchronize
SynchronizedMap(Map<K,V> m) {
this.m = Objects.requireNonNull(m);
//存储在自己的成员变量中
mutex = this;
}
SynchronizedMap(Map<K,V> m, Object mutex) {
this.m = m;
this.mutex = mutex;
}
public int size() {
synchronized (mutex) {return m.size();}
}
public boolean isEmpty() {
synchronized (mutex) {return m.isEmpty();}
}
public boolean containsKey(Object key) {
synchronized (mutex) {return m.containsKey(key);}
}
public boolean containsValue(Object value) {
synchronized (mutex) {return m.containsValue(value);}
}
public V get(Object key) {
synchronized (mutex) {return m.get(key);}
}
public V put(K key, V value) {
synchronized (mutex) {return m.put(key, value);}
}
public V remove(Object key) {
synchronized (mutex) {return m.remove(key);}
}
public void putAll(Map<? extends K, ? extends V> map) {
synchronized (mutex) {m.putAll(map);}
}
public void clear() {
synchronized (mutex) {m.clear();}
}
private transient Set<K> keySet;
private transient Set<Map.Entry<K,V>> entrySet;
private transient Collection<V> values;
public Set<K> keySet() {
synchronized (mutex) {
if (keySet==null)
keySet = new SynchronizedSet<>(m.keySet(), mutex);
return keySet;
}
}
public Set<Map.Entry<K,V>> entrySet() {
synchronized (mutex) {
if (entrySet==null)
entrySet = new SynchronizedSet<>(m.entrySet(), mutex);
return entrySet;
}
}
public Collection<V> values() {
synchronized (mutex) {
if (values==null)
values = new SynchronizedCollection<>(m.values(), mutex);
return values;
}
}
public boolean equals(Object o) {
if (this == o)
return true;
synchronized (mutex) {return m.equals(o);}
}
public int hashCode() {
synchronized (mutex) {return m.hashCode();}
}
public String toString() {
synchronized (mutex) {return m.toString();}
}
// Override default methods in Map
@Override
public V getOrDefault(Object k, V defaultValue) {
synchronized (mutex) {return m.getOrDefault(k, defaultValue);}
}
@Override
public void forEach(BiConsumer<? super K, ? super V> action) {
synchronized (mutex) {m.forEach(action);}
}
@Override
public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
synchronized (mutex) {m.replaceAll(function);}
}
@Override
public V putIfAbsent(K key, V value) {
synchronized (mutex) {return m.putIfAbsent(key, value);}
}
@Override
public boolean remove(Object key, Object value) {
synchronized (mutex) {return m.remove(key, value);}
}
@Override
public boolean replace(K key, V oldValue, V newValue) {
synchronized (mutex) {return m.replace(key, oldValue, newValue);}
}
@Override
public V replace(K key, V value) {
synchronized (mutex) {return m.replace(key, value);}
}
@Override
public V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
synchronized (mutex) {return m.computeIfAbsent(key, mappingFunction);}
}
@Override
public V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
synchronized (mutex) {return m.computeIfPresent(key, remappingFunction);}
}
@Override
public V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
synchronized (mutex) {return m.compute(key, remappingFunction);}
}
@Override
public V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
synchronized (mutex) {return m.merge(key, value, remappingFunction);}
}
private void writeObject(ObjectOutputStream s) throws IOException {
synchronized (mutex) {s.defaultWriteObject();}
}
}
- 想来,和 HashTable 没有太大区别,都是使用了 synchronized 关键字,然后调用原始的 Map,🤕
2、ConcurrentHashMap
2.1、简单应用
讲解 CHM 之前,我们先做一个 Demo,单词计数,首先准备测试数据
static final String ALPHA = "abcedfghijklmnopqrstuvwxyz";
@SneakyThrows
public static void main(String[] args) {
int length = ALPHA.length();
int count = 200;
List<String> list = new ArrayList<>(length * count);
for (int i = 0; i < length; i++) {
char ch = ALPHA.charAt(i);
for (int j = 0; j < count; j++) {
list.add(String.valueOf(ch));
}
}
//随机打乱顺序
Collections.shuffle(list);
for (int i = 0; i < 26; i++) {
try (PrintWriter out = new PrintWriter(
new OutputStreamWriter(
new FileOutputStream("D:/temp/" + (i + 1) + ".txt")))) {
String collect = String.join("\n", list.subList(i * count, (i + 1) * count));
out.print(collect);
} catch (IOException e) {
e.printStackTrace();
}
}
}

接下来准备测试代码,以下代码用于从文件集合中读取内容,并同时并发的往自己准备的 Map 集合中存储字符出现次数
private static <V> void demo(Supplier<Map<String, V>> supplier,
BiConsumer<Map<String, V>, List<String>> consumer) {
Map<String, V> counterMap = supplier.get();
List<Thread> ts = new ArrayList<>();
for (int i = 1; i <= 26; i++) {
int idx = i;
Thread thread = new Thread(() -> {
List<String> words = readFromFile(idx);
consumer.accept(counterMap, words);
});
ts.add(thread);
}
ts.forEach(Thread::start);
//等待26个线程结束
ts.forEach(t -> {
try {
t.join();
} catch (InterruptedException e) {
e.printStackTrace();
}
});
System.out.println(counterMap);
}
public static List<String> readFromFile(int i) {
ArrayList<String> words = new ArrayList<>();
try (BufferedReader in = new BufferedReader(new InputStreamReader(new FileInputStream("D:/temp/"
+ i + ".txt")))) {
while (true) {
String word = in.readLine();
if (word == null) {
break;
}
words.add(word);
}
return words;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
首先使用普通的 HashMap 做测试
demo(
(Supplier<Map<String, Integer>>) HashMap::new,
(map, words) -> {
for (String word : words) {
Integer count = map.get(word);
map.put(word, count == null ? 1 : count + 1);
}
}
);

- 可以发现,没有一个是对的,因为有 26 个线程同时操作同一个 HashMap,出现了线程安全的问题,那么我们换线程安全的类 ConcurrentHashMap 试试
demo(
(Supplier<Map<String, Integer>>) ConcurrentHashMap::new,
(map, words) -> {
for (String word : words) {
Integer count = map.get(word);
map.put(word, count == null ? 1 : count + 1);
}
}
);

- 发现仍然是错误的结果,这是为什么呢?其实对于线程安全的集合类,它们只能保证其对应的某个方法线程安全,但是如果对于多个方法的合集,并不能保证其线程安全,可以明白的是,我们的程序在高并发的场景下,使用了线程安全的集合仍然不能保证程序的正确性,但是使用了非线程安全的集合,必然不能保证程序的正确性
为了保证我们程序输出的正确性,我们可以尝试在统计字母的时候,加上 synchronized
private static final Object LOCK = new Object();
public static void main(String[] args) {
demo(
(Supplier<Map<String, Integer>>) ConcurrentHashMap::new,
(map, words) -> {
synchronized (LOCK) {
for (String word : words) {
Integer count = map.get(word);
map.put(word, count == null ? 1 : count + 1);
}
}
}
);
}

- 但是我们往往选择使用 ConcurrentHashMap 的时候,不就是看重了它的锁粒度很低吗,我们这样子写了,还不如直接使用 HashMap 去加锁效率高,如果解决这个问题呢,其实 ConcurrentHashMap 这个类中给我们封装了部分符合这个功能的方法 computeIfAbsent,如果缺少目标 key,则可以计算生成一个 value,然后将 key value 放入 map,但是我们还缺少一个累加操作,它的线程安全,我们可以使用 LongAdder 去保证
demo(
(Supplier<Map<String, LongAdder>>) ConcurrentHashMap::new,
(map, words) -> {
synchronized (LOCK) {
for (String word : words) {
//如果缺少key,则可以计算生成一个 value,然后将 key value 放入map
LongAdder count = map.computeIfAbsent(word, (k) -> new LongAdder());
//内部使用 cas 保证线程安全
count.increment();
}
}
}
);

2.2、JDK 7 HashMap 并发死链
2.2.1、问题
如果是在单线程下使用 HashMap,自然是没有问题的,如果后期由于代码优化,这段逻辑引入了多线程并发执行,在一个未知的时间点,会发现 CPU 占用 100%,居高不下,通过查看堆栈,你会惊讶的发现,线程都卡在 HashMap 的 get() 方法上,服务重启之后,问题消失,过段时间可能又复现了。这是为什么?
2.2.2、复现
- 第一步,保证当前 JDK 环境为 7
System.getProperty("java.version");

- 第二步,加入如下测试代码,注意,不要轻易更改其中逻辑
public static void main(String[] args) {
// 测试 java 7 中哪些数字的 hash 结果相等
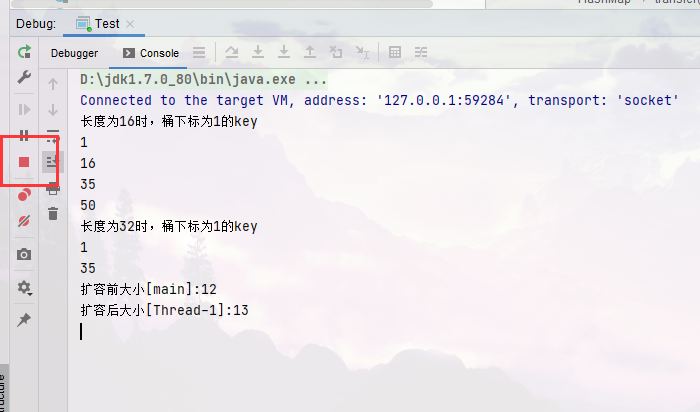
System.out.println("长度为16时,桶下标为1的key");
for (int i = 0; i < 64; i++) {
if (hash(i) % 16 == 1) {
System.out.println(i);
}
}
System.out.println("长度为32时,桶下标为1的key");
for (int i = 0; i < 64; i++) {
if (hash(i) % 32 == 1) {
System.out.println(i);
}
}
// 1, 35, 16, 50 当大小为16时,它们在一个桶内
final HashMap<Integer, Integer> map = new HashMap<>();
// 放 12 个元素
map.put(2, null);
map.put(3, null);
map.put(4, null);
map.put(5, null);
map.put(6, null);
map.put(7, null);
map.put(8, null);
map.put(9, null);
map.put(10, null);
map.put(16, null);
map.put(35, null);
map.put(1, null);
System.out.println("扩容前大小[main]:" + map.size());
new Thread() {
@Override
public void run() {
// 放第 13 个元素, 发生扩容
map.put(50, null);
System.out.println("扩容后大小[Thread-0]:" + map.size());
}
}.start();
new Thread() {
@Override
public void run() {
// 放第 13 个元素, 发生扩容
map.put(50, null);
System.out.println("扩容后大小[Thread-1]:" + map.size());
}
}.start();
}
static int hash(Object k) {
int h = 0;
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
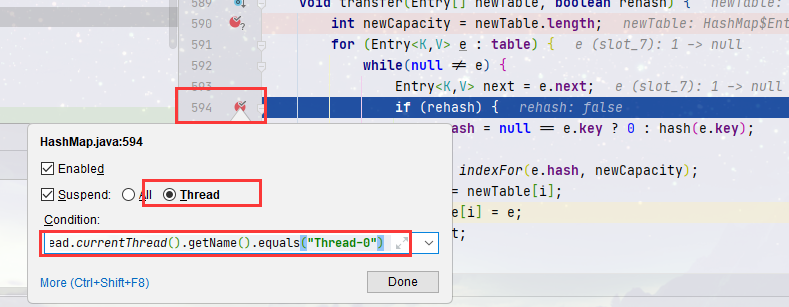
- 第三步,在 HashMap 源码第 590 行打上断点,注意断点类型设置为 Thread,否则一个线程断住后,其他,然后加上一个断点条件
newTable.length==32 &&
(
Thread.currentThread().getName().equals("Thread-0")||
Thread.currentThread().getName().equals("Thread-1")
)

- debug ,注意 IDEA 在调试的时候在非 Object 视图下有些属性不可见,需要改以下视图类型为 Object,其余不可见属性同样可这样设置

可以看到,1 的位置上有三个节点,我们程序在 put 的时候,顺序是 16 -> 35 -> 1 ,这里可以体现,如果出现 Hash 冲突,节点指向顺序是添加的逆序

- 单步运行到 594 行,然后在这里再加一个断点,目的是为了让 Thread-1 恢复运行后停在这里,同样需要加上如下断点条件
Thread.currentThread().getName().equals("Thread-0")
- 记住现在的 e 和 next,分别是 1 和 35,也就是:
e:1 -> 35 -> 16 -> null
next : 35 -> 16 -> null

- 在 Threads 面板选中 Thread-1 恢复运行

- 直接让它执行完,可以看见,扩容完毕

- 现在只剩下 Thread-0 还停下来了

- 现在再看一下 1 的位置,因为我们 rehash 的时候,访问链表的顺序和我们重新插入的顺序是相反的,所以 1 -> 35 变为了 35 -> 1,原本的 16 经过 rehash 转移到了其他地方

- 好,现在我们重新把注意力放在之前的 e 和 next
e:1 -> 35 -> 16 -> null
next : 35 -> 16 -> null
- 现在变成了
e : (1)->null
next:(35)->(1)->null
- 因为 Thread-1 扩容时链表也是后加入的元素放入链表头,因此链表就倒过来了,但 Thread-1 虽然结果正确,但它结束后 Thread-0 还要继续运行,现在单步执行,进入下一次循环,此时观察 newTable,它把 1 加入了,并且 e = 35,next = 1

- 再执行一次循环,35 -> 1
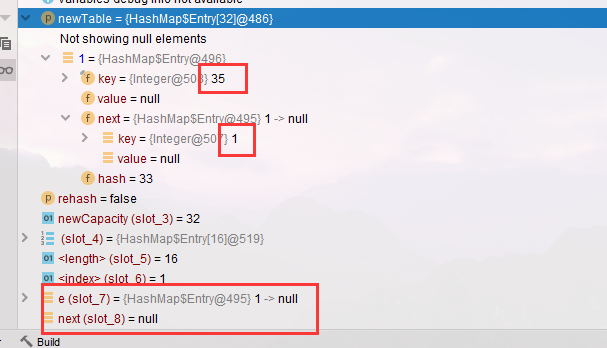
- 再次执行循环,此时 e = 1 重新加入头节点,1 -> 35,便有了 1 -> 35 -> 1…

- 然后就直接卡死了
2.2.3、HashMap数据结构概述
在了解来龙去脉之后,我们再来回顾一下 HashMap 的数据结构。
-
在内部,HashMap 使用一个 Entry 数组保存 key、value 数据,当一对 key、value 被加入时,会通过一个 hash 算法得到数组的下标 index,算法很简单,根据 key 的 hash 值,对数组的大小取模 hash & (length-1),并把结果插入数组该位置,如果该位置上已经有元素了,就说明存在 hash 冲突,这样会在 index 位置生成链表。
-
如果存在 hash 冲突,最惨的情况,就是所有元素都定位到同一个位置,形成一个长长的链表,这样 get 一个值时,最坏情况需要遍历所有节点,性能变成了 O(n),所以元素的 hash 值算法和 HashMap 的初始化大小很重要。
-
当插入一个新的节点时,如果不存在相同的 key,则会判断当前内部元素是否已经达到阈值(默认是数组大小的 0.75 ),如果已经达到阈值,会对数组进行扩容,也会对链表中的元素进行 rehash。
2.2.4、过程分析
原始 map(省略其他节点)

Thread-0,Thread-1执行到扩容操作后,同时创建了新的 entry 数组 newTable
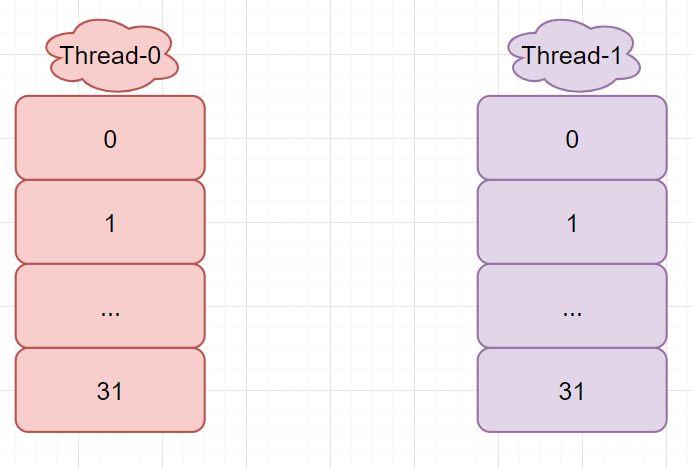
Thread-0 在执行到 Entry<K,V> next = e.next; 时间片用完了,挂起了,此时
- e -> 1 -> 35 -> 16 -> null
- next -> 35 -> 16 -> null
Thread-1 正常执行,由于当前 JDK7 在进行链表插入的时候,是用的头插法,所以 Thread-1 在 rehash 后,复制出来的新链表顺序就和以前相反(16 转移到其他地方了)

此时 Thread-0 的变量 e 指向的还是 1 ,next 指向了 35 ,开始循环操作,将 1 插入链表,e 变为 后继 35,next 此时又等于 35 的后继 1

再来一次循环 e = 1, next = null

至此,35 和 1 分别指向了对方,形成一个死链
2.2.6、jdk8的改变
JDK 8 将扩容算法做了调整,不再将元素加入链表头(而是保持与扩容前一样的顺序),但仍不意味着能够在多线程环境下能够安全扩容,还会出现其它问题(如扩容丢数据),但是官方并不会修复,因为高并发场景下本身就没让你用 HashMap,明明让你用 ConcurrentHashMap
2.3、JDK8 ConcurrentHashMap原理

2.3.1、重要的属性和内部类
// 默认为 0
// 当初始化时, 为 -1
// 当扩容时, 为 -(1 + 扩容线程数)
// 当初始化或扩容完成后,为 下一次的扩容的阈值大小
private transient volatile int sizeCtl;
// 整个 ConcurrentHashMap 就是一个 Node[]
static class Node<K,V> implements Map.Entry<K,V> {}
// hash 表
transient volatile Node<K,V>[] table;
// 扩容时的 新 hash 表
private transient volatile Node<K,V>[] nextTable;
// 扩容时如果某个 bin 迁移完毕, 用 ForwardingNode 作为旧 table bin 的头结点,key = -1
static final class ForwardingNode<K,V> extends Node<K,V> {}
// 用在 compute 以及 computeIfAbsent 时, 用来占位, 计算完成后替换为普通 Node
static final class ReservationNode<K,V> extends Node<K,V> {}
// 作为 红黑树 的头节点, 存储 root 和 first,其子节点还是 TreeNode
static final class TreeBin<K,V> extends Node<K,V> {}
// 作为 treebin 的节点, 存储 parent, left, right
static final class TreeNode<K,V> extends Node<K,V> {}
2.3.2、重要的方法
// 获取 Node[] 中第 i 个 Node
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i)
// cas 修改 Node[] 中第 i 个 Node 的值, c 为旧值, v 为新值
static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v)
// 直接修改 Node[] 中第 i 个 Node 的值, v 为新值
static final <K,V> void setTabAt(Node<K,V>[] tab, int i, Node<K,V> v)
2.3.3、构造器
JDK 8 是懒惰初始化的,在构造方法中仅仅计算了 table 的大小,以后在第一次使用时才会真正创建
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
// tableSizeFor 仍然是保证计算的大小是 2^n, 即 16,32,64 ...
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}
2.3.4、get
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// spread 方法能确保返回结果是正数
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
// 如果头结点已经是要查找的 key
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
// hash 为负数表示该 bin 在扩容中(-1)或是 treebin(-2), 这时调用 find 方法来查找
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 正常遍历链表, 用 equals 比较
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
2.3.5、put
- put 还有一个重载的三参数方法,第三个参数表示是否要覆盖已有的值,如果已经存在就不能放了
- HashMap 允许空值,但是 ConcurrentHashMap 不允许
- map 的初始化是懒惰的
- 如果链表长度 >= 树化阈值(8), 进行链表转为红黑树,但是也不是立即转换为红黑树,首先会进行扩容,如果 hash 表长度还没有达到 64 的时候,它会先扩容,让数据再分散一次,如果扩容到 64 后,链表长度大于等于 8 就不会再扩容了,就会转换为红黑树的数据结构
- 初始化 hash 表的时候,只有一个线程能够创建,其他线程并不会阻塞,而是忙等,死循环的方式
- 在 put 成功后,还会借鉴 LongAdder 的思想,调用了 addCount 方法做了一个分段的计数,保存每一个位置的元素个数,同时还去判断了当前是否需要扩容
public V put(K key, V value) {
//第三个参数是是否要覆盖已有的值,如果已经存在就不能放了
return putVal(key, value, false);
}
final V putVal(K key, V value, boolean onlyIfAbsent) {
//HashMap允许空值,但是ConcurrentHashMap不允许
if (key == null || value == null) throw new NullPointerException();
// 其中 spread 方法会综合高位低位, 具有更好的 hash 性
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
// f 是链表头节点
// fh 是链表头结点的 hash
// i 是链表在 table 中的下标
Node<K,V> f; int n, i, fh;
// 要创建 table
if (tab == null || (n = tab.length) == 0)
// 初始化 table 使用了 cas, 无需 synchronized,创建成功, 进入下一轮循环
tab = initTable();
// 要创建链表头节点
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 添加链表头使用了 cas, 无需 synchronized
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break;
}
// 判断头节点是否是 -1 ,如果是,则其他线程正在扩容,然后自己还回去帮忙扩容
else if ((fh = f.hash) == MOVED)
// 帮忙之后, 进入下一轮循环
tab = helpTransfer(tab, f);
//既不是扩容,也不是初始化,就是下标冲突
else {
V oldVal = null;
// 锁住链表头节点
synchronized (f) {
// 再次确认链表头节点没有被移动
if (tabAt(tab, i) == f) {
// 链表,红黑树是-2
if (fh >= 0) {
//链表长度
binCount = 1;
// 遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 找到相同的 key
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
// 更新
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 已经是最后的节点了, 新增 Node, 追加至链表尾
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
// 红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
//树高度
binCount = 2;
// putTreeVal 会看 key 是否已经在树中, 是, 则返回对应的 TreeNode
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
// 释放链表头节点的锁
}
//判断是否要扩容
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
// 如果链表长度 >= 树化阈值(8), 进行链表转为红黑树,但是也不是立即转换为红黑树,首先会进行扩容,如果 hash 表长度还没有达到 64 的时候,它会先扩容,让数据再分散一次,如果扩容到 64 后,链表长度大于等于 8 就不会再扩容了,就会转换为红黑树的数据结构
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 增加 size 计数,保存了每个位置上的元素深度
addCount(1L, binCount);
return null;
}
private final Node<K,V>[] initTable() {
Node<K,V>[] tab; int sc;
while ((tab = table) == null || tab.length == 0) {
if ((sc = sizeCtl) < 0)
//如果其他线程已经在创建表了,就会让权
Thread.yield();
// 尝试将 sizeCtl 设置为 -1(表示初始化 table)
else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
// 获得锁, 创建 table, 这时其它线程会在 while() 循环中 yield 直至 table 创建
try {
if ((tab = table) == null || tab.length == 0) {
int n = (sc > 0) ? sc : DEFAULT_CAPACITY;
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = tab = nt;
//准备好下次要扩容的数值
sc = n - (n >>> 2);
}
} finally {sizeCtl = sc;
}
break;
}
}
return tab;
}
// check 是之前 binCount 的个数
private final void addCount(long x, int check) {
CounterCell[] as; long b, s;
if (
// 已经有了 counterCells, 向 cell 累加
(as = counterCells) != null ||
// 还没有, 向 baseCount 累加
!U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)
) {
CounterCell a; long v; int m;
boolean uncontended = true;
if (
// 还没有 counterCells
as == null || (m = as.length - 1) < 0 ||
// 还没有 cell
(a = as[ThreadLocalRandom.getProbe() & m]) == null ||
// cell cas 增加计数失败
!(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))
) {
// 创建累加单元数组和cell, 累加重试
fullAddCount(x, uncontended);
return;
}
if (check <= 1)
return;
// 获取元素个数
s = sumCount();
}
if (check >= 0) {
Node<K,V>[] tab, nt; int n, sc;
//是否大于扩容阈值
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&
(n = tab.length) < MAXIMUM_CAPACITY) {
int rs = resizeStamp(n);
if (sc < 0) {
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
// newtable 已经创建了,帮忙扩容
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
// 需要扩容,这时 newtable 未创建
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
s = sumCount();
}
}
}
2.3.6、Size计算流程
因为 ConcurrentHashMap 计算大小的时候实际发生在 put,remove 改变集合元素的操作之中
-
没有竞争发生,向 baseCount 累加计数
-
有竞争发生,新建 counterCells,向其中的一个 cell 累加计数
- counterCells 初始有两个 cell,如果计数竞争比较激烈,会创建新的 cell 来累加计数
public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); } final long sumCount() { CounterCell[] as = counterCells; CounterCell a; // 将 baseCount 计数与所有 cell 计数累加 long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }
2.4、JDK7 ConcurrentHashMap原理

它维护了一个 segment 数组,每个 segment 对应一把锁(其实本身就继承自 ReentrantLock,自己就是一把锁)
- 优点:如果多个线程访问不同的 segment,实际是没有冲突的,这与 jdk8 中是类似的(加在每个链表头)
- 缺点:Segments 数组默认大小为 16,这个容量初始化指定后就不能改变了,并且不是懒惰初始化
2.4.1、构造器
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// ssize 必须是 2^n, 即 2, 4, 8, 16 ... 表示了 segments 数组的大小
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
// segmentShift 默认是 32 - 4 = 28
this.segmentShift = 32 - sshift;
// segmentMask 默认是 15 即 0000 0000 0000 1111
this.segmentMask = ssize - 1;
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// 创建 segments and segments[0]
Segment<K,V> s0 =
new Segment<K,V>(loadFactor, (int)(cap * loadFactor),
(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];
UNSAFE.putOrderedObject(ss, SBASE, s0); // ordered write of segments[0]
this.segments = ss;
}
- 可以看到 ConcurrentHashMap 没有实现懒惰初始化,空间占用不友好,其中 this.segmentShift 和 this.segmentMask 的作用是决定将 key 的 hash 结果匹配到哪个 segment
例如,根据某一 hash 值求 segment 位置,先将高位向低位移动 this.segmentShift 位

- 最终得到 1010 即下标为 10 的 segment
2.4.2、put
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
// 计算出 segment 下标
int j = (hash >>> segmentShift) & segmentMask;
// 获得 segment 对象, 判断是否为 null, 是则创建该 segment
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null) {
// 这时不能确定是否真的为 null, 因为其它线程也发现该 segment 为 null,
// 因此在 ensureSegment 里用 cas 方式保证该 segment 安全性
s = ensureSegment(j);
}
// 进入 segment 的put 流程
return s.put(key, hash, value, false);
}
segment 继承了可重入锁(ReentrantLock),它的 put 方法为
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 尝试加锁
HashEntry<K,V> node = tryLock() ? null :
// 如果不成功, 进入 scanAndLockForPut 流程
// 如果是多核 cpu 最多 tryLock 64 次, 进入 lock 流程
// 在尝试期间, 还可以顺便看该节点在链表中有没有, 如果没有顺便创建出来
scanAndLockForPut(key, hash, value);
// 执行到这里 segment 已经被成功加锁, 可以安全执行
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
// 更新
K k;
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 新增
// 1) 之前等待锁时, node 已经被创建, next 指向链表头
if (node != null)
node.setNext(first);
else
// 2) 创建新 node
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
// 3) 扩容
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
// 将 node 作为链表头
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
unlock();
}
return oldValue;
}
2.4.3、rehash
发生在 put 中,因为此时已经获得了锁,因此 rehash 时不需要考虑线程安全
private void rehash(HashEntry<K,V> node) {
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =
(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
// 过一遍链表, 尽可能把 rehash 后 idx 不变的节点重用
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// 剩余节点需要新建
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
// 扩容完成, 才加入新的节点
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
// 替换为新的 HashEntry table
table = newTable;
}
2.4.4、get
get 时并未加锁,用了 UNSAFE 方法保证了可见性,扩容过程中,get 先发生就从旧表取内容,get 后发生就从新表取内容
public V get(Object key) {
Segment<K,V> s; // manually integrate access methods to reduce overhead
HashEntry<K,V>[] tab;
int h = hash(key);
// u 为 segment 对象在数组中的偏移量
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
// s 即为 segment
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}
2.4.5、Size计算流程
- 计算元素个数前,先不加锁计算两次,如果前后两次结果如一样,认为个数正确返回
- 如果不一样,进行重试,重试次数超过 3,将所有 segment 锁住,重新计算个数返回
public int size() {
// Try a few times to get accurate count. On failure due to
// continuous async changes in table, resort to locking.
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
// 超过重试次数, 需要创建所有 segment 并加锁
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
2.5、总结
-
JDK7 中 ConcurrentHashMap 使用的分段锁,也就是每一个 Segment 上同时只有一个线程可以操作,每一个 Segment 都是一个类似 HashMap 数组的结构,它可以扩容,它的冲突会转化为链表。但是 Segment 的个数一但初始化就不能改变。
-
JDK8 中的 ConcurrentHashMap 使用的 Synchronized 锁加 CAS 的机制。结构也由 JDK7 中的 Segment 数组 + HashEntry 数组 + 链表 进化成了 Node 数组 + 链表 / 红黑树,Node 是类似于一个 HashEntry 的结构。它的链表的元素个数达到了阈值 8 时会转化成红黑树,在冲突小于 6 时又退回链表。















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









